







MIPS最终还是失败了,最可惜的是, 它既不是败给了对手,也不是败给了技术,而是败给了自己,败给了市场。MIPS的失败充分说明了,人美活儿好不一定能混好,MIPS作为一项处理器的设计技术是顶级的,但是它不识时务,忽视市场变化,几经贱卖,最终沦落到不得不放弃MIPS架构,转头火热的RISCV阵营.曾几何时,风光无两的MIPS是X86服务器的主要挑战者,也曾为RISC阵营扛起过大旗。但风云变幻,三十年河东,三是年河西,曾经的小弟ARM,RISCV,一个成为包括手机在内的移动电子设备的核心部件,另一个在IOT芯片领域做的风生水起.MIPS作为曾经的RISC老大哥的处境,让人唏嘘。
不过,从软件开发的角度,RISCV和MIPS还是很像的,个人感觉它们ISA的相似度至少有90%. RISCV继承了MIPS指令集设计的优雅,辨识度高,设计对称的特点,基本上你认识一半的指令,另一半仅靠猜测就可以识别了, 大大降低了汇编程序员的认知负担。现在写一点儿关于MIPS处理器应用的相关记录文章,一方面是为了小小纪念一下曾经使用了六年的MIPS,虽然学的并不好,另一方面,在RISCV的学习中,MIPS的设计思路也有非常好的借鉴意义。
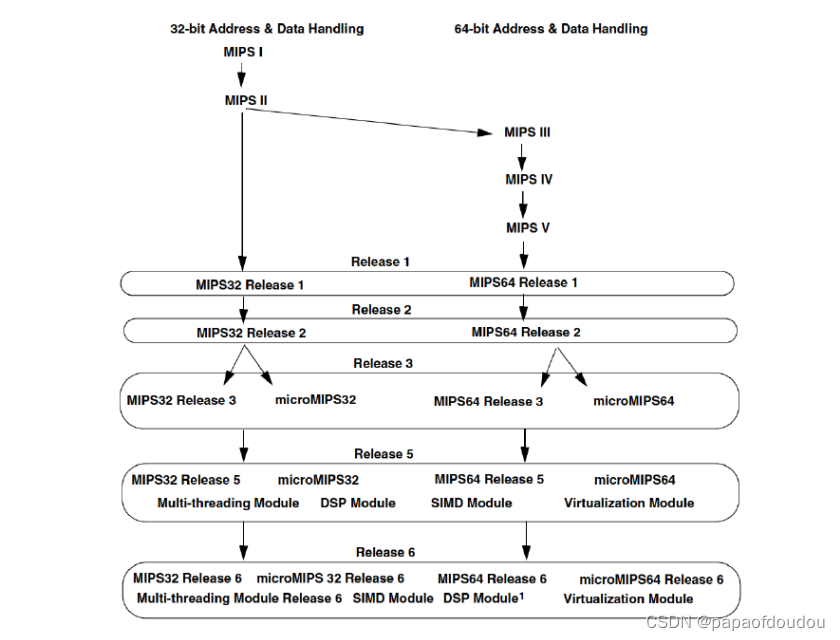
MIPS架构一路走来,历经风雨,指令集总共经历了六版迭代,如下图所示:
体系结构状态和指令集
计算机体系结构包括指令集和体系结构状态,MIPS处理器的体系结构状态包括程序计数器PC和32个寄存器。任何一个MIPS微体系结构都必须包含所有这些状态。基于当前的体系结构状态,处理器执行一条具有特定数据集的特定指令,将产生一个新的体系结构状态。
体系结构的组成如下图所示:
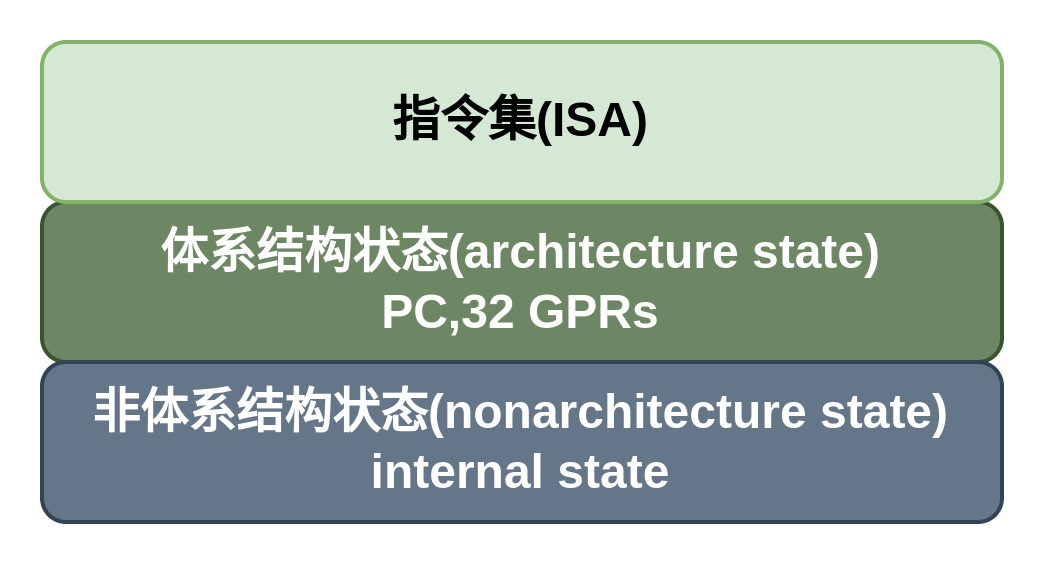
微体系结构可以分为为两个互相作用的部分,数据路径和控制路径,数据路径对数据字进行操作,它包括存储器,寄存器,ALU和复用器等结构,数据路径的位宽也就是处理器的位数。控制路径从数据路径获取当前指令,并控制数据路径如何执行这条指令,具体一点来说,控制单元产生复用器选择,寄存器使能和存储器读写信号来控制数据路径操作。
处理器可以看做一个巨大的有限状态机(FSM),它是一个同步时序电路,微处理器由时钟驱动的状态元件和组合逻辑构成。其中状态元件仅在时钟的上升沿改变它们的状态。所以,整个CPU的状态只有在时钟边沿才能改变。这也是为什么控制路径中,指令存储器,寄存器文件和数据存储器在读的过程中都呈现出组合逻辑的特性,还句话说,如果读地址发生改变,则数据将会立刻出现在读出口,而不需要时钟信号的参与,但是写入过程仅仅发生在时钟的边沿。这样能够保证系统状态只有在时钟边沿时刻发生改变。
