







6.4.3 Nanite渲染
本节将阐述Nanite渲染阶段的代码及逻辑。
6.4.3.1 Nanite渲染概述
UE5在渲染模块做了较大的改动以支持Nanite特性的渲染,总结起来如下:
-
引擎模块:
- 增加FMeshNaniteSettings类型,上一章节已做解析。
- FStaticMeshRenderData增加Nanite::FResources数据及相关处理逻辑。
- UStaticMeshComponent增加bDisplayNaniteProxyMesh,及增加FMeshNaniteSettings数据。
- UHierarchicalInstancedStaticMeshComponent、UInstancedStaticMeshComponent等组件增加Nanite的数据和SceneProxy的支持。
- 增加InstanceUniformShaderParameters模块。
-
渲染模块:
-
新增NaniteRender模块,包含FNaniteCommandInfo、ENaniteMeshPass、FNaniteDrawListContext、FCullingContext、FRasterContext、FRasterResults、FNaniteShader、FNaniteMaterialVS、FNaniteMeshProcessor、FNaniteMaterialTables、ERasterTechnique、ERasterScheduling、EOutputBufferMode、FPackedView等等类型及处理接口。
-
FPrimitiveSceneInfo增加NaniteCommandInfos、NaniteMaterialIds、LumenPrimitiveIndex以及CachedRayTracingMeshCommandsHashPerLOD、bRegisteredWithVelocityData、InstanceDataOffset、NumInstanceDataEntries实例化和光追相关的等数据和处理接口。
-
新增NaniteResources模块,包含Nanite::FSceneProxy、Nanite::FResources、Nanite::FVertexFactory等类型。
-
新增NaniteStreamingManager模块,包含Nanite::FPageKey、Nanite::FGPUStreamingRequest、Nanite::FStreamingRequest、Nanite::FStreamingPageInfo、Nanite::FRootPageInfo、Nanite::FPendingPage、Nanite::FAsyncState、Nanite::FStreamingManager、Nanite::、Nanite::等类型。
-
FPrimitiveSceneProxyz增加SupportsNaniteRendering、IsNaniteMesh、bSupportsMeshCardRepresentation、IsAlwaysVisible、GetPrimitiveInstances、RayTracingGroupId等。
-
SceneInterface和SceneManagement增加FInstanceCullingManagerResources等类型,使用FGPUScenePrimitiveCollector代替FPrimitiveUniformShaderParameters。
-
SceneView增加FViewShaderParameters、PrecomputedIndirectLightingColorScale、GlobalDistanceField、VirtualTexture、PhysicsField、Lumen、Instance、Page等shader绑定。
-
FPrimitiveFlagsCompact等类型增加bIsNaniteMesh标记。
-
-
Shader模块:
- 新增了ClusterCulling、Culling、HZBCull、InstanceCulling、MaterialCulling、Shadow、GBuffer、Impsoter、DataDecode、DataPacked、Rasterizer、WritePixel等。
6.4.3.2 Nanite渲染基础
本小节解析Nanite渲染中涉及的主要概念、类型及接口。
- InstanceUniformShaderParameters
// Engine\Source\Runtime\Engine\Public\InstanceUniformShaderParameters.h
#define INSTANCE_SCENE_DATA_FLAG_CAST_SHADOWS 0x1
#define INSTANCE_SCENE_DATA_FLAG_DETERMINANT_SIGN 0x2
#define INSTANCE_SCENE_DATA_FLAG_HAS_IMPOSTER 0x4
// Nanite实例化信息.
class FNaniteInfo
{
public:
uint32 RuntimeResourceID; // 运行时的资源标识号.
uint32 HierarchyOffset_AndHasImposter; // 层次结构偏移和是否有Imposter的联合数据.
FNaniteInfo()
: RuntimeResourceID(0xFFFFFFFFu)
, HierarchyOffset_AndHasImposter(0xFFFFFFFFu)
{
}
FNaniteInfo(uint32 InRuntimeResourceID, int32 InHierarchyOffset, bool bHasImposter)
: RuntimeResourceID(InRuntimeResourceID)
, HierarchyOffset_AndHasImposter((InHierarchyOffset << 1) | (bHasImposter ? 1u : 0u))
{
}
};
// Nanite图元实例化信息.
struct FPrimitiveInstance
{
FMatrix InstanceToLocal;
FMatrix PrevInstanceToLocal;
FMatrix LocalToWorld;
FMatrix PrevLocalToWorld;
FVector4 NonUniformScale;
FVector4 InvNonUniformScaleAndDeterminantSign;
FBoxSphereBounds RenderBounds;
FBoxSphereBounds LocalBounds;
FVector4 LightMapAndShadowMapUVBias;
uint32 PrimitiveId; // 图元ID.
FNaniteInfo NaniteInfo; // Nanite信息.
uint32 LastUpdateSceneFrameNumber;
float PerInstanceRandom;
uint32 Flags;
};
(......)
// FInstanceUniformShaderParameters的声明. 需要和shader的FInstanceSceneData严格匹配.
BEGIN_GLOBAL_SHADER_PARAMETER_STRUCT(FInstanceUniformShaderParameters,ENGINE_API)
SHADER_PARAMETER(FMatrix, LocalToWorld)
SHADER_PARAMETER(FMatrix, PrevLocalToWorld)
SHADER_PARAMETER(FVector4, NonUniformScale)
SHADER_PARAMETER(FVector4, InvNonUniformScaleAndDeterminantSign)
SHADER_PARAMETER(FVector, LocalBoundsCenter)
SHADER_PARAMETER(uint32, PrimitiveId)
SHADER_PARAMETER(FVector, LocalBoundsExtent)
SHADER_PARAMETER(uint32, LastUpdateSceneFrameNumber)
SHADER_PARAMETER(uint32, NaniteRuntimeResourceID)
SHADER_PARAMETER(uint32, NaniteHierarchyOffset)
SHADER_PARAMETER(float, PerInstanceRandom)
SHADER_PARAMETER(uint32, Flags)
SHADER_PARAMETER(FVector4, LightMapAndShadowMapUVBias)
END_GLOBAL_SHADER_PARAMETER_STRUCT()
// 实例化场景着色数据.
struct FInstanceSceneShaderData
{
// 需要和SceneData.ush的GetInstanceData()相匹配.
enum { InstanceDataStrideInFloat4s = 10 };
FVector4 Data[InstanceDataStrideInFloat4s];
(......)
};
- NaniteStreamingManager
// Engine\Source\Runtime\Engine\Public\Rendering\NaniteStreamingManager.h
namespace Nanite
{
// 页面键值
struct FPageKey
{
// 运行时资源ID.
uint32 RuntimeResourceID;
// 页索引.
uint32 PageIndex;
};
// 键值哈希
FORCEINLINE uint32 GetTypeHash( const FPageKey& Key )
{
return Key.RuntimeResourceID * 0xFC6014F9u + Key.PageIndex * 0x58399E77u;
}
// 键值比较.
FORCEINLINE bool operator==( const FPageKey& A, const FPageKey& B )
{
return A.RuntimeResourceID == B.RuntimeResourceID && A.PageIndex == B.PageIndex;
}
FORCEINLINE bool operator!=(const FPageKey& A, const FPageKey& B)
{
return !(A == B);
}
// 去重(deduplication)【之前】的数据信息.
struct FGPUStreamingRequest
{
uint32 RuntimeResourceID;
uint32 PageIndex_NumPages;
uint32 Priority;
};
// 去重(deduplication)【之后】的数据信息.
struct FStreamingRequest
{
FPageKey Key;
uint32 Priority;
};
// 流式页面信息.
struct FStreamingPageInfo
{
FStreamingPageInfo* Next;
FStreamingPageInfo* Prev;
FPageKey RegisteredKey;
FPageKey ResidentKey;
uint32 GPUPageIndex;
uint32 LatestUpdateIndex;
uint32 RefCount;
};
// 根页信息.
struct FRootPageInfo
{
uint32 RuntimeResourceID;
uint32 NumClusters;
};
// 挂起页面.
struct FPendingPage
{
#if !WITH_EDITOR
uint8* MemoryPtr;
FIoRequest Request;
IAsyncReadFileHandle* AsyncHandle;
IAsyncReadRequest* AsyncRequest;
#endif
uint32 GPUPageIndex;
FPageKey InstallKey;
#if !UE_BUILD_SHIPPING
uint32 BytesLeftToStream;
#endif
};
// 异步信息.
struct FAsyncState
{
FRHIGPUBufferReadback* LatestReadbackBuffer = nullptr;
const uint32* LatestReadbackBufferPtr = nullptr;
uint32 NumReadyPages = 0;
bool bUpdateActive = false;
bool bBuffersTransitionedToWrite = false;
};
// Nanite流管理器.
class FStreamingManager : public FRenderResource
{
public:
FStreamingManager();
// 初始化/释放RHI资源.
virtual void InitRHI() override;
virtual void ReleaseRHI() override;
// 增删资源.
void Add( FResources* Resources );
void Remove( FResources* Resources );
// 须在Nanite任何渲染发生之前每帧调用一次, 也必须在EndUpdate[之前]调用。
ENGINE_API void BeginAsyncUpdate(FRDGBuilder& GraphBuilder);
// 须在Nanite任何渲染发生之前每帧调用一次, 也必须在BeginUpdate[之后]调用。
ENGINE_API void EndAsyncUpdate(FRDGBuilder& GraphBuilder);
ENGINE_API bool IsAsyncUpdateInProgress();
// 在添加最后一个请求后,每帧调用一次。
ENGINE_API void SubmitFrameStreamingRequests(FRDGBuilder& GraphBuilder);
(......)
private:
friend class FStreamingUpdateTask;
// 堆缓冲, 包含数据和上传缓冲.
struct FHeapBuffer
{
int32 TotalUpload = 0;
FGrowOnlySpanAllocator Allocator;
FScatterUploadBuffer UploadBuffer;
FRWByteAddressBuffer DataBuffer;
void Release()
{
UploadBuffer.Release();
DataBuffer.Release();
}
};
// FPackedCluster*, GeometryData { Index, Position, TexCoord, TangentX, TangentZ }*
FHeapBuffer ClusterPageData;
FHeapBuffer ClusterPageHeaders;
FScatterUploadBuffer ClusterFixupUploadBuffer;
FHeapBuffer Hierarchy; // 层次结构.
FHeapBuffer RootPages; // 根页面.
TRefCountPtr< FRDGPooledBuffer > StreamingRequestsBuffer;
uint32 MaxStreamingPages;
uint32 MaxPendingPages;
uint32 MaxPageInstallsPerUpdate;
uint32 MaxStreamingReadbackBuffers;
// 回传数据.
uint32 ReadbackBuffersWriteIndex;
uint32 ReadbackBuffersNumPending;
TArray<uint32> NextRootPageVersion;
uint32 NextUpdateIndex;
uint32 NumRegisteredStreamingPages;
uint32 NumPendingPages;
uint32 NextPendingPageIndex;
TArray<FRootPageInfo> RootPageInfos;
#if !UE_BUILD_SHIPPING
uint64 PrevUpdateTick;
#endif
TArray< FRHIGPUBufferReadback* > StreamingRequestReadbackBuffers;
TArray< FResources* > PendingAdds;
TMap< uint32, FResources* > RuntimeResourceMap;
TMap< FPageKey, FStreamingPageInfo* > RegisteredStreamingPagesMap; // This is updated immediately.
TMap< FPageKey, FStreamingPageInfo* > CommittedStreamingPageMap; // This update is deferred to the point where the page has been loaded and committed to memory.
TArray< FStreamingRequest > PrioritizedRequestsHeap;
FStreamingPageInfo StreamingPageLRU;
FStreamingPageInfo* StreamingPageInfoFreeList;
TArray< FStreamingPageInfo > StreamingPageInfos;
// 常驻流页面的修复信息, 需保持这个信息,以便能够释放页面。
TArray< FFixupChunk* > StreamingPageFixupChunks;
TArray< FPendingPage > PendingPages;
#if !WITH_EDITOR
TArray< uint8 > PendingPageStagingMemory;
#endif
TArray< uint8 > PendingPageStagingMemoryLZ;
FRequestsHashTable* RequestsHashTable = nullptr;
FStreamingPageUploader* PageUploader = nullptr;
FGraphEventArray AsyncTaskEvents;
FAsyncState AsyncState;
// 操作页面.
void CollectDependencyPages( FResources* Resources, TSet< FPageKey >& DependencyPages, const FPageKey& Key );
void SelectStreamingPages( FResources* Resources, TArray< FPageKey >& SelectedPages, TSet<FPageKey>& SelectedPagesSet, uint32 RuntimeResourceID, uint32 PageIndex, uint32 MaxSelectedPages );
// 注册/取消注册页面.
void RegisterStreamingPage( FStreamingPageInfo* Page, const FPageKey& Key );
void UnregisterPage( const FPageKey& Key );
void MovePageToFreeList( FStreamingPageInfo* Page );
void ApplyFixups( const FFixupChunk& FixupChunk, const FResources& Resources, uint32 PageIndex, uint32 GPUPageIndex );
bool ArePageDependenciesCommitted(uint32 RuntimeResourceID, uint32 PageIndex, uint32 DependencyPageStart, uint32 DependencyPageNum);
// 返回是否完成了任何工作且页面/层次缓冲区是否转换为计算可写状态.
bool ProcessNewResources( FRDGBuilder& GraphBuilder);
uint32 DetermineReadyPages();
void InstallReadyPages( uint32 NumReadyPages );
// 异步更新.
void AsyncUpdate();
void ClearStreamingRequestCount(FRDGBuilder& GraphBuilder, FRDGBufferUAVRef BufferUAVRef);
};
// Nanite流管理器声明.
extern ENGINE_API TGlobalResource< FStreamingManager > GStreamingManager;
}
- NaniteRender
// Engine\Source\Runtime\Renderer\Private\Nanite\NaniteRender.h
static constexpr uint32 NANITE_MAX_MATERIALS = 64;
static constexpr uint32 MAX_VIEWS_PER_CULL_RASTERIZE_PASS_BITS = 12;
static constexpr uint32 MAX_VIEWS_PER_CULL_RASTERIZE_PASS_MASK = ( ( 1 << MAX_VIEWS_PER_CULL_RASTERIZE_PASS_BITS ) - 1 );
static constexpr uint32 MAX_VIEWS_PER_CULL_RASTERIZE_PASS = ( 1 << MAX_VIEWS_PER_CULL_RASTERIZE_PASS_BITS );
(......)
// Nanite统一缓冲区参数.
BEGIN_GLOBAL_SHADER_PARAMETER_STRUCT(FNaniteUniformParameters, )
SHADER_PARAMETER(FIntVector4, SOAStrides)
SHADER_PARAMETER(FIntVector4, MaterialConfig) // .x mode, .yz grid size, .w unused
SHADER_PARAMETER(uint32, MaxNodes)
SHADER_PARAMETER(uint32, MaxVisibleClusters)
SHADER_PARAMETER(uint32, RenderFlags)
SHADER_PARAMETER(FVector4, RectScaleOffset) // xy: scale, zw: offset
SHADER_PARAMETER_SRV(ByteAddressBuffer, ClusterPageData)
SHADER_PARAMETER_SRV(ByteAddressBuffer, ClusterPageHeaders)
SHADER_PARAMETER_SRV(ByteAddressBuffer, VisibleClustersSWHW)
SHADER_PARAMETER_SRV(StructuredBuffer<uint>, VisibleMaterials)
SHADER_PARAMETER_TEXTURE(Texture2D<uint2>, MaterialRange)
SHADER_PARAMETER_TEXTURE(Texture2D<UlongType>, VisBuffer64)
SHADER_PARAMETER_TEXTURE(Texture2D<UlongType>, DbgBuffer64)
SHADER_PARAMETER_TEXTURE(Texture2D<uint>, DbgBuffer32)
END_SHADER_PARAMETER_STRUCT()
(......)
// 光栅化参数.
BEGIN_SHADER_PARAMETER_STRUCT( FRasterParameters, )
SHADER_PARAMETER_RDG_TEXTURE_UAV( RWTexture2D< uint >, OutDepthBuffer ) // 深度
SHADER_PARAMETER_RDG_TEXTURE_UAV( RWTexture2D< UlongType >, OutVisBuffer64 ) // 可见性
SHADER_PARAMETER_RDG_TEXTURE_UAV( RWTexture2D< UlongType >, OutDbgBuffer64 ) // 调试数据
SHADER_PARAMETER_RDG_TEXTURE_UAV( RWTexture2D< uint >, OutDbgBuffer32 )
SHADER_PARAMETER_RDG_TEXTURE_UAV( RWTexture2D< uint >, LockBuffer ) // 锁定缓冲
END_SHADER_PARAMETER_STRUCT()
// Nanite绘制命令信息.
class FNaniteCommandInfo
{
public:
static constexpr int32 MAX_STATE_BUCKET_ID = (1 << 14) - 1; // Must match NaniteDataDecode.ush
void SetStateBucketId(int32 InStateBucketId)
{
StateBucketId = InStateBucketId;
}
int32 GetStateBucketId() const
{
check(StateBucketId < MAX_STATE_BUCKET_ID);
return StateBucketId;
}
uint32 GetMaterialId() const
{
return GetMaterialId(GetStateBucketId());
}
static uint32 GetMaterialId(int32 StateBucketId)
{
float DepthId = GetDepthId(StateBucketId);
return *reinterpret_cast<uint32*>(&DepthId);
}
static float GetDepthId(int32 StateBucketId)
{
return float(StateBucketId + 1) / float(MAX_STATE_BUCKET_ID);
}
private:
// 将索引存储到对应FMeshDrawCommand的FScene::NaniteDrawCommands中.
int32 StateBucketId = INDEX_NONE;
};
struct MeshDrawCommandKeyFuncs;
// Nanite绘制命令列表上下文, 跟非Nanite模式的比较类型.
class FNaniteDrawListContext : public FMeshPassDrawListContext
{
public:
FNaniteDrawListContext(FRWLock& InNaniteDrawCommandLock, FStateBucketMap& InNaniteDrawCommands);
virtual FMeshDrawCommand& AddCommand(FMeshDrawCommand& Initializer, uint32 NumElements) override final;
virtual void FinalizeCommand(
const FMeshBatch& MeshBatch,
int32 BatchElementIndex,
int32 DrawPrimitiveId,
int32 ScenePrimitiveId,
ERasterizerFillMode MeshFillMode,
ERasterizerCullMode MeshCullMode,
FMeshDrawCommandSortKey SortKey,
EFVisibleMeshDrawCommandFlags Flags,
const FGraphicsMinimalPipelineStateInitializer& PipelineState,
const FMeshProcessorShaders* ShadersForDebugging,
FMeshDrawCommand& MeshDrawCommand
) override final;
(......)
private:
FRWLock* NaniteDrawCommandLock;
FStateBucketMap* NaniteDrawCommands; // Nanite绘制命令.
FNaniteCommandInfo CommandInfo; // Nanite命令信息.
FMeshDrawCommand MeshDrawCommandForStateBucketing;
};
// Nanite着色器父类.
class FNaniteShader : public FGlobalShader
{
public:
(......)
static bool ShouldCompilePermutation(const FGlobalShaderPermutationParameters& Parameters);
static void ModifyCompilationEnvironment(const FGlobalShaderPermutationParameters& Parameters, FShaderCompilerEnvironment& OutEnvironment;
};
// 指定深度绘制全屏的顶点着色器, 可在所有平台运行.
class FNaniteMaterialVS : public FNaniteShader
{
DECLARE_GLOBAL_SHADER(FNaniteMaterialVS);
BEGIN_SHADER_PARAMETER_STRUCT(FParameters, )
SHADER_PARAMETER(float, MaterialDepth)
END_SHADER_PARAMETER_STRUCT()
(......)
void GetShaderBindings(
const FScene* Scene,
ERHIFeatureLevel::Type FeatureLevel,
const FPrimitiveSceneProxy* PrimitiveSceneProxy,
const FMaterialRenderProxy& MaterialRenderProxy,
const FMaterial& Material,
const FMeshPassProcessorRenderState& DrawRenderState,
const FMeshMaterialShaderElementData& ShaderElementData,
FMeshDrawSingleShaderBindings& ShaderBindings) const
{
ShaderBindings.Add(NaniteUniformBuffer, DrawRenderState.GetNaniteUniformBuffer());
}
private:
LAYOUT_FIELD(FShaderParameter, MaterialDepth);
LAYOUT_FIELD(FShaderUniformBufferParameter, NaniteUniformBuffer);
};
// Nanite网格处理器.
class FNaniteMeshProcessor : public FMeshPassProcessor
{
public:
(......)
virtual void AddMeshBatch(const FMeshBatch& RESTRICT MeshBatch, uint64 BatchElementMask, const FPrimitiveSceneProxy* RESTRICT PrimitiveSceneProxy, int32 StaticMeshId = -1) override final;
private:
FMeshPassProcessorRenderState PassDrawRenderState;
};
// 创建Nanite网格处理器实例.
FMeshPassProcessor* CreateNaniteMeshProcessor(const FScene* Scene, const FSceneView* InViewIfDynamicMeshCommand, FMeshPassDrawListContext* InDrawListContext);
// Nanite材质表.
class FNaniteMaterialTables
{
public:
FNaniteMaterialTables(uint32 MaxMaterials = NANITE_MAX_MATERIALS);
~FNaniteMaterialTables();
void Release();
void UpdateBufferState(FRDGBuilder& GraphBuilder, uint32 NumPrimitives);
void Begin(FRHICommandListImmediate& RHICmdList, uint32 NumPrimitives, uint32 NumPrimitiveUpdates);
void* GetDepthTablePtr(uint32 PrimitiveIndex, uint32 EntryCount);
void Finish(FRHICommandListImmediate& RHICmdList);
FRHIShaderResourceView* GetDepthTableSRV() const { return DepthTableDataBuffer.SRV; }
private:
uint32 MaxMaterials = 0;
uint32 NumPrimitiveUpdates = 0;
uint32 NumDepthTableUpdates = 0;
uint32 NumHitProxyTableUpdates = 0;
// CPU及用于上传的数据缓冲.
