









类似于Windows下使用CPU-Z工具查看CPU信息,Linux下也可以使用CUDA-Z工具来查看显卡资源/支持信息。
CUDA-Z运行需要主机首先已经安装CUDA和N卡驱动为前提,具体步骤可参考博客:
Darknet CUDA/CUDANN环境的快速安装_tugouxp的专栏-CSDN博客
之后便可以开始下面的步骤:
下载cuda-z
cuda-z在sourceforge上开源,主页地址:CUDA-Z

根据主页提示进入下载页:

下载后得到文件CUDA-Z-0.10.251-64bit.run

运行:
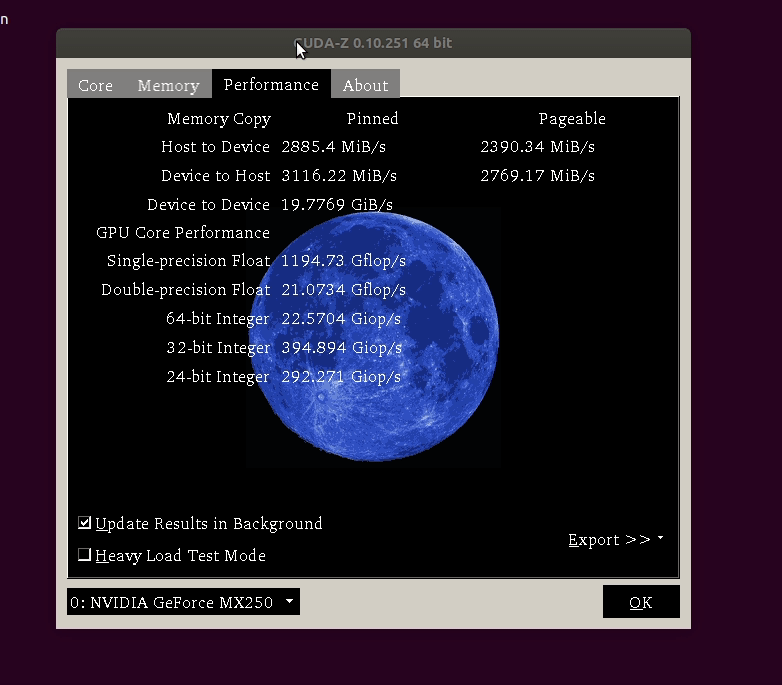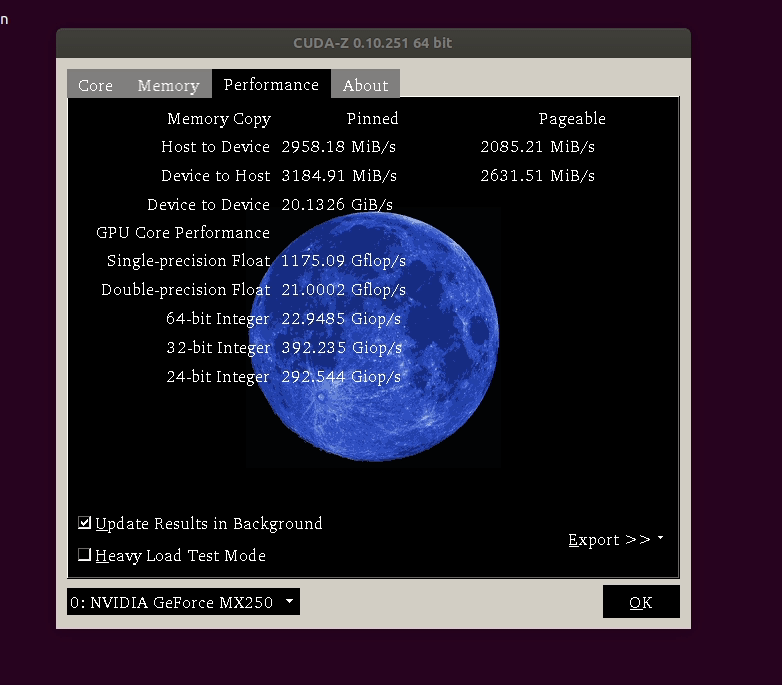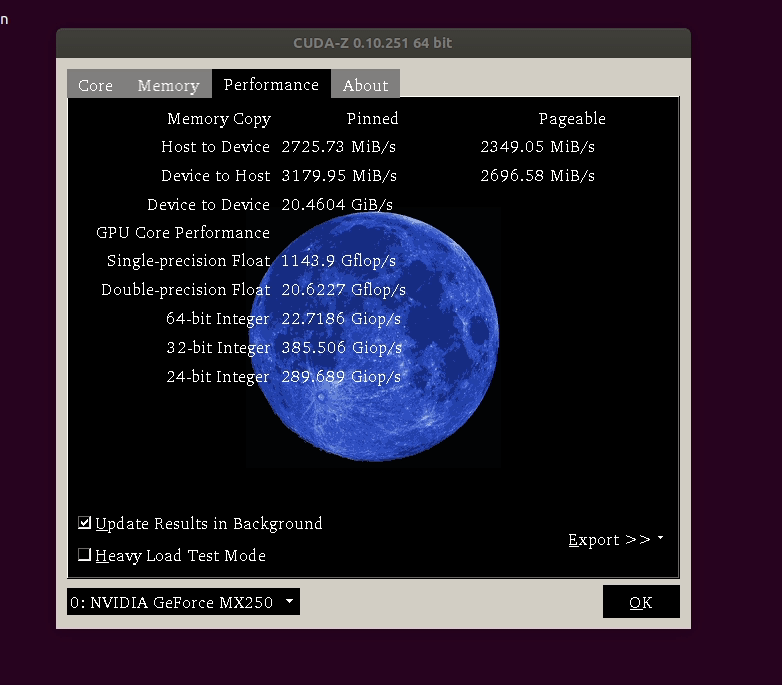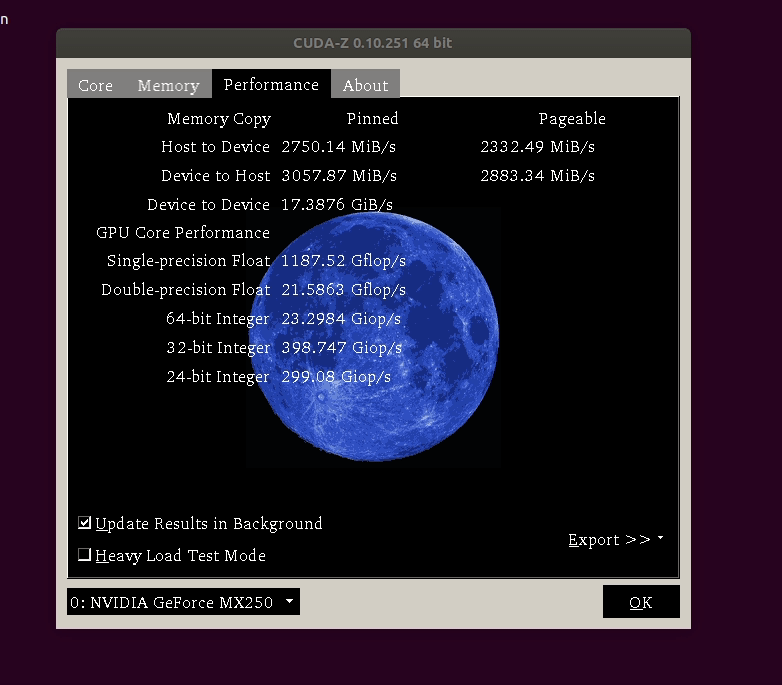
CUDA-Z-0.10.251-64bit.run是个绿色程序,添加可执行属性后直接运行即可,界面如下:
核心信息:

显存信息:

不过NVIDIA 2G的显存并没有映射到BAR上。


如果显卡的显存没有映射到BAR上,是否说明CPU无法直接访问显存?HOST访问显存的方式有三个:


只有BAR方式是CPU直接访问显存,也就是无法使用上面的第三条,BAR方式访问显存,如果没有开启足够的BAR窗口(Resize Bar),则CPU将无法访问显存。比如我笔记本上的MX250 N卡,2G的显存,CPU并不能直接访问。
cuda貌似没有分配支持HOST CPU直接访问的显存的API,这取决于硬件的实现,如果显存没有映射到BAR,则根本就没有支持HOST CPU直接访问显存的机制存在。BR10X支持将显存全部映射到BAR,所以可以做到,但是HOST CPU访问显存本身是一个鸡肋的功能,访问效率较低,有更改好的通过SDMA拷贝的方案去做。
算力信息,1TFLOPS=1000GFLOPS,所以这里单精度浮点算力为1.2TFLOPS左右。
| Single Precision Float | 1192.48 Gflop/s |
| Double Precision Float | 20.6227 Gflop/s |
| 64-Bit Integer | 23.0647 Giop/s |
| 32-Bit Integer | 398.375 Giop/s |
| 24-Bit Integer | 289.689 Giop/s |
GPU算力特点,和CPU相比的不同:
CPU除了负责浮点整形运算外,还有很多其他的指令集的负载,比如像多媒体解码,硬件解码等,因此CPU是多才多艺的。CPU注重的是单线程的性能,要保证指令流不中断,需要消耗更多的晶体管和能耗用在控制部分,于是CPU分配在浮点计算的功耗就会变少。
GPU基本上只做浮点运算的,设计结构简单,也就可以做的更快。GPU注重的是吞吐量,单指令能驱动更多的计算,相比较GPU消耗在控制部分的能耗就比较少,因此可以把电省下来的资源给浮点计算使用。
工具信息:

Windows下的GPU-Z
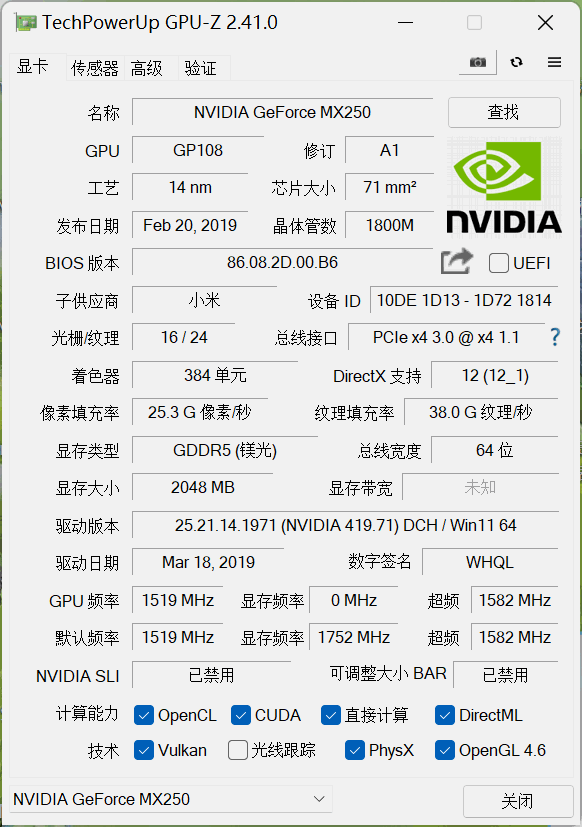
Windows下还有另外一款GPU分析工具叫做GPU-Z,估计是模仿CPU-Z起的名字,GPUZ不但可以分析N卡,还能对其它厂家的显卡比如英特尔的集成显卡进行分析,从下拉列表中选择你想获取信息的显卡,界面将会自动刷新。