指令集ISA
任何程序在处理器中执行计算任务时,都需要通过特定的规范转化成硬件能够理解并处理的语言,这种语言就称为指令集架构(ISA),简称指令集,只能挂机包含了数据类型,基本操作,寄存器位置,寻址模式,读/写方式,中断,异常处理以及外部IO等。每条指令都会描述处理器的一种特定功能,指令集是程序能够使用的处理器全部功能的集合,是处理器功能的抽象,也是计算机系统软硬件之间的接口。
MIPS属于精简指令集RISC,精简指令集是通过定义大量的寄存器和非常规则的指令流水线来简化设计,每条指令所需始终周期数(CPI)较少。RISC中的一大特点是广泛使用load/store架构,在load/store架构下,内存访问必须通过特定指令进行,而不是作为指令集中大部分指令的一部分。而在X86体系架构下,大部分的数据移动指令和算数指令也可以进行内存访问,比如:ADD/SUB/MOV/JMP指令等X86下的指令,均可以直接访问存储器。功能指令和访存之间的解耦是RISC指令集的一大特点。
MIPS的失败不是因为指令集不够好,实际上,曾经有位大佬指出,争论指令集是一个非常悲伤的事,无论那种架构,百分之八十的核心指令和只有六条,分别是加载(Load),存储(Store),加(Add),减(Subtract), 比较(Compare)和分支跳转(Branch).这是因为,要构成图灵完备的逻辑,执行流支持三种基本结构,分别是:
顺序结构:通过PC指针的顺序加减实现。
选择分支结构:通过逻辑比较指令和跳转指令实现。
循环结构:通过调准指令实现。
以上六条指令能够完全cover上面提到的三种执行流。
RISCV指令格式有六种,包括R-type, I-type, S-type, B-type, U-type, J-type. 而MIPS只有三种,分别是R-Type,J-Type,I-Type.
MIPS I-Type的五级流水线如下所示:
I-type指令,有三种类型比如:
运算指令: 例如ori rt, rs, imm16
load/store指令:例如lw rt, rs, imm16
条件分支指令:beq rs, rt, imm16
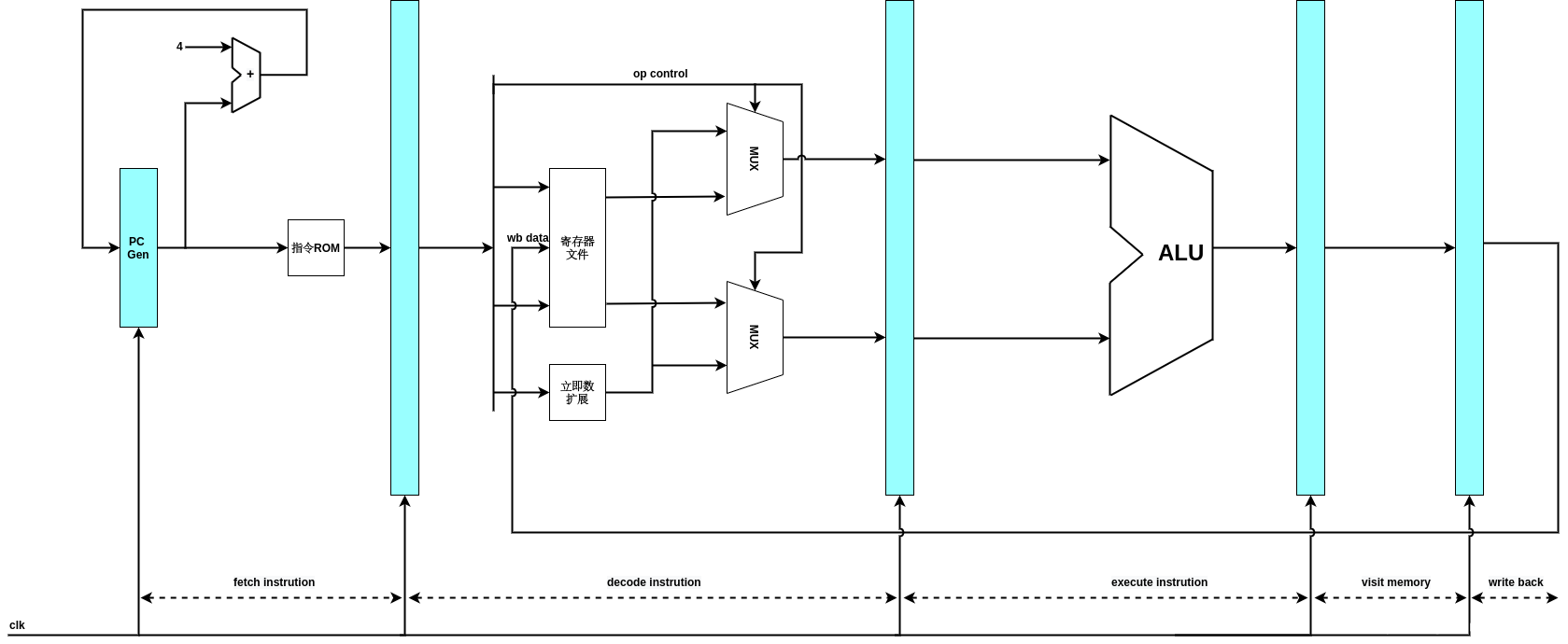
蓝色的部分是时序逻辑,主要是触发器逻辑,用来保存每一级计算的中间结果,它受到时钟信号的驱动,逐级传递.中间是组合逻辑,它的输入来源于上一级的时序逻辑输出部分,经过组合逻辑计算后,将输出送到下一级的时序逻辑输入口.