FScatterUploadBuffer DepthTableUploadBuffer;
FRWByteAddressBuffer DepthTableDataBuffer;
FScatterUploadBuffer HitProxyTableUploadBuffer;
FRWByteAddressBuffer HitProxyTableDataBuffer;
};
namespace Nanite
{
// 光栅化技术.
enum class ERasterTechnique : uint8
{
LockBufferFallback = 0, // 使用备用锁定缓冲来近似没有64位原子(有竞争条件).
PlatformAtomics = 1, // 使用平台提供的64位原子.
NVAtomics = 2, // 使用Nv扩展提供的64位原子.
AMDAtomicsD3D11 = 3, // 使用AMD扩展(D3D11)提供的64位原子.
AMDAtomicsD3D12 = 4, // 使用AMD扩展(D3D12)提供的64位原子.
DepthOnly = 5, // 对深度使用32位原子, 没有额外负载.
NumTechniques
};
// 光栅化调度模式.
enum class ERasterScheduling : uint8
{
HardwareOnly = 0, // 只使用固定功能硬件的光栅化.
HardwareThenSoftware = 1, // 用硬件光栅化大三角形,用软件(comtue shader)光栅化小三角形.
HardwareAndSoftwareOverlap = 2, // 用硬件光栅化大三角形,重叠地用软件(comtue shader)光栅化小三角形.
};
// 输出缓冲模式. 当创建设备上下文时用来选择光栅化模式.
enum class EOutputBufferMode : uint8
{
VisBuffer, // 可见性缓冲, 默认模式, 用来输出ID和深度.
DepthOnly, // 仅光栅化深度到32位缓冲.
};
// 填充的视图.
struct FPackedView
{
FMatrix TranslatedWorldToView;
FMatrix TranslatedWorldToClip;
FMatrix ViewToClip;
FMatrix ClipToWorld;
FMatrix PrevTranslatedWorldToView;
FMatrix PrevTranslatedWorldToClip;
FMatrix PrevViewToClip;
FMatrix PrevClipToWorld;
FIntVector4 ViewRect;
FVector4 ViewSizeAndInvSize;
FVector4 ClipSpaceScaleOffset;
FVector4 PreViewTranslation;
FVector4 PrevPreViewTranslation;
FVector4 WorldCameraOrigin;
FVector4 ViewForwardAndNearPlane;
FVector2D LODScales;
float MinBoundsRadiusSq;
uint32 StreamingPriorityCategory_AndFlags;
FIntVector4 TargetLayerIdX_AndMipLevelY_AndNumMipLevelsZ;
FIntVector4 HZBTestViewRect; // In full resolution
// 计算LOD比例,假设视图大小和投影已经设置好。依赖全局变量GNaniteMaxPixelsPerEdge.
void UpdateLODScales();
};
// 裁剪上下文.
struct FCullingContext
{
FGlobalShaderMap* ShaderMap;
uint32 DrawPassIndex;
uint32 NumInstancesPreCull;
uint32 RenderFlags;
uint32 DebugFlags;
TRefCountPtr<IPooledRenderTarget> PrevHZB; // 如果非null, HZB裁剪将开启.
FIntRect HZBBuildViewRect;
bool bTwoPassOcclusion;
bool bSupportsMultiplePasses;
FIntVector4 SOAStrides;
FRDGBufferRef MainRasterizeArgsSWHW;
FRDGBufferRef PostRasterizeArgsSWHW;
FRDGBufferRef SafeMainRasterizeArgsSWHW;
FRDGBufferRef SafePostRasterizeArgsSWHW;
FRDGBufferRef MainAndPostPassPersistentStates;
FRDGBufferRef VisibleClustersSWHW;
FRDGBufferRef OccludedInstances;
FRDGBufferRef OccludedInstancesArgs;
FRDGBufferRef TotalPrevDrawClustersBuffer;
FRDGBufferRef StreamingRequests;
FRDGBufferRef ViewsBuffer;
FRDGBufferRef InstanceDrawsBuffer;
FRDGBufferRef StatsBuffer;
};
// 光栅化上下文.
struct FRasterContext
{
FGlobalShaderMap* ShaderMap;
FVector2D RcpViewSize;
FIntPoint TextureSize;
ERasterTechnique RasterTechnique;
ERasterScheduling RasterScheduling;
FRasterParameters Parameters;
FRDGTextureRef LockBuffer;
FRDGTextureRef DepthBuffer;
FRDGTextureRef VisBuffer64;
FRDGTextureRef DbgBuffer64;
FRDGTextureRef DbgBuffer32;
uint32 VisualizeModeBitMask;
bool VisualizeActive;
};
// 光栅化结果.
struct FRasterResults
{
FIntVector4 SOAStrides;
uint32 MaxVisibleClusters;
uint32 MaxNodes;
uint32 RenderFlags;
FRDGBufferRef ViewsBuffer{};
FRDGBufferRef VisibleClustersSWHW{};
FRDGTextureRef VisBuffer64{};
FRDGTextureRef DbgBuffer64{};
FRDGTextureRef DbgBuffer32{};
FRDGTextureRef MaterialDepth{};
FRDGTextureRef NaniteMask{};
FRDGTextureRef VelocityBuffer{};
TArray<FVisualizeResult, TInlineAllocator<32>> Visualizations;
};
// 初始化裁剪上下文.
FCullingContext InitCullingContext(FRDGBuilder& GraphBuilder, const FScene& Scene, ...);
// 初始化光栅化上下文.
FRasterContext InitRasterContext(FRDGBuilder& GraphBuilder, ERHIFeatureLevel::Type FeatureLevel, ...);
// 填充的视图参数.
struct FPackedViewParams
{
FViewMatrices ViewMatrices;
FViewMatrices PrevViewMatrices;
FIntRect ViewRect;
FIntPoint RasterContextSize;
uint32 StreamingPriorityCategory = 0;
float MinBoundsRadius = 0.0f;
float LODScaleFactor = 1.0f;
uint32 Flags = 0;
int32 TargetLayerIndex = 0;
int32 PrevTargetLayerIndex = INDEX_NONE;
int32 TargetMipLevel = 0;
int32 TargetMipCount = 1;
FIntRect HZBTestViewRect = {0, 0, 0, 0};
};
FPackedView CreatePackedView( const FPackedViewParams& Params );
FPackedView CreatePackedViewFromViewInfo(const FViewInfo& View, FIntPoint RasterContextSize, ...);
// 光栅化状态.
struct FRasterState
{
bool bNearClip = true; // 是否开启Near平面裁剪.
ERasterizerCullMode CullMode = CM_CW; // 光栅化裁剪模式, 默认是顺时针.
};
// 带裁剪的光栅化.
void CullRasterize(
FRDGBuilder& GraphBuilder,
const FScene& Scene,
const TArray<FPackedView, SceneRenderingAllocator>& Views,
FCullingContext& CullingContext,
const FRasterContext& RasterContext,
const FRasterState& RasterState = FRasterState(),
const TArray<FInstanceDraw, SceneRenderingAllocator>* OptionalInstanceDraws = nullptr,
bool bExtractStats = false
);
// 光栅化到虚拟阴影图(virtual shadow map)集
void CullRasterize(
FRDGBuilder& GraphBuilder,
const FScene& Scene,
const TArray<FPackedView, SceneRenderingAllocator>& Views,
uint32 NumPrimaryViews, // Number of non-mip views
FCullingContext& CullingContext,
const FRasterContext& RasterContext,
const FRasterState& RasterState = FRasterState(),
const TArray<FInstanceDraw, SceneRenderingAllocator>* OptionalInstanceDraws = nullptr,
FVirtualShadowMapArray* VirtualShadowMapArray = nullptr,
bool bExtractStats = false
);
// 解压光栅化结果.
void ExtractResults(FRDGBuilder& GraphBuilder, const FCullingContext& CullingContext, const FRasterContext& RasterContext, FRasterResults& RasterResults);
// 触发阴影图.
void EmitShadowMap(FRDGBuilder& GraphBuilder, const FRasterContext& RasterContext, const FRDGTextureRef DepthBuffer, ...);
// 触发立方体图阴影.
void EmitCubemapShadow(FRDGBuilder& GraphBuilder, const FRasterContext& RasterContext, const FRDGTextureRef CubemapDepthBuffer, ...);
// 触发深度目标.
void EmitDepthTargets(FRDGBuilder& GraphBuilder, const FScene& Scene, const FViewInfo& View, ...);
// 绘制BasePass.
void DrawBasePass(FRDGBuilder& GraphBuilder, const FSceneTextures& SceneTextures, const FDBufferTextures& DBufferTextures, const FScene& Scene, const FViewInfo& View, const FRasterResults& RasterResults
);
// 绘制Lumen网格捕捉通道.
void DrawLumenMeshCapturePass(FRDGBuilder& GraphBuilder, const FScene& Scene, ...);
(......)
}
// 是否需要渲染Nanite.
extern bool ShouldRenderNanite(const FScene* Scene, const FViewInfo& View, bool bCheckForAtomicSupport = true);
- NaniteSceneProxy
// Engine\Source\Runtime\Engine\Public\NaniteSceneProxy.h
namespace Nanite
{
// Nanite场景代理父类.
class FSceneProxyBase : public FPrimitiveSceneProxy
{
public:
struct FMaterialSection
{
UMaterialInterface* Material = nullptr;
int32 MaterialIndex = INDEX_NONE;
};
public:
ENGINE_API SIZE_T GetTypeHash() const override;
FSceneProxyBase(UPrimitiveComponent* Component)
: FPrimitiveSceneProxy(Component)
{
bIsNaniteMesh = true;
bAlwaysVisible = true;
}
// 检测是否满足Nanite渲染的条件: 不透明物体, 不是贴花, 不是Masked, 不是法线半透明, 不是分离半透明.
static bool IsNaniteRenderable(FMaterialRelevance MaterialRelevance)
{
return MaterialRelevance.bOpaque &&
!MaterialRelevance.bDecal &&
!MaterialRelevance.bMasked &&
!MaterialRelevance.bNormalTranslucency &&
!MaterialRelevance.bSeparateTranslucency;
}
virtual bool CanBeOccluded() const override;
inline const TArray<FMaterialSection>& GetMaterialSections() const;
inline int32 GetMaterialMaxIndex() const;
virtual const TArray<FPrimitiveInstance>* GetPrimitiveInstances() const;
virtual TArray<FPrimitiveInstance>* GetPrimitiveInstances();
virtual uint8 GetCurrentFirstLODIdx_RenderThread() const override;
protected:
ENGINE_API void DrawStaticElementsInternal(FStaticPrimitiveDrawInterface* PDI, const FLightCacheInterface* LCI);
protected:
TArray<FMaterialSection> MaterialSections;
TArray<FPrimitiveInstance> Instances;
int32 MaterialMaxIndex = INDEX_NONE;
};
// Nanite场景代理.
class FSceneProxy : public FSceneProxyBase
{
public:
FSceneProxy(UStaticMeshComponent* Component);
FSceneProxy(UInstancedStaticMeshComponent* Component);
FSceneProxy(UHierarchicalInstancedStaticMeshComponent* Component);
virtual ~FSceneProxy() = default;
public:
// FPrimitiveSceneProxy接口.
virtual FPrimitiveViewRelevance GetViewRelevance(const FSceneView* View) const override;
virtual void GetLightRelevance(const FLightSceneProxy* LightSceneProxy, bool& bDynamic, bool& bRelevant, bool& bLightMapped, bool& bShadowMapped) const override;
// 获取静态或动态网格元素.
virtual void DrawStaticElements(FStaticPrimitiveDrawInterface* PDI) override;
virtual void GetDynamicMeshElements(const TArray<const FSceneView*>& Views, const FSceneViewFamily& ViewFamily, uint32 VisibilityMap, FMeshElementCollector& Collector) const override;
// 光追相关接口.
#if RHI_RAYTRACING
virtual bool IsRayTracingRelevant() const { return true; }
virtual bool IsRayTracingStaticRelevant() const { return false; }
virtual void GetDynamicRayTracingInstances(FRayTracingMaterialGatheringContext& Context, TArray<struct FRayTracingInstance>& OutRayTracingInstances) override;
#endif
virtual uint32 GetMemoryFootprint() const override;
virtual void GetLCIs(FLCIArray& LCIs) override
{
FLightCacheInterface* LCI = &MeshInfo;
LCIs.Add(LCI);
}
// 距离场接口.
virtual void GetDistancefieldAtlasData(const FDistanceFieldVolumeData*& OutDistanceFieldData, float& SelfShadowBias) const override;
virtual void GetDistancefieldInstanceData(TArray<FMatrix>& ObjectLocalToWorldTransforms) const override;
virtual bool HasDistanceFieldRepresentation() const override;
// GI接口.
virtual const FCardRepresentationData* GetMeshCardRepresentation() const override;
virtual int32 GetLightMapCoordinateIndex() const override;
// 获取静态网格.
const UStaticMesh* GetStaticMesh() const
{
return StaticMesh;
}
protected:
virtual void CreateRenderThreadResources() override;
class FMeshInfo : public FLightCacheInterface
{
public:
FMeshInfo(const UStaticMeshComponent* InComponent);
// FLightCacheInterface.
virtual FLightInteraction GetInteraction(const FLightSceneProxy* LightSceneProxy) const override;
private:
TArray<FGuid> IrrelevantLights;
};
bool IsCollisionView(const FEngineShowFlags& EngineShowFlags, bool& bDrawSimpleCollision, bool& bDrawComplexCollision) const;
protected:
FMeshInfo MeshInfo;
FResources* Resources = nullptr;
const FStaticMeshRenderData* RenderData;
const FDistanceFieldVolumeData* DistanceFieldData;
const FCardRepresentationData* CardRepresentationData;
FMaterialRelevance MaterialRelevance;
uint32 bReverseCulling : 1;
uint32 bHasMaterialErrors : 1;
const UStaticMesh* StaticMesh = nullptr;
#if RHI_RAYTRACING
TArray<FRayTracingGeometry*> RayTracingGeometries;
#endif
(......)
};
} // namespace Nanite
- RenderUtils
// Engine\Source\Runtime\RenderCore\Public\RenderUtils.h
(......)
// 检测平台是否支持Nanite渲染.
RENDERCORE_API bool DoesPlatformSupportNanite(EShaderPlatform Platform)
{
// 确保当前平台定义了DDPI(FGenericDataDrivenShaderPlatformInfo).
const bool bValidPlatform = FDataDrivenShaderPlatformInfo::IsValid(Platform);
// Nanite需要GPUScene.
const bool bSupportGPUScene = FDataDrivenShaderPlatformInfo::GetSupportsGPUScene(Platform);
// Nanite特定检测.
const bool bSupportNanite = FDataDrivenShaderPlatformInfo::GetSupportsNanite(Platform);
const bool bFullCheck = bValidPlatform && bSupportGPUScene && bSupportNanite;
return bFullCheck;
}
// 使用Nanite, 如果成功将返回true.
inline bool UseNanite(EShaderPlatform ShaderPlatform, bool bCheckForAtomicSupport = true);
// 使用VSM, 成功返回true.
inline bool UseVirtualShadowMaps(EShaderPlatform ShaderPlatform, const FStaticFeatureLevel FeatureLevel);
// 使用非Nanite的VSM, 成功返回true. 前提是r.Shadow.Virtual.NonNaniteVSM不为0, 且UseVirtualShadowMaps为true.
inline bool UseNonNaniteVirtualShadowMaps(EShaderPlatform ShaderPlatform, const FStaticFeatureLevel FeatureLevel);
- 其它
// Engine\Source\Runtime\Engine\Classes\Components\StaticMeshComponent.h
class ENGINE_API UStaticMeshComponent : public UMeshComponent
{
(......)
uint8 bDisplayNaniteProxyMesh:1; // 对于nanite启用的网格,如果为true,将只显示代理网格.
(......)
};
// Engine\Source\Runtime\Engine\Public\PrimitiveSceneProxy.h
class FPrimitiveSceneProxy
{
inline bool IsNaniteMesh() const
{
return bIsNaniteMesh;
}
(......)
private:
uint8 bIsNaniteMesh : 1; // 是否Nanite网格.
(......)
};
// 如果指定网格可通过Nanite渲染, 则返回true.
ENGINE_API extern bool SupportsNaniteRendering(const FVertexFactory* RESTRICT VertexFactory, const FPrimitiveSceneProxy* RESTRICT PrimitiveSceneProxy);
ENGINE_API extern bool SupportsNaniteRendering(const FVertexFactory* RESTRICT VertexFactory, const FPrimitiveSceneProxy* RESTRICT PrimitiveSceneProxy, const class FMaterialRenderProxy* MaterialRenderProxy, ERHIFeatureLevel::Type FeatureLevel);
// Engine\Source\Runtime\Renderer\Public\MeshPassProcessor.h
struct FMeshPassProcessorRenderState
{
public:
void SetNaniteUniformBuffer(FRHIUniformBuffer* InNaniteUniformBuffer);
FRHIUniformBuffer* GetNaniteUniformBuffer() const;
(......)
private:
FRHIUniformBuffer* NaniteUniformBuffer = nullptr; // Nanite统一缓冲区.
(......)
};
// Engine\Source\Runtime\RenderCore\Public\VertexFactory.h
// 顶点工厂标记.
enum class EVertexFactoryFlags : uint32
{
None = 0u,
UsedWithMaterials = 1u << 1,
SupportsStaticLighting = 1u << 2,
SupportsDynamicLighting = 1u << 3,
SupportsPrecisePrevWorldPos = 1u << 4,
SupportsPositionOnly = 1u << 5,
SupportsCachingMeshDrawCommands = 1u << 6,
SupportsPrimitiveIdStream = 1u << 7,
SupportsNaniteRendering = 1u << 8, // 是否支持Nanite渲染.
};
// 是否支持Nanite渲染.
bool SupportsNaniteRendering() const { return HasFlags(EVertexFactoryFlags::SupportsNaniteRendering); }
// Engine\Source\Runtime\RHI\Public\RHIDefinitions.h
// 通用的数据驱动着色器平台信息.
class RHI_API FGenericDataDrivenShaderPlatformInfo
{
static FORCEINLINE_DEBUGGABLE const bool GetSupportsNanite(const FStaticShaderPlatform Platform)
{
return Infos[Platform].bSupportsNanite;
}
(......)
};
6.4.3.3 Nanite渲染流程
Nanite的主要渲染步骤也是发生在FDeferredShadingSceneRenderer::Render,下面将阐述Nanite相关的步骤以及前几篇涉及的重要步骤:
void FDeferredShadingSceneRenderer::Render(FRDGBuilder& GraphBuilder)
{
// 尝试使用Nanite渲染。
const bool bNaniteEnabled = UseNanite(ShaderPlatform) && ViewFamily.EngineShowFlags.NaniteMeshes;
// 更新图元场景信息.
Scene->UpdateAllPrimitiveSceneInfos(GraphBuilder, true);
// 使用GPUScene.
FGPUSceneScopeBeginEndHelper GPUSceneScopeBeginEndHelper(Scene->GPUScene, GPUSceneDynamicContext, Scene);
bool bVisualizeNanite = false;
if (bNaniteEnabled) // Nanite开启才执行
{
// 更新Nanite全局资源. 需要为Nanite管理乱序的缓冲区。
Nanite::GGlobalResources.Update(GraphBuilder);
// 开始异步更新Nanite流管理器.
Nanite::GStreamingManager.BeginAsyncUpdate(GraphBuilder);
// 处理Nanite可视化模式.
FNaniteVisualizationData& NaniteVisualization = GetNaniteVisualizationData();
if (Views.Num() > 0)
{
const FName& NaniteViewMode = Views[0].CurrentNaniteVisualizationMode;
if (NaniteVisualization.Update(NaniteViewMode))
{
ViewFamily.EngineShowFlags.SetVisualizeNanite(true);
}
bVisualizeNanite = NaniteVisualization.IsActive() && ViewFamily.EngineShowFlags.VisualizeNanite;
}
}
(......)
// 是否需要应用Nanite材质.
const bool bShouldApplyNaniteMaterials
= !ViewFamily.EngineShowFlags.ShaderComplexity
&& !ViewFamily.UseDebugViewPS()
&& !ViewFamily.EngineShowFlags.Wireframe
&& !ViewFamily.EngineShowFlags.LightMapDensity;
(......)
// 实例化裁剪管理器.
FInstanceCullingManager InstanceCullingManager(GInstanceCullingManagerResources, Scene->GPUScene.IsEnabled());
bDoInitViewAftersPrepass = InitViews(GraphBuilder, ..., InstanceCullingManager);
(......)
// 处理GPUScene.
{
(......)
// 更新GPUScene.
Scene->GPUScene.Update(GraphBuilder, *Scene);
(......)
// 上传动态图元着色器数据到GPU.
for (int32 ViewIndex = 0; ViewIndex < Views.Num(); ViewIndex++)
{
FViewInfo& View = Views[ViewIndex];
Scene->GPUScene.UploadDynamicPrimitiveShaderDataForView(GraphBuilder, Scene, View);
}
// 实例化裁剪.
{
InstanceCullingManager.CullInstances(GraphBuilder, Scene->GPUScene);
}
(......)
}
(......)
if (bNaniteEnabled)
{
Nanite::ListStatFilters(this);
// 必须在每帧的Nanite渲染之前调用.
Nanite::GStreamingManager.EndAsyncUpdate(GraphBuilder);
}
(......)
// 提前深度通道.
RenderPrePass(GraphBuilder, SceneTextures.Depth.Target, InstanceCullingManager);
(......)
