







在快乐痛苦地学习了
n
n
n天二分图后
终于!!!!
得到了这篇总结
二分图
定义&概念
- 二分图:又称作二部图。若G是一个无向图。G的顶点分成X和Y两部分,G中每条边的两个顶点一定是一个属于X,另一个属于Y。图G称为二分图。
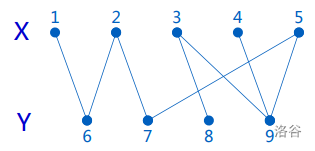
-
节点由两个集合组成,且两个集合内部没有边的图。换言之,存在一种方案,将节点划分成满足以上性质的两个集合。
-
匹配:M是无向图G的若干条边的集合,如果M中任意两条边都没有公共端点,则称M是一个匹配。
-
未盖点:若点Vi不与任何一条属于M的边相关联,则称Vi是一个未盖点(未匹配点)。比如图中D、E就是未盖点。
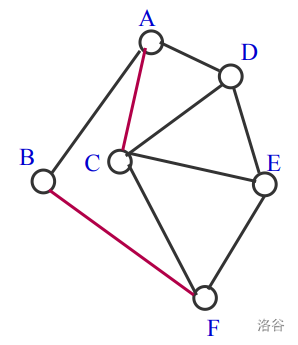
性质
- 如果两个集合中的点分别染成黑色和白色,可以发现二分图中的每一条边都一定是连接一个黑色点和一个白色点。
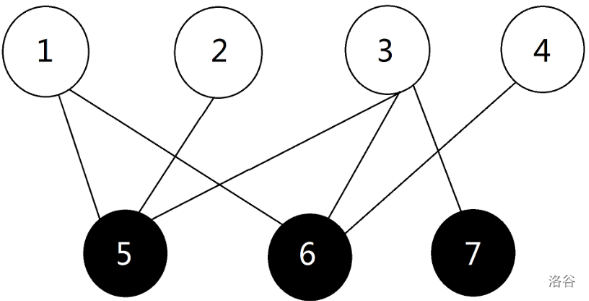
可以看到,其中每一条边都连接一个白点和一个黑点。
-
二分图不存在长度为奇数的环
举例上图中的 1 , 6 , 3 , 5 , 1 1,6,3,5,1 1,6,3,5,1 可以发现为4条边;
因为每一条边都是从一个集合走到另一个集合,只有走偶数次才可能回到同一个集合。
恰与上文提到的黑白点对应。
以此延伸,得到
判定
判定一个图是不是二分图,本质上就是判断图中的顶点是否可以分为两个集合,且满足定义。
通过上文提到的性质,我们考虑遍历( D F S DFS DFS或 B F S BFS BFS)整张图,若找到奇环则不是,否则是。
扯了许多定义(乱七八糟)
那么来到了问题的核心,在二分图中求
最大匹配
定义
-
给定一个二分图 G G G,在 G G G的一个子图 M M M中, M M M的边集中的任意两条边都没有公共顶点,则称 M M M是一个匹配。
-
这样的边数最多的集合称为图的最大匹配(maximal matching)
-
如果一个匹配中,图中的每个顶点都和匹配中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
讲到这里,大概已经想到了最大匹配可以用来做什么(某某喜欢什么,一一对应,最多满足多少人balabala)
那么怎么解决呢!!!
首当其冲的是暴力:
先找出全部匹配,然后保留匹配数最多的;
但是这个算法的复杂度为边数的指数级函数!
所以我们要寻求一种更高效率的做法。
匈牙利算法
增广路(亦称增广轨或交错轨)
-
若P是图G中一条连通两个未匹配顶点的路径,并且属匹配边集M的边和不属M的边(即已匹配和未匹配的边)在P上交替出现,则称P为相对于M的一条增广路径。
-
借助下图理解
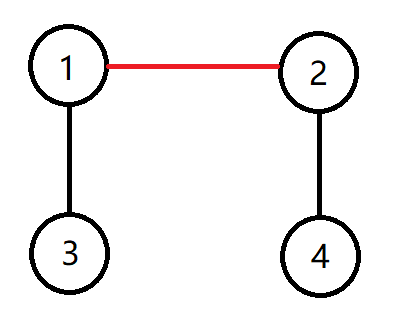
图中我们先求出 1 , 2 1,2 1,2 这个匹配
此时发现找到路径 3 , 1 , 2 , 4 3,1,2,4 3,1,2,4
而这条路径正符合在匹配中的点和不在匹配中的点(已匹配和未匹配的边)交替出现
则这条路径是一条增广路。
那么怎样应用增广路呢?
同样的图,此时我们找到了这条增广路,只需要变化一下:
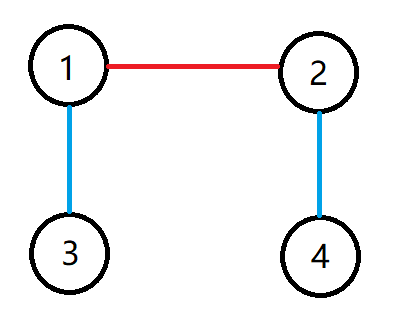
此时将 1 , 3 1,3 1,3 和 2 , 4 2,4 2,4 作为匹配中的边,丢弃 1 , 2 1,2 1,2
而新的匹配也满足匹配的定义,而我们的匹配数就增加了1
由增广路的定义可以推出下述四个结论:
1.P的路径长度必定为奇数,第一条边和最后一条边都不属于M。
2.P经过取反操作可以得到一个更大的匹配。
3.M为图G的最大匹配当且仅当不存在相对于M的增广路径。
4.如果两个未盖点之间仅含一条边,那么这条边是增广路
拥有了这些知识,我们就可以来了解匈牙利算法究竟是怎么工作了啦!
算法过程
1.置M为空
2.找出一条增广路径P,通过取反操作获得更大的匹配M’代替M
3.重复 2 操作直到找不出增广路径为止
简单来说,匈牙利算法正是利用增广路的特性,不断地让最大匹配值更大,不断改变的过程也保证了正确性。
而代码实现的方式也就十分重要。
Code:
bool _find(int x){
for(int i=0;i<ma[x].size();i++){
int v=ma[x][i];
if(!vis[v]){
vis[v]=true;
if((!link[v])||_find(link[v])){
link[v]=x;
return true;
}
}
}
return false;
}
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++) vis[j]=false;
if(_find(i)) ans++;
}
由于蒟蒻暂时没学最大权匹配,这篇文章就先到此结束了!!!
等我学了最大权匹配再回来完善!!!















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