对于I-type的指令,每一级流水线完成的功能如下:
fetch instruction:取出指令存储器中的指令,PC值递增,准备取下一条指令.
decode:对指令进行译码,根据译码结果,从32个通用寄存器中取出源操作数,有的指令要求两个源操作数都是寄存器的值,比如or指令,有的指令要求其中一个源操作数是指令中立即数的扩展,比如ori指令,所以decode阶段有两个muxer,用于依据指令要求,确定参与运算的操作数,最终确定的两个操作数会送到执行阶段.总结一下,对任意指令而言,译码工作的主要内容是,确定要读取的寄存器情况,要执行的运算,和要写的目的寄存器等三个方面的信息.
execute:依据译码阶段送入的源操作数,操作码,进行运算,这个阶段需要ALU单元的参与,对于ori指令而言,就是在ALU单元中进行逻辑"或"运算,运算结果传递到访存阶段,对于load/store,要进行地址的计算操作.
memory:对于ori指令,在访存阶段没有任何操作,运算结果在这里呆一个时钟周期,会传递到回写阶段,对于访存类指令,这里要进行访问存储器的操作.
writeback:将运算结果保存到目的寄存器.
为了解决指令中出现的RAW相关,将执行阶段的运算结果前递给译码阶段,访存阶段的前递是为了应对装载指令相关的RAW相关.

加入了HI,LO寄存器和HI,LO寄存器访存,回写阶段数据前递的数据流图,HI,LO是寄存器,只是它们不能在MIPS指令的5位寄存器字段中编码。这些“已编号”的寄存器通过特殊的指令识别,属于特殊寄存器,用来存放乘除的结果.
在整个流水线中,除了regfile模块和HI.LO模块中由于写入操作引入了时钟信号外,其它阶段都是组合逻辑,不需要始终信号.尤其是ALU单元,进行的纯粹的组合逻辑数学计算.甚至指令ROM都不需要时钟驱动,因为它本身是只写的.在openmips流水线里面,ROM读操作是不需要时钟驱动的.

如同寄存器文件一样,HI,LO寄存器的读是组合逻辑,但是写是时序逻辑,需要一个使能位和时钟触发,所以也需要在回写阶段的写口前进行前递,这里的实现逻辑如下:
Regfile前递:


HI,LO数据前递.
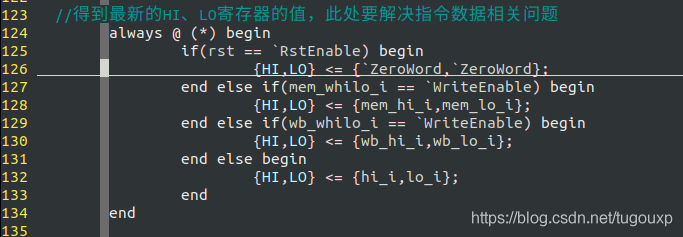
在decode instruction阶段,完整的4字节指令编码便会转换为各种控制信号和数据产生信号,后续流水线阶段不会在出现这条完整的指令编码,但由它产生的各种电信号,时时刻刻影响着整条流水线.所以,你可以看到,在id.v文件里面没有clk输入,但是在regfile.v和hilo.v中需要用时钟信号作为输入.
下一步,增加一个muxer,用来确定PC值,PC值在下一个时钟周期的值可以是PC+4,也可以保持当前值不变,后者对应的就是流水线暂停的情况.
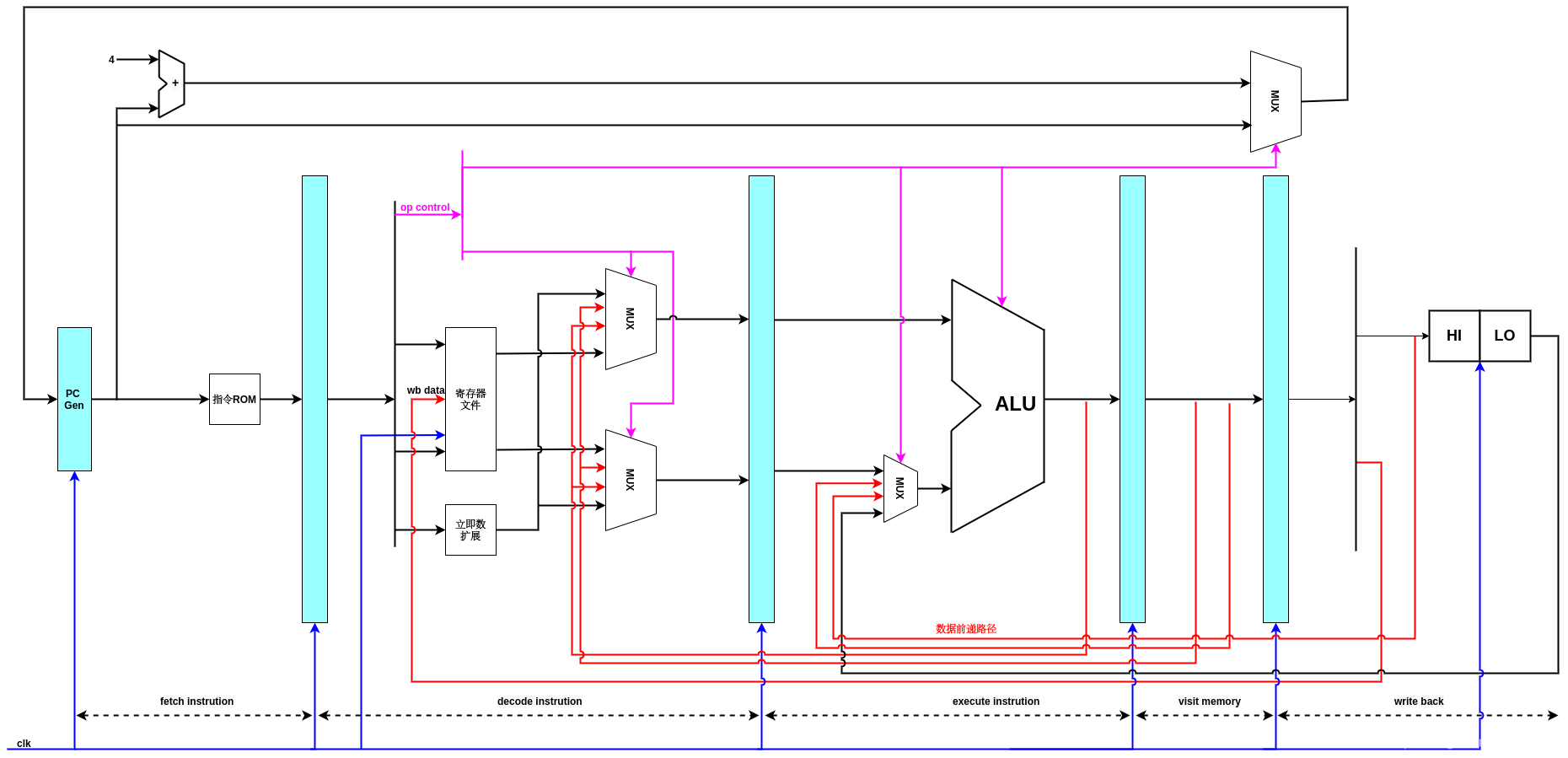
流水线暂停的情况发生在执行阶段需要多个时钟周期才能完成的情况下,比如MACs乘累加和除法操作,尤其是除法,需要较多的时钟周期才能完成,这个时候,需要发出freeze信号(也叫stall信号),冻结执行流水线阶段之前的阶段的推进,等执行阶段完成之后,在继续流水线.