// Nanite光栅化
TArray<Nanite::FRasterResults, TInlineAllocator<2>> NaniteRasterResults;
if (bNaniteEnabled && Views.Num() > 0)
{
LLM_SCOPE_BYTAG(Nanite);
NaniteRasterResults.AddDefaulted(Views.Num());
RDG_GPU_STAT_SCOPE(GraphBuilder, NaniteRaster);
const FIntPoint RasterTextureSize = SceneTextures.Depth.Target->Desc.Extent;
const FViewInfo& PrimaryViewRef = Views[0];
const FIntRect PrimaryViewRect = PrimaryViewRef.ViewRect;
// 主光栅化视图
{
Nanite::FRasterState RasterState;
Nanite::FRasterContext RasterContext = Nanite::InitRasterContext(GraphBuilder, FeatureLevel, RasterTextureSize);
const bool bTwoPassOcclusion = true;
const bool bUpdateStreaming = true;
const bool bSupportsMultiplePasses = false;
const bool bForceHWRaster = RasterContext.RasterScheduling == Nanite::ERasterScheduling::HardwareOnly;
const bool bPrimaryContext = true;
const bool bDiscardNonMoving = ViewFamily.EngineShowFlags.DrawOnlyVSMInvalidatingGeo != 0;
// 遍历所有view
for (int32 ViewIndex = 0; ViewIndex < Views.Num(); ViewIndex++)
{
const FViewInfo& View = Views[ViewIndex];
// 初始化裁剪上下文.
Nanite::FCullingContext CullingContext = Nanite::InitCullingContext(
GraphBuilder,
*Scene,
!bIsEarlyDepthComplete ? View.PrevViewInfo.NaniteHZB : View.PrevViewInfo.HZB,
View.ViewRect,
bTwoPassOcclusion,
bUpdateStreaming,
bSupportsMultiplePasses,
bForceHWRaster,
bPrimaryContext,
bDiscardNonMoving
);
static FString EmptyFilterName = TEXT(""); // Empty filter represents primary view.
const bool bExtractStats = Nanite::IsStatFilterActive(EmptyFilterName);
Nanite::FPackedView PackedView = Nanite::CreatePackedViewFromViewInfo(View, RasterTextureSize, VIEW_FLAG_HZBTEST, /*StreamingPriorityCategory*/ 3);
// 带裁剪的光栅化.
Nanite::CullRasterize(
GraphBuilder,
*Scene,
{ PackedView },
CullingContext,
RasterContext,
RasterState,
/*OptionalInstanceDraws*/ nullptr,
bExtractStats
);
Nanite::FRasterResults& RasterResults = NaniteRasterResults[ViewIndex];
// 需要提前深度, 则渲染之.
if (bNeedsPrePass)
{
Nanite::EmitDepthTargets(
GraphBuilder,
*Scene,
Views[ViewIndex],
CullingContext.SOAStrides,
CullingContext.VisibleClustersSWHW,
CullingContext.ViewsBuffer,
SceneTextures.Depth.Target,
RasterContext.VisBuffer64,
RasterResults.MaterialDepth,
RasterResults.NaniteMask,
RasterResults.VelocityBuffer,
bNeedsPrePass
);
}
// 构建层次深度缓冲HZB.
if (!bIsEarlyDepthComplete && bTwoPassOcclusion && View.ViewState)
{
// 不会有一个针对后通道的完整的场景深度,所以不能使用完整的HZB主通道, 否则它将干扰后通道HZB销毁遮挡剔除。
RDG_EVENT_SCOPE(GraphBuilder, "Nanite::BuildHZB");
FRDGTextureRef SceneDepth = SystemTextures.Black;
FRDGTextureRef GraphHZB = nullptr;
// 最大程度地构建HZB.
BuildHZBFurthest(
GraphBuilder,
SceneDepth,
RasterContext.VisBuffer64,
PrimaryViewRect,
FeatureLevel,
ShaderPlatform,
TEXT("Nanite.HZB"),
/* OutFurthestHZBTexture = */ &GraphHZB );
GraphBuilder.QueueTextureExtraction( GraphHZB, &View.ViewState->PrevFrameViewInfo.NaniteHZB );
}
Nanite::ExtractResults(GraphBuilder, CullingContext, RasterContext, RasterResults);
}
}
}
(......)
// 渲染Nanite的BasePass.
{
RenderBasePass(GraphBuilder, SceneTextures, DBufferTextures, BasePassDepthStencilAccess, ForwardScreenSpaceShadowMaskTexture, InstanceCullingManager);
AddServiceLocalQueuePass(GraphBuilder);
if (bNaniteEnabled && bShouldApplyNaniteMaterials)
{
for (int32 ViewIndex = 0; ViewIndex < Views.Num(); ++ViewIndex)
{
const FViewInfo& View = Views[ViewIndex];
Nanite::FRasterResults& RasterResults = NaniteRasterResults[ViewIndex];
// 如果没有提前绘制深度, 则现在绘制深度
if (!bNeedsPrePass)
{
Nanite::EmitDepthTargets(
GraphBuilder,
*Scene,
Views[ViewIndex],
RasterResults.SOAStrides,
RasterResults.VisibleClustersSWHW,
RasterResults.ViewsBuffer,
SceneTextures.Depth.Target,
RasterResults.VisBuffer64,
RasterResults.MaterialDepth,
RasterResults.NaniteMask,
RasterResults.VelocityBuffer,
bNeedsPrePass
);
}
// 绘制BasePass.
Nanite::DrawBasePass(
GraphBuilder,
SceneTextures,
DBufferTextures,
*Scene,
View,
RasterResults
);
}
}
if (!bAllowReadOnlyDepthBasePass)
{
AddResolveSceneDepthPass(GraphBuilder, Views, SceneTextures.Depth);
}
(......)
}
(......)
if (bNaniteEnabled)
{
// 计算体积雾.
if (!bOcclusionBeforeBasePass)
{
ComputeVolumetricFog(GraphBuilder);
}
// 提交帧流请求.
Nanite::GStreamingManager.SubmitFrameStreamingRequests(GraphBuilder);
}
(......)
// 渲染延迟光源.
RenderLights(GraphBuilder, SceneTextures, ...);
(......)
// 渲染半透明物体.
RenderTranslucency(GraphBuilder, SceneTextures, ...);
(......)
// 后处理
AddPostProcessingPasses(GraphBuilder, View, PostProcessingInputs, NaniteResults, InstanceCullingManager);
(......)
}
由此可见,Nanite的渲染流程和普通模式比较类型,都是先更新图元数据、GPUScene、裁剪数据,然后渲染BasePass和Lighting,最后是半透明和后处理。不过也存在与普通模式不同点,如增加了GStreamingManager、FInstanceCullingManager、构建HZB、Nanite光栅化等阶段。下面借助RenderDoc截取示例工程AncientGame以展示UE5相关的主要步骤:
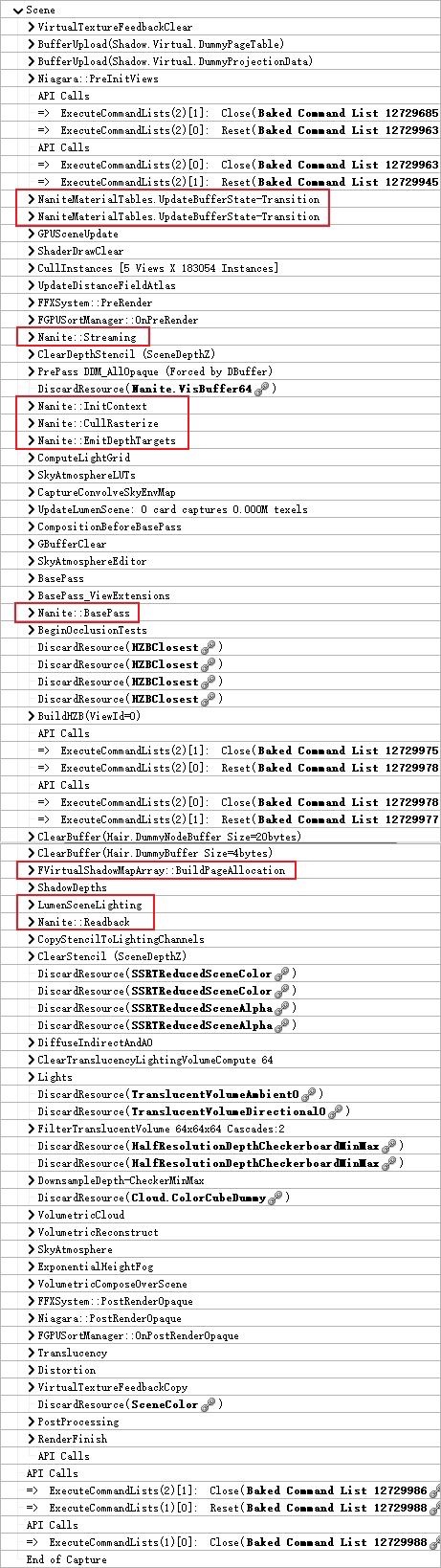
RenderDoc截取的UE5渲染过程,其中红框处是UE5相关的步骤。
6.4.3.4 Nanite裁剪
Nanite的实例化裁剪由FInstanceCullingManager担当,贯穿在FDeferredShadingSceneRenderer::Render的整个过程。下面是它及相关类型的定义和声明:
// Engine\Source\Runtime\Engine\Public\SceneManagement.h
// 实例化裁剪管理资源, 用于FInstanceCullingManager中.
class FInstanceCullingManagerResources : public FRenderResource
{
public:
// 最大非直接绘制实例数量是1024*1024=104万个.
static constexpr uint32 MaxIndirectInstances = 1024 * 1024;
// 初始化和释放RHI资源.
virtual void InitRHI() override;
virtual void ReleaseRHI() override;
// 获取数据接口.
FRHIBuffer* GetInstancesIdBuffer() const { return InstanceIdsBuffer.Buffer; }
FRHIShaderResourceView* GetInstancesIdBufferSrv() const { return InstanceIdsBuffer.SRV.GetReference(); }
FRHIShaderResourceView* GetPageInfoBufferSrv() const { return PageInfoBuffer.SRV.GetReference(); }
FUnorderedAccessViewRHIRef GetInstancesIdBufferUav() const { return InstanceIdsBuffer.UAV; }
FUnorderedAccessViewRHIRef GetPageInfoBufferUav() const { return PageInfoBuffer.UAV; }
private:
FRWBuffer PageInfoBuffer; // 页面信息缓冲.
FRWBuffer InstanceIdsBuffer; // 实例化ID缓冲.
};
// 全局FInstanceCullingManagerResources对象.
extern ENGINE_API TGlobalResource<FInstanceCullingManagerResources> GInstanceCullingManagerResources;
// Engine\Source\Runtime\Renderer\Private\InstanceCulling\InstanceCullingManager.h
// 实例化裁剪中间数据.
class FInstanceCullingIntermediate
{
public:
// 每个注册视图对应的每个Instance可见性位, 它被CullInstances接口处理.
FRDGBufferRef VisibleInstanceFlags = nullptr;
// 所有实例ID扩展所使用的写偏移量, 用于在全局实例ID缓冲区中分配空间. 被CullInstances初始化为0.
FRDGBufferRef InstanceIdOutOffsetBuffer = nullptr;
// 实例化数量.
int32 NumInstances = 0;
// 视图数量.
int32 NumViews = 0;
};
// 实例化裁剪结果.
struct FInstanceCullingResult
{
// 非直接绘制参数缓冲.
FRDGBufferRef DrawIndirectArgsBuffer = nullptr;
// 实例化ID偏移缓冲.
FRDGBufferRef InstanceIdOffsetBuffer = nullptr;
// 获取绘制参数到FInstanceCullingDrawParams中.
void GetDrawParameters(FInstanceCullingDrawParams &OutParams) const
{
OutParams.DrawIndirectArgsBuffer = DrawIndirectArgsBuffer;
OutParams.InstanceIdOffsetBuffer = InstanceIdOffsetBuffer;
}
// 带检测地获取绘制参数.
static void CondGetDrawParameters(const FInstanceCullingResult* InstanceCullingResult, FInstanceCullingDrawParams& OutParams)
{
if (InstanceCullingResult)
{
InstanceCullingResult->GetDrawParameters(OutParams);
}
else
{
OutParams.DrawIndirectArgsBuffer = nullptr;
OutParams.InstanceIdOffsetBuffer = nullptr;
}
}
};
// 管理所有实例绘制的非直接参数和裁剪作业的分配, 使用GPUScene裁剪.
class FInstanceCullingManager
{
public:
FInstanceCullingManager(FInstanceCullingManagerResources& InResources, bool bInIsEnabled);
// 图元展开后的最大平均实例数.
static constexpr uint32 MaxAverageInstanceFactor = 128;
bool IsEnabled() const { return bIsEnabled; }
// 注册需要裁剪的视图, 返回视图的id.
int32 RegisterView(const Nanite::FPackedViewParams& Params);
int32 RegisterView(const FViewInfo& ViewInfo);
// 裁剪实例, 需要在视图被初始化和注册之后, 需要在GPUScene被更新之后且渲染指令被提交之前.
void CullInstances(FRDGBuilder& GraphBuilder, FGPUScene& GPUScene);
// 由CullInstances填充, 被用于执行最终裁剪和渲染之时.
FInstanceCullingIntermediate CullingIntermediate;
private:
FInstanceCullingManagerResources& Resources;
TArray<Nanite::FPackedView> CullingViews;
bool bIsEnabled;
(....)
};
接下来分析FInstanceCullingManager::CullInstances的代码:
// Engine\Source\Runtime\Renderer\Private\InstanceCulling\InstanceCullingManager.cpp
void FInstanceCullingManager::CullInstances(FRDGBuilder& GraphBuilder, FGPUScene& GPUScene)
{
#if GPUCULL_TODO
// 获取视图和实例化数量.
int32 NumViews = CullingViews.Num();
int32 NumInstances = GPUScene.InstanceDataAllocator.GetMaxSize();
RDG_EVENT_SCOPE(GraphBuilder, "CullInstances [%d Views X %d Instances]", NumViews, NumInstances);
(......)
TArray<uint32> NullArray;
NullArray.AddZeroed(1);
// 初始化裁剪中间数据CullingIntermediate.
CullingIntermediate.InstanceIdOutOffsetBuffer = CreateStructuredBuffer(GraphBuilder, TEXT("InstanceCulling.OutputOffsetBufferOut"), NullArray);
int32 NumInstanceFlagWords = FMath::DivideAndRoundUp(NumInstances, int32(sizeof(uint32) * 8));
CullingIntermediate.NumInstances = NumInstances;
CullingIntermediate.NumViews = NumViews;
if (NumInstances && NumViews) // 视图数量和实例化数量同时大于0才需要GPU裁剪.
{
// 为每个视图的每个实例创建一个缓冲区记录一个位,
CullingIntermediate.VisibleInstanceFlags = GraphBuilder.CreateBuffer(FRDGBufferDesc::CreateStructuredDesc(sizeof(uint32), NumInstanceFlagWords * NumViews), TEXT("InstanceCulling.VisibleInstanceFlags"));
FRDGBufferUAVRef VisibleInstanceFlagsUAV = GraphBuilder.CreateUAV(CullingIntermediate.VisibleInstanceFlags);
if (CVarCullInstances.GetValueOnRenderThread() != 0)
{
// 清理UAV.
AddClearUAVPass(GraphBuilder, VisibleInstanceFlagsUAV, 0);
// 处理裁剪实例CS的参数.
FCullInstancesCs::FParameters* PassParameters = GraphBuilder.AllocParameters<FCullInstancesCs::FParameters>();
// 从GPUScene获取实例化和图元数据.
PassParameters->GPUSceneInstanceSceneData = GPUScene.InstanceDataBuffer.SRV;
PassParameters->GPUScenePrimitiveSceneData = GPUScene.PrimitiveBuffer.SRV;
PassParameters->InstanceDataSOAStride = GPUScene.InstanceDataSOAStride;
PassParameters->NumInstances = NumInstances;
PassParameters->NumInstanceFlagWords = NumInstanceFlagWords;
// GPU侧View的类型是Nanite::FPackedView.
// GPU侧InViews的类型是StructuredBuffer< Nanite::FPackedView >.
PassParameters->InViews = GraphBuilder.CreateSRV(CreateStructuredBuffer(GraphBuilder, TEXT("InstanceCulling.CullingViews"), CullingViews));
PassParameters->NumViews = NumViews;
// 存储可见性结果的缓冲区.
PassParameters->InstanceVisibilityFlagsOut = VisibleInstanceFlagsUAV;
// CS用的是FCullInstancesCs, 后面再解析之.
auto ComputeShader = GetGlobalShaderMap(GMaxRHIFeatureLevel)->GetShader<FCullInstancesCs>();
// 增加裁剪的CS Pass.
FComputeShaderUtils::AddPass(
GraphBuilder,
RDG_EVENT_NAME("CullInstancesCs"),
ComputeShader,
PassParameters,
FComputeShaderUtils::GetGroupCount(NumInstances, FCullInstancesCs::NumThreadsPerGroup)
);
}
else // 视图数量和实例化数量都是0
{
// 所有都清理成可见.
AddClearUAVPass(GraphBuilder, VisibleInstanceFlagsUAV, 0xFFFFFFFF);
}
}
#endif // GPUCULL_TODO
}
上面的逻辑就是构建裁剪着色器FCullInstancesCs的参数,调用FComputeShaderUtils::AddPass进行裁剪工作。下面继续分析FCullInstancesCs的代码:
// Engine\Source\Runtime\Renderer\Private\InstanceCulling\InstanceCullingManager.cpp
class FCullInstancesCs : public FGlobalShader
{
DECLARE_GLOBAL_SHADER(FCullInstancesCs);
SHADER_USE_PARAMETER_STRUCT(FCullInstancesCs, FGlobalShader)
public:
static constexpr int32 NumThreadsPerGroup = 64;
static bool ShouldCompilePermutation(const FGlobalShaderPermutationParameters& Parameters)
{
return UseGPUScene(Parameters.Platform);
}
static void ModifyCompilationEnvironment(const FGlobalShaderPermutationParameters& Parameters, FShaderCompilerEnvironment& OutEnvironment)
{
FGlobalShader::ModifyCompilationEnvironment(Parameters, OutEnvironment);
OutEnvironment.SetDefine(TEXT("INDIRECT_ARGS_NUM_WORDS"), FInstanceCullingContext::IndirectArgsNumWords);
OutEnvironment.SetDefine(TEXT("VF_SUPPORTS_PRIMITIVE_SCENE_DATA"), 1);
OutEnvironment.SetDefine(TEXT("USE_GLOBAL_GPU_SCENE_DATA"), 1);
OutEnvironment.SetDefine(TEXT("NUM_THREADS_PER_GROUP"), NumThreadsPerGroup);
OutEnvironment.SetDefine(TEXT("NANITE_MULTI_VIEW"), 1);
}
// 声明着色器需要使用到的参数.
BEGIN_SHADER_PARAMETER_STRUCT(FParameters, )
SHADER_PARAMETER_SRV(StructuredBuffer<float4>, GPUSceneInstanceSceneData)
SHADER_PARAMETER_SRV(StructuredBuffer<float4>, GPUScenePrimitiveSceneData)
SHADER_PARAMETER(uint32, InstanceDataSOAStride)
SHADER_PARAMETER_RDG_BUFFER_SRV(StructuredBuffer< Nanite::FPackedView >, InViews)
// 存储可见性结果的缓冲区.
SHADER_PARAMETER_RDG_BUFFER_UAV(RWStructuredBuffer<uint>, InstanceVisibilityFlagsOut)
SHADER_PARAMETER(int32, NumInstances)
SHADER_PARAMETER(int32, NumInstanceFlagWords)
SHADER_PARAMETER(int32, NumViews)
END_SHADER_PARAMETER_STRUCT()
};
// 实现着色器.
IMPLEMENT_GLOBAL_SHADER(FCullInstancesCs, "/Engine/Private/InstanceCulling/CullInstances.usf", "CullInstancesCs", SF_Compute);
上面的最后一句实现宏可知FCullInstancesCs调用的shader代码文件是CullInstances.usf,分析之:
// Engine\Shaders\Private\InstanceCulling\CullInstances.usf
#include "../Common.ush"
#include "../SceneData.ush"
#include "../Nanite/NaniteDataDecode.ush"
#include "../Nanite/HZBCull.ush"
RWStructuredBuffer<uint> InstanceVisibilityFlagsOut;
uint NumInstances;
uint NumInstanceFlagWords;
uint NumViews;
uint InstanceDataSOAStride;
// 裁剪实例主入口.
[numthreads(NUM_THREADS_PER_GROUP, 1, 1)]
void CullInstancesCs(uint InstanceId : SV_DispatchThreadID)
{
// 防止InstanceId越界.
if (InstanceId >= NumInstances)
{
return;
}
const bool bNearClip = true;
// 解压Instance数据成Mask和Offset.
FInstanceSceneData InstanceData = GetInstanceData(InstanceId, InstanceDataSOAStride);
uint WordMask = 1U << (InstanceId % 32U);
uint InstanceWordOffset = InstanceId / 32U;
// 判定是否有效: PrimitiveId不是最大值且局部包围盒长度不为0.
bool bIsValid = InstanceData.PrimitiveId != 0xFFFFFFFFu && dot(InstanceData.LocalBoundsExtent, InstanceData.LocalBoundsExtent) > 0.0f;
// 遍历所有view, 每个view的视锥体和实例的包围盒做相交测试.
for (uint ViewId = 0; ViewId < NumViews; ++ViewId)
{
uint Flag = WordMask;
if (bIsValid)
{
FNaniteView NaniteView = GetNaniteView(ViewId);
// 计算局部到裁剪空间的变换矩阵.
float4x4 LocalToTranslatedWorld = InstanceData.LocalToWorld;
LocalToTranslatedWorld[3].xyz += NaniteView.PreViewTranslation.xyz;
float4x4 LocalToClip = mul(LocalToTranslatedWorld, NaniteView.TranslatedWorldToClip);
// 立方体和视锥体相交检测.
FFrustumCullData Cull = BoxCullFrustum(InstanceData.LocalBoundsCenter, InstanceData.LocalBoundsExtent, LocalToClip, bNearClip, false);
if (!Cull.bIsVisible)
{
Flag = 0U;
}
}
// 若实例可见, 设置InstanceVisibilityFlagsOut对应位置的值为1.
if (Flag != 0U)
{
uint WordOffset = NumInstanceFlagWords * ViewId + InstanceWordOffset;
// 注意CS里需要调用原子操作InterlockXXX接口, 避免竞争条件.
