







 本文深入探讨了OpenCV中的watershed算法,基于Meyer的基本思想,详细介绍了算法流程,包括构建标记图、使用优先级队列进行处理,并讨论了核心数据结构。通过棋盘距离确定像素优先级,算法在遇到已有标签的邻域时建立分水岭。
本文深入探讨了OpenCV中的watershed算法,基于Meyer的基本思想,详细介绍了算法流程,包括构建标记图、使用优先级队列进行处理,并讨论了核心数据结构。通过棋盘距离确定像素优先级,算法在遇到已有标签的邻域时建立分水岭。
¨
参
考文献:
Meyer, F.Color Image Segmentation, ICIP92,1992
基本思想:
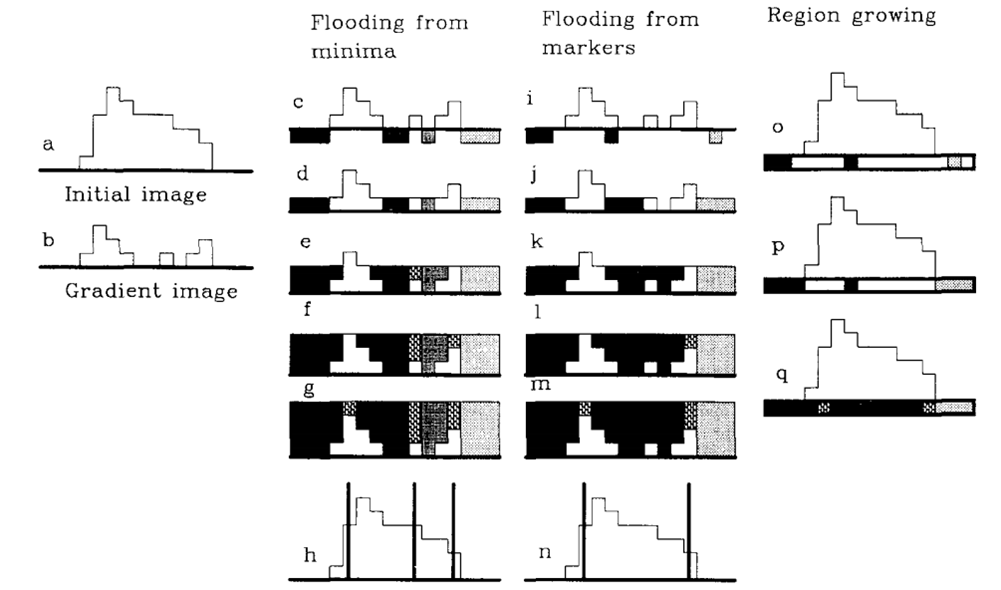
算法流程:
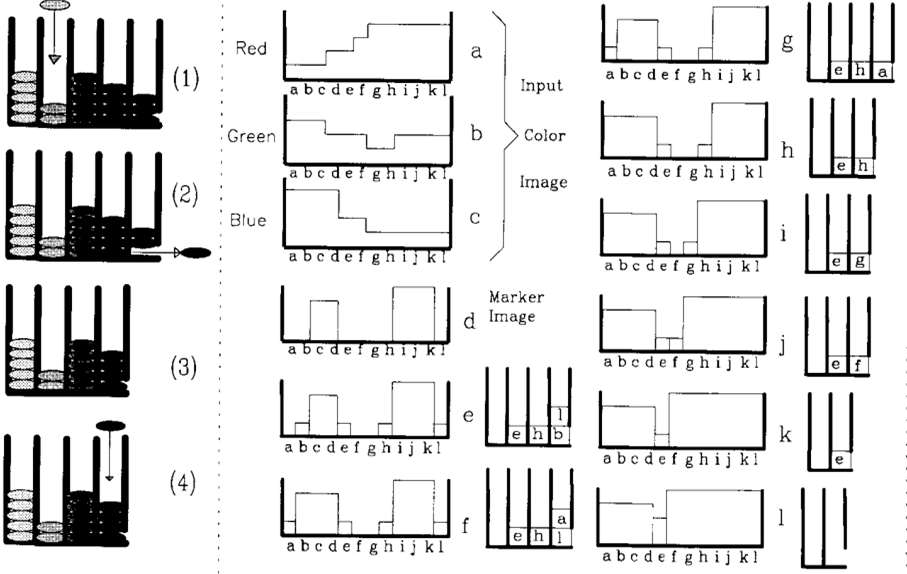
(1)首先得到mark标记图,标记区域的值为1,2...L,未标记区域为0,分水岭区域为-1(图像边界预先标记为分水岭)
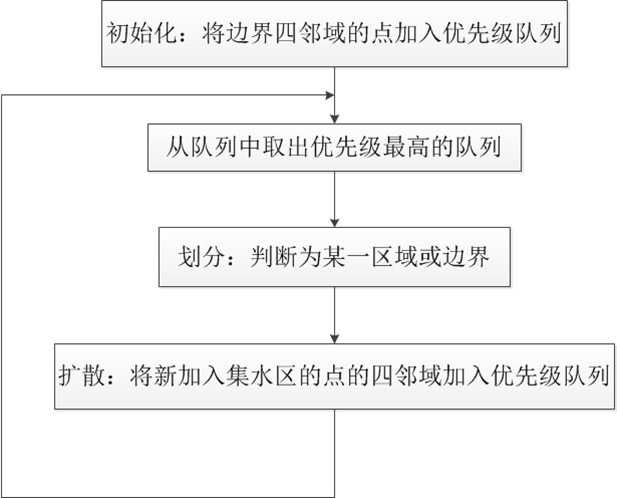
(2)将mark区域的四邻域加入到优先级队列,优先级为0,1,...255 ,取决于两像素点rgb距离中最大的值(也可以称为棋盘距离吧)
while(!queue.empty())
从优先级最高的队列开始,出队
如果,其4邻域不存在其他label,那么4邻域就统统归它所有,同样对于俘获的像素也安装其与该出队的元素之间的距离作为优先级加入队列
如果,其周围已经有其它的label了,那么画地为界,该像素充当分水岭,标记为-1
优先级队列及一维算法示例:
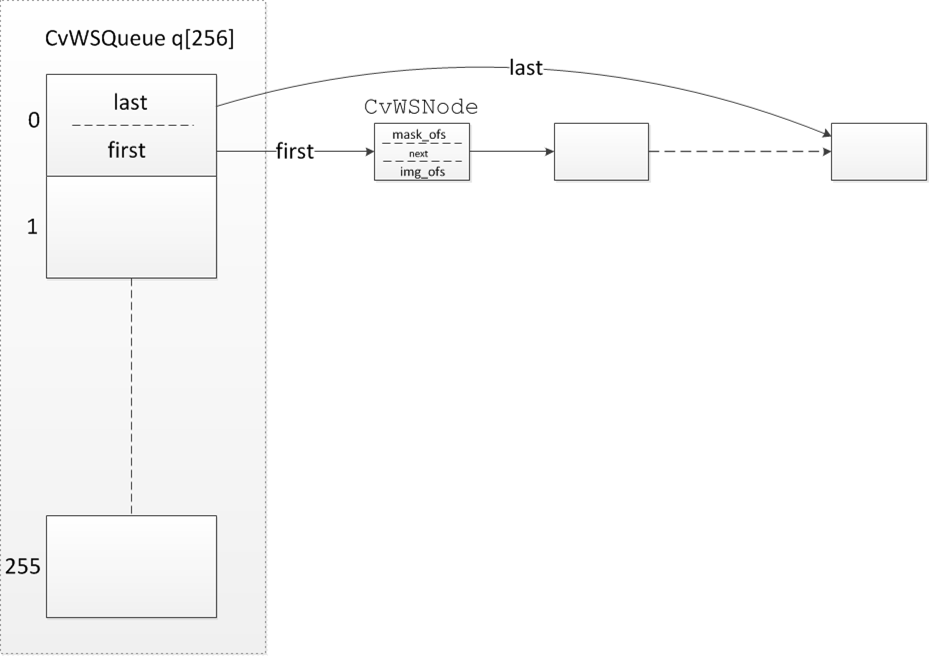
核心数据结构:
源码注释:
typedef struct CvWSNode //像素节点
{
struct CvWSNode* next;
int mask_ofs; //该节点对于mask中的偏移
int img_ofs; //该节点对于原图像中的偏移
}
CvWSNode;
typedef struct CvWSQueue //同等级像素队列
{
CvWSNode* first;
CvWSNode* last;
}
CvWSQueue;
static CvWSNode*
icvAllocWSNodes( CvMemStorage* storage )
{
CvWSNode* n = 0;
//改内存块的总大小,减去内存块链接需要的空间,/一个节点的大小,得到的就是能存放节点的个数
//减去1,可能是为了安全起见
int i, count = (storage->block_size - sizeof(CvMemBlock))/sizeof(*n) - 1;
//向该内存块要空间,搞成线性链表
n = (CvWSNode*)cvMemStorageAlloc( storage, count*sizeof(*n) );
for( i = 0; i < count-1; i++ )
n[i].next = n + i + 1;
n[count-1].next = 0;
return n;
}
CV_IMPL void
cvWatershed( const 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