下图是增加了跳转指令逻辑的流水线结构:
增加了跳转逻辑的支持后,PC muxer多了一条输入信号,它代表转移判断的结果,如果是转移指令,且满足转移条件,那么会通过这条路径将转移的目标地址赋给PC.

为了实现数据加载/存储指令,修改数据流图如下所示,主要是在访存阶段增加了对数据存储器SRAM的访问,同时,由于要写入目的寄存器的数据可能是执行阶段的结果,也可能是在访存阶段从数据存储器RAM加载得来的数据,所以在访存阶段增加了一个多路选择器,进行选择.
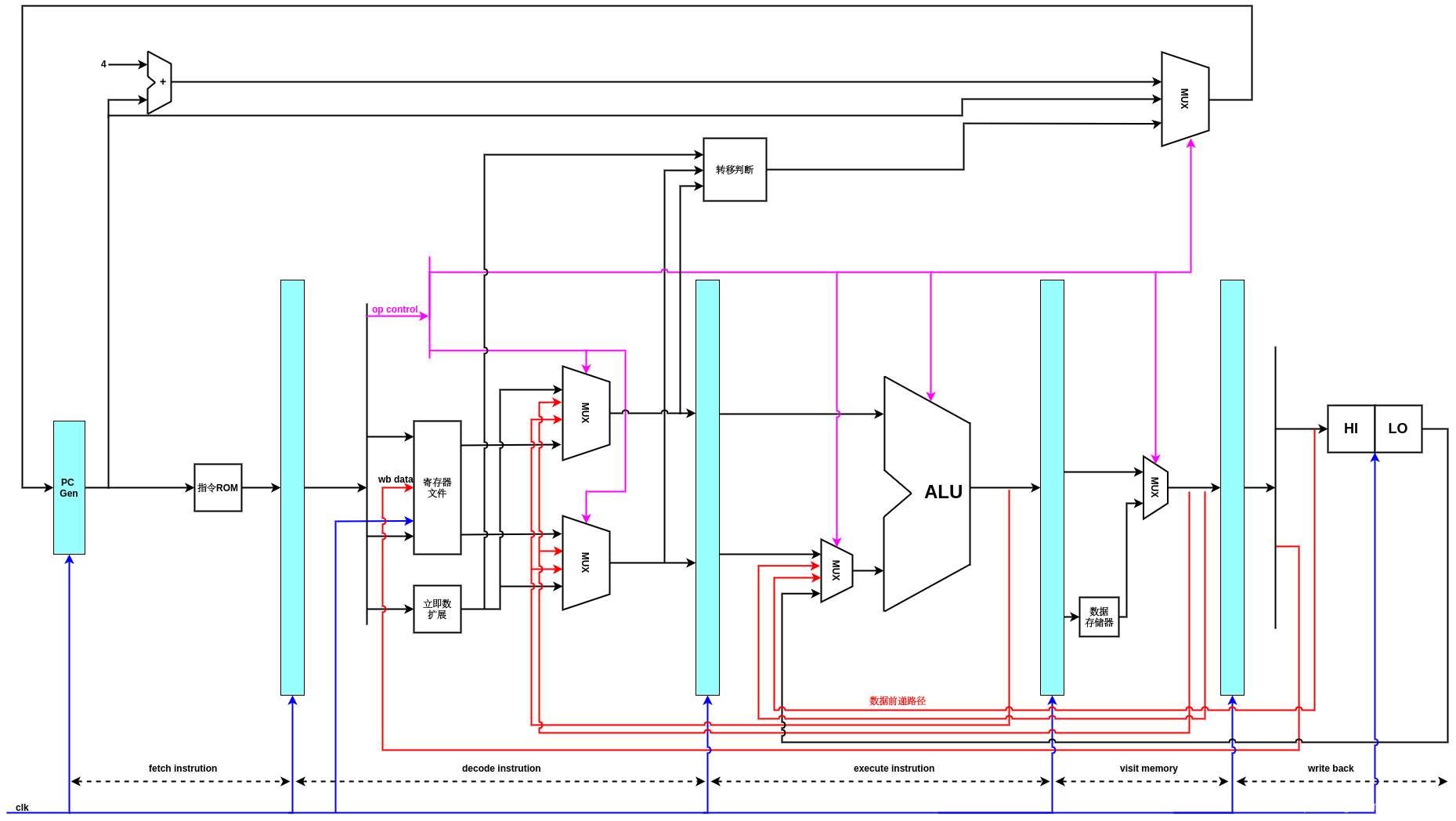
增加LLBit寄存器的数据流,用来实现链接加载,存储指令(LL,SC)后的流水线:
注意,这里可能还有一些问题,由于sc判断发生在访存阶段,而LLBit的引入之值是基于LLBIt寄存器中的值,这两个中间相隔了两个时钟周期(访存->回写以及LLBIT的写时序),所以如果sc指令紧挨ll指令的情况下,会有一些问题.