InterlockedOr(InstanceVisibilityFlagsOut[WordOffset], Flag);
}
}
}
有了VisibleInstanceFlags可见性数据,后续的Pass绘制就可以根据它来动态生成绘制指令和绘制参数,以达成GPU裁剪和驱动的渲染管线。
6.4.3.5 Nanite光栅化
Nanite光栅化主要是给每个View构建并初始化一个FCullingContext的实例,接着调用CullRasterize,存储光栅化结果,构建HZB,关键代码如下:
for (int32 ViewIndex = 0; ViewIndex < Views.Num(); ViewIndex++)
{
const FViewInfo& View = Views[ViewIndex];
// 初始化裁剪上下文.
Nanite::FCullingContext CullingContext = Nanite::InitCullingContext(
GraphBuilder, *Scene,
!bIsEarlyDepthComplete ? View.PrevViewInfo.NaniteHZB : View.PrevViewInfo.HZB,
View.ViewRect,
bTwoPassOcclusion, bUpdateStreaming, bSupportsMultiplePasses, bForceHWRaster, bPrimaryContext, bDiscardNonMoving);
static FString EmptyFilterName = TEXT("");
const bool bExtractStats = Nanite::IsStatFilterActive(EmptyFilterName);
Nanite::FPackedView PackedView = Nanite::CreatePackedViewFromViewInfo(View, RasterTextureSize, VIEW_FLAG_HZBTEST, 3);
// 带裁剪的光栅化.
Nanite::CullRasterize(GraphBuilder, *Scene, { PackedView }, CullingContext, RasterContext, RasterState, nullptr, bExtractStats);
Nanite::FRasterResults& RasterResults = NaniteRasterResults[ViewIndex];
// 渲染提前渲染.
if (bNeedsPrePass)
{
Nanite::EmitDepthTargets(GraphBuilder, *Scene, Views[ViewIndex], CullingContext.SOAStrides, CullingContext.VisibleClustersSWHW, CullingContext.ViewsBuffer, SceneTextures.Depth.Target, RasterContext.VisBuffer64,RasterResults.MaterialDepth,RasterResults.NaniteMask,RasterResults.VelocityBuffer,bNeedsPrePass);
}
// 构建HZB.
if (!bIsEarlyDepthComplete && bTwoPassOcclusion && View.ViewState)
{
RDG_EVENT_SCOPE(GraphBuilder, "Nanite::BuildHZB");
FRDGTextureRef SceneDepth = SystemTextures.Black;
FRDGTextureRef GraphHZB = nullptr;
BuildHZBFurthest(GraphBuilder,SceneDepth, RasterContext.VisBuffer64, PrimaryViewRect, FeatureLevel, ShaderPlatform, TEXT("Nanite.HZB"), &GraphHZB );
GraphBuilder.QueueTextureExtraction( GraphHZB, &View.ViewState->PrevFrameViewInfo.NaniteHZB );
}
// 提取光栅化和裁剪结果.
Nanite::ExtractResults(GraphBuilder, CullingContext, RasterContext, RasterResults);
}
着重分析一下Nanite::CullRasterize的代码:
// Engine\Source\Runtime\Renderer\Private\Nanite\NaniteRender.cpp
void CullRasterize(
FRDGBuilder& GraphBuilder,
const FScene& Scene,
const TArray<FPackedView, SceneRenderingAllocator>& Views,
uint32 NumPrimaryViews, // Number of non-mip views
FCullingContext& CullingContext,
const FRasterContext& RasterContext,
const FRasterState& RasterState,
const TArray<FInstanceDraw, SceneRenderingAllocator>* OptionalInstanceDraws,
// VirtualShadowMapArray is the supplier of virtual to physical translation, probably could abstract this a bit better,
FVirtualShadowMapArray* VirtualShadowMapArray,
bool bExtractStats
)
{
// 如果视图太多, 拆分到多个Pass去光栅化. 只有depth-only渲染才可能发生.
if (Views.Num() > MAX_VIEWS_PER_CULL_RASTERIZE_PASS)
{
CullRasterizeMultiPass(GraphBuilder, Scene, Views, NumPrimaryViews, CullingContext, RasterContext, RasterState, OptionalInstanceDraws, VirtualShadowMapArray, bExtractStats);
return;
}
RDG_EVENT_SCOPE(GraphBuilder, "Nanite::CullRasterize");
(......)
// 创建视图的结构化缓冲.
{
const uint32 ViewsBufferElements = FMath::RoundUpToPowerOfTwo(Views.Num());
CullingContext.ViewsBuffer = CreateStructuredBuffer(GraphBuilder, TEXT("Nanite.Views"), Views.GetTypeSize(), ViewsBufferElements, Views.GetData(), Views.Num() * Views.GetTypeSize());
}
// 处理裁剪上下文的结构化缓冲.
if (OptionalInstanceDraws)
{
const uint32 InstanceDrawsBufferElements = FMath::RoundUpToPowerOfTwo(OptionalInstanceDraws->Num());
CullingContext.InstanceDrawsBuffer = CreateStructuredBuffer
(
GraphBuilder,
TEXT("Nanite.InstanceDraws"),
OptionalInstanceDraws->GetTypeSize(),
InstanceDrawsBufferElements,
OptionalInstanceDraws->GetData(),
OptionalInstanceDraws->Num() * OptionalInstanceDraws->GetTypeSize()
);
CullingContext.NumInstancesPreCull = OptionalInstanceDraws->Num();
}
else
{
CullingContext.InstanceDrawsBuffer = nullptr;
CullingContext.NumInstancesPreCull = Scene.GPUScene.InstanceDataAllocator.GetMaxSize();
}
(......)
// 裁剪参数.
FCullingParameters CullingParameters;
{
CullingParameters.InViews = GraphBuilder.CreateSRV(CullingContext.ViewsBuffer);
CullingParameters.NumViews = Views.Num();
CullingParameters.NumPrimaryViews = NumPrimaryViews;
CullingParameters.DisocclusionLodScaleFactor = GNaniteDisocclusionHack ? 0.01f : 1.0f; // TODO: Get rid of this hack
CullingParameters.HZBTexture = RegisterExternalTextureWithFallback(GraphBuilder, CullingContext.PrevHZB, GSystemTextures.BlackDummy);
CullingParameters.HZBSize = CullingContext.PrevHZB ? CullingContext.PrevHZB->GetDesc().Extent : FVector2D(0.0f);
CullingParameters.HZBSampler = TStaticSamplerState< SF_Point, AM_Clamp, AM_Clamp, AM_Clamp >::GetRHI();
CullingParameters.SOAStrides = CullingContext.SOAStrides;
CullingParameters.MaxCandidateClusters = Nanite::FGlobalResources::GetMaxCandidateClusters();
CullingParameters.MaxVisibleClusters = Nanite::FGlobalResources::GetMaxVisibleClusters();
CullingParameters.RenderFlags = CullingContext.RenderFlags;
CullingParameters.DebugFlags = CullingContext.DebugFlags;
CullingParameters.CompactedViewInfo = nullptr;
CullingParameters.CompactedViewsAllocation = nullptr;
}
FVirtualTargetParameters VirtualTargetParameters;
// 处理VSM(虚拟阴影图)数组.
if (VirtualShadowMapArray)
{
VirtualTargetParameters.VirtualShadowMap = VirtualShadowMapArray->GetUniformBuffer(GraphBuilder);
VirtualTargetParameters.PageFlags = GraphBuilder.CreateSRV(VirtualShadowMapArray->PageFlagsRDG, PF_R32_UINT);
VirtualTargetParameters.HPageFlags = GraphBuilder.CreateSRV(VirtualShadowMapArray->HPageFlagsRDG, PF_R32_UINT);
VirtualTargetParameters.PageRectBounds = GraphBuilder.CreateSRV(VirtualShadowMapArray->PageRectBoundsRDG);
// 如果提供了来自上一帧的HZB, 也需要上一帧的Page表.
FRDGBufferRef HZBPageTableRDG = VirtualShadowMapArray->PageTableRDG;
if (CullingContext.PrevHZB)
{
check( VirtualShadowMapArray->CacheManager );
TRefCountPtr<FRDGPooledBuffer> HZBPageTable = VirtualShadowMapArray->CacheManager->PrevBuffers.PageTable;
check( HZBPageTable );
HZBPageTableRDG = GraphBuilder.RegisterExternalBuffer( HZBPageTable, TEXT( "Shadow.Virtual.HZBPageTable" ) );
}
VirtualTargetParameters.ShadowHZBPageTable = GraphBuilder.CreateSRV( HZBPageTableRDG, PF_R32_UINT );
}
// 处理GPUScene数据.
FGPUSceneParameters GPUSceneParameters;
GPUSceneParameters.GPUSceneInstanceSceneData = Scene.GPUScene.InstanceDataBuffer.SRV;
GPUSceneParameters.GPUScenePrimitiveSceneData = Scene.GPUScene.PrimitiveBuffer.SRV;
GPUSceneParameters.GPUSceneFrameNumber = Scene.GPUScene.GetSceneFrameNumber();
// 裁剪VSM.
if (VirtualShadowMapArray && CVarCompactVSMViews.GetValueOnRenderThread() != 0)
{
RDG_GPU_STAT_SCOPE(GraphBuilder, NaniteInstanceCullVSM);
// 压缩视图来删除不必要的(空的)mip视图, 需要在GPU上做,因为GPU侧才知道mip拥有哪些page。
const uint32 ViewsBufferElements = FMath::RoundUpToPowerOfTwo(Views.Num());
FRDGBufferRef CompactedViews = GraphBuilder.CreateBuffer(FRDGBufferDesc::CreateStructuredDesc(sizeof(FPackedView), ViewsBufferElements), TEXT("Shadow.Virtual.CompactedViews"));
FRDGBufferRef CompactedViewInfo = GraphBuilder.CreateBuffer(FRDGBufferDesc::CreateStructuredDesc(sizeof(FCompactedViewInfo), Views.Num()), TEXT("Shadow.Virtual.CompactedViewInfo"));
const static uint32 TheZeros[2] = { 0U, 0U };
FRDGBufferRef CompactedViewsAllocation = CreateStructuredBuffer(GraphBuilder, TEXT("Shadow.Virtual.CompactedViewsAllocation"), sizeof(uint32), 2, TheZeros, sizeof(TheZeros), ERDGInitialDataFlags::NoCopy);
{
FCompactViewsVSM_CS::FParameters* PassParameters = GraphBuilder.AllocParameters< FCompactViewsVSM_CS::FParameters >();
PassParameters->GPUSceneParameters = GPUSceneParameters;
PassParameters->CullingParameters = CullingParameters;
PassParameters->VirtualShadowMap = VirtualTargetParameters;
PassParameters->CompactedViewsOut = GraphBuilder.CreateUAV(CompactedViews);
PassParameters->CompactedViewInfoOut = GraphBuilder.CreateUAV(CompactedViewInfo);
PassParameters->CompactedViewsAllocationOut = GraphBuilder.CreateUAV(CompactedViewsAllocation);
auto ComputeShader = CullingContext.ShaderMap->GetShader<FCompactViewsVSM_CS>();
// 利用CS压缩并裁剪VSM.
FComputeShaderUtils::AddPass(
GraphBuilder,
RDG_EVENT_NAME("CompactViewsVSM"),
ComputeShader,
PassParameters,
FComputeShaderUtils::GetGroupCount(NumPrimaryViews, 64)
);
}
// 用压缩的视图覆盖原有的信息.
CullingParameters.InViews = GraphBuilder.CreateSRV(CompactedViews);
CullingContext.ViewsBuffer = CompactedViews;
CullingParameters.CompactedViewInfo = GraphBuilder.CreateSRV(CompactedViewInfo);
CullingParameters.CompactedViewsAllocation = GraphBuilder.CreateSRV(CompactedViewsAllocation);
}
// 初始化裁剪上下文的参数.
{
FInitArgs_CS::FParameters* PassParameters = GraphBuilder.AllocParameters< FInitArgs_CS::FParameters >();
PassParameters->RenderFlags = CullingParameters.RenderFlags;
PassParameters->OutMainAndPostPassPersistentStates = GraphBuilder.CreateUAV( CullingContext.MainAndPostPassPersistentStates );
PassParameters->InOutMainPassRasterizeArgsSWHW = GraphBuilder.CreateUAV( CullingContext.MainRasterizeArgsSWHW );
uint32 ClampedDrawPassIndex = FMath::Min(CullingContext.DrawPassIndex, 2u);
if (CullingContext.bTwoPassOcclusion)
{
PassParameters->OutOccludedInstancesArgs = GraphBuilder.CreateUAV( CullingContext.OccludedInstancesArgs );
PassParameters->InOutPostPassRasterizeArgsSWHW = GraphBuilder.CreateUAV( CullingContext.PostRasterizeArgsSWHW );
}
if (CullingContext.RenderFlags & RENDER_FLAG_HAVE_PREV_DRAW_DATA)
{
PassParameters->InOutTotalPrevDrawClusters = GraphBuilder.CreateUAV(CullingContext.TotalPrevDrawClustersBuffer);
}
else
{
// Use any UAV just to keep render graph happy that something is bound, but the shader doesn't actually touch this.
PassParameters->InOutTotalPrevDrawClusters = PassParameters->OutMainAndPostPassPersistentStates;
}
FInitArgs_CS::FPermutationDomain PermutationVector;
PermutationVector.Set<FInitArgs_CS::FOcclusionCullingDim>( CullingContext.bTwoPassOcclusion );
PermutationVector.Set<FInitArgs_CS::FDrawPassIndexDim>( ClampedDrawPassIndex );
auto ComputeShader = CullingContext.ShaderMap->GetShader< FInitArgs_CS >( PermutationVector );
// 也是用CS初始化参数.
FComputeShaderUtils::AddPass(
GraphBuilder,
RDG_EVENT_NAME( "InitArgs" ),
ComputeShader,
PassParameters,
FIntVector( 1, 1, 1 )
);
}
// 分配候选缓冲区, 生命周期只在CullRasterize期间.
FRDGBufferRef MainCandidateNodesAndClustersBuffer = nullptr;
FRDGBufferRef PostCandidateNodesAndClustersBuffer = nullptr;
AllocateCandidateBuffers(GraphBuilder, CullingContext.ShaderMap, &MainCandidateNodesAndClustersBuffer, CullingContext.bTwoPassOcclusion ? &PostCandidateNodesAndClustersBuffer : nullptr);
// 实例化层级和Cluster裁剪, 包含无遮挡Pass或遮挡主Pass.
AddPass_InstanceHierarchyAndClusterCull(
GraphBuilder,
Scene,
CullingParameters,
Views,
NumPrimaryViews,
CullingContext,
RasterContext,
RasterState,
GPUSceneParameters,
MainCandidateNodesAndClustersBuffer,
PostCandidateNodesAndClustersBuffer,
CullingContext.bTwoPassOcclusion ? CULLING_PASS_OCCLUSION_MAIN : CULLING_PASS_NO_OCCLUSION,
VirtualShadowMapArray,
VirtualTargetParameters
);
// 光栅化.
AddPass_Rasterize(
GraphBuilder,
Views,
RasterContext,
RasterState,
CullingContext.SOAStrides,
CullingContext.RenderFlags,
CullingContext.ViewsBuffer,
CullingContext.VisibleClustersSWHW,
nullptr,
CullingContext.SafeMainRasterizeArgsSWHW,
CullingContext.TotalPrevDrawClustersBuffer,
GPUSceneParameters,
true,
VirtualShadowMapArray,
VirtualTargetParameters
);
// 遮挡后置Pass. 重新检测上一帧不可见的实例和Cluster, 如果它们此帧可见, 渲染之.
if (CullingContext.bTwoPassOcclusion)
{
// 用上一帧的遮挡体建立一个最近的HZB,以再次检测剩余的遮挡体。
{
RDG_EVENT_SCOPE(GraphBuilder, "BuildPreviousOccluderHZB");
FSceneTextureParameters SceneTextures = GetSceneTextureParameters(GraphBuilder);
FRDGTextureRef SceneDepth = SceneTextures.SceneDepthTexture;
FRDGTextureRef RasterizedDepth = RasterContext.VisBuffer64;
if( RasterContext.RasterTechnique == ERasterTechnique::DepthOnly )
{
SceneDepth = GraphBuilder.RegisterExternalTexture( GSystemTextures.BlackDummy );
RasterizedDepth = RasterContext.DepthBuffer;
}
FRDGTextureRef OutFurthestHZBTexture;
FIntRect ViewRect(0, 0, RasterContext.TextureSize.X, RasterContext.TextureSize.Y);
if (Views.Num() == 1)
{
ViewRect = FIntRect(Views[0].ViewRect.X, Views[0].ViewRect.Y, Views[0].ViewRect.Z, Views[0].ViewRect.W);
}
// 构建HZB.
BuildHZBFurthest(
GraphBuilder,
SceneDepth,
RasterizedDepth,
CullingContext.HZBBuildViewRect,
Scene.GetFeatureLevel(),
Scene.GetShaderPlatform(),
TEXT("Nanite.PreviousOccluderHZB"),
/* OutFurthestHZBTexture = */ &OutFurthestHZBTexture);
CullingParameters.HZBTexture = OutFurthestHZBTexture;
CullingParameters.HZBSize = CullingParameters.HZBTexture->Desc.Extent;
}
// 后置Pass.
AddPass_InstanceHierarchyAndClusterCull(
GraphBuilder,
Scene,
CullingParameters,
Views,
NumPrimaryViews,
CullingContext,
RasterContext,
RasterState,
GPUSceneParameters,
MainCandidateNodesAndClustersBuffer,
PostCandidateNodesAndClustersBuffer,
CULLING_PASS_OCCLUSION_POST,
VirtualShadowMapArray,
VirtualTargetParameters
);
// 渲染后置Pass.
AddPass_Rasterize(
GraphBuilder,
Views,
RasterContext,
RasterState,
CullingContext.SOAStrides,
CullingContext.RenderFlags,
CullingContext.ViewsBuffer,
CullingContext.VisibleClustersSWHW,
CullingContext.MainRasterizeArgsSWHW,
CullingContext.SafePostRasterizeArgsSWHW,
CullingContext.TotalPrevDrawClustersBuffer,
GPUSceneParameters,
false,
VirtualShadowMapArray,
VirtualTargetParameters
);
}
if (RasterContext.RasterTechnique != ERasterTechnique::DepthOnly)
{
// 上一个Pass渲染的Cluster索引和数量和仅深度渲染毫无关联.
CullingContext.DrawPassIndex++;
CullingContext.RenderFlags |= RENDER_FLAG_HAVE_PREV_DRAW_DATA;
}
(......)
}
下面将注意力放到AddPass_InstanceHierarchyAndClusterCull和AddPass_Rasterize两个接口。首先是AddPass_InstanceHierarchyAndClusterCull:
void AddPass_InstanceHierarchyAndClusterCull(
FRDGBuilder& GraphBuilder,
const FScene& Scene,
const FCullingParameters& CullingParameters,
const TArray<FPackedView, SceneRenderingAllocator>& Views,
const uint32 NumPrimaryViews,
const FCullingContext& CullingContext,
const FRasterContext& RasterContext,
const FRasterState& RasterState,
const FGPUSceneParameters &GPUSceneParameters,
FRDGBufferRef MainCandidateNodesAndClusters,
FRDGBufferRef PostCandidateNodesAndClusters,
uint32 CullingPass,
FVirtualShadowMapArray *VirtualShadowMapArray,
FVirtualTargetParameters &VirtualTargetParameters
)
{
(......)
const bool bMultiView = Views.Num() > 1 || VirtualShadowMapArray != nullptr;
if (VirtualShadowMapArray)
{
(......)
}
// 处理实例化裁剪.
else if (CullingContext.NumInstancesPreCull > 0 || CullingPass == CULLING_PASS_OCCLUSION_POST)
{
RDG_GPU_STAT_SCOPE( GraphBuilder, NaniteInstanceCull );
// 处理实例化裁剪CS的参数.
FInstanceCull_CS::FParameters* PassParameters = GraphBuilder.AllocParameters< FInstanceCull_CS::FParameters >();
PassParameters->NumInstances = CullingContext.NumInstancesPreCull;
PassParameters->MaxNodes = Nanite::FGlobalResources::GetMaxNodes();
PassParameters->ImposterMaxPixels = GNaniteImposterMaxPixels;
PassParameters->GPUSceneParameters = GPUSceneParameters;
PassParameters->RasterParameters = RasterContext.Parameters;
PassParameters->CullingParameters = CullingParameters;
const ERasterTechnique Technique = RasterContext.RasterTechnique;
PassParameters->OnlyCastShadowsPrimitives = Technique == ERasterTechnique::DepthOnly ? 1 : 0;
PassParameters->ImposterAtlas = Nanite::GStreamingManager.GetRootPagesSRV();
PassParameters->OutMainAndPostPassPersistentStates = GraphBuilder.CreateUAV( CullingContext.MainAndPostPassPersistentStates );
if (CullingContext.StatsBuffer)
{
PassParameters->OutStatsBuffer = GraphBuilder.CreateUAV(CullingContext.StatsBuffer);
}
// 根据不同的裁剪方式设置不同的参数.
if( CullingPass == CULLING_PASS_NO_OCCLUSION )
{
if( CullingContext.InstanceDrawsBuffer )
{
PassParameters->InInstanceDraws = GraphBuilder.CreateSRV( CullingContext.InstanceDrawsBuffer );
}
PassParameters->OutCandidateNodesAndClusters = GraphBuilder.CreateUAV( MainCandidateNodesAndClusters);
}
else if( CullingPass == CULLING_PASS_OCCLUSION_MAIN )
{
PassParameters->OutOccludedInstances = GraphBuilder.CreateUAV( CullingContext.OccludedInstances );
PassParameters->OutOccludedInstancesArgs = GraphBuilder.CreateUAV( CullingContext.OccludedInstancesArgs );
PassParameters->OutCandidateNodesAndClusters = GraphBuilder.CreateUAV( MainCandidateNodesAndClusters );
}
else
{
PassParameters->InInstanceDraws = GraphBuilder.CreateSRV( CullingContext.OccludedInstances );
PassParameters->InOccludedInstancesArgs = GraphBuilder.CreateSRV( CullingContext.OccludedInstancesArgs );
PassParameters->OutCandidateNodesAndClusters = GraphBuilder.CreateUAV( PostCandidateNodesAndClusters);
}
check(CullingContext.ViewsBuffer);
// 处理排列参数.
const uint32 InstanceCullingPass = CullingContext.InstanceDrawsBuffer != nullptr ? CULLING_PASS_EXPLICIT_LIST : CullingPass;
FInstanceCull_CS::FPermutationDomain PermutationVector;
PermutationVector.Set<FInstanceCull_CS::FCullingPassDim>(InstanceCullingPass);
PermutationVector.Set<FInstanceCull_CS::FMultiViewDim>(bMultiView);
PermutationVector.Set<FInstanceCull_CS::FNearClipDim>(RasterState.bNearClip);
PermutationVector.Set<FInstanceCull_CS::FDebugFlagsDim>(CullingContext.DebugFlags != 0);
PermutationVector.Set<FInstanceCull_CS::FRasterTechniqueDim>(int32(RasterContext.RasterTechnique));
auto ComputeShader = CullingContext.ShaderMap->GetShader<FInstanceCull_CS>(PermutationVector);
// 后置Pass实例裁剪.
if( InstanceCullingPass == CULLING_PASS_OCCLUSION_POST )
{
PassParameters->IndirectArgs = CullingContext.OccludedInstancesArgs;
FComputeShaderUtils::AddPass(
GraphBuilder,
RDG_EVENT_NAME( "Post Pass: InstanceCull" ),
ComputeShader,
PassParameters,
PassParameters->IndirectArgs,
0
);
}
else // 主通道实例裁剪.