N卡信息:
英特尔显卡:
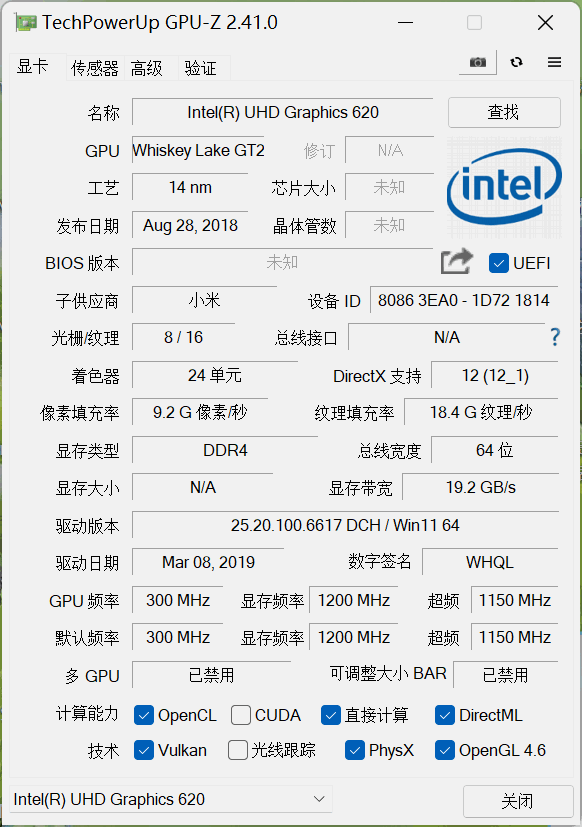
从对CUDA的支持可以看出两类显卡的一个明显差异。
再来看一个AMD的显卡,可以看到不支持CUDA,不支持光追。
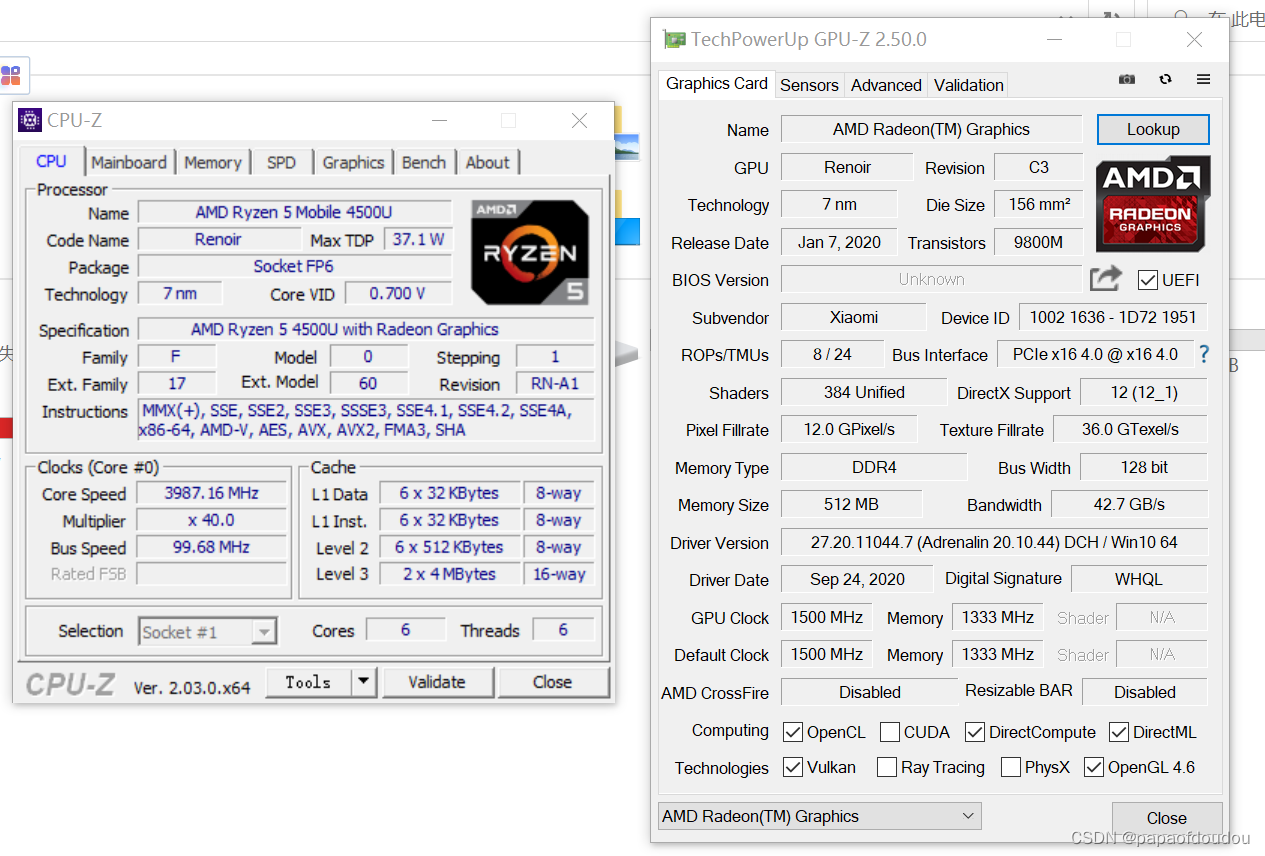
对比可以发现,AMD的显卡全面优于INTEL的集成显卡。
GPU性能测速
使用gpu-burn测试GPU 单精度,双精度以及tensor core的计算能力.
1.下载gpu-burn
$ git clone https://github.com/wilicc/gpu-burn
2.编译
$ cd gpu-burn
$ make
3.测试
测试单精度
zlcao@zlcao-RedmiBook-14:~/gpu/gpu-burn$ ./gpu_burn 60
Burning for 60 seconds.
GPU 0: NVIDIA GeForce MX250 (UUID: GPU-657800de-5f00-da64-7c46-68e7e31fcae1)
Initialized device 0 with 2001 MB of memory (1878 MB available, using 1690 MB of it), using FLOATS
Results are 16777216 bytes each, thus performing 103 iterations
13.3% proc'd: 412 (1022 Gflop/s) errors: 0 temps: 44 C
Summary at: 2023年 01月 28日 星期六 19:31:36 CST
25.0% proc'd: 721 (1020 Gflop/s) errors: 0 temps: 48 C
Summary at: 2023年 01月 28日 星期六 19:31:43 CST
36.7% proc'd: 1236 (1018 Gflop/s) errors: 0 temps: 55 C
Summary at: 2023年 01月 28日 星期六 19:31:50 CST
48.3% proc'd: 1648 (1021 Gflop/s) errors: 0 temps: 58 C
Summary at: 2023年 01月 28日 星期六 19:31:57 CST
60.0% proc'd: 2060 (1013 Gflop/s) errors: 0 temps: 61 C
Summary at: 2023年 01月 28日 星期六 19:32:04 CST
71.7% proc'd: 2472 (1013 Gflop/s) errors: 0 temps: 62 C
Summary at: 2023年 01月 28日 星期六 19:32:11 CST
83.3% proc'd: 2781 (1013 Gflop/s) errors: 0 temps: 63 C
Summary at: 2023年 01月 28日 星期六 19:32:18 CST
95.0% proc'd: 3296 (1012 Gflop/s) errors: 0 temps: 65 C