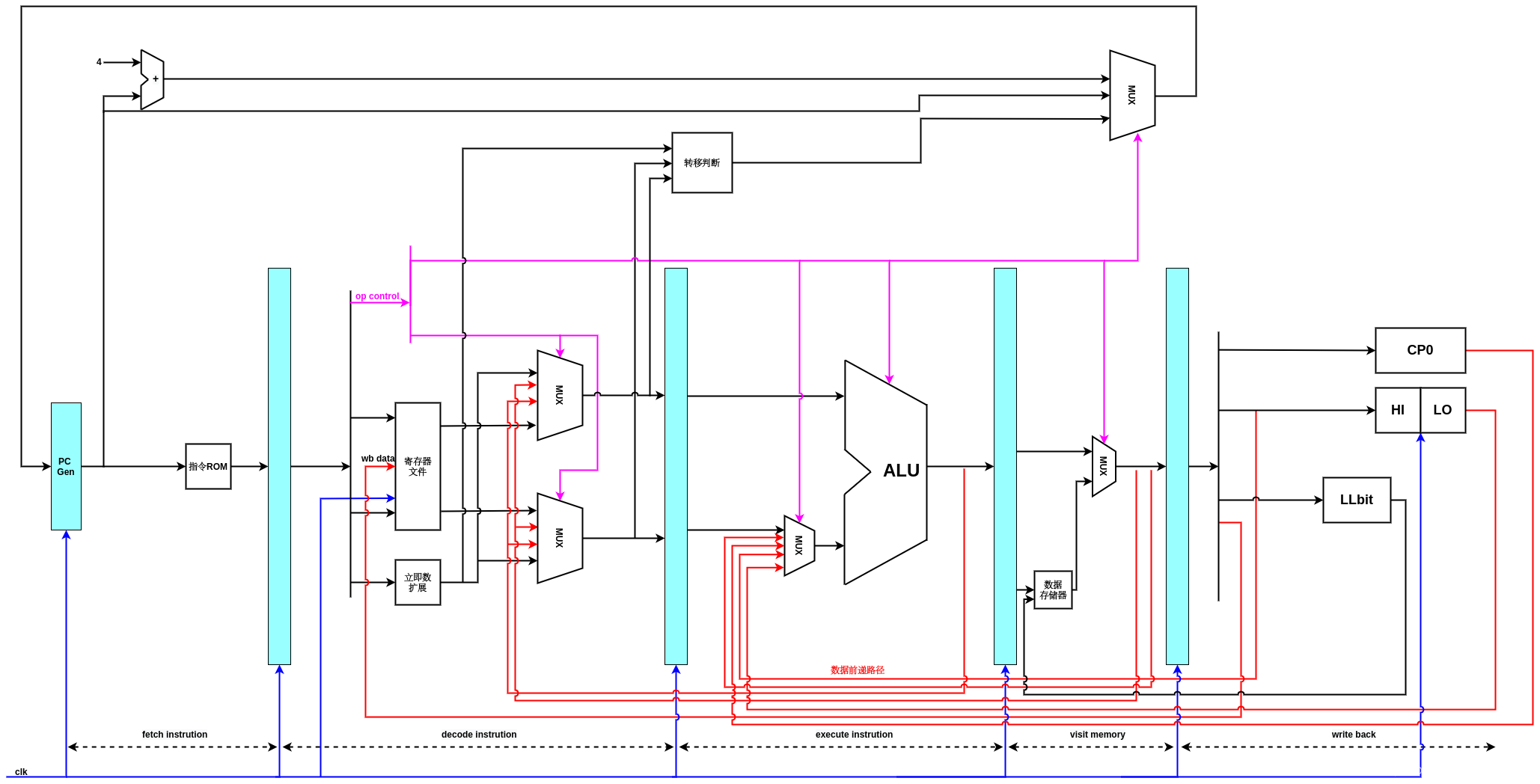
增加了协处理CP0的数据流图,在回写阶段增加了CP0模块,并且CP0模块的输出数据传递到执行阶段,用于确定最后参数运算的操作数,比如,mfc0指令在执行极端就会选择从CP0传递过来的数据,作为运算结果,写入目的寄存器.
添加异常处理后的数据流图如下图所示:在访存阶段增加了异常判断模块,主要作用是依据从译码,执行阶段传递过来的信息,以及CP0中寄存器的值,判断是否要处理异常,如果要处理异常,那么按照异常类型给出新的指令地址送入PC.时钟和复位信号存在的目的是,更新PC,回写寄存器,以及访存都需要时钟,而上电复位则需要RST信号,让PC从一个ISA设定的地址开始执行。
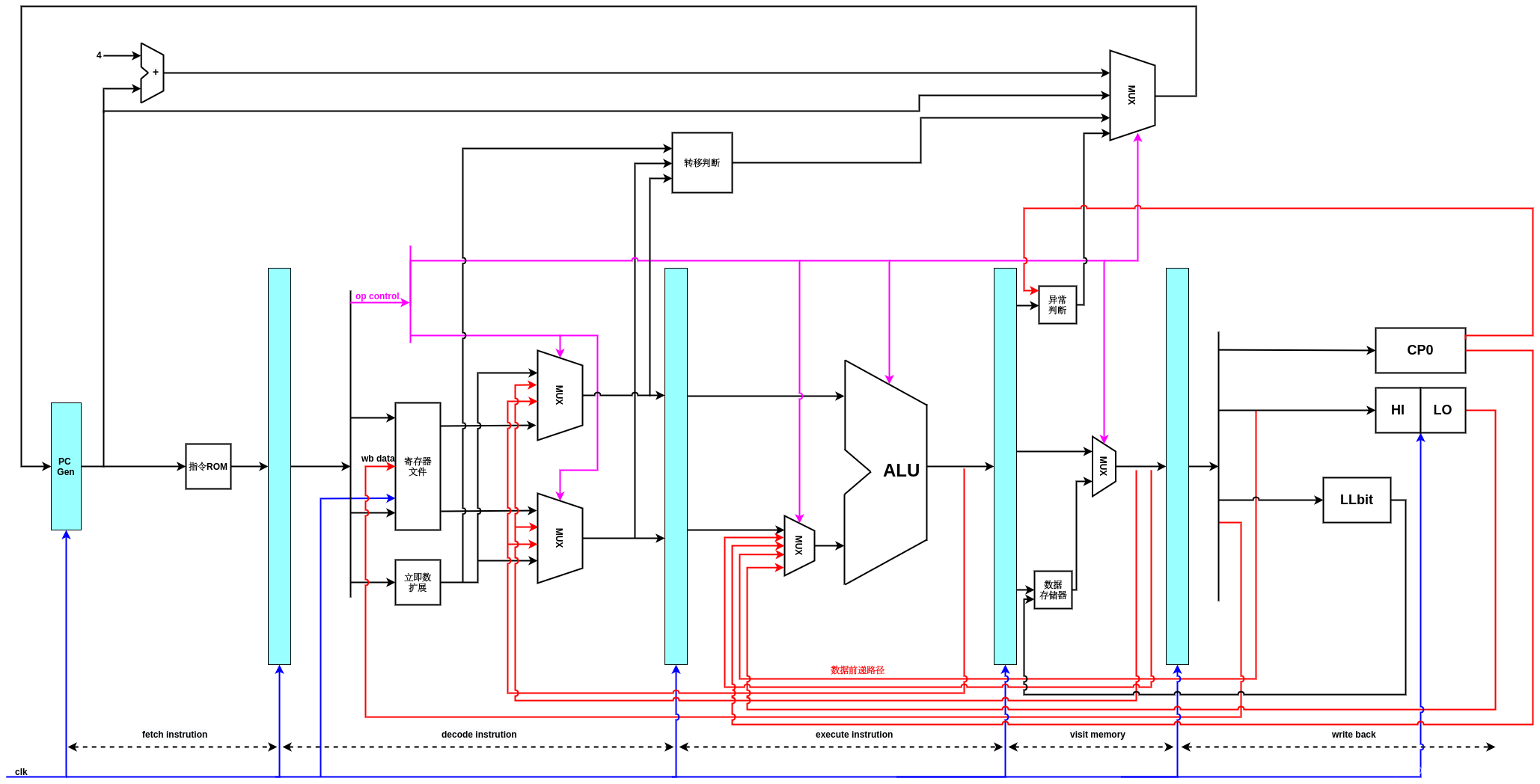
异常处理
异常产生的来源包括外部事件,指令执行中的错误,数据完整性(ECC),地址转换异常,系统调用和陷入,以及软中断辅助的浮点计算等等,在流水线处理中,这些不同类型的异常可能在流水线的不同阶段产生,例如访存地址错误异常发生在取址阶段和访存阶段,系统调用异常和非法指令异常发生在译码阶段,溢出异常发生在执行阶段,而中断由于是异步的,随时可能发生。
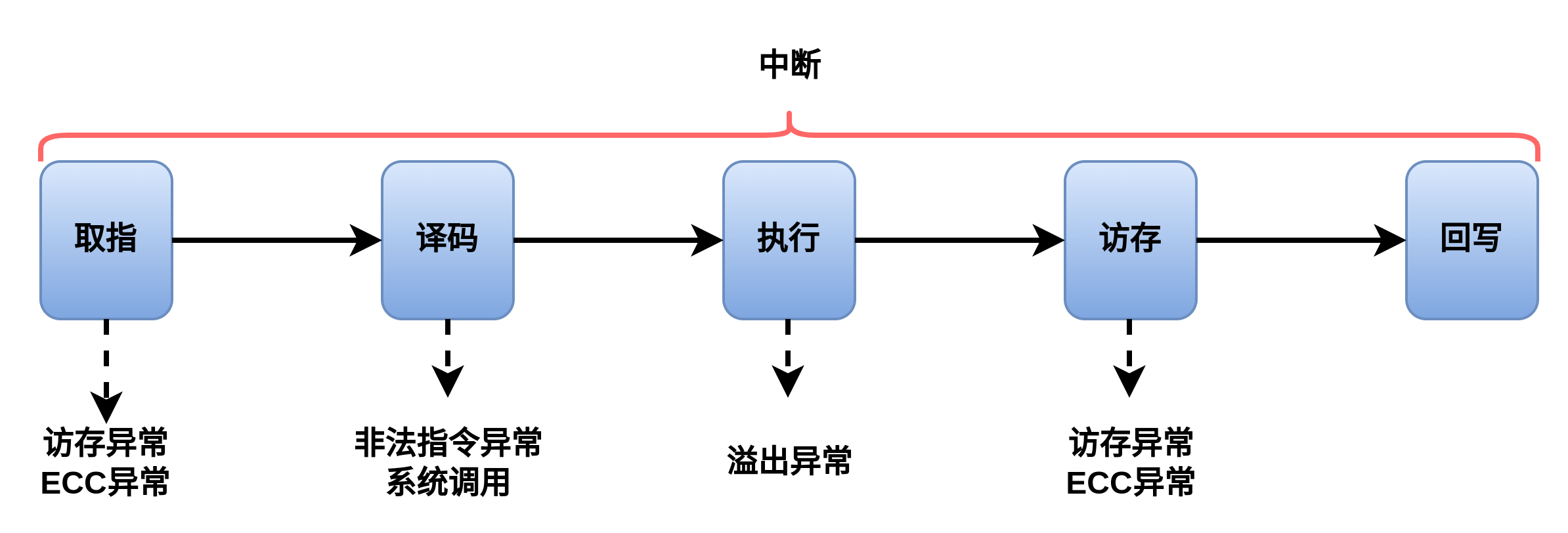
为了实现MIPS精确异常,必须要求异常发生的顺序与指令顺序相同,在非流水线的处理器上,这一点是显然的,但是对于拥有流水线的处理器,就会有些复杂,在流水线处理器上,指令不同,异常会在流水线的不同阶段发生,带来潜在问题,比如,syscall指令在指令译码阶段便会产生异常信号,而装载指令在访存阶段才会发生地址不对齐的异常,如果代码顺序是:
lw t0, 0x04(t1)
syscall
syscall位于lw指令后面第一条指令,如果按照产生异常信号产生的时间来处理异常,syscall处于译码阶段时,lw指令还没有进行访存处理,便会发生后面的指令(syscall)先于前面指令(lw)进行异常处理的情况,这是错误的.为了避免上述情况,先发生的异常并不立即处理,异常事件只是被标记,并继续运行流水线,在大多数处理器中,会设计一个特殊的流水线阶段,专门用于处理异常,如果能够保证任何阶段流水线中的异常在这个阶段之前都可以被发现了,那么就能够保证指令顺序和异常顺序保持一直的原则,最终可以保证,指令按照执行的顺序处理异常,而不是按异常发生的顺序处理异常.