{
FComputeShaderUtils::AddPass(
GraphBuilder,
InstanceCullingPass == CULLING_PASS_OCCLUSION_MAIN ? RDG_EVENT_NAME( "Main Pass: InstanceCull" ) :
InstanceCullingPass == CULLING_PASS_NO_OCCLUSION ? RDG_EVENT_NAME( "Main Pass: InstanceCull - No occlusion" ) :
RDG_EVENT_NAME( "Main Pass: InstanceCull - Explicit list" ),
ComputeShader,
PassParameters,
FComputeShaderUtils::GetGroupCount(CullingContext.NumInstancesPreCull, 64)
);
}
}
// Cluster裁剪.
{
RDG_GPU_STAT_SCOPE(GraphBuilder, NaniteClusterCull);
FPersistentClusterCull_CS::FParameters* PassParameters = GraphBuilder.AllocParameters< FPersistentClusterCull_CS::FParameters >();
// Cluster裁剪用到了GPUScene、GStreamingManager等参数。
PassParameters->GPUSceneParameters = GPUSceneParameters;
PassParameters->CullingParameters = CullingParameters;
PassParameters->MaxNodes = Nanite::FGlobalResources::GetMaxNodes();
PassParameters->ClusterPageHeaders = Nanite::GStreamingManager.GetClusterPageHeadersSRV();
PassParameters->ClusterPageData = Nanite::GStreamingManager.GetClusterPageDataSRV();
PassParameters->HierarchyBuffer = Nanite::GStreamingManager.GetHierarchySRV();
check(CullingContext.DrawPassIndex == 0 || CullingContext.RenderFlags & RENDER_FLAG_HAVE_PREV_DRAW_DATA); // sanity check
// 处理上一帧数据.
if (CullingContext.RenderFlags & RENDER_FLAG_HAVE_PREV_DRAW_DATA)
{
PassParameters->InTotalPrevDrawClusters = GraphBuilder.CreateSRV(CullingContext.TotalPrevDrawClustersBuffer);
}
else
{
FRDGBufferRef Dummy = GraphBuilder.RegisterExternalBuffer(Nanite::GGlobalResources.GetStructureBufferStride8(), TEXT("Nanite.StructuredBufferStride8"));
PassParameters->InTotalPrevDrawClusters = GraphBuilder.CreateSRV(Dummy);
}
PassParameters->MainAndPostPassPersistentStates = GraphBuilder.CreateUAV( CullingContext.MainAndPostPassPersistentStates );
// 候选节点和Cluster.
if( CullingPass == CULLING_PASS_NO_OCCLUSION || CullingPass == CULLING_PASS_OCCLUSION_MAIN )
{
PassParameters->InOutCandidateNodesAndClusters = GraphBuilder.CreateUAV( MainCandidateNodesAndClusters );
PassParameters->VisibleClustersArgsSWHW = GraphBuilder.CreateUAV( CullingContext.MainRasterizeArgsSWHW );
if( CullingPass == CULLING_PASS_OCCLUSION_MAIN )
{
PassParameters->OutOccludedNodesAndClusters = GraphBuilder.CreateUAV( PostCandidateNodesAndClusters );
}
}
else
{
PassParameters->InOutCandidateNodesAndClusters = GraphBuilder.CreateUAV( PostCandidateNodesAndClusters );
PassParameters->OffsetClustersArgsSWHW = GraphBuilder.CreateSRV( CullingContext.MainRasterizeArgsSWHW );
PassParameters->VisibleClustersArgsSWHW = GraphBuilder.CreateUAV( CullingContext.PostRasterizeArgsSWHW );
}
// 输出结果UAV, 包含可见Cluster和流请求.
PassParameters->OutVisibleClustersSWHW = GraphBuilder.CreateUAV( CullingContext.VisibleClustersSWHW );
PassParameters->OutStreamingRequests = GraphBuilder.CreateUAV( CullingContext.StreamingRequests );
if (VirtualShadowMapArray)
{
PassParameters->VirtualShadowMap = VirtualTargetParameters;
PassParameters->OutDynamicCasterFlags = GraphBuilder.CreateUAV(VirtualShadowMapArray->DynamicCasterPageFlagsRDG, PF_R32_UINT);
}
if (CullingContext.StatsBuffer)
{
PassParameters->OutStatsBuffer = GraphBuilder.CreateUAV(CullingContext.StatsBuffer);
}
PassParameters->LargePageRectThreshold = CVarLargePageRectThreshold.GetValueOnRenderThread();
check(CullingContext.ViewsBuffer);
// 排列.
FPersistentClusterCull_CS::FPermutationDomain PermutationVector;
PermutationVector.Set<FPersistentClusterCull_CS::FCullingPassDim>(CullingPass);
PermutationVector.Set<FPersistentClusterCull_CS::FMultiViewDim>(bMultiView);
PermutationVector.Set<FPersistentClusterCull_CS::FNearClipDim>(RasterState.bNearClip);
PermutationVector.Set<FPersistentClusterCull_CS::FVirtualTextureTargetDim>(VirtualShadowMapArray != nullptr);
PermutationVector.Set<FPersistentClusterCull_CS::FClusterPerPageDim>(GNaniteClusterPerPage && VirtualShadowMapArray != nullptr);
PermutationVector.Set<FPersistentClusterCull_CS::FDebugFlagsDim>(CullingContext.DebugFlags != 0);
auto ComputeShader = CullingContext.ShaderMap->GetShader<FPersistentClusterCull_CS>(PermutationVector);
// CS Pass调用.
FComputeShaderUtils::AddPass(
GraphBuilder,
CullingPass == CULLING_PASS_NO_OCCLUSION ? RDG_EVENT_NAME( "Main Pass: PersistentCull - No occlusion" ) :
CullingPass == CULLING_PASS_OCCLUSION_MAIN ? RDG_EVENT_NAME( "Main Pass: PersistentCull" ) :
RDG_EVENT_NAME( "Post Pass: PersistentCull" ),
ComputeShader,
PassParameters,
FIntVector(GRHIPersistentThreadGroupCount, 1, 1)
);
}
// 计算光栅化参数, 以保证后续的光栅化通道正确且安全.
{
FCalculateSafeRasterizerArgs_CS::FParameters* PassParameters = GraphBuilder.AllocParameters< FCalculateSafeRasterizerArgs_CS::FParameters >();
const bool bPrevDrawData = (CullingContext.RenderFlags & RENDER_FLAG_HAVE_PREV_DRAW_DATA) != 0;
const bool bPostPass = (CullingPass == CULLING_PASS_OCCLUSION_POST) != 0;
if (bPrevDrawData)
{
PassParameters->InTotalPrevDrawClusters = GraphBuilder.CreateSRV(CullingContext.TotalPrevDrawClustersBuffer);
}
if (bPostPass)
{
PassParameters->OffsetClustersArgsSWHW = GraphBuilder.CreateSRV(CullingContext.MainRasterizeArgsSWHW);
PassParameters->InRasterizerArgsSWHW = GraphBuilder.CreateSRV(CullingContext.PostRasterizeArgsSWHW);
PassParameters->OutSafeRasterizerArgsSWHW = GraphBuilder.CreateUAV(CullingContext.SafePostRasterizeArgsSWHW);
}
else
{
PassParameters->InRasterizerArgsSWHW = GraphBuilder.CreateSRV(CullingContext.MainRasterizeArgsSWHW);
PassParameters->OutSafeRasterizerArgsSWHW = GraphBuilder.CreateUAV(CullingContext.SafeMainRasterizeArgsSWHW);
}
PassParameters->MaxVisibleClusters = Nanite::FGlobalResources::GetMaxVisibleClusters();
PassParameters->RenderFlags = CullingContext.RenderFlags;
FCalculateSafeRasterizerArgs_CS::FPermutationDomain PermutationVector;
PermutationVector.Set<FCalculateSafeRasterizerArgs_CS::FHasPrevDrawData>(bPrevDrawData);
PermutationVector.Set<FCalculateSafeRasterizerArgs_CS::FIsPostPass>(bPostPass);
auto ComputeShader = CullingContext.ShaderMap->GetShader< FCalculateSafeRasterizerArgs_CS >(PermutationVector);
FComputeShaderUtils::AddPass(
GraphBuilder,
bPostPass ? RDG_EVENT_NAME("Post Pass: CalculateSafeRasterizerArgs") : RDG_EVENT_NAME("Main Pass: CalculateSafeRasterizerArgs"),
ComputeShader,
PassParameters,
FIntVector(1, 1, 1)
);
}
}
上面涉及多次Compute Shader的调用,限于篇幅,就不对其shader代码进行剖析了。下面将重点放到AddPass_Rasterize:
void AddPass_Rasterize(
FRDGBuilder& GraphBuilder,
const TArray<FPackedView, SceneRenderingAllocator>& Views,
const FRasterContext& RasterContext,
const FRasterState& RasterState,
FIntVector4 SOAStrides,
uint32 RenderFlags,
FRDGBufferRef ViewsBuffer,
FRDGBufferRef VisibleClustersSWHW,
FRDGBufferRef ClusterOffsetSWHW,
FRDGBufferRef IndirectArgs,
FRDGBufferRef TotalPrevDrawClustersBuffer,
const FGPUSceneParameters& GPUSceneParameters,
bool bMainPass,
FVirtualShadowMapArray* VirtualShadowMapArray,
FVirtualTargetParameters& VirtualTargetParameters
)
{
(......)
// 分配光栅化参数.
auto* RasterPassParameters = GraphBuilder.AllocParameters<FHWRasterizePS::FParameters>();
auto* CommonPassParameters = &RasterPassParameters->Common;
// 设置Cluster页面和页面头.
CommonPassParameters->ClusterPageData = GStreamingManager.GetClusterPageDataSRV();
CommonPassParameters->ClusterPageHeaders = GStreamingManager.GetClusterPageHeadersSRV();
// 视图缓冲数据.
if (ViewsBuffer)
{
CommonPassParameters->InViews = GraphBuilder.CreateSRV(ViewsBuffer);
}
// 绘制参数.
CommonPassParameters->GPUSceneParameters = GPUSceneParameters;
CommonPassParameters->RasterParameters = RasterContext.Parameters;
CommonPassParameters->VisualizeModeBitMask = RasterContext.VisualizeModeBitMask;
CommonPassParameters->SOAStrides = SOAStrides;
CommonPassParameters->MaxVisibleClusters = Nanite::FGlobalResources::GetMaxVisibleClusters();
CommonPassParameters->RenderFlags = RenderFlags;
if (RasterState.CullMode == CM_CCW)
{
CommonPassParameters->RenderFlags |= RENDER_FLAG_REVERSE_CULLING;
}
CommonPassParameters->VisibleClustersSWHW = GraphBuilder.CreateSRV(VisibleClustersSWHW);
if (VirtualShadowMapArray)
{
CommonPassParameters->VirtualShadowMap = VirtualTargetParameters;
}
if (!bMainPass)
{
CommonPassParameters->InClusterOffsetSWHW = GraphBuilder.CreateSRV(ClusterOffsetSWHW);
}
CommonPassParameters->IndirectArgs = IndirectArgs;
const bool bHavePrevDrawData = (RenderFlags & RENDER_FLAG_HAVE_PREV_DRAW_DATA);
if (bHavePrevDrawData)
{
CommonPassParameters->InTotalPrevDrawClusters = GraphBuilder.CreateSRV(TotalPrevDrawClustersBuffer);
}
const ERasterTechnique Technique = RasterContext.RasterTechnique;
const ERasterScheduling Scheduling = RasterContext.RasterScheduling;
const bool bNearClip = RasterState.bNearClip;
const bool bMultiView = Views.Num() > 1 || VirtualShadowMapArray != nullptr;
ERDGPassFlags ComputePassFlags = ERDGPassFlags::Compute;
// 如果是软硬件结合的方式, 创建带SkipBarrier标记的UAV.
if (Scheduling == ERasterScheduling::HardwareAndSoftwareOverlap)
{
const auto CreateSkipBarrierUAV = [&](auto& InOutUAV)
{
if (InOutUAV)
{
// 带了ERDGUnorderedAccessViewFlags::SkipBarrier标记.
InOutUAV = GraphBuilder.CreateUAV(InOutUAV->Desc, ERDGUnorderedAccessViewFlags::SkipBarrier);
}
};
// 创建带SkipBarrier标记的UAV, 以允许软硬件交叉重叠.
CreateSkipBarrierUAV(CommonPassParameters->RasterParameters.OutDepthBuffer);
CreateSkipBarrierUAV(CommonPassParameters->RasterParameters.OutVisBuffer64);
CreateSkipBarrierUAV(CommonPassParameters->RasterParameters.OutDbgBuffer64);
CreateSkipBarrierUAV(CommonPassParameters->RasterParameters.OutDbgBuffer32);
CreateSkipBarrierUAV(CommonPassParameters->RasterParameters.LockBuffer);
ComputePassFlags = ERDGPassFlags::AsyncCompute;
}
FIntRect ViewRect(Views[0].ViewRect.X, Views[0].ViewRect.Y, Views[0].ViewRect.Z, Views[0].ViewRect.W);
if (bMultiView)
{
ViewRect.Min = FIntPoint::ZeroValue;
ViewRect.Max = RasterContext.TextureSize;
}
// 处理VSM.
if (VirtualShadowMapArray)
{
ViewRect.Min = FIntPoint::ZeroValue;
if( GNaniteClusterPerPage )
{
ViewRect.Max = FIntPoint( FVirtualShadowMap::PageSize, FVirtualShadowMap::PageSize ) * FVirtualShadowMap::RasterWindowPages;
}
else
{
ViewRect.Max = FIntPoint( FVirtualShadowMap::VirtualMaxResolutionXY, FVirtualShadowMap::VirtualMaxResolutionXY );
}
}
// 先用传统的硬件渲染管线光栅化.
{
const bool bUsePrimitiveShader = UsePrimitiveShader();
const bool bUseAutoCullingShader =
GRHISupportsPrimitiveShaders &&
!bUsePrimitiveShader &&
GNaniteAutoShaderCulling != 0;
// 处理VS参数.
FHWRasterizeVS::FPermutationDomain PermutationVectorVS;
PermutationVectorVS.Set<FHWRasterizeVS::FRasterTechniqueDim>(int32(Technique));
PermutationVectorVS.Set<FHWRasterizeVS::FAddClusterOffset>(bMainPass ? 0 : 1);
PermutationVectorVS.Set<FHWRasterizeVS::FMultiViewDim>(bMultiView);
PermutationVectorVS.Set<FHWRasterizeVS::FPrimShaderDim>(bUsePrimitiveShader);
PermutationVectorVS.Set<FHWRasterizeVS::FAutoShaderCullDim>(bUseAutoCullingShader);
PermutationVectorVS.Set<FHWRasterizeVS::FHasPrevDrawData>(bHavePrevDrawData);
PermutationVectorVS.Set<FHWRasterizeVS::FVisualizeDim>(RasterContext.VisualizeActive && Technique != ERasterTechnique::DepthOnly);
PermutationVectorVS.Set<FHWRasterizeVS::FNearClipDim>(bNearClip);
PermutationVectorVS.Set<FHWRasterizeVS::FVirtualTextureTargetDim>(VirtualShadowMapArray != nullptr);
PermutationVectorVS.Set<FHWRasterizeVS::FClusterPerPageDim>(GNaniteClusterPerPage && VirtualShadowMapArray != nullptr );
// 处理PS参数.
FHWRasterizePS::FPermutationDomain PermutationVectorPS;
PermutationVectorPS.Set<FHWRasterizePS::FRasterTechniqueDim>(int32(Technique));
PermutationVectorPS.Set<FHWRasterizePS::FMultiViewDim>(bMultiView);
PermutationVectorPS.Set<FHWRasterizePS::FPrimShaderDim>(bUsePrimitiveShader);
PermutationVectorPS.Set<FHWRasterizePS::FVisualizeDim>(RasterContext.VisualizeActive && Technique != ERasterTechnique::DepthOnly);
PermutationVectorPS.Set<FHWRasterizePS::FNearClipDim>(bNearClip);
PermutationVectorPS.Set<FHWRasterizePS::FVirtualTextureTargetDim>(VirtualShadowMapArray != nullptr);
PermutationVectorPS.Set<FHWRasterizePS::FClusterPerPageDim>( GNaniteClusterPerPage && VirtualShadowMapArray != nullptr );
auto VertexShader = RasterContext.ShaderMap->GetShader<FHWRasterizeVS>(PermutationVectorVS);
auto PixelShader = RasterContext.ShaderMap->GetShader<FHWRasterizePS>(PermutationVectorPS);
// 增加光栅化Pass.
GraphBuilder.AddPass(
bMainPass ? RDG_EVENT_NAME("Main Pass: Rasterize") : RDG_EVENT_NAME("Post Pass: Rasterize"),
RasterPassParameters,
ERDGPassFlags::Raster | ERDGPassFlags::SkipRenderPass,
[VertexShader, PixelShader, RasterPassParameters, ViewRect, bUsePrimitiveShader, bMainPass](FRHICommandListImmediate& RHICmdList)
{
// 渲染Pass信息.
FRHIRenderPassInfo RPInfo;
// Resolve参数.
RPInfo.ResolveParameters.DestRect.X1 = ViewRect.Min.X;
RPInfo.ResolveParameters.DestRect.Y1 = ViewRect.Min.Y;
RPInfo.ResolveParameters.DestRect.X2 = ViewRect.Max.X;
RPInfo.ResolveParameters.DestRect.Y2 = ViewRect.Max.Y;
RHICmdList.BeginRenderPass(RPInfo, bMainPass ? TEXT("Main Pass: Rasterize") : TEXT("Post Pass: Rasterize"));
RHICmdList.SetViewport(ViewRect.Min.X, ViewRect.Min.Y, 0.0f, FMath::Min(ViewRect.Max.X, 32767), FMath::Min(ViewRect.Max.Y, 32767), 1.0f);
FGraphicsPipelineStateInitializer GraphicsPSOInit;
RHICmdList.ApplyCachedRenderTargets(GraphicsPSOInit);
// PSO.
GraphicsPSOInit.BlendState = TStaticBlendState<>::GetRHI();
GraphicsPSOInit.RasterizerState = GetStaticRasterizerState<false>(FM_Solid, CM_CW);
GraphicsPSOInit.DepthStencilState = TStaticDepthStencilState<false, CF_Always>::GetRHI();
GraphicsPSOInit.PrimitiveType = bUsePrimitiveShader ? PT_PointList : PT_TriangleList;
GraphicsPSOInit.BoundShaderState.VertexDeclarationRHI = GEmptyVertexDeclaration.VertexDeclarationRHI;
GraphicsPSOInit.BoundShaderState.VertexShaderRHI = VertexShader.GetVertexShader();
GraphicsPSOInit.BoundShaderState.PixelShaderRHI = PixelShader.GetPixelShader();
SetGraphicsPipelineState( RHICmdList, GraphicsPSOInit );
SetShaderParameters(RHICmdList, VertexShader, VertexShader.GetVertexShader(), RasterPassParameters->Common);
SetShaderParameters(RHICmdList, PixelShader, PixelShader.GetPixelShader(), *RasterPassParameters);
RHICmdList.SetStreamSource( 0, nullptr, 0 );
// 注意调用的是Indirect类型的接口, 并且IndirectArgs就是AddPass_InstanceHierarchyAndClusterCull的结果.
RHICmdList.DrawPrimitiveIndirect(RasterPassParameters->Common.IndirectArgs->GetIndirectRHICallBuffer(), 16);
RHICmdList.EndRenderPass();
});
}
// 软件光栅化(用Compute Shader计算).
if (Scheduling != ERasterScheduling::HardwareOnly)
{
// 处理软件光栅化CS的参数.
FMicropolyRasterizeCS::FPermutationDomain PermutationVectorCS;
PermutationVectorCS.Set<FMicropolyRasterizeCS::FAddClusterOffset>(bMainPass ? 0 : 1);
PermutationVectorCS.Set<FMicropolyRasterizeCS::FMultiViewDim>(bMultiView);
PermutationVectorCS.Set<FMicropolyRasterizeCS::FHasPrevDrawData>(bHavePrevDrawData);
PermutationVectorCS.Set<FMicropolyRasterizeCS::FRasterTechniqueDim>(int32(Technique));
PermutationVectorCS.Set<FMicropolyRasterizeCS::FVisualizeDim>(RasterContext.VisualizeActive && Technique != ERasterTechnique::DepthOnly);
PermutationVectorCS.Set<FMicropolyRasterizeCS::FNearClipDim>(bNearClip);
PermutationVectorCS.Set<FMicropolyRasterizeCS::FVirtualTextureTargetDim>(VirtualShadowMapArray != nullptr);
PermutationVectorCS.Set<FMicropolyRasterizeCS::FClusterPerPageDim>(GNaniteClusterPerPage&& VirtualShadowMapArray != nullptr);
auto ComputeShader = RasterContext.ShaderMap->GetShader<FMicropolyRasterizeCS>(PermutationVectorCS);
// 派发调用, 光栅化的数据和参数在CommonPassParameters内.
