










 文章详细介绍了Linux系统中的IOMMU机制,包括IOMMU的作用——管理输入输出设备的内存映射和访问权限,提升系统安全性和性能。IOMMUGroup用于设备分组和隔离,确保DMA请求的正确管理。内容还涉及到IOMMUGroup的分配逻辑,以及PCI设备如何根据BUS和SLOT号被分到同一组。此外,文章探讨了IOMMUDomain的页表结构,以及在不同IOMMU模式(如关闭、非PT模式、PT模式)下,物理地址和IOMMU映射地址的关系。最后,提到了启用IOMMUPASS-THROUGH模式的影响和设备间内存访问的规则。
文章详细介绍了Linux系统中的IOMMU机制,包括IOMMU的作用——管理输入输出设备的内存映射和访问权限,提升系统安全性和性能。IOMMUGroup用于设备分组和隔离,确保DMA请求的正确管理。内容还涉及到IOMMUGroup的分配逻辑,以及PCI设备如何根据BUS和SLOT号被分到同一组。此外,文章探讨了IOMMUDomain的页表结构,以及在不同IOMMU模式(如关闭、非PT模式、PT模式)下,物理地址和IOMMU映射地址的关系。最后,提到了启用IOMMUPASS-THROUGH模式的影响和设备间内存访问的规则。
在Linux系统中,IOMMU是指Input/Output Memory Management Unit是一种硬件设备,用于管理输入输出设备的内存映射以及访问权限。IOMMU可以提高系统的安全性和性能,通过对DMA请求进行隔离和管理,防止恶意设备访问系统内存并提高内存使用效率。
在IOMMU的实现中,一个IOMMU设备通常会管理多个I/O设备,而这些IO设备可能需要共享同一块物理内存。为了有效管理这些IO设备,Linux内核使用IOMMU Group进行设备的分组和隔离。
IOMMU group是一组物理设备和其对应的DMA地址空间,一般来说,IOMMU group中的所有设备共享相同的DMA地址空间,并受到相同的IOMMU保护,如果一个设备与多个IOMMU