一个RTOS系统仿真的实例,最下面的时钟中断信号周期发生, 仿真需要事先安装 iverilog, vvp,gtkwave三个工具(apt-get install iverilog,apt-get install gtkwave).

事件触发的时机
看waveform的重点是理清各种事件的发生顺序,而触发顺序的事件包括边沿和电平。边缘触发(Edge Triggered)和电平触发(Level Triggered)是在数字电子电路和计算机系统中常见的两种触发方式,它们用于确定何时触发某个事件或信号。它们的主要区别在于触发信号的处理方式和持续时间:
-
边缘触发(Edge Triggered):
- 边缘触发是基于信号的变化边沿来触发事件的方式。这些边沿可以是上升沿(从低电平到高电平的变化)或下降沿(从高电平到低电平的变化)。
- 当出现特定的边沿时,触发器会产生触发信号,然后事件或处理动作会被执行。这意味着触发事件仅在信号的状态发生变化时触发,而不是在信号保持在某个状态时一直触发。
- 边缘触发通常用于捕获瞬时事件或信号,如按钮按下或上升沿触发器(Rising Edge Triggered)。
-
电平触发(Level Triggered):
- 电平触发是基于信号的保持状态来触发事件的方式。当信号保持在特定电平(高电平或低电平)时,触发器产生触发信号,然后事件或处理动作会被执行。
- 与边缘触发不同,电平触发器不关心信号的变化边沿,只要信号保持在指定的电平上,触发事件就会持续触发。
- 电平触发通常用于监测某个条件是否满足,只要条件保持,触发事件就会持续执行,例如,温度传感器的温度超过某个阈值时触发报警。
总结,边缘触发关注信号状态的变化边沿,触发事件只在边缘发生时触发。电平触发关注信号的持续状态,触发事件在信号保持在指定电平时持续触发。选择使用哪种触发方式取决于特定的应用需求和设计要求。
电平和边沿组合,时钟信号的每个时间点都可以触发事件。
流水线与多发射
流水线设计的目标是平衡各个流水线阶段的长度,就像装配线设计者力争平衡每一步的时间那样,如果每一步都得到了最佳平衡,那么每条指令在流水线上的平均执行时间理想情况下等于:

在这种情况下,流水线的加速比等于流水线的段数,就好像在一个装有N个装配器流水线上,可以同时有N部汽车在装配,但是,通常的流水线加速比和流水段之间不会有这么好的平衡,而且流水线本身也要附加一定的时间开销,因此,每条指令在流水线上的平均执行时间不会达到上面的计算理论值,只能不断接近。
流水线增加了指令吞吐量,即单位时间内执行完成的指令条数,但是它并未减少每条指令各自的执行时间,实际上,流水线经常要对各个阶段增加一些控制,增加了开销,造成单个指令的执行时间有略微增加。但是资源利用率提高带来的吞吐量收益更大,造成每个指令平摊下来的执行时间缩短,这就是并行的好处,流水线主要是通过提高硬件资源的利用率来提高性能的。
英文ISSUE在计算机体系结构中,被翻译为发射,或者流出,它是指这种阶段,指令译码后,并不一定有条件执行,当从执行停滞到执行这个过程发生的时候,就认为是指令发射(流出)。
上面的例子是单发射5级流水的设计,为了降低CPI(cycle per instruction),最直观的方法就是让处理器中每级流水线都可以同时处理更多的指令,这叫做多发射技术,例如双发射流水线意味着每一拍用PC从指令存储器中取两条指令,在译码级同时进行两条指令的译码,读源寄存器的操作,执行阶段同时执行两条指令的运算操作和访存操作,并同时回写两条指令的结果i,这样CPI就从1降为0.5.
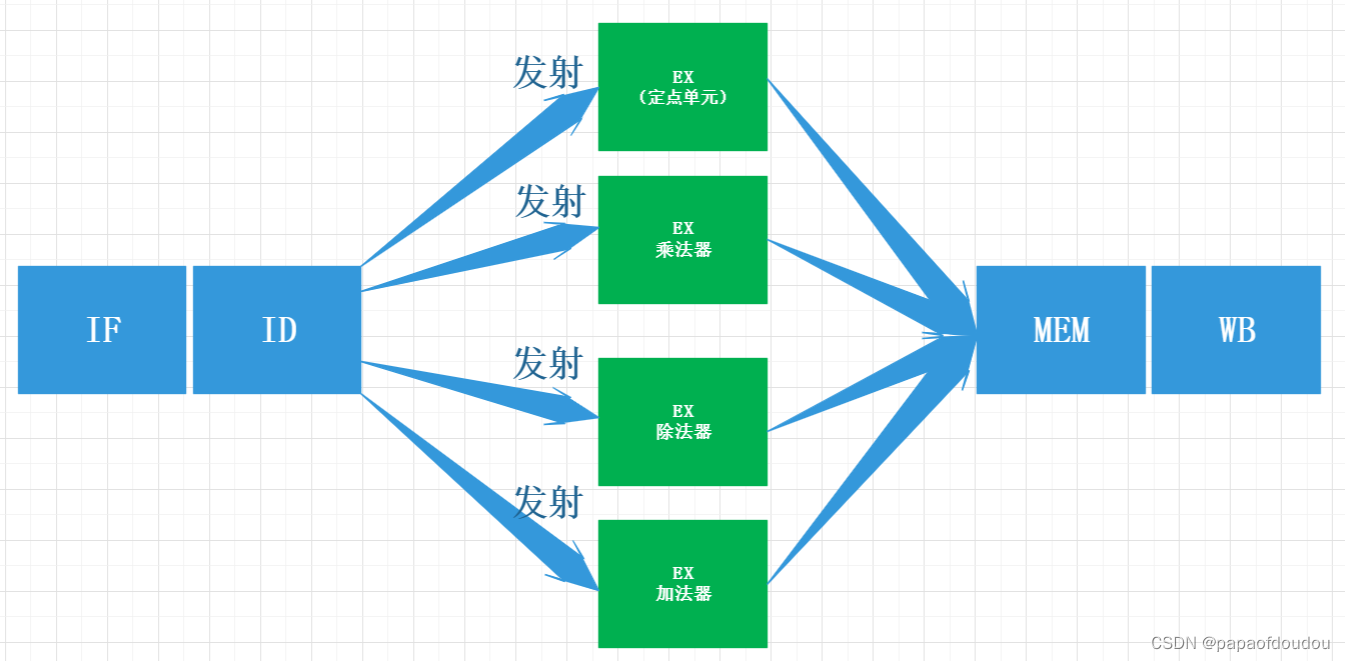
要在处理器中支持多发射,首先就要将处理器中的各种资源翻倍,包括采用支持双端口的存储器,其次还要增加额外的阻塞判断逻辑,当同一个时钟周期执行的两条指令存在指令相关是,也需要进行阻塞,包括数据相关控制相关和结构相关在内的阻塞机制都要略微改动。
流水线取指指令和访存指令同时发生时,该如何处理?
