







一、决策树的基本思想
决策树(Decision Tree)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。
决策树算法的核心是要解决两个问题:
1)如何从数据表中找出最佳节点和最佳分枝?
2)如何让决策树停止生长,防止过拟合?
1. 决策树模型的建树依据
(1)决策树模型的建树依据主要用到的是基尼系数概念。
基尼系数(gini)用于计算一个系统中的失序现象,即系统的混乱程度越高,基尼系数越高,建立决策树模型的目的就是降低系统的混乱程度,从而得到合适的数据分类效果。
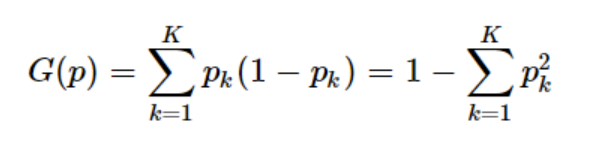
其中Pk为类别k在样本T中出现的频率
信息熵用以描述信源的不确定度, 概率越大,可能性越大,但是信息量越小,不确定性越小,熵越小。
决策树采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处的熵值为0,此时每个叶子节点中的实例都属于同一类。
二、决策树的代码实现
2.1. 决策树sklearn基本思想
from sklearn import tree #导入需要的模块
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(X_train,y_train) #用训练集数据训练模型
result = clf.score(X_test,y_test) #导入测试集,从接口中调用需要的信息
sklearn.tree.DecisionTreeClassifier
八个参数: Criterion,两个随机性相关的参数(random_state,splitter),五个剪枝参数(max_depth,
min_samples_split,min_samples_leaf,max_feature,min_impurity_decrease)
一个属性: feature_importances_
四个接口: fit,score,apply,predict参数:
1、criterion:{“gini”, “entropy”}, default=”gini” 信息增益计算指标, 基尼指数信息熵
2、 splitter: {“best”, “random”}, default=”best” best选择最优切分方案, random,
随机选择. 3、 max_depth: int, default=None 限制树能增长到的最大深度. 限制模型过拟合的参数.
4、min_samples_split: int or float, default=2 最小样本分裂个数.
只有当一个节点当中的样本个数,超过这个值的时候, 才能够继续向下分裂.整数: 就是样本个数 小数: 百分比 5、
min_samples_leaf:int or float, default=1 叶节点最小样本个数. 分裂之后的叶节点样本个数. 6、
max_features:int, float or {“auto”, “sqrt”, “log2”},
default=None寻找最佳分割时要考虑的特征数量.If int,考虑几个 If float, 百分比 0.6 随机选择60%的特征,
寻找最优的. If “auto”, ‘sqrt’ 根号个特征. If “log2” 对数个 If None, 所有特征都考虑 7、
random_state: 随机数种子8、max_leaf_nodes:int, default=None 最大叶节点个数.
9、min_impurity_decrease:float, default=0.0 最小不纯度下降.
每次分裂不纯度都会下降,下降越多分裂效果越好, 如果一次分裂下降不到这个参数值, 就不再向下分裂.10、 class_weight: 类别权重 用于处理不平衡数据集.
2.2 重要参数
1. criterion :不纯度指标计算方式
不纯度越低,决策树对训练集的拟合越好。现在使用的决策树算法在分枝方法上的核心大多是围绕在对某个不纯度相关指标的最优化上。不纯度基于节点来计算,树中的每个节点都会有一个不纯度,并且子节点的不纯度一定是低于父节点的,也就是说,在同一棵决策树上,叶子节点的不纯度一定是最低的。
- 输入”entropy“,使用信息熵(Entropy)
- 输入”gini“,使用基尼系数(Gini Impurity)
- 不填默认是使用基尼系数
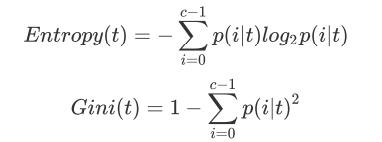
其中t代表给定的节点,i代表标签的任意分类, p(i|t)代表标签分类i在节点t上所占的比例。注意,当使用信息熵时,sklearn实际计算的是基于信息熵的信息增益(Information Gain),即父节点的信息熵和子节点的信息熵之差.
不纯度越低,决策树对训练集的拟合越好。
决策树的基本流程:
(1)计算全部特征的不纯度指标
(2)选取不纯度指标最优的特征进行分支
(3)在第一个特征的分支下,计算全部特征的不纯度指标
(4)选取不纯度指标最优的特征继续进行分支
直到没有更多的特征可用,或是整体的不纯度指标已经最优,决策树就会停止生长。
下面我们以白酒数据集为例画一棵树:
- 导入需要的算法库和模块
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