GROUP关联,或者一个IOMMU group中包含多个设备,可能需要重新配置系统以确保正确的IOMMU保护,在IOMMU GROUP中,IO设备可以访问统一块物理内存。但不能访问其它IOMMU GROUP的内存,这样可以保护系统的安全性。
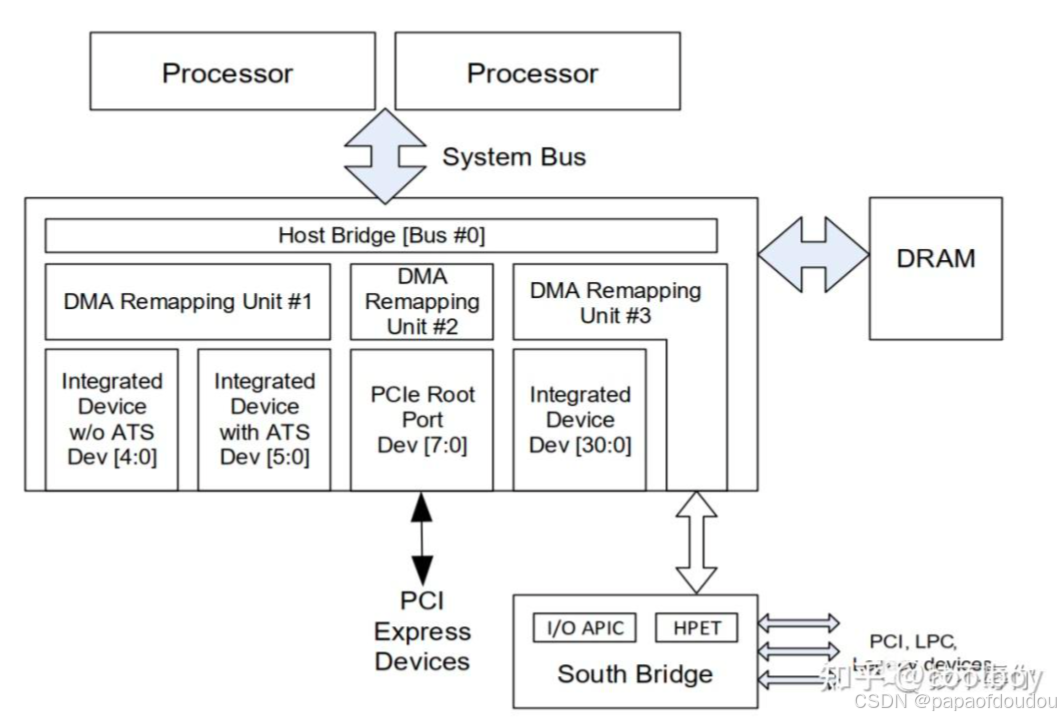
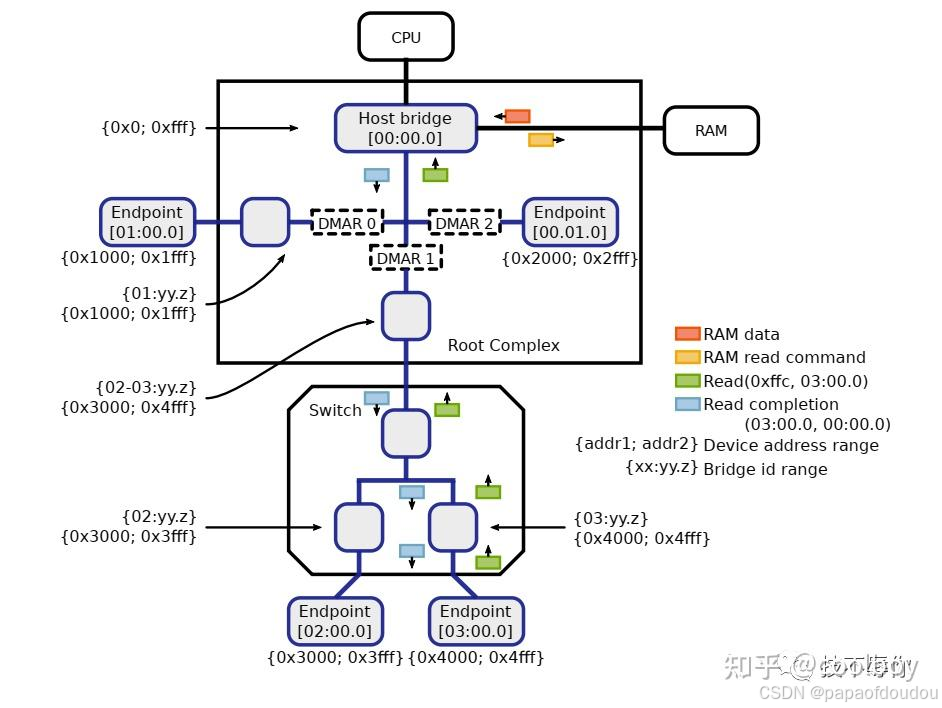
从硬件架构上看一下iommu,iommu就是上图所展示的DMA Remapping Unit,通常一台硬件服务器上会有多个DMA Remapping Unit,它下面可以对接pcie设备。简称为DMAR,通常DMA Remapping Unit集成在Root Complex当中,系统当中所有的外设的DMA操作理论上都要经过DMAR(例外就是在p2p通信的场景下且pcie switch 开了ATS功能那就不用再到DMAR转一圈了)。下图展示了一个pci设备在有iommu的场景下其进行一次read dma操作的相关流程。
