







实验平台信息:

首先编译X86版本和ARM版本两个平台的QEMU
1.获取代码:
wget https://download.qemu.org/qemu-4.1.0.tar.bz22.安装依赖:
sudo apt-get install build-essential pkg-config zlib1g-dev libglib2.0-0 libglib2.0-dev libsdl1.2-dev libpixman-1-dev libfdt-dev autoconf automake libtool librbd-dev libaio-dev flex bison3.编译
./configure --target-list=arm-softmmu --audio-drv-list=alsa,pa --prefix=/home/caozilong/Workspace/qemu/install接着执行 make -j4

4.生成DEB包
sudo apt-get install checkinstall
sudo checkinstall make install 

5.安装结果

6.分析
由于HOST机是X86架构,所以这里的tcg-target.inc.c一定是X86目录下的tcg-target.inc.c文件。


ARM平台上:
arm平台上会使用arm目录的tcg-target.inc.c

原理:



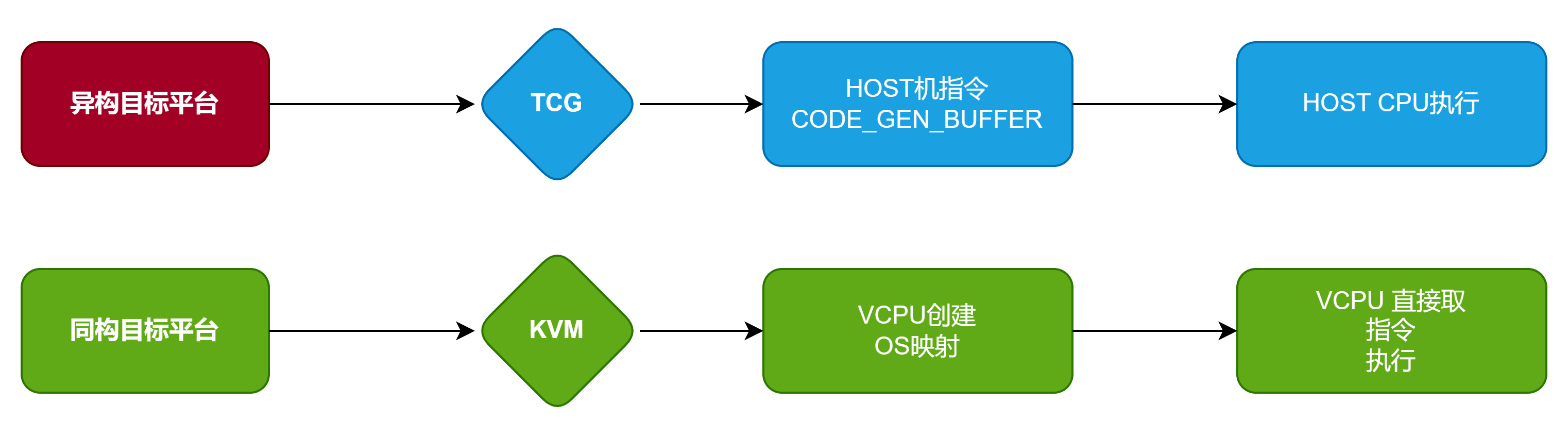
TCG翻译引擎
KVM加速虚拟化过程虽然执行很快,但是要求目标平台和HOST平台为同一架构才有可能,而TCG引擎没有这个要求,TCG可以将目标机架构的二进制指令翻译为HOST指令,放到一片预先分配好的code_gen_buffer中,code_gen_buffer具有可执行权限,CPU可以执行放在其中的指令,用这种方式实现本地CPU加速。
带有可执行属性MAP的CODE_GEN_BUFFER分配过程:

可执行匿名区映射的例子:
#include <unistd.h>
#include <stdio.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#define FILE_SIZE 0x4000
int add(int a, int b)
{
return a+b;
}
typedef int (*ptrfunc)(int, int);
int main(void)
{
int i;
unsigned int *maddr;
ptrfunc ptrf;
#if 0
maddr = mmap(NULL, FILE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS, -1, 0);
#else
maddr = mmap(NULL, FILE_SIZE, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_SHARED|MAP_ANONYMOUS, -1, 0);
#endif
if(maddr == (void*)-1) {
printf("%s line %d, faild to map buffer, error %s.\n", __func__, __LINE__, strerror(errno));
return -1;
}
printf("%s line %d maddr = %p errno %s.\n", __func__, __LINE__, maddr, strerror(errno));
memcpy(maddr, add, 64);
ptrf = (ptrfunc)maddr;
printf("%s line %d, maddr = %p, maddr(5,6) = %d.\n", __func__, __LINE__, maddr, ptrf(5, 6));
for(i = 0; i < 16; i ++) {
maddr[i] = i;
printf("0x%02x ", maddr[i]);
}
printf("\n");
munmap((void *)maddr, FILE_SIZE);
return 0;
} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2409
2409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