FComputeShaderUtils::AddPass(
GraphBuilder,
bMainPass ? RDG_EVENT_NAME("Main Pass: Rasterize") : RDG_EVENT_NAME("Post Pass: Rasterize"),
ComputePassFlags,
ComputeShader,
CommonPassParameters,
CommonPassParameters->IndirectArgs,
0);
}
}
为了更进一步探查硬件光栅化和软件光栅化的过程,有必要进入它们的shader逻辑进行分析:
// Engine\Shaders\Private\Nanite\Rasterizer.usf
(......)
// 光栅化三角形(用于软件光栅化)
void RasterizeTri(
FNaniteView NaniteView,
int4 ViewRect,
uint PixelValue,
#if VISUALIZE
uint2 VisualizeValues,
#endif
float3 Verts[3],
bool bUsePageTable )
{
float3 v01 = Verts[1] - Verts[0];
float3 v02 = Verts[2] - Verts[0];
// 背面剔除
float DetXY = v01.x * v02.y - v01.y * v02.x;
if( DetXY >= 0.0f )
{
return;
}
float InvDet = rcp( DetXY );
float2 GradZ;
GradZ.x = ( v01.z * v02.y - v01.y * v02.z ) * InvDet;
GradZ.y = ( v01.x * v02.z - v01.z * v02.x ) * InvDet;
// 16.8定点数
float2 Vert0 = Verts[0].xy;
float2 Vert1 = Verts[1].xy;
float2 Vert2 = Verts[2].xy;
// 矩形包围盒
const float2 MinSubpixel = min3( Vert0, Vert1, Vert2 );
const float2 MaxSubpixel = max3( Vert0, Vert1, Vert2 );
// 四舍五入到最近像素
int2 MinPixel = (int2)floor( ( MinSubpixel + (SUBPIXEL_SAMPLES / 2) - 1 ) * (1.0 / SUBPIXEL_SAMPLES) );
int2 MaxPixel = (int2)floor( ( MaxSubpixel - (SUBPIXEL_SAMPLES / 2) - 1 ) * (1.0 / SUBPIXEL_SAMPLES) );
// 裁剪到视图.
MinPixel = max( MinPixel, ViewRect.xy );
MaxPixel = min( MaxPixel, ViewRect.zw - 1 );
// 裁剪无像素覆盖的三角形
if( any( MinPixel > MaxPixel ) )
return;
// 限制光栅化边界到一个合理的最大值。
MaxPixel = min( MaxPixel, MinPixel + 63 );
// 4.8 定点数
float2 Edge01 = -v01.xy;
float2 Edge12 = Vert1 - Vert2;
float2 Edge20 = v02.xy;
// 用MinPixel调整MinPixel的像素偏移
// 4.8 fixed point
// 最大三角形尺寸 = 127x127像素
const float2 BaseSubpixel = (float2)MinPixel * SUBPIXEL_SAMPLES + (SUBPIXEL_SAMPLES / 2);
Vert0 -= BaseSubpixel;
Vert1 -= BaseSubpixel;
Vert2 -= BaseSubpixel;
// 半边常量
// 8.16 fixed point
float C0 = Edge01.y * Vert0.x - Edge01.x * Vert0.y;
float C1 = Edge12.y * Vert1.x - Edge12.x * Vert1.y;
float C2 = Edge20.y * Vert2.x - Edge20.x * Vert2.y;
// 校正填充规则
// Top left rule for CCW
C0 -= saturate(Edge01.y + saturate(1.0f - Edge01.x));
C1 -= saturate(Edge12.y + saturate(1.0f - Edge12.x));
C2 -= saturate(Edge20.y + saturate(1.0f - Edge20.x));
float Z0 = Verts[0].z - ( GradZ.x * Vert0.x + GradZ.y * Vert0.y );
GradZ *= SUBPIXEL_SAMPLES;
// 计算步进常量, 和SUBPIXEL_SAMPLES相关, SUBPIXEL_SAMPLES越大, 步进越小, 光栅化结果越精准, 但消耗越大.
float CY0 = C0 * (1.0f / SUBPIXEL_SAMPLES);
float CY1 = C1 * (1.0f / SUBPIXEL_SAMPLES);
float CY2 = C2 * (1.0f / SUBPIXEL_SAMPLES);
float ZY = Z0;
// 是否使用扫描线
#if COMPILER_SUPPORTS_WAVE_VOTE
bool bScanLine = WaveActiveAnyTrue( MaxPixel.x - MinPixel.x > 4 );
#else
bool bScanLine = false;
#endif
if( bScanLine ) // 扫描线算法.
{
float3 Edge012 = { Edge01.y, Edge12.y, Edge20.y };
bool3 bOpenEdge = Edge012 < 0;
float3 InvEdge012 = Edge012 == 0 ? 1e8 : rcp( Edge012 );
int y = MinPixel.y;
while( true )
{
// No longer fixed point
float3 CrossX = float3( CY0, CY1, CY2 ) * InvEdge012;
float3 MinX = bOpenEdge ? CrossX : 0;
float3 MaxX = bOpenEdge ? MaxPixel.x - MinPixel.x : CrossX;
float x0 = ceil( max3( MinX.x, MinX.y, MinX.z ) );
float x1 = min3( MaxX.x, MaxX.y, MaxX.z );
float ZX = ZY + GradZ.x * x0;
x0 += MinPixel.x;
x1 += MinPixel.x;
// 遍历x方向上的所有像素, 写入像素数据.
for( float x = x0; x <= x1; x++ )
{
// 写入像素值和深度值.
WritePixel(OutVisBuffer64, PixelValue, uint2(x,y), ZX, NaniteView, bUsePageTable);
#if VISUALIZE
WritePixel(OutDbgBuffer64, VisualizeValues.x, uint2(x,y), ZX, NaniteView, bUsePageTable);
InterlockedAdd(OutDbgBuffer32[uint2(x,y)], VisualizeValues.y);
#endif
ZX += GradZ.x;
}
if( y >= MaxPixel.y )
break;
// 增加Y方向的步进
CY0 += Edge01.x;
CY1 += Edge12.x;
CY2 += Edge20.x;
ZY += GradZ.y;
y++;
}
}
else // 非扫描线算法(矩形框算法, 需要检测是否在三角形内部)
{
int y = MinPixel.y;
while (true)
{
int x = MinPixel.x;
// 3个都是正数, 说明在三角形内.
if (min3(CY0, CY1, CY2) >= 0)
{
WritePixel(OutVisBuffer64, PixelValue, uint2(x, y), ZY, NaniteView, bUsePageTable);
#if VISUALIZE
WritePixel(OutDbgBuffer64, VisualizeValues.x, uint2(x, y), ZY, NaniteView, bUsePageTable);
InterlockedAdd(OutDbgBuffer32[uint2(x, y)], VisualizeValues.y);
#endif
}
if (x < MaxPixel.x)
{
float CX0 = CY0 - Edge01.y;
float CX1 = CY1 - Edge12.y;
float CX2 = CY2 - Edge20.y;
float ZX = ZY + GradZ.x;
x++;
HOIST_DESCRIPTORS
while (true)
{
if (min3(CX0, CX1, CX2) >= 0)
{
WritePixel(OutVisBuffer64, PixelValue, uint2(x, y), ZX, NaniteView, bUsePageTable);
#if VISUALIZE
WritePixel(OutDbgBuffer64, VisualizeValues.x, uint2(x, y), ZX, NaniteView, bUsePageTable);
InterlockedAdd(OutDbgBuffer32[uint2(x, y)], VisualizeValues.y);
#endif
}
if (x >= MaxPixel.x)
break;
CX0 -= Edge01.y;
CX1 -= Edge12.y;
CX2 -= Edge20.y;
ZX += GradZ.x;
x++;
}
}
if (y >= MaxPixel.y)
break;
CY0 += Edge01.x;
CY1 += Edge12.x;
CY2 += Edge20.x;
ZY += GradZ.y;
y++;
}
}
}
#if USE_CONSTRAINED_CLUSTERS
groupshared float3 GroupVerts[256];
#else
groupshared float3 GroupVerts[384];
#endif
// 检测裁剪模式, 模式是顺时针(CW). 如果返回true, 需要逆时针(CCW).
bool ReverseWindingOrder(FInstanceSceneData InstanceData)
{
bool bReverseInstanceCull = (InstanceData.InvNonUniformScaleAndDeterminantSign.w < 0.0f);
bool bRasterStateReverseCull = (RenderFlags & RENDER_FLAG_REVERSE_CULLING);
// Logical XOR
return (bReverseInstanceCull != bRasterStateReverseCull);
}
StructuredBuffer< uint2 > InTotalPrevDrawClusters;
Buffer<uint> InClusterOffsetSWHW;
groupshared float4x4 LocalToSubpixelLDS;
// 微表面光栅化, 用于Nanite的CS软光栅.
[numthreads(128, 1, 1)]
void MicropolyRasterize(
uint VisibleIndex : SV_GroupID,
uint GroupIndex : SV_GroupIndex)
{
// 计算可见索引.
#if HAS_PREV_DRAW_DATA
VisibleIndex += InTotalPrevDrawClusters[0].x;
#endif
#if ADD_CLUSTER_OFFSET
VisibleIndex += InClusterOffsetSWHW[0];
#endif
// 获取可见的Cluster和实例数据.
FVisibleCluster VisibleCluster = GetVisibleCluster( VisibleIndex, VIRTUAL_TEXTURE_TARGET );
FInstanceSceneData InstanceData = GetInstanceData( VisibleCluster.InstanceId );
// 获取Nanite视图.
FNaniteView NaniteView = GetNaniteView( VisibleCluster.ViewId );
// 获取页面信息.
#if CLUSTER_PER_PAGE
// Scalar
uint2 vPage = VisibleCluster.vPage;
FShadowPhysicalPage pPage = ShadowGetPhysicalPage( CalcPageTableLevelOffset( NaniteView.TargetLayerIndex, NaniteView.TargetMipLevel ) + CalcPageOffsetInLevel( NaniteView.TargetMipLevel, vPage ) );
#endif
float4x4 LocalToSubpixel;
// InstancedDynamicData是Group不变的, 所以只需计算一次, 然后存储在groupshared的变量中以供后续使用.
if( GroupIndex == 0 )
{
LocalToSubpixel = CalculateInstanceDynamicData(NaniteView, InstanceData).LocalToClip;
float2 Scale = float2( 0.5, -0.5 ) * NaniteView.ViewSizeAndInvSize.xy * SUBPIXEL_SAMPLES;
float2 Bias = ( 0.5 * NaniteView.ViewSizeAndInvSize.xy + NaniteView.ViewRect.xy ) * SUBPIXEL_SAMPLES + 0.5f;
#if CLUSTER_PER_PAGE
Bias += ( (float2)pPage.PageIndex - (float2)vPage ) * VSM_PAGE_SIZE * SUBPIXEL_SAMPLES;
#endif
LocalToSubpixel._m00_m10_m20_m30 = LocalToSubpixel._m00_m10_m20_m30 * Scale.x + LocalToSubpixel._m03_m13_m23_m33 * Bias.x;
LocalToSubpixel._m01_m11_m21_m31 = LocalToSubpixel._m01_m11_m21_m31 * Scale.y + LocalToSubpixel._m03_m13_m23_m33 * Bias.y;
LocalToSubpixelLDS = LocalToSubpixel;
}
// 使用Group内存屏障以同步Group数据.
GroupMemoryBarrierWithGroupSync();
LocalToSubpixel = LocalToSubpixelLDS;
// 获取Cluster数据.
FCluster Cluster = GetCluster(VisibleCluster.PageIndex, VisibleCluster.ClusterIndex);
UNROLL
for( uint i = 0; i < 2; i++ )
{
uint VertIndex = GroupIndex + i * 128;
if( VertIndex < Cluster.NumVerts )
{
// 变换顶点, 且保持到组间共享内存中.
float3 PointLocal = DecodePosition( VertIndex, Cluster );
float4 PointClipSubpixel = mul( float4( PointLocal, 1 ), LocalToSubpixel );
float3 Subpixel = PointClipSubpixel.xyz / PointClipSubpixel.w;
GroupVerts[ VertIndex ] = float3(floor(Subpixel.xy), Subpixel.z);
}
}
// 使用Group内存屏障以同步Group数据.
GroupMemoryBarrierWithGroupSync();
int4 ViewRect = NaniteView.ViewRect;
#if CLUSTER_PER_PAGE
ViewRect.xy = pPage.PageIndex * VSM_PAGE_SIZE;
ViewRect.zw = ViewRect.xy + VSM_PAGE_SIZE;
#endif
if (GroupIndex < Cluster.NumTris)
{
// 三角形ID就是Group索引.
uint TriangleID = GroupIndex;
// 生成三角形索引, 同时处理需要翻转的情况.
uint3 TriangleIndices = ReadTriangleIndices(Cluster, TriangleID);
if (ReverseWindingOrder(InstanceData))
{
TriangleIndices = uint3(TriangleIndices.x, TriangleIndices.z, TriangleIndices.y);
}
// 获取三角形位置.
float3 Vertices[3];
Vertices[0] = GroupVerts[TriangleIndices.x];
Vertices[1] = GroupVerts[TriangleIndices.y];
Vertices[2] = GroupVerts[TriangleIndices.z];
// 像素值就是三角形ID.
uint PixelValue = ((VisibleIndex + 1) << 7) | TriangleID;
// 光栅化该三角形, 写入对应的id和深度.
RasterizeTri(
NaniteView,
ViewRect,
PixelValue,
#if VISUALIZE
GetVisualizeValues(),
#endif
Vertices,
!CLUSTER_PER_PAGE );
}
}
#define PIXEL_VALUE (RASTER_TECHNIQUE != RASTER_TECHNIQUE_DEPTHONLY)
#define VERTEX_TO_TRIANGLE_MASKS (NANITE_PRIM_SHADER && PIXEL_VALUE)
struct VSOut
{
noperspective float DeviceZ : TEXCOORD0;
#if PIXEL_VALUE
nointerpolation uint PixelValue : TEXCOORD1;
#endif
#if NANITE_MULTI_VIEW
nointerpolation int4 ViewRect : TEXCOORD2;
#endif
#if VISUALIZE
nointerpolation uint2 VisualizeValues : TEXCOORD3;
#endif
#if VIRTUAL_TEXTURE_TARGET
nointerpolation int ViewId : TEXCOORD4;
#endif
#if VERTEX_TO_TRIANGLE_MASKS
CUSTOM_INTERPOLATION uint4 ToTriangleMasks : TEXCOORD5;
#endif
float4 Position : SV_Position;
};
// 硬件光栅化的VS, 主要是将顶点数据从Cluster中解压出来, 然后变换到裁剪空间.
VSOut CommonRasterizerVS(FNaniteView NaniteView, FInstanceSceneData InstanceData, FVisibleCluster VisibleCluster, FCluster Cluster, uint VertIndex, out float4 PointClipNoScaling)
{
VSOut Out;
float4x4 LocalToWorld = InstanceData.LocalToWorld;
float3 PointLocal = DecodePosition( VertIndex, Cluster );
float3 PointRotated = LocalToWorld[0].xyz * PointLocal.xxx + LocalToWorld[1].xyz * PointLocal.yyy + LocalToWorld[2].xyz * PointLocal.zzz;
float3 PointTranslatedWorld = PointRotated + (LocalToWorld[3].xyz + NaniteView.PreViewTranslation.xyz);
float4 PointClip = mul( float4( PointTranslatedWorld, 1 ), NaniteView.TranslatedWorldToClip );
PointClipNoScaling = PointClip;
#if CLUSTER_PER_PAGE
PointClip.xy = NaniteView.ClipSpaceScaleOffset.xy * PointClip.xy + NaniteView.ClipSpaceScaleOffset.zw * PointClip.w;
// Offset 0,0 to be at vPage for a 0, VSM_PAGE_SIZE * VSM_RASTER_WINDOW_PAGES viewport.
PointClip.xy += PointClip.w * ( float2(-2, 2) / VSM_RASTER_WINDOW_PAGES ) * VisibleCluster.vPage;
Out.ViewRect.xy = VisibleCluster.vPage * VSM_PAGE_SIZE;
Out.ViewRect.zw = NaniteView.ViewRect.zw;
#elif NANITE_MULTI_VIEW
PointClip.xy = NaniteView.ClipSpaceScaleOffset.xy * PointClip.xy + NaniteView.ClipSpaceScaleOffset.zw * PointClip.w;
Out.ViewRect = NaniteView.ViewRect;
#endif
#if VIRTUAL_TEXTURE_TARGET
Out.ViewId = VisibleCluster.ViewId;
#endif
Out.Position = PointClip;
Out.DeviceZ = PointClip.z / PointClip.w;
// Shader workaround to avoid HW depth clipping. Should be replaced with rasterizer state ideally.
#if !NEAR_CLIP
Out.Position.z = 0.5f * Out.Position.w;
#endif
#if VISUALIZE
Out.VisualizeValues = GetVisualizeValues();
#endif
return Out;
}
#if NANITE_PRIM_SHADER
#pragma argument(wavemode=wave64)
#pragma argument(realtypes)
struct PrimitiveInput
{
uint Index : PRIM_SHADER_SEM_VERT_INDEX;
uint WaveIndex : PRIM_SHADER_SEM_WAVE_INDEX;
};
struct PrimitiveOutput
{
VSOut Out;
uint PrimExport : PRIM_SHADER_SEM_PRIM_EXPORT;
uint VertCount : PRIM_SHADER_SEM_VERT_COUNT;
uint PrimCount : PRIM_SHADER_SEM_PRIM_COUNT;
};
// 压缩三角形索引, 其中x,y,z的位数是10,10,12.
uint PackTriangleExport(uint3 TriangleIndices)
{
return TriangleIndices.x | (TriangleIndices.y << 10) | (TriangleIndices.z << 20);
}
// 解压三角形索引.
uint3 UnpackTriangleExport(uint Packed)
{
const uint Index0 = (Packed & 0x3FF); // 提取前10位.
const uint Index1 = (Packed >> 10) & 0x3FF; // 提取中间10位
const uint Index2 = (Packed >> 20); // 提取后12位.
return uint3(Index0, Index1, Index2);
}
#if VERTEX_TO_TRIANGLE_MASKS // 三角形掩码渲染模式.
groupshared uint GroupVertexToTriangleMasks[256][4];
#endif
groupshared uint GroupTriangleCount;
groupshared uint GroupVertexCount;
groupshared uint GroupClusterIndex;
PRIM_SHADER_OUTPUT_TRIANGLES
PRIM_SHADER_PRIM_COUNT(1)
PRIM_SHADER_VERT_COUNT(1)
PRIM_SHADER_VERT_LIMIT(256)
PRIM_SHADER_AMP_FACTOR(128)
PRIM_SHADER_AMP_ENABLE
// 硬件光栅化VS入口(三角形掩码渲染模式).
PrimitiveOutput HWRasterizeVS(PrimitiveInput Input)
{
const uint LaneIndex = WaveGetLaneIndex();
const uint LaneCount = WaveGetLaneCount();
const uint GroupThreadID = LaneIndex + Input.WaveIndex * LaneCount;
if (GroupThreadID == 0)
{
// Input index is only initialized for lane 0, so we need to manually communicate it to all other threads in subgroup (not just wavefront).
GroupClusterIndex = Input.Index;
}
GroupMemoryBarrierWithGroupSync();
// 下面的代码和MicropolyRasterize类型, 省略之.
uint VisibleIndex = GroupClusterIndex;
#if HAS_PREV_DRAW_DATA
VisibleIndex += InTotalPrevDrawClusters[0].y;
#endif
#if ADD_CLUSTER_OFFSET
VisibleIndex += InClusterOffsetSWHW[GetHWClusterCounterIndex(RenderFlags)];
#endif
VisibleIndex = (MaxVisibleClusters - 1) - VisibleIndex;
// Should be all scalar.
FVisibleCluster VisibleCluster = GetVisibleCluster( VisibleIndex, VIRTUAL_TEXTURE_TARGET );
FInstanceSceneData InstanceData = GetInstanceData( VisibleCluster.InstanceId );
FNaniteView NaniteView = GetNaniteView( VisibleCluster.ViewId );
FInstanceDynamicData InstanceDynamicData = CalculateInstanceDynamicData(NaniteView, InstanceData);
FCluster Cluster = GetCluster(VisibleCluster.PageIndex, VisibleCluster.ClusterIndex);
#if VERTEX_TO_TRIANGLE_MASKS
if (GroupThreadID < Cluster.NumVerts)
{
GroupVertexToTriangleMasks[GroupThreadID][0] = 0;
GroupVertexToTriangleMasks[GroupThreadID][1] = 0;
GroupVertexToTriangleMasks[GroupThreadID][2] = 0;
GroupVertexToTriangleMasks[GroupThreadID][3] = 0;
}
#endif
GroupMemoryBarrierWithGroupSync();
PrimitiveOutput PrimOutput;
PrimOutput.VertCount = Cluster.NumVerts;
PrimOutput.PrimCount = Cluster.NumTris;
bool bCullTriangle = false;
if (GroupThreadID < Cluster.NumTris)
{
uint TriangleID = GroupThreadID;
uint3 TriangleIndices = ReadTriangleIndices(Cluster, TriangleID);
if (ReverseWindingOrder(InstanceData))
{
TriangleIndices = uint3(TriangleIndices.x, TriangleIndices.z, TriangleIndices.y);
}
#if VERTEX_TO_TRIANGLE_MASKS
const uint DwordIndex = (GroupThreadID >> 5) & 3;
const uint TriangleMask = 1 << (GroupThreadID & 31);
InterlockedOr(GroupVertexToTriangleMasks[TriangleIndices.x][DwordIndex], TriangleMask);
InterlockedOr(GroupVertexToTriangleMasks[TriangleIndices.y][DwordIndex], TriangleMask);
InterlockedOr(GroupVertexToTriangleMasks[TriangleIndices.z][DwordIndex], TriangleMask);
#endif
PrimOutput.PrimExport = PackTriangleExport(TriangleIndices);
}
GroupMemoryBarrierWithGroupSync();
if (GroupThreadID < Cluster.NumVerts)
{
float4 PointClipNoScaling;
// 光栅化三角形.