IOMMU 工作模型
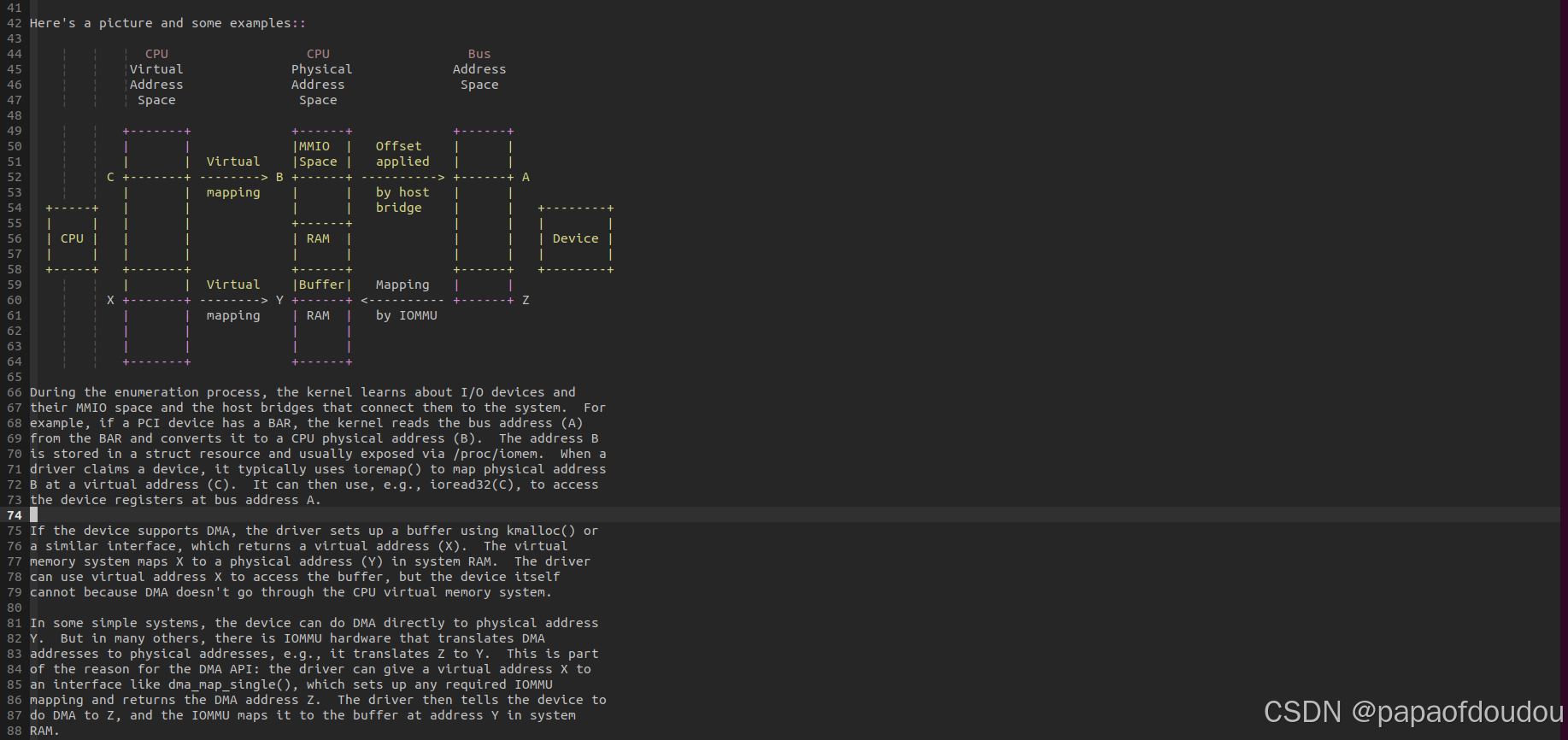
C->B:ioremap
B->A:physical address -> bus address(pci bar mmio).
X->Y: alloc pages.
Z->Y:dma_map_xxx
查看系统中的iommu group
使用如下脚本查看系统中的iommu group以及旗下设备列表
for iommu_group in $(find /sys/kernel/iommu_groups/ -maxdepth 1 -mindepth 1 -type d); do
echo "IOMMU Group $(basename "$iommu_group")";
for device in $(ls "$iommu_group"/devices/); do
