






分什么
数据量大分表,并发大分库
分表字段如何选择
如果对交易订单进行分表,可以选择的东西很多,比如说商户id,用户id,地区等等
分表的时候要考虑到数据倾斜问题
数据倾斜
比如说按商户号进行分表,一共500w条数据,结果一个商户就有400w条的数据,这样来说 会有严重的数据倾斜问题
解决方案 二次分表
1. 二次分表
一开始可以根据商户进行分库分表,如果出现数据倾斜的问题,可以根据商户和时间在做一次分库分表
根据多个字段进行路由
查询的时候也是根据多个字段进行路由
2. 隔离
把严重数据偏移的商户数据,单独开一个数据库
数据倾斜问题可能导致 资源利用不均匀。
数据关联查询问题
如果订单表根据用户id进行分表
用户可以查询自己的订单
那商户如何查询用户的订单呢?
毕竟商户没有用户的id
解决方案 数据同步
买家表使用canal 做数据同步,将表中的数据同步到一个新的表(商户表)
这个表里面维护了 商家id 和 订单表的数据,根据商家id进行分库分表
商家不需要写入性能,只需要读取性能比较高
比如说可以采用HBASE数据库进行读取
数据id查询问题
如果我想根据订单id直接查询订单信息,如何进行查询呢?
因为此时,我没有路由的建,用户id
解决方案 基因法
生成id的策略可以定义为 订单id+分表路由
这样根据订单id 就可以知道数据存储在哪张表中
这张表根据订单id去做索引
当然还有别的方法,如果是其他无关紧要的数据,可以放入es,搜索引擎,从而对订单进行搜索
分表算法是什么
选择完分表字段了,如何选择分表算法呢?
直接取模
hash
关键字
一致性hash
一致性hash
一致性hash 很好的解决了,多次分表的问题(原来分128张表,现在增加到256张表)