PrimOutput.Out = CommonRasterizerVS(NaniteView, InstanceData, VisibleCluster, Cluster, GroupThreadID, PointClipNoScaling);
#if VERTEX_TO_TRIANGLE_MASKS
PrimOutput.Out.PixelValue = ((VisibleIndex + 1) << 7);
PrimOutput.Out.ToTriangleMasks = uint4(GroupVertexToTriangleMasks[GroupThreadID][0],
GroupVertexToTriangleMasks[GroupThreadID][1],
GroupVertexToTriangleMasks[GroupThreadID][2],
GroupVertexToTriangleMasks[GroupThreadID][3]);
#endif
}
return PrimOutput;
}
#else // NANITE_PRIM_SHADER(Nanite图元着色模式)
// 硬件光栅化VS入口(图元着色模式).
VSOut HWRasterizeVS(
uint VertexID : SV_VertexID,
uint VisibleIndex : SV_InstanceID
)
{
#if HAS_PREV_DRAW_DATA
VisibleIndex += InTotalPrevDrawClusters[0].y;
#endif
#if ADD_CLUSTER_OFFSET
VisibleIndex += InClusterOffsetSWHW[GetHWClusterCounterIndex(RenderFlags)];
#endif
VisibleIndex = (MaxVisibleClusters - 1) - VisibleIndex;
uint TriIndex = VertexID / 3;
VertexID = VertexID - TriIndex * 3;
VSOut Out;
Out.Position = float4(0,0,0,1);
Out.DeviceZ = 0.0f;
FVisibleCluster VisibleCluster = GetVisibleCluster( VisibleIndex, VIRTUAL_TEXTURE_TARGET );
FInstanceSceneData InstanceData = GetInstanceData( VisibleCluster.InstanceId );
FNaniteView NaniteView = GetNaniteView( VisibleCluster.ViewId );
FCluster Cluster = GetCluster(VisibleCluster.PageIndex, VisibleCluster.ClusterIndex);
if( TriIndex < Cluster.NumTris )
{
uint3 TriangleIndices = ReadTriangleIndices( Cluster, TriIndex );
if( ReverseWindingOrder( InstanceData ) )
{
TriangleIndices = uint3( TriangleIndices.x, TriangleIndices.z, TriangleIndices.y );
}
uint VertIndex = TriangleIndices[ VertexID ];
float4 PointClipNoScaling;
// 光栅化三角形.
Out = CommonRasterizerVS(NaniteView, InstanceData, VisibleCluster, Cluster, VertIndex, PointClipNoScaling);
#if PIXEL_VALUE
Out.PixelValue = ((VisibleIndex + 1) << 7) | TriIndex;
#endif
}
return Out;
}
#endif // NANITE_PRIM_SHADER
// 硬件光栅化的PS入口.
void HWRasterizePS(VSOut In)
{
uint2 PixelPos = (uint2)In.Position.xy;
uint PixelValue = 0;
#if PIXEL_VALUE
PixelValue = In.PixelValue;
#endif
#if VERTEX_TO_TRIANGLE_MASKS
uint4 Masks0 = LoadParameterCacheP0( In.ToTriangleMasks );
uint4 Masks1 = LoadParameterCacheP1( In.ToTriangleMasks );
uint4 Masks2 = LoadParameterCacheP2( In.ToTriangleMasks );
uint4 Masks = Masks0 & Masks1 & Masks2;
uint TriangleIndex = Masks.x ? firstbitlow( Masks.x ) :
Masks.y ? firstbitlow( Masks.y ) + 32 :
Masks.z ? firstbitlow( Masks.z ) + 64 :
firstbitlow( Masks.w ) + 96;
PixelValue += TriangleIndex;
#endif
#if VIRTUAL_TEXTURE_TARGET
FNaniteView NaniteView = GetNaniteView(In.ViewId);
#else
FNaniteView NaniteView;
#endif
#if CLUSTER_PER_PAGE
PixelPos += In.ViewRect.xy;
if (all(PixelPos < In.ViewRect.zw))
#elif NANITE_MULTI_VIEW
// In multi-view mode every view has its own scissor, so we have to scissor manually.
if (all(PixelPos >= In.ViewRect.xy && PixelPos < In.ViewRect.zw))
#endif
{
// 写入像素数据: 三角形id(PixelValue), 深度(In.DeviceZ)
WritePixel(OutVisBuffer64, PixelValue, PixelPos, In.DeviceZ, NaniteView, VIRTUAL_TEXTURE_TARGET);
#if VISUALIZE
WritePixel(OutDbgBuffer64, In.VisualizeValues.x, PixelPos, In.DeviceZ, NaniteView, VIRTUAL_TEXTURE_TARGET);
InterlockedAdd(OutDbgBuffer32[PixelPos], In.VisualizeValues.y);
#endif
}
}
从上面的分析可知,无论是软件光栅还是硬件光栅,写入数据的只有ClusterID、三角形ID和深度(如果是可视化模式还有其它数据),也就是说此阶段并没有真正地着色,而是类似于延迟渲染的BasePass,但输出的信息远没有BasePass的多,由此产生的IO、显存都显著降低。其实这个技术就是Visibility Buffer技术,具体可以参见剖析虚幻渲染体系(04)- 延迟渲染管线的小节4.2.3.5 Visibility Buffer。

Nanite光栅化后的存储结构:ClusterID占25位,三角形ID占7位,深度占32位。

Nanite光栅化后的结果示意图,从上到下依次是ClusterID、三角形ID、深度。
在Nanite光栅化之后,还有个重要的步骤是Nanite::EmitDepthTargets,它的作用在于场景的深度、模板、速度、材质深度等缓冲数据:

其中模板缓冲表示哪些像素是被Nanite渲染的:

而最有意思的是材质深度,表明位于场景最前面的每个像素被哪个材质所覆盖,本质上是一个转换为唯一深度值并存储在深度模板纹理中的材质ID。实际上,每种材质都有一个灰度值,以便后续将利用Early Z进行优化。

6.4.3.6 Nanite BasePass
本小节主要阐述Nanite的BasePass对GBuffer的生成。其在FDeferredShadingSceneRenderer::Render主流程如下:
void FDeferredShadingSceneRenderer::Render(FRDGBuilder& GraphBuilder)
{
(......)
// 渲染Nanite的BasePass.
{
// 绘制普通模式的BasePass.
RenderBasePass(GraphBuilder, SceneTextures, DBufferTextures, BasePassDepthStencilAccess, ForwardScreenSpaceShadowMaskTexture, InstanceCullingManager);
AddServiceLocalQueuePass(GraphBuilder);
if (bNaniteEnabled && bShouldApplyNaniteMaterials)
{
for (int32 ViewIndex = 0; ViewIndex < Views.Num(); ++ViewIndex)
{
const FViewInfo& View = Views[ViewIndex];
Nanite::FRasterResults& RasterResults = NaniteRasterResults[ViewIndex];
// 如果没有提前绘制深度, 则现在绘制深度
if (!bNeedsPrePass)
{
Nanite::EmitDepthTargets(
GraphBuilder,
*Scene,
Views[ViewIndex],
RasterResults.SOAStrides,
RasterResults.VisibleClustersSWHW,
RasterResults.ViewsBuffer,
SceneTextures.Depth.Target,
RasterResults.VisBuffer64,
RasterResults.MaterialDepth,
RasterResults.NaniteMask,
RasterResults.VelocityBuffer,
bNeedsPrePass
);
}
// 绘制Nanite模式的BasePass.
Nanite::DrawBasePass(
GraphBuilder,
SceneTextures,
DBufferTextures,
*Scene,
View,
RasterResults
);
}
}
// 解析场景深度.
if (!bAllowReadOnlyDepthBasePass)
{
AddResolveSceneDepthPass(GraphBuilder, Views, SceneTextures.Depth);
}
(......)
}
(......)
}
需要注意的是,上面有两次BasePass的绘制:一次是传统的BasePass绘制RenderBasePass,另一次是Nanite模式的BasePass绘制Nanite::DrawBasePass。下面是Nanite::DrawBasePass的解析:
// Engine\Source\Runtime\Renderer\Private\Nanite\NaniteRender.cpp
void DrawBasePass(
FRDGBuilder& GraphBuilder,
const FSceneTextures& SceneTextures,
const FDBufferTextures& DBufferTextures,
const FScene& Scene,
const FViewInfo& View,
const FRasterResults& RasterResults
)
{
(......)
RDG_EVENT_SCOPE(GraphBuilder, "Nanite::BasePass");
const int32 ViewWidth = View.ViewRect.Max.X - View.ViewRect.Min.X;
const int32 ViewHeight = View.ViewRect.Max.Y - View.ViewRect.Min.Y;
const FIntPoint ViewSize = FIntPoint(ViewWidth, ViewHeight);
const FRDGSystemTextures& SystemTextures = FRDGSystemTextures::Get(GraphBuilder);
FRenderTargetBindingSlots GBufferRenderTargets;
SceneTextures.GetGBufferRenderTargets(ERenderTargetLoadAction::ELoad, GBufferRenderTargets);
// 初始化纹理引用.
FRDGTextureRef MaterialDepth = RasterResults.MaterialDepth ? RasterResults.MaterialDepth : SystemTextures.Black;
FRDGTextureRef VisBuffer64 = RasterResults.VisBuffer64 ? RasterResults.VisBuffer64 : SystemTextures.Black;
FRDGTextureRef DbgBuffer64 = RasterResults.DbgBuffer64 ? RasterResults.DbgBuffer64 : SystemTextures.Black;
FRDGTextureRef DbgBuffer32 = RasterResults.DbgBuffer32 ? RasterResults.DbgBuffer32 : SystemTextures.Black;
FRDGBufferRef VisibleClustersSWHW = RasterResults.VisibleClustersSWHW;
// 检测材质裁剪模式. 波操作需要SM6才支持,不支持的平台将切换成4.
if (!FDataDrivenShaderPlatformInfo::GetSupportsWaveOperations(GMaxRHIShaderPlatform) &&
(GNaniteMaterialCulling == 1 || GNaniteMaterialCulling == 2))
{
UE_LOG(LogNanite, Warning, TEXT("r.Nanite.MaterialCulling set to %d which requires wave-ops (not supported on this platform), switching to mode 4"), GNaniteMaterialCulling);
GNaniteMaterialCulling = 4;
}
// 使用局部赋值, 可以不用修改全部视图达到覆盖的目的.
int32 NaniteMaterialCulling = GNaniteMaterialCulling;
if ((NaniteMaterialCulling == 1 || NaniteMaterialCulling == 2) && (View.ViewRect.Min.X != 0 || View.ViewRect.Min.Y != 0))
{
NaniteMaterialCulling = 4;
static bool bLoggedAlready = false;
if (!bLoggedAlready)
{
bLoggedAlready = true;
UE_LOG(LogNanite, Warning, TEXT("View has non-zero viewport offset, using material culling mode 4 (overrides r.Nanite.MaterialCulling = %d)."), GNaniteMaterialCulling);
}
}
// 位掩码裁剪
const bool b32BitMaskCulling = (NaniteMaterialCulling == 1 || NaniteMaterialCulling == 2);
// 分块裁剪
const bool bTileGridCulling = (NaniteMaterialCulling == 3 || NaniteMaterialCulling == 4);
const FIntPoint TileGridDim = bTileGridCulling ? FMath::DivideAndRoundUp(ViewSize, { 64, 64 }) : FIntPoint(1, 1);
// 创建纹理和缓冲.
FRDGBufferDesc VisibleMaterialsDesc = FRDGBufferDesc::CreateStructuredDesc(4, b32BitMaskCulling ? FNaniteCommandInfo::MAX_STATE_BUCKET_ID+1 : 1);
FRDGBufferRef VisibleMaterials = GraphBuilder.CreateBuffer(VisibleMaterialsDesc, TEXT("Nanite.VisibleMaterials"));
FRDGBufferUAVRef VisibleMaterialsUAV = GraphBuilder.CreateUAV(VisibleMaterials);
FRDGTextureDesc MaterialRangeDesc = FRDGTextureDesc::Create2D(TileGridDim, PF_R32G32_UINT, FClearValueBinding::Black, TexCreate_ShaderResource | TexCreate_UAV);
FRDGTextureRef MaterialRange = GraphBuilder.CreateTexture(MaterialRangeDesc, TEXT("Nanite.MaterialRange"));
FRDGTextureUAVRef MaterialRangeUAV = GraphBuilder.CreateUAV(MaterialRange);
FRDGTextureSRVDesc MaterialRangeSRVDesc = FRDGTextureSRVDesc::Create(MaterialRange);
FRDGTextureSRVRef MaterialRangeSRV = GraphBuilder.CreateSRV(MaterialRangeSRVDesc);
// 清理纹理缓冲
AddClearUAVPass(GraphBuilder, VisibleMaterialsUAV, 0);
AddClearUAVPass(GraphBuilder, MaterialRangeUAV, { 0u, 1u, 0u, 0u });
// 分类材质以分块裁剪
if (b32BitMaskCulling || bTileGridCulling)
{
FClassifyMaterialsCS::FParameters* PassParameters = GraphBuilder.AllocParameters<FClassifyMaterialsCS::FParameters>();
PassParameters->View = View.ViewUniformBuffer;
PassParameters->VisibleClustersSWHW = GraphBuilder.CreateSRV(VisibleClustersSWHW);
PassParameters->SOAStrides = RasterResults.SOAStrides;
PassParameters->ClusterPageData = Nanite::GStreamingManager.GetClusterPageDataSRV();
PassParameters->ClusterPageHeaders = Nanite::GStreamingManager.GetClusterPageHeadersSRV();
PassParameters->VisBuffer64 = VisBuffer64;
PassParameters->MaterialDepthTable = Scene.MaterialTables[ENaniteMeshPass::BasePass].GetDepthTableSRV();
uint32 DispatchGroupSize = 0;
PassParameters->ViewRect = FIntVector4(View.ViewRect.Min.X, View.ViewRect.Min.Y, View.ViewRect.Max.X, View.ViewRect.Max.Y);
if (b32BitMaskCulling)
{
checkf(View.ViewRect.Min.X == 0 && View.ViewRect.Min.Y == 0, TEXT("Viewport offset support is not implemented."));
DispatchGroupSize = 8;
PassParameters->VisibleMaterials = VisibleMaterialsUAV;
}
else if (bTileGridCulling)
{
DispatchGroupSize = 64;
PassParameters->FetchClamp = View.ViewRect.Max - 1;
PassParameters->MaterialRange = MaterialRangeUAV;
}
const FIntVector DispatchDim = FComputeShaderUtils::GetGroupCount(View.ViewRect.Max - View.ViewRect.Min, DispatchGroupSize);
FClassifyMaterialsCS::FPermutationDomain PermutationVector;
PermutationVector.Set<FClassifyMaterialsCS::FCullingMethodDim>(NaniteMaterialCulling);
auto ComputeShader = View.ShaderMap->GetShader<FClassifyMaterialsCS>(PermutationVector.ToDimensionValueId());
// 分类材质的CS Pass.
FComputeShaderUtils::AddPass(
GraphBuilder,
RDG_EVENT_NAME("Classify Materials"),
ComputeShader,
PassParameters,
DispatchDim
);
}
// 渲染GBuffer.
{
// 处理Pass数据
FNaniteEmitGBufferParameters* PassParameters = GraphBuilder.AllocParameters<FNaniteEmitGBufferParameters>();
PassParameters->SOAStrides = RasterResults.SOAStrides;
PassParameters->MaxVisibleClusters = RasterResults.MaxVisibleClusters;
PassParameters->MaxNodes = RasterResults.MaxNodes;
PassParameters->RenderFlags = RasterResults.RenderFlags;
PassParameters->ClusterPageData = Nanite::GStreamingManager.GetClusterPageDataSRV();
PassParameters->ClusterPageHeaders = Nanite::GStreamingManager.GetClusterPageHeadersSRV();
PassParameters->VisibleClustersSWHW = GraphBuilder.CreateSRV(VisibleClustersSWHW);
PassParameters->MaterialRange = MaterialRange;
PassParameters->VisibleMaterials = GraphBuilder.CreateSRV(VisibleMaterials, PF_R32_UINT);
PassParameters->VisBuffer64 = VisBuffer64; // 可见性
PassParameters->DbgBuffer64 = DbgBuffer64;
PassParameters->DbgBuffer32 = DbgBuffer32;
PassParameters->RenderTargets = GBufferRenderTargets; // 渲染纹理
// Uniform Buffer
PassParameters->View = View.ViewUniformBuffer; // To get VTFeedbackBuffer
PassParameters->BasePass = CreateOpaqueBasePassUniformBuffer(GraphBuilder, View, 0, {}, DBufferTextures, nullptr);
switch (NaniteMaterialCulling)
{
// 使用8x4的格子渲染, 共32bit, 每个bit一个tile.
case 1:
case 2:
PassParameters->GridSize.X = 8;
PassParameters->GridSize.Y = 4;
break;
// 用64x64的像素分块渲染.
case 3:
case 4:
PassParameters->GridSize = FMath::DivideAndRoundUp(View.ViewRect.Max - View.ViewRect.Min, { 64, 64 });
break;
// 使用全屏方块渲染.
default:
PassParameters->GridSize.X = 1;
PassParameters->GridSize.Y = 1;
break;
}
const FExclusiveDepthStencil MaterialDepthStencil = UseComputeDepthExport()
? FExclusiveDepthStencil::DepthWrite_StencilNop
: FExclusiveDepthStencil::DepthWrite_StencilWrite;
PassParameters->RenderTargets.DepthStencil = FDepthStencilBinding(
MaterialDepth,
ERenderTargetLoadAction::ELoad,
ERenderTargetLoadAction::ELoad,
MaterialDepthStencil
);
TShaderMapRef<FNaniteMaterialVS> NaniteVertexShader(View.ShaderMap);
// 增加渲染pass.
GraphBuilder.AddPass(
RDG_EVENT_NAME("Emit GBuffer"),
PassParameters,
ERDGPassFlags::Raster,
[PassParameters, &Scene, NaniteVertexShader, ViewRect = View.ViewRect, NaniteMaterialCulling](FRHICommandListImmediate& RHICmdList)
{
RHICmdList.SetViewport(ViewRect.Min.X, ViewRect.Min.Y, 0.0f, ViewRect.Max.X, ViewRect.Max.Y, 1.0f);
// 处理全局缓冲参数.
FNaniteUniformParameters UniformParams;
UniformParams.SOAStrides = PassParameters->SOAStrides;
UniformParams.MaxVisibleClusters= PassParameters->MaxVisibleClusters;
UniformParams.MaxNodes = PassParameters->MaxNodes;
UniformParams.RenderFlags = PassParameters->RenderFlags;
UniformParams.MaterialConfig.X = NaniteMaterialCulling;
UniformParams.MaterialConfig.Y = PassParameters->GridSize.X;
UniformParams.MaterialConfig.Z = PassParameters->GridSize.Y;
UniformParams.MaterialConfig.W = 0;
UniformParams.RectScaleOffset = FVector4(1.0f, 1.0f, 0.0f, 0.0f); // Render a rect that covers the entire screen
// 材质裁剪模式
if (NaniteMaterialCulling == 3 || NaniteMaterialCulling == 4)
{
FIntPoint ScaledSize = PassParameters->GridSize * 64;
UniformParams.RectScaleOffset.X = float(ScaledSize.X) / float(ViewRect.Max.X - ViewRect.Min.X);
UniformParams.RectScaleOffset.Y = float(ScaledSize.Y) / float(ViewRect.Max.Y - ViewRect.Min.Y);
}
// Cluster页面及可见性数据
UniformParams.ClusterPageData = PassParameters->ClusterPageData;
UniformParams.ClusterPageHeaders = PassParameters->ClusterPageHeaders;
UniformParams.VisibleClustersSWHW = PassParameters->VisibleClustersSWHW->GetRHI();
// 材质数据
UniformParams.MaterialRange = PassParameters->MaterialRange->GetRHI();
UniformParams.VisibleMaterials = PassParameters->VisibleMaterials->GetRHI();
// 可见性数据
UniformParams.VisBuffer64 = PassParameters->VisBuffer64->GetRHI();
UniformParams.DbgBuffer64 = PassParameters->DbgBuffer64->GetRHI();
UniformParams.DbgBuffer32 = PassParameters->DbgBuffer32->GetRHI();
const_cast<FScene&>(Scene).UniformBuffers.NaniteUniformBuffer.UpdateUniformBufferImmediate(UniformParams);
FGraphicsMinimalPipelineStateSet GraphicsMinimalPipelineStateSet;
TArray<FNaniteMaterialPassCommand, SceneRenderingAllocator> NaniteMaterialPassCommands;
// 构建Nanite材质Pass的命令.
BuildNaniteMaterialPassCommands(RHICmdList, Scene.NaniteDrawCommands[ENaniteMeshPass::BasePass], NaniteMaterialPassCommands);
FMeshDrawCommandStateCache StateCache;
const uint32 TileCount = UniformParams.MaterialConfig.Y * UniformParams.MaterialConfig.Z; // (W * H)
// 遍历所有材质通道命令, 逐个提交.
for (auto CommandsIt = NaniteMaterialPassCommands.CreateConstIterator(); CommandsIt; ++CommandsIt)
{
SubmitNaniteMaterialPassCommand(*CommandsIt, NaniteVertexShader, GraphicsMinimalPipelineStateSet, TileCount, RHICmdList, StateCache);
}
});
}
}
在渲染BasePass之前,需要执行材质分类Pass,以对材质进行分类(Classify Material),对后续的材质剔除等操作有着重要作用。它用Compute Shader分析全屏的Visibility Buffer,输出20x12=240的像素(被称为材质范围,格式是R32G32_UINT),每个像素(材质范围)对每个分块表示的64×64区域中出现的材质范围进行了编码。它呈现的颜色如下所示:

上面代码涉及的Wave Operation翻译成波操作,是DX的概念,VK至于对应的概念是Subgroup,只有SM6以上才支持。具体可以参见GDC2017的Talk:Wave-Programming-D3D12-Vulkan。
上面代码构建Nanite材质Pass的绘制指令时的源数据是Scene.NaniteDrawCommands[ENaniteMeshPass::BasePass],该数据是在FPrimitiveSceneInfo::UpdateStaticMeshes时生成的,调用堆栈如下:
// Engine\Source\Runtime\Renderer\Private\PrimitiveSceneInfo.cpp
void FPrimitiveSceneInfo::UpdateStaticMeshes(FRHICommandListImmediate& RHICmdList, FScene* Scene, const TArrayView<FPrimitiveSceneInfo*>& SceneInfos, bool bReAddToDrawLists)
{
(......)
if (bReAddToDrawLists)
{
CacheMeshDrawCommands(RHICmdList, Scene, SceneInfos);
// 缓存Nanite绘制指令.