echo -e "\t$(lspci -nns "$device")";
done;
done;
输出如下:
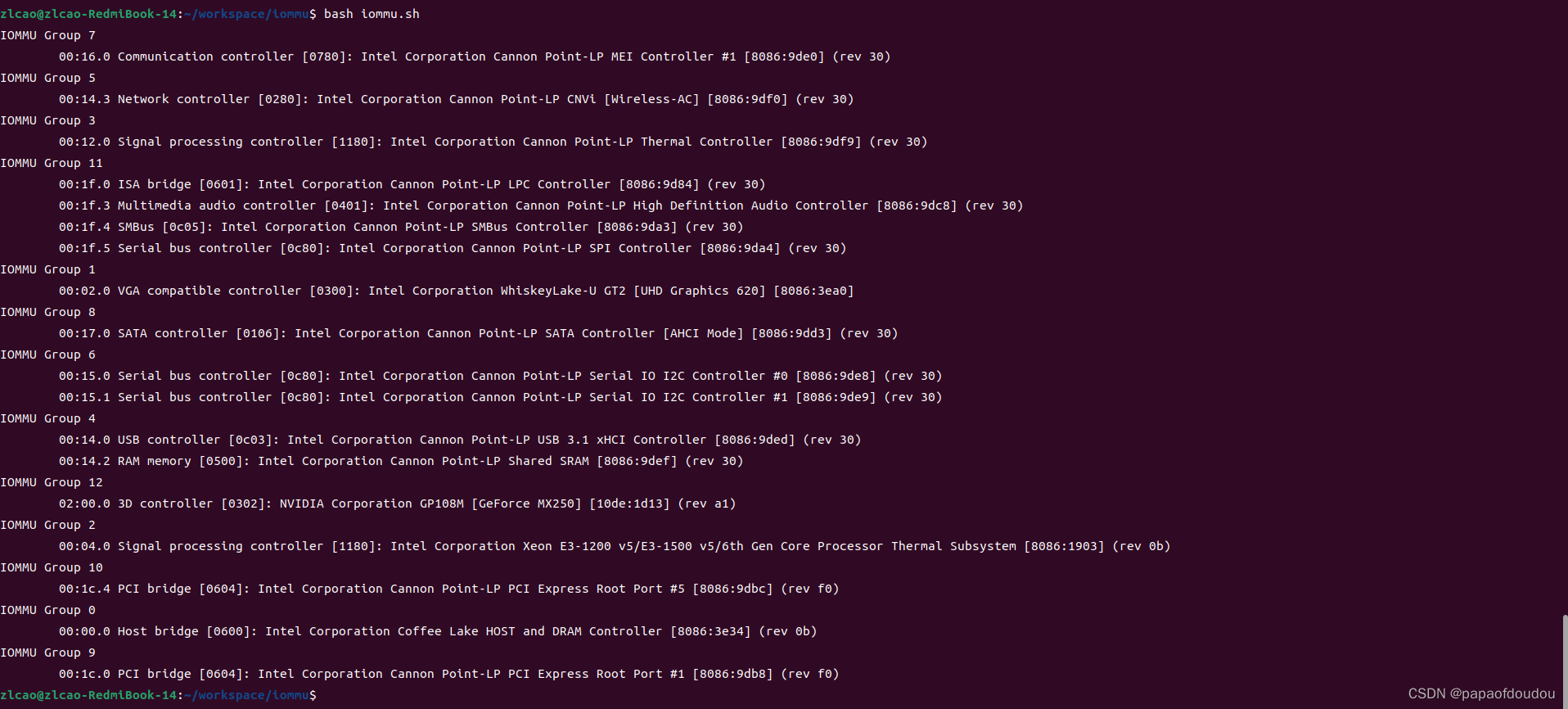

和启动启动时候的注册过程打印做对比,是匹配的:

可以看到,有些group里面只有1个设备,而有些group里面则有多个设备。
iommu goup id的分配

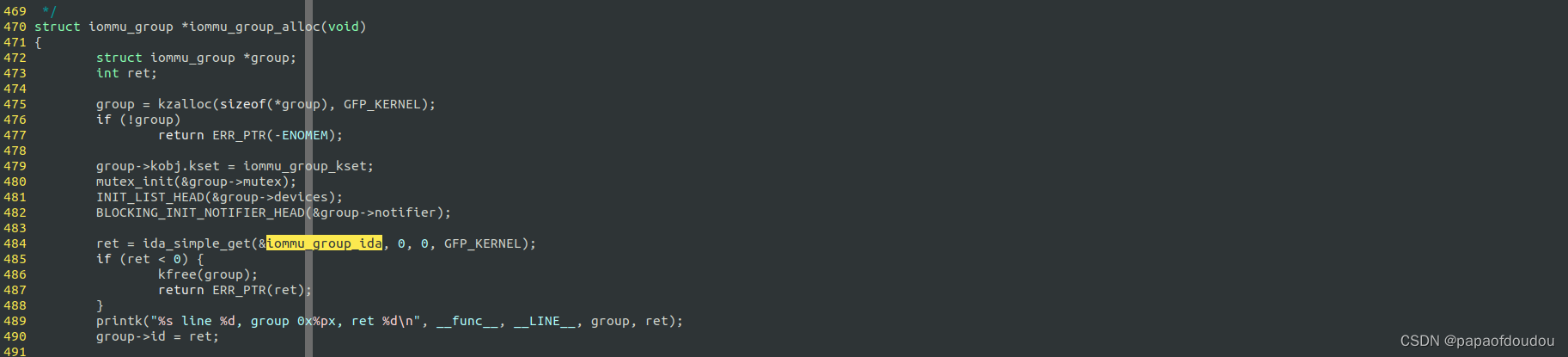
iommu_group_alloc callstack
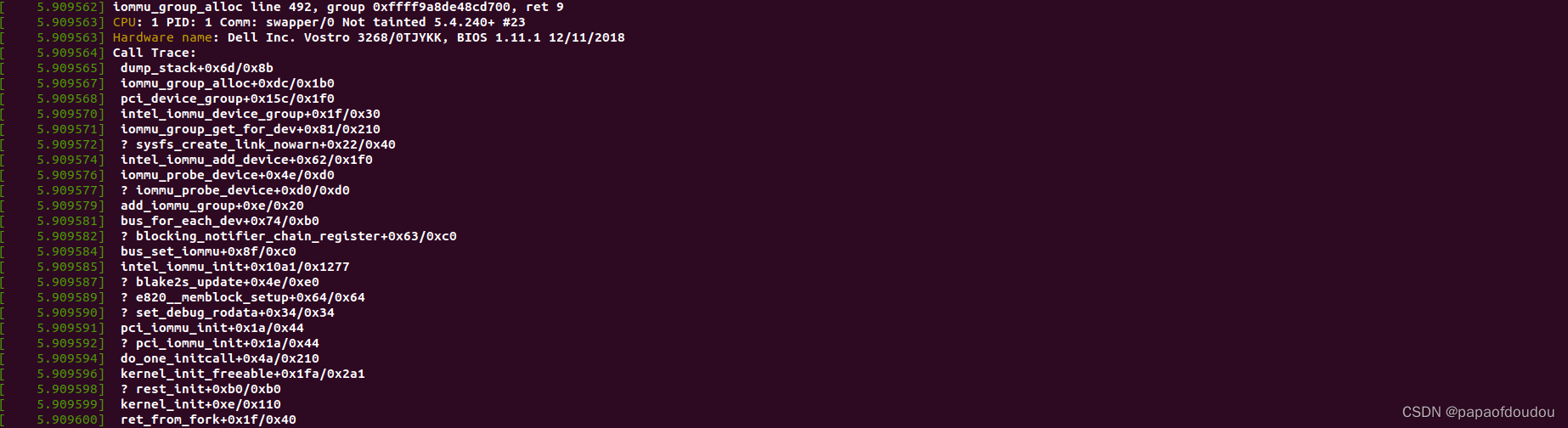
GROUP ID分配逻辑
group id的最终分配来源于iommu_group_ida,通过如下的调用堆栈进行创建和初始化:
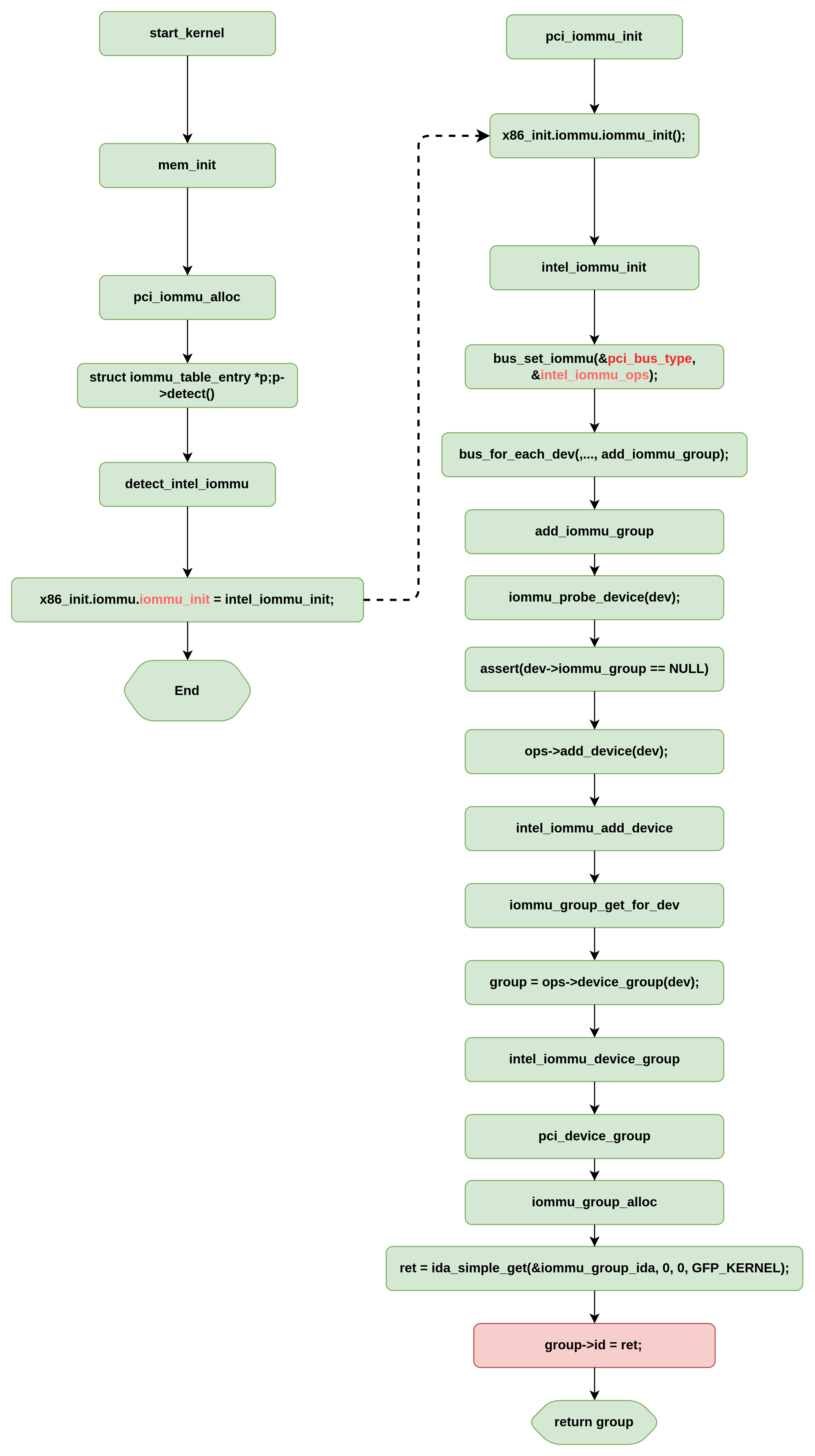
为什么有些PCI设备在一个GROUP,而有些在不同的GROUP,依据是什么?