Summary at: 2023年 01月 28日 星期六 19:32:25 CST
100.0% proc'd: 3605 (1009 Gflop/s) errors: 0 temps: 66 C
Killing processes.. Freed memory for dev 0
Uninitted cublas
done
Tested 1 GPUs:
GPU 0: OK
测试双精度
./gpu_burn -d 60
Burning for 60 seconds.
GPU 0: NVIDIA GeForce MX250 (UUID: GPU-657800de-5f00-da64-7c46-68e7e31fcae1)
Initialized device 0 with 2001 MB of memory (1878 MB available, using 1690 MB of it), using DOUBLES
Results are 33554432 bytes each, thus performing 50 iterations
36.7% proc'd: 50 (39 Gflop/s) errors: 0 temps: 47 C
Summary at: 2023年 01月 28日 星期六 19:36:51 CST
50.0% proc'd: 50 (39 Gflop/s) errors: 0 temps: 49 C
Summary at: 2023年 01月 28日 星期六 19:36:59 CST
66.7% proc'd: 50 (39 Gflop/s) errors: 0 temps: 51 C
Summary at: 2023年 01月 28日 星期六 19:37:09 CST
83.3% proc'd: 100 (39 Gflop/s) errors: 0 temps: 52 C
Summary at: 2023年 01月 28日 星期六 19:37:19 CST
100.0% proc'd: 100 (39 Gflop/s) errors: 0 temps: 54 C
Summary at: 2023年 01月 28日 星期六 19:37:29 CST
100.0% proc'd: 100 (39 Gflop/s) errors: 0 temps: 54 C
Killing processes.. Freed memory for dev 0
Uninitted cublas
done
Tested 1 GPUs:
GPU 0: OK
测试tensor core
./gpu_burn -tc 60
Burning for 60 seconds.
GPU 0: NVIDIA GeForce MX250 (UUID: GPU-657800de-5f00-da64-7c46-68e7e31fcae1)
Initialized device 0 with 2001 MB of memory (1878 MB available, using 1690 MB of it), using FLOATS, using Tensor Cores