CacheNaniteDrawCommands(RHICmdList, Scene, SceneInfos);
}
}
void FPrimitiveSceneInfo::CacheNaniteDrawCommands(FRHICommandListImmediate& RHICmdList, FScene* Scene, const TArrayView<FPrimitiveSceneInfo*>& SceneInfos)
{
(......)
// 遍历场景的所有图元场景信息, 逐个构建Nanite绘制指令.
for (FPrimitiveSceneInfo* PrimitiveSceneInfo : SceneInfos)
{
BuildNaniteDrawCommands(RHICmdList, Scene, PrimitiveSceneInfo);
}
(......)
}
void BuildNaniteDrawCommands(FRHICommandListImmediate& RHICmdList, FScene* Scene, FPrimitiveSceneInfo* PrimitiveSceneInfo)
{
(......)
for (int32 MeshPass = 0; MeshPass < ENaniteMeshPass::Num; ++MeshPass)
{
FNaniteDrawListContext NaniteDrawListContext(Scene->NaniteDrawCommandLock[MeshPass], Scene->NaniteDrawCommands[MeshPass]);
// 创建Nanite模式的MeshProcessor.
FMeshPassProcessor* NaniteMeshProcessor = nullptr;
switch (MeshPass)
{
case ENaniteMeshPass::BasePass:
NaniteMeshProcessor = CreateNaniteMeshProcessor(Scene, nullptr, &NaniteDrawListContext);
break;
case ENaniteMeshPass::LumenCardCapture:
NaniteMeshProcessor = CreateLumenCardNaniteMeshProcessor(Scene, nullptr, &NaniteDrawListContext);
break;
default:
check(false);
}
// 遍历所有静态网格, 对支持Nanite渲染的网格构建Nanite绘制指令.
int32 StaticMeshesCount = PrimitiveSceneInfo->StaticMeshes.Num();
for (int32 MeshIndex = 0; MeshIndex < StaticMeshesCount; ++MeshIndex)
{
FStaticMeshBatchRelevance& MeshRelevance = PrimitiveSceneInfo->StaticMeshRelevances[MeshIndex];
FStaticMeshBatch& Mesh = PrimitiveSceneInfo->StaticMeshes[MeshIndex];
if (MeshRelevance.bSupportsNaniteRendering)
{
uint64 BatchElementMask = ~0ull;
// 向MeshProcessor加入网格批次, 后续的步骤跟传统的类似, 不再追踪.
NaniteMeshProcessor->AddMeshBatch(Mesh, BatchElementMask, Proxy);
FNaniteCommandInfo CommandInfo = NaniteDrawListContext.GetCommandInfoAndReset();
PrimitiveSceneInfo->NaniteCommandInfos[MeshPass].Add(CommandInfo);
const uint32 MaterialDepthId = CommandInfo.GetMaterialId();
const uint32 SectionIndex = Mesh.SegmentIndex;
PrimitiveSceneInfo->NaniteMaterialIds[MeshPass][SectionIndex] = MaterialDepthId;
}
}
NaniteMeshProcessor->~FMeshPassProcessor();
}
(......)
}
下面继续解析Nanite::DrawBasePass的两个重要接口BuildNaniteMaterialPassCommands和SubmitNaniteMaterialPassCommand:
// Engine\Source\Runtime\Renderer\Private\Nanite\NaniteRender.cpp
// 构建Nanite材质Pass的命令
static void BuildNaniteMaterialPassCommands(
FRHICommandListImmediate& RHICmdList,
const FStateBucketMap& NaniteDrawCommands,
TArray<FNaniteMaterialPassCommand, SceneRenderingAllocator>& OutNaniteMaterialPassCommands)
{
OutNaniteMaterialPassCommands.Reset(NaniteDrawCommands.Num());
FGraphicsMinimalPipelineStateSet GraphicsMinimalPipelineStateSet;
const int32 MaterialSortMode = GNaniteMaterialSortMode;
// 遍历所有Nanite绘制指令, 构建对应的FNaniteMaterialPassCommand.
for (auto& Command : NaniteDrawCommands)
{
// 构建FNaniteMaterialPassCommand实例.
FNaniteMaterialPassCommand PassCommand(Command.Key);
Experimental::FHashElementId SetId = NaniteDrawCommands.FindId(Command.Key);
int32 DrawIdx = SetId.GetIndex();
PassCommand.MaterialDepth = FNaniteCommandInfo::GetDepthId(DrawIdx);
// 使用渲染状态的排序键值替换原有的.
if (MaterialSortMode == 2 && GRHISupportsPipelineStateSortKey)
{
const FMeshDrawCommand& MeshDrawCommand = Command.Key;
const FGraphicsMinimalPipelineStateInitializer& MeshPipelineState = MeshDrawCommand.CachedPipelineId.GetPipelineState(GraphicsMinimalPipelineStateSet);
FGraphicsPipelineState* PipelineState = PipelineStateCache::GetAndOrCreateGraphicsPipelineState(RHICmdList, MeshPipelineState.AsGraphicsPipelineStateInitializer(), EApplyRendertargetOption::DoNothing);
if (PipelineState)
{
const uint64 StateSortKey = PipelineStateCache::RetrieveGraphicsPipelineStateSortKey(PipelineState);
if (StateSortKey != 0)
{
PassCommand.SortKey = StateSortKey;
}
}
}
// 添加到命令列表.
OutNaniteMaterialPassCommands.Emplace(PassCommand);
}
// 排序材质.
if (MaterialSortMode != 0)
{
OutNaniteMaterialPassCommands.Sort();
}
}
// 提交单个材质通道绘制命令
static void SubmitNaniteMaterialPassCommand(
const FMeshDrawCommand& MeshDrawCommand,
const float MaterialDepth,
const TShaderRef<FNaniteMaterialVS>& NaniteVertexShader,
const FGraphicsMinimalPipelineStateSet& GraphicsMinimalPipelineStateSet,
const uint32 InstanceFactor,
FRHICommandList& RHICmdList,
FMeshDrawCommandStateCache& StateCache)
{
// 提交绘制开始.
FMeshDrawCommand::SubmitDrawBegin(MeshDrawCommand, GraphicsMinimalPipelineStateSet, nullptr, 0, InstanceFactor, RHICmdList, StateCache);
// 所有Nanite网格绘制指令都是使用相同的VS, 该命令拥有在渲染时刻赋值的材质深度.
{
FNaniteMaterialVS::FParameters Parameters;
Parameters.MaterialDepth = MaterialDepth;
SetShaderParameters(RHICmdList, NaniteVertexShader, NaniteVertexShader.GetVertexShader(), Parameters);
}
// 提交绘制结束.
FMeshDrawCommand::SubmitDrawEnd(MeshDrawCommand, InstanceFactor, RHICmdList);
}
不过奇怪的是,绘制BasePass只指定了VS,而没有指定PS,那么PS究竟在哪里设置的或者本来就是空的?为了探明真相,利用RenderDoc截帧分析,发现PS使用的依然是传统的BasePassPixelShader,并且经过此阶段之后渲染的GBuffer和传统的基本一致:

左上:渲染画面,右上:GBufferA,左下:GBufferB,右下:GBufferC
Nanite在渲染BasePass的过程中,是以材质为Pass来进行提交的,这意味着,可以利用之前渲染的材质范围纹理和材质深度进行快速剔除,以下面了两图为例:

在渲染上面的第一幅图的材质区域时,会根据材质深度和材质范围来快速判断和剔除像素,如第二幅图所示,红色方框表示其覆盖的所有像素均没有通过材质范围检测,会被顶点着色器完全抛弃,而绿色的像素则表示通过了深度测试和材质范围测试,将送入PS执行GBuffer的输出。
6.4.3.7 Nanite光影
Nanite的光影计算和传统的光影混夹在一起,都在RenderLights接口中:
// Engine\Source\Runtime\Renderer\Private\LightRendering.cpp
void FDeferredShadingSceneRenderer::RenderLights(
FRDGBuilder& GraphBuilder,
FMinimalSceneTextures& SceneTextures,
const FTranslucencyLightingVolumeTextures& TranslucencyLightingVolumeTextures,
FRDGTextureRef LightingChannelsTexture,
FSortedLightSetSceneInfo& SortedLightSet)
{
(......)
const FSimpleLightArray &SimpleLights = SortedLightSet.SimpleLights;
const TArray<FSortedLightSceneInfo, SceneRenderingAllocator> &SortedLights = SortedLightSet.SortedLights;
const int32 AttenuationLightStart = SortedLightSet.AttenuationLightStart;
const int32 SimpleLightsEnd = SortedLightSet.SimpleLightsEnd;
(......)
{
RDG_EVENT_SCOPE(GraphBuilder, "DirectLighting");
if (ViewFamily.EngineShowFlags.DirectLighting &&
Strata::IsStrataEnabled() && Strata::IsClassificationEnabled())
{
// 更新模板缓冲, 为所有后续的Pass只标记一次简单/复杂的阶层材质.
Strata::AddStrataStencilPass(GraphBuilder, Views, SceneTextures);
}
(......)
// 无阴影光照.
if(ViewFamily.EngineShowFlags.DirectLighting)
{
RDG_EVENT_SCOPE(GraphBuilder, "NonShadowedLights");
(......)
}
// 带阴影光照.
{
RDG_EVENT_SCOPE(GraphBuilder, "ShadowedLights");
(......)
// 绘制阴影和带光照函数的光源.
for (int32 LightIndex = AttenuationLightStart; LightIndex < SortedLights.Num(); LightIndex++)
{
(......)
if (bDrawShadows)
{
INC_DWORD_STAT(STAT_NumShadowedLights);
(......)
else // (OcclusionType == FOcclusionType::Shadowmap)
{
(......)
// 清理阴影遮蔽纹理.
ClearShadowMask(ScreenShadowMaskTexture);
// 渲染阴影投射.
RenderDeferredShadowProjections(GraphBuilder, SceneTextures, TranslucencyLightingVolumeTextures, &LightSceneInfo, ScreenShadowMaskTexture, ScreenShadowMaskSubPixelTexture, bInjectedTranslucentVolume);
}
bUsedShadowMaskTexture = true;
}
(......)
if (bDirectLighting)
{
const bool bRenderOverlap = false;
// 渲染单个光源.
RenderLight(GraphBuilder, SceneTextures, &LightSceneInfo, ScreenShadowMaskTexture, LightingChannelsTexture, bRenderOverlap);
}
(......)
}
}
}
}
由于UE5的RenderLights的处理逻辑和UE4高度相似,仅增加了Strata模板的初始化。下面继续看RenderLight的逻辑:
void FDeferredShadingSceneRenderer::RenderLight(
FRHICommandList& RHICmdList,
const FViewInfo& View,
const FLightSceneInfo* LightSceneInfo,
FRHITexture* ScreenShadowMaskTexture,
FRHITexture* LightingChannelsTexture,
bool bRenderOverlap, bool bIssueDrawEvent)
{
(......)
// 渲染光源的内部接口.
auto RenderInternalLight = [&](bool bStrataFastPath)
{
(......)
// 设置Strata深度模板缓冲.
if (Strata::IsStrataEnabled() && Strata::IsClassificationEnabled())
{
GraphicsPSOInit.DepthStencilState = TStaticDepthStencilState<
false, CF_Always,
true, CF_Equal, SO_Keep, SO_Keep, SO_Keep,
true, CF_Equal, SO_Keep, SO_Keep, SO_Keep,
Strata::StencilBit, 0x0>::GetRHI();
}
else
{
GraphicsPSOInit.DepthStencilState = TStaticDepthStencilState<false, CF_Always>::GetRHI();
}
(......)
if (LightProxy->GetLightType() == LightType_Directional)
{
(......)
else
{
(......)
FDeferredLightPS::FPermutationDomain PermutationVector;
(......)
// 增加了Strata(阶层)排序
PermutationVector.Set< FDeferredLightPS::FStrata >(Strata::IsStrataEnabled());
PermutationVector.Set< FDeferredLightPS::FStrataFastPath >(Strata::IsStrataEnabled() && Strata::IsClassificationEnabled() && bStrataFastPath);
TShaderMapRef< FDeferredLightPS > PixelShader( View.ShaderMap, PermutationVector );
(......)
}
(......)
// 设置Strata目标值.
RHICmdList.SetStencilRef(bStrataFastPath ? Strata::StencilBit : 0u);
// 全屏幕绘制平行光.
DrawRectangle(
RHICmdList,
0, 0,
View.ViewRect.Width(), View.ViewRect.Height(),
View.ViewRect.Min.X, View.ViewRect.Min.Y,
View.ViewRect.Width(), View.ViewRect.Height(),
View.ViewRect.Size(),
GetSceneTextureExtent(),
VertexShader,
EDRF_UseTriangleOptimization);
}
else // 非平行光(局部光源)
{
(......)
TShaderMapRef<TDeferredLightVS<true> > VertexShader(View.ShaderMap);
// 相机是否在光源几何体内部.
const bool bCameraInsideLightGeometry = ((FVector)View.ViewMatrices.GetViewOrigin() - LightBounds.Center).SizeSquared() < FMath::Square(LightBounds.W * 1.05f + View.NearClippingDistance * 2.0f)
|| !View.IsPerspectiveProjection();
// 设置绑定几何体光栅化和深度状态, 其中bCameraInsideLightGeometry在此传进入.
SetBoundingGeometryRasterizerAndDepthState(GraphicsPSOInit, View, bCameraInsideLightGeometry);
(......)
else
{
(......)
// Strata.
PermutationVector.Set< FDeferredLightPS::FStrata >(Strata::IsStrataEnabled());
PermutationVector.Set< FDeferredLightPS::FStrataFastPath >(Strata::IsStrataEnabled() && Strata::IsClassificationEnabled() && bStrataFastPath);
TShaderMapRef< FDeferredLightPS > PixelShader( View.ShaderMap, PermutationVector );
(......)
}
(......)
RHICmdList.SetStencilRef(bStrataFastPath ? Strata::StencilBit : 0u);
(......)
// 根据不同类型的局部光选择不同的形状绘制.
if( LightProxy->GetLightType() == LightType_Point ||
LightProxy->GetLightType() == LightType_Rect )
{
StencilingGeometry::DrawSphere(RHICmdList);
}
else if (LightProxy->GetLightType() == LightType_Spot)
{
StencilingGeometry::DrawCone(RHICmdList);
}
}
};
// 调用一次非Strata版本的光源绘制(UE4的光源计算模式).
RenderInternalLight(false);
// 如果开启了Strata, 则再调用一次Strata版本的光源绘制.
if (Strata::IsStrataEnabled() && Strata::IsClassificationEnabled())
{
RenderInternalLight(true);
}
}
而光照的Shader代码也仅仅是增加了对Strata的支持,此处就不展开探讨了。
另外,值得一提的是,UE5的阴影计算使用了虚拟阴影图(VirtualShadowMap,VSM)技术,它是一种新的阴影投射方法,用于提供一致的、高分辨率的阴影、与电影质量的资产和大型开放世界的动态照明。
VSM最早由Markus Giegl等人在2007年提出,并发表了论文Queried Virtual Shadow Maps ,随后又发表了改进篇Fitted Virtual Shadow Maps。多年后的2015年,Olsson Ola等人结合了Clusterred等渲染技术,发表了论文More efficient virtual shadow maps for many lights。
该技术的核心在于它以一种适应性的方式渲染阴影图,即在需要的地方创建更大的阴影贴图分辨率,不需要存储来自前一帧的信息,使其适用于完全动态的场景。因此,它可以保证阴影图亚像素精度的查询,消除了传统阴影图的投影和透视锯齿。
VSM采用虚拟分块阴影图(Virtual Tiled Shadow Mapping)技术,算法描述如下:
- 分配GPU能够支持的最大纹理分辨率(早期一般取4096×40964096×4096,现今16k×16k16k×16k或更高)。
- 沿着X和Y方向划分阴影图成n×nn×n(如16×1616×16)大小相等的分块(每个分块使用最大阴影图纹理分辨率的纹素),因此最大阴影图的有效分辨率相当于(16×4096)×(16×4096)=65536×65536(16×4096)×(16×4096)=65536×65536。针对每个分块:
- 渲染阴影到阴影图纹理(使用分块的光源视锥进行裁剪,且覆盖之前分块的阴影图)。
- 立即使用它来遮蔽场景中被当前阴影图覆盖的部分。

上:使用传统的阴影图,出现了严重的锯齿问题;下:使用了32x32 2048x2048的QVSM,阴影精度得到极大提升。
在UE5的实现中,VSM的最大分辨率为16k×16k16k×16k像素,每个分块(页面)大小为128×128128×128,以便在合理的内存成本下保持较高的性能。分块的分配和渲染只需要根据屏幕上需要着色的像素(基于深度缓冲区的分析)。分块会被缓存在帧之间,除非它们涉及的物体或灯光移动,这进一步提高了性能。
另外,UE5对定向光的阴影采纳了ClipMap技术,以取代CSM获取更高的阴影图分辨率。ClipMap最早于1998年由Christopher C. Tanner等人在论文The clipmap: a virtual mipmap中提出。该技术的核心在于设置一个阴影图mipmap大小的上限,超过这个上限的mipmap会被clip掉(不会加载到内存中):
由此构成了Clipmap Stack(堆栈)和Clipmap Pyramid(金字塔):
当摄像机(视野)发生变化时,需要修改重映射Clipmap Stack的区域,并加载重映射之后的Clipmap数据,使得Clipmap Stack部分和视野相对应:
视野发生变化后的Clipmap更新示意图,此处使用了环形更新(Toroidal Update)来提升性能。
6.4.4 Nanite总结
Nanite技术涉及了渲染前的预处理构建、渲染时的各级粒度裁剪、光栅化、BasePass和Lighting阶段。这期间应用了大量的数据结构、算法、渲染技术以及对应的优化技术。
Nanite并非如之前所传的使用了Geometry Image技术,而是使用了Cluster、ClusterGroup、Page为基础的各级粗糙代表,这种技术可以充分利用预计算提前构建简化的数据以及对应的存储数据,以便在渲染时较高效地重建、索引、处理和渲染Nanite数据,但也导致了Nanite只支持静态网格的缺点。
Nanite的渲染阶段穿插于传统的渲染管线中,先后经历GPUScene更新、流管理、裁剪、光栅化、BasePass和Readback等阶段,充分发挥了GPU-Driven Rendering Pipeline的威力,最终将Nanite的数据良好地呈现到RenderTrage上。每个步骤都历经了众多Pass、渲染技术和优化技巧,比如:裁剪有逐Instance、逐Cluster、逐Page、逐三角形等不同粒度的裁剪,都是GPU Driven的裁剪,以减少CPU和GPU的IO;光栅化阶段默认使用了CS软光栅+PS硬光栅的混合关系,其中CS软光栅负责面积很小的三角光栅化(避免Quad Overdraw),而PS负责面积较大的三角形光栅化,光栅化之后输出的只是三角形ID和深度(Visibility Buffer技术),以减少GBuffer的占用和带宽的消耗;BasePass输出的结果跟传统的一样,存储于GBufferA、GBufferB...之中;后续的光照计算阶段,除了增加Strata模式的支持,其它光照逻辑基本和传统一样。
UE5为了提升阴影的质量和优化阴影的消耗,使用了VSM和Clipmap技术,获得了效果和消耗相平衡的实时阴影渲染。
以下章节将在UE5特辑Part 2呈现:
6.5 Lumen
6.6 其它渲染技术
6.7 本篇总结
特别说明
- 感谢所有参考文献的作者,部分图片来自参考文献和网络,侵删。
- 本系列文章为笔者原创,只发表在博客园上,欢迎分享本文链接,但未经同意,不允许转载!
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
参考文献
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- New Rendering Features
- Nanite Virtualized Geometry
- Lumen Global Illumination and Reflections
- Lumen Technical Details
- Behind the scenes of “Lumen in the Land of Nanite” | Unreal Engine 5
- Unreal Engine 5 Early Access Release Notes
- Virtual Shadow Maps
- 初探虚幻引擎5
- 虚幻引擎5下载学习资源汇总
- 如何评价 Unreal Engine 5 Early-Access?
- Unreal Engine 5 How to Nanite Skeletal Mesh
- UE5 Nanite实现浅析
- UE5 Nanite和Lumen背后的优化技术
- 游戏引擎随笔 0x20:UE5 Nanite 源码解析之渲染篇:BVH 与 Cluster 的 Culling
- Learning Boundary Edges for 3D-Mesh Segmentation
- Family of Graph and Hypergraph Partitioning Software
- METIS Three Phases Coarsening Partitioning Uncoarsening
- METIS: Unstructured Graph Partitioning and Sparse Matrix Ordering System
- Dynamic LZW for Compressing Large Files
- Geometry images
- New Quadric Metric for Simplifying Meshes with Appearance Attributes
- Lock Mesh Edges
- Wave-Programming-D3D12-Vulkan
- GPU-Driven Rendering Pipeline
- Optimizing the Graphics Pipeline with Compute
- A Macro View of Nanite
- DynamicOcclusionWithSignedDistanceFields
- Queried Virtual Shadow Maps
- Fitted Virtual Shadow Maps
- More efficient virtual shadow maps for many lights
- 剖析虚幻渲染体系(06)- UE5特辑Part 1(特性和Nanite之Nanite基础与数据构建篇)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