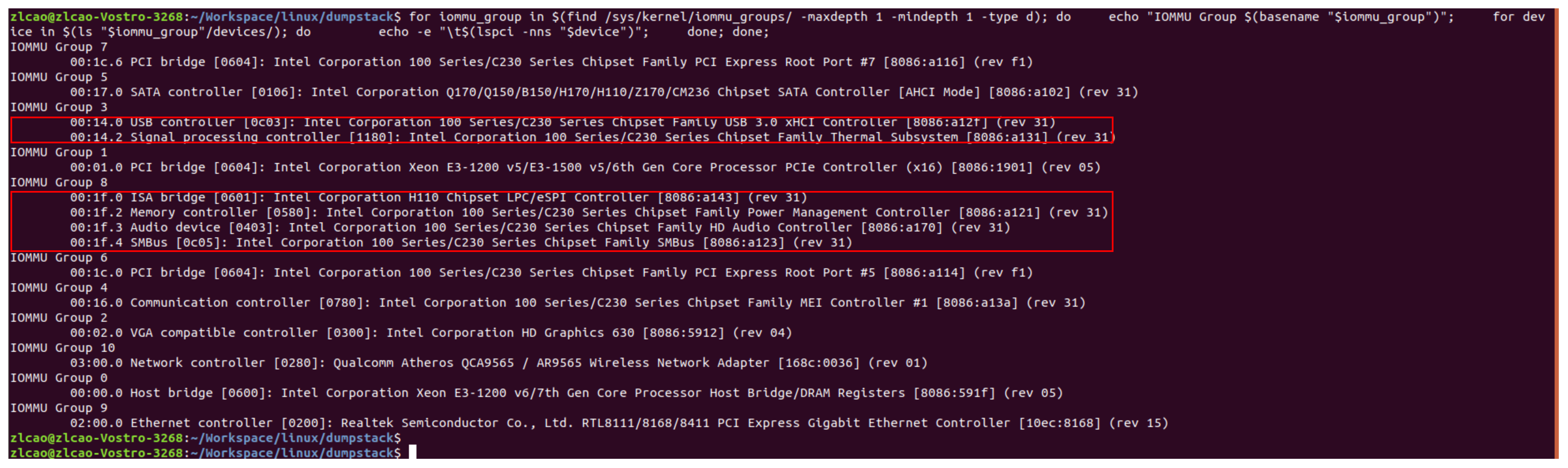
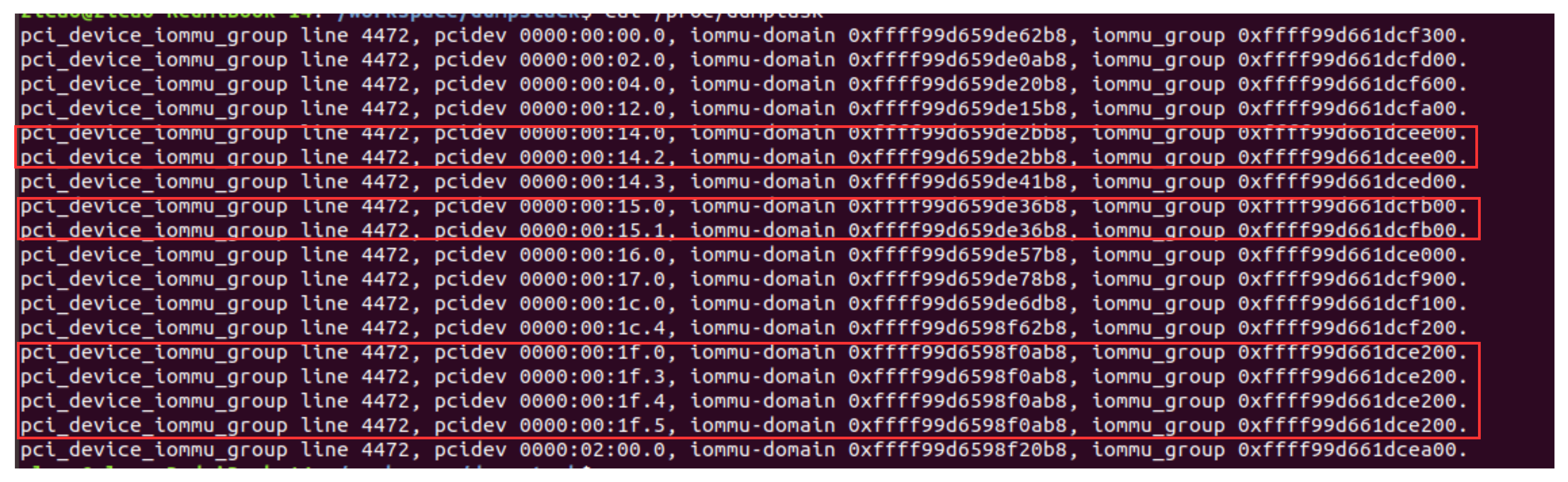
从图中可以看出,有两个group比较特殊,他们的ID分贝为3和8,别的GORUP只有一个设备,而这两个GROUP则分别有2个和4个设备。
通过BDF分析他们的共性,可以看属于同一个IOMMU GROUP PCI设备的BUS号和Device(slot)号是相同的,只有功能号不同,而根据PCI设备的定义,BUS号和DEVICE号确定了一个物理上的PCI设备,对应一个PCI插槽,而funcdtion则是对PCI设备的逻辑划分而并非物理划分,同一个设备的不同的function共用同一个PCI 插槽。所以猜测,内核判断设备是否是同一个IOMMU GROUP的依据是否是根据BUS和SLOT号呢?查看逻辑确实如此:
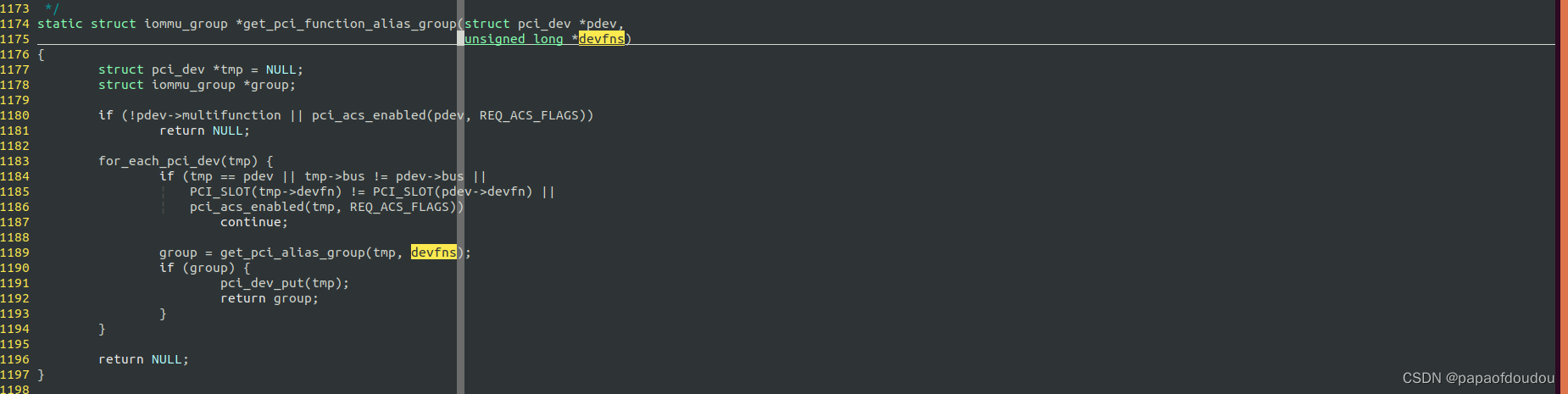