hash环上面有32^2的虚拟节点

再把数据也hash到环上
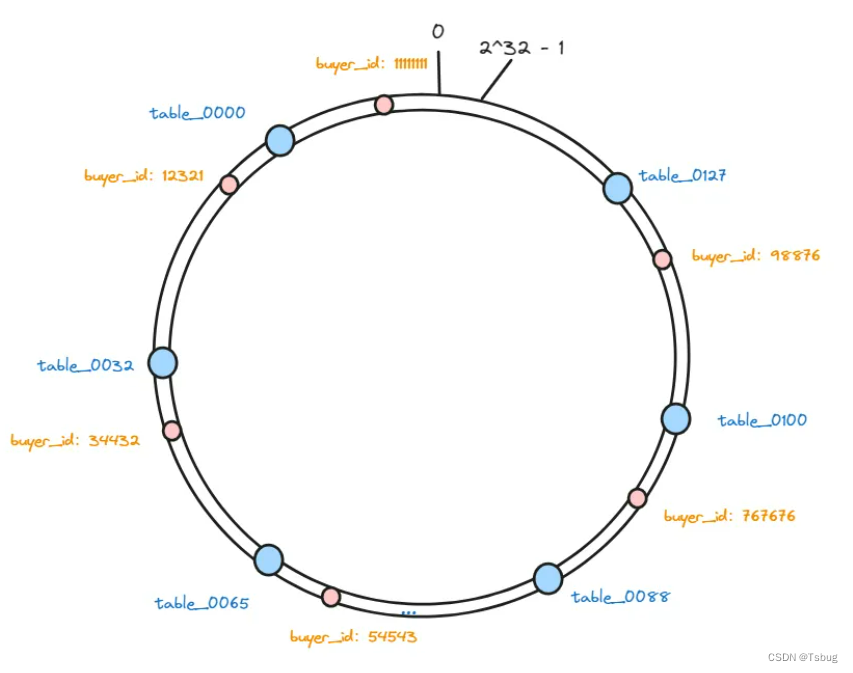
id往前找到要进行存储的表

如果此时需要新增表,就通过一致性hash,将要加入的表映射到hash换上

这样会有一部分数据进行查找表的时候会有一定的影响
但是受到的影响已经很小了
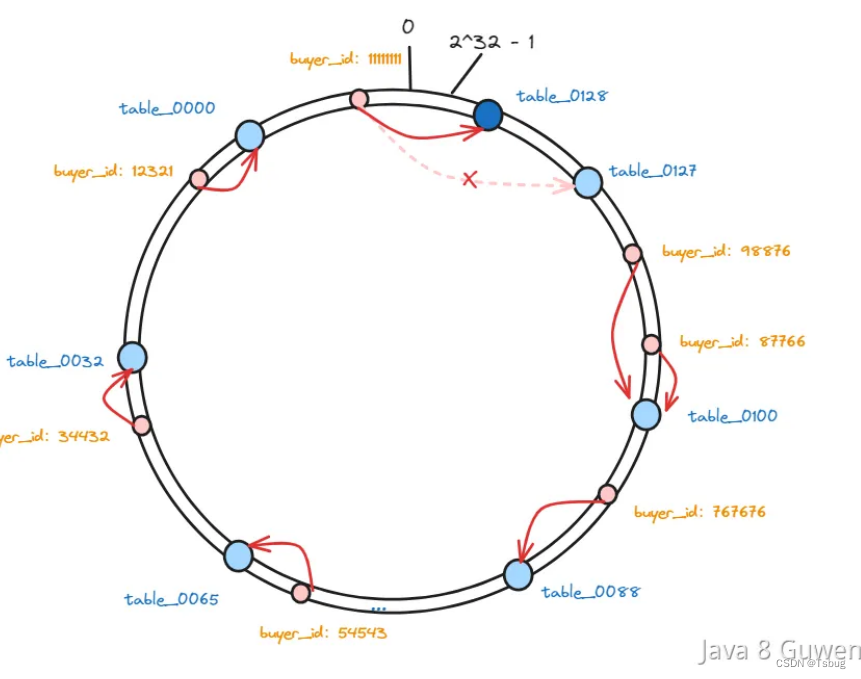
这个时候可以再去做数据迁移

估计一下单表数据量
公式:( 非叶子节点层数 -1)* 一页内非叶子节点索引数 * 叶子节点的数据量
分表后 全局id如何生成
肯定不能用自增去弄,因为自增会导致id重复
UUID
太长了、无业务含义
雪花算法

雪花算法也有个问题
时间回拨,容易造成id的重复生成
分库分表事务
Seata
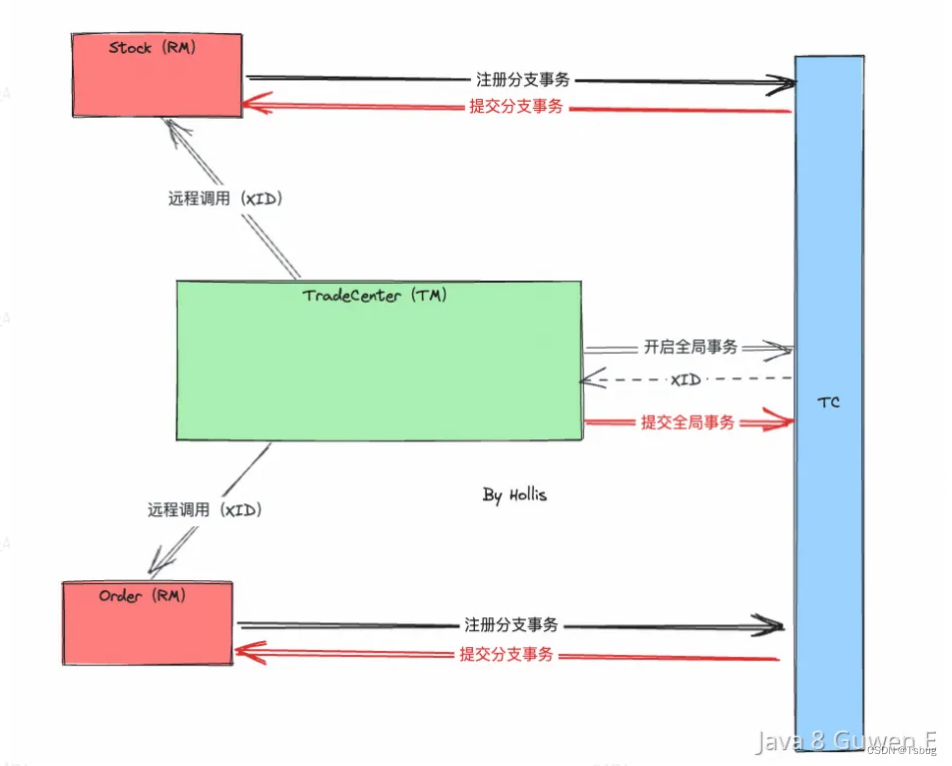
流程
TM 向 TC申请 XID
TM带着XID调用RM
RM向TC注册分支事务
TM告诉TC是否commit 或者是 rollback
由TC告知RM进行提交
跨库join
指定库名做join
数据冗余
宽表
es















 3161
3161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