以OR1200为例,当不同指令的取指和访存请求同时有效时,优先处理访存请求:
OR1200_QMEMFSM_STORE>OR1200_QMEMFSM_LOAD>OR1200_QMEMFSM_FETCH。
可不可以得出一个通用的结论,当流水线的的后级和前级共享资源时,优先处理后级,否则,后级得不到处理,前级也无法得到处理,因为流水线本身也是资源,需要按序进行。
MIPS和ARM对比
MIPS和ARM是两种常见的嵌入式处理器体系结构,他们都具有高性能,低功耗和低成本的特点,因此在很多应用领域都有广泛的应用。
在性能方面,一般来说,MIPS和ARM处理器性能相当,不过,具体性能取决于处理器的具体设计和应用场景,一些基准测试表明,在某些情况下,MIPS处理器比ARM处理器具有更高的性能。例如,MIPS64位处理器比ARM的64位处理器具有更高的证书和浮点性能,因为它们具有更多的寄存器和更复杂的执行单元。
然而,在许多实际应用中,ARM处理器在性能和功耗之间取得了很好的平衡,因此他们通常比IPS处理器更适合用于移动设备,嵌入式系统等低功耗领域。
除了性能之外,MIPS和ARM还有一些其它的区别,例如,MIPS处理器具有更多的操作码和更严格的指令格式,使得编译器需要更多的优化才能实现高效的代码生成,ARM处理器则更加灵活,可以根据不同应用场景进行优化,因此在某些场景下可能比MIPS更加高效。
总之,MIPS和ARM都是成熟的嵌入式处理器体系结构,具有各自的优点和适用场景,选择那种处理器取决于具体的应用需求。
失去竞争力的原因:
MIPS曾经是一种非常流行的嵌入式处理器架构,但是随着时间的推移,它的市场份额逐渐减少。以下是MIPS失去竞争力的一些原因:
ARM的兴起:随着移动设备市场的迅速发展,ARM处理器逐渐成为了市场的主流。ARM处理器在低功耗、高性能和灵活性等方面都具有优势,而MIPS则缺乏相应的创新和竞争力。
缺乏兼容性:MIPS的架构和指令集变化较大,导致软件和硬件之间的兼容性较差,这使得MIPS的开发和维护成本较高,限制了其市场竞争力。
生态系统的不完善:与ARM相比,MIPS生态系统相对不完善,缺乏足够的软件、工具和开发支持。这使得MIPS在应用开发和生态建设方面存在一定的局限性。
缺乏创新:MIPS缺乏创新和更新,导致其处理器的性能和功能无法与竞争对手相比。相比之下,ARM一直在不断地改进和更新其处理器架构和指令集,以满足新的应用需求。
综上所述,MIPS失去竞争力的原因是多方面的,包括市场趋势、技术创新、兼容性和生态系统等方面的因素。这些因素共同作用,导致了MIPS在市场上的逐渐萎缩。
优点和不足
MIPS作为一种嵌入式处理器架构,其对客户的友好程度取决于客户的具体需求和使用场景。以下是MIPS对客户的一些优点和缺点:
优点:
性能:MIPS处理器在某些方面具有优异的性能,特别是在运算密集型应用方面。例如,MIPS处理器的指令集具有丰富的算术和逻辑运算功能,能够高效地处理大量的数据和计算任务。
可定制性:MIPS处理器的架构和指令集具有一定的灵活性,可以根据客户的需求进行定制和优化。这使得MIPS可以满足不同客户的不同需求,例如低功耗、高性能和高安全性等。
可靠性:MIPS处理器经过多年的发展和优化,已经成为了一种成熟、稳定的处理器架构。在某些关键领域,例如网络、通信和安全等,MIPS处理器具有优异的可靠性和稳定性。
缺点:
缺乏兼容性:MIPS处理器的架构和指令集变化较大,导致软件和硬件之间的兼容性较差。这使得MIPS的开发和维护成本较高,限制了其市场竞争力。
生态系统的不完善:相比其他处理器架构,MIPS的生态系统相对不完善,缺乏足够的软件、工具和开发支持。这使得MIPS在应用开发和生态建设方面存在一定的局限性。
综上所述,MIPS对客户的友好程度因具体情况而异。在某些领域和应用场景中,MIPS可能具有较高的性能和可靠性,可以满足客户的需求;而在其他领域和应用场景中,MIPS可能存在一些局限性和缺陷。
总结:
在处理器发展历史上,MIPS 公司的处理器曾经是唯一能覆盖从高性能计算(HPC) 到嵌入式领域的指令集架构,在市场上得到广泛应用。在 ARM 建立起移动互联网领域生态后,MIPS 指令集生态环境受到了极大冲击,即使在 MIPS 的传统优势领域也逐渐被 ARM 处理器取代.MIPS 架构处理器在大部分行业应用中的市场份额处于下降趋势, 即使在 MIPS 架构的传统优势领域,比如机顶盒、打印机控制器、WIFI 路由器、 网络处理器等,也已经逐步被 ARM 架构的处理器所取代。 从已有信息来看,自 2014 年 MIPS Release 6 发布以来,除 MIPS 公司自己 的 Warrior 产品系列之外,尚无第二个实现 MIPS Release 6 指令集的芯片,这说明IP也卖不动了。

参考文章
mips pipeline animation:
Installation — Verilator 5.012 documentation
Verilator简介与使用_Hwang_shuo的博客-CSDN博客

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