并且发现,分组内的第一个设备负责调用iommu_group_alloc分配iommu group,其它设备则通过1339行得到第一个设备的GROUP信息并分配给自身。


PCIe协议允许P2P传输,这就意味着同一个PCIE Switch下连接不同End Point可以在不经过RC的情况下相互通信。除了End Point和End Point之间(End Point和End Point都是挂在同一个PCIE Switch下)可以peer-to-peer传输,同一个Poot Complex下的Root Port之间也可以支持peer-to-peer传输。而对于多功能的PCIe dev,dev的不同功能之间也可以进行peer-to-peer传输。
另外也可以看出,iommu domain分配的最小粒度是 iommug group,属于同一个iommu group的设备也属于同一个iommu domain.
bus号和function号相同是必要条件,并非充分条件,当设备支持ACS访问控制功能时,不能和其它具有相同的BUS和SLOT号的设备同组,必须单独创建一个IOMMU组,如下图中的00:14.3设备的GROUP。

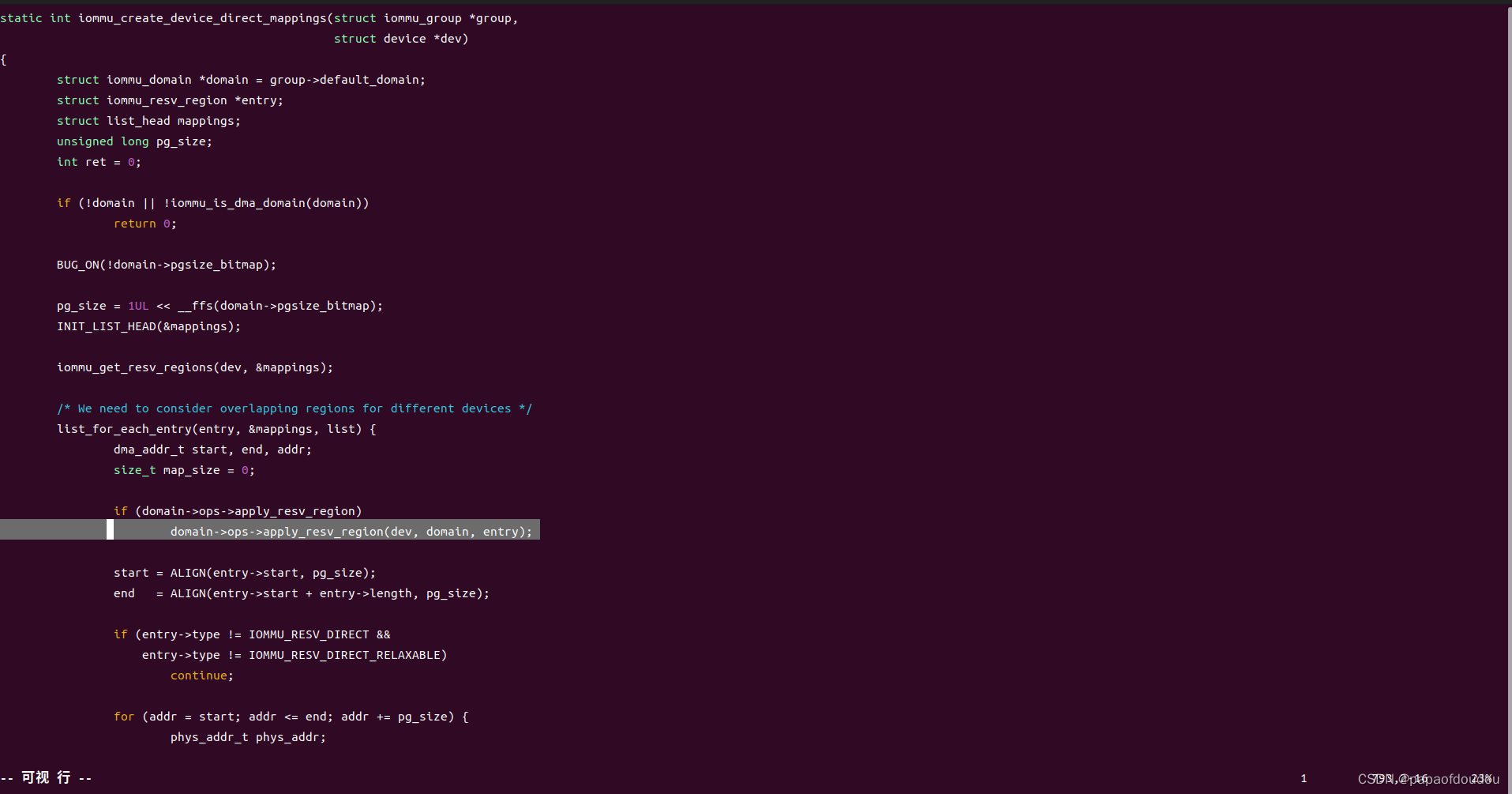
dev->iommu_group被设置后,会继续给设备做DMA映射,iommu_group_create_direct_mappings函数主要是将设备对应的虚拟机地址空间映射到物理地址空间,其会遍历设备映射的地址段,然后调用iommu_map给每段虚拟地址空间都映射到相应的物理内存上。




IOMMU GROUP和IOMMU是对应的,相同IOMMU GROUP的设备指向相同的iommu domain,而每个iommu domain分配对应一个页表PGD,所以,同一个IOMMU GROUP内的设备,是可以互相访问彼此的IOMMU 映射的。
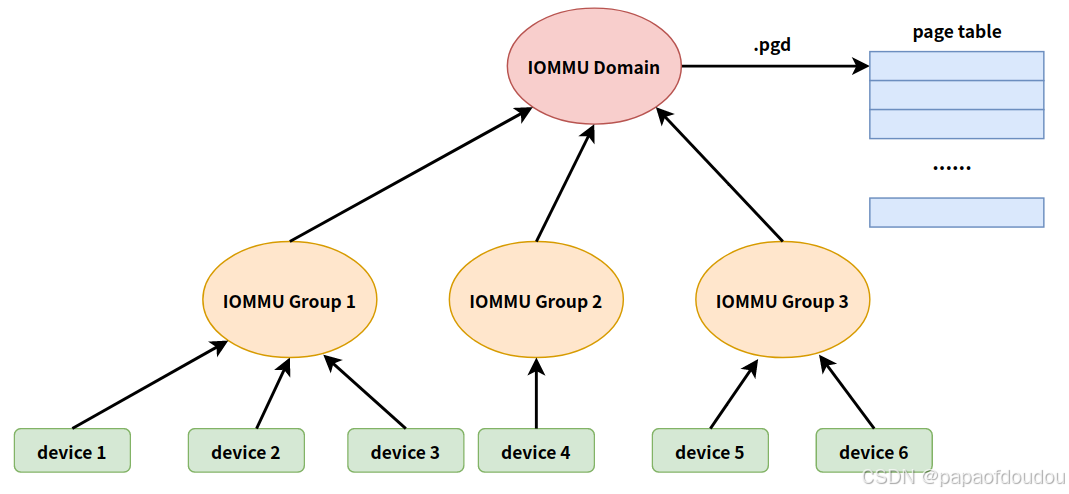