Results are 16777216 bytes each, thus performing 103 iterations
11.7% proc'd: 412 (1025 Gflop/s) errors: 0 temps: 59 C
Summary at: 2023年 01月 28日 星期六 19:38:16 CST
23.3% proc'd: 824 (1025 Gflop/s) errors: 0 temps: 61 C
Summary at: 2023年 01月 28日 星期六 19:38:23 CST
35.0% proc'd: 1236 (1018 Gflop/s) errors: 0 temps: 63 C
Summary at: 2023年 01月 28日 星期六 19:38:30 CST
46.7% proc'd: 1648 (1014 Gflop/s) errors: 0 temps: 64 C
Summary at: 2023年 01月 28日 星期六 19:38:37 CST
58.3% proc'd: 1957 (1013 Gflop/s) errors: 0 temps: 65 C
Summary at: 2023年 01月 28日 星期六 19:38:44 CST
70.0% proc'd: 2472 (1015 Gflop/s) errors: 0 temps: 67 C
Summary at: 2023年 01月 28日 星期六 19:38:51 CST
81.7% proc'd: 2884 (1017 Gflop/s) errors: 0 temps: 67 C
Summary at: 2023年 01月 28日 星期六 19:38:58 CST
91.7% proc'd: 3193 (1015 Gflop/s) errors: 0 temps: 68 C
Summary at: 2023年 01月 28日 星期六 19:39:04 CST
100.0% proc'd: 3605 (1015 Gflop/s) errors: 0 temps: 69 C
Killing processes.. Freed memory for dev 0
Uninitted cublas
done
Tested 1 GPUs:
GPU 0: OK
得到的数据和上面cuda-z得到的还是非常接近的。
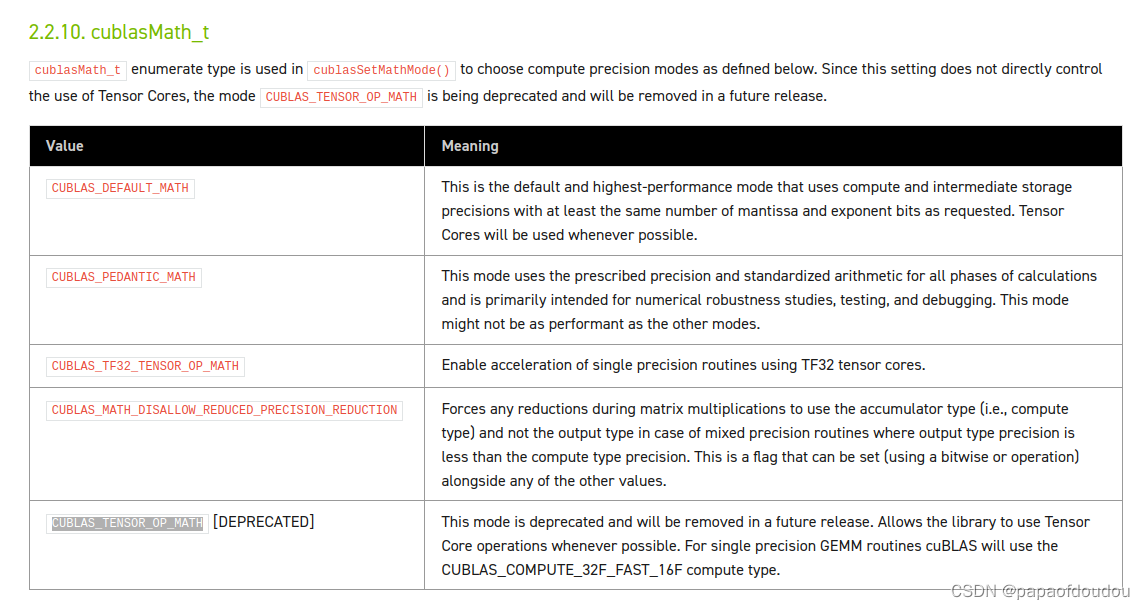
-tc指定tensor core上跑的原理是会导致cublasSetMathMode的执行。

其中的参数CUBLAS_TENSOR_OP_MATH 根据官方文档,表达让GPU尽可能的利用tensor core去完成计算。
参考文章
https://gpuopen.com/wp-content/uploads/2022/01/Efficient-Use-of-GPU-Memory-Digital-Dragons-2021.pdf

















 1608
1608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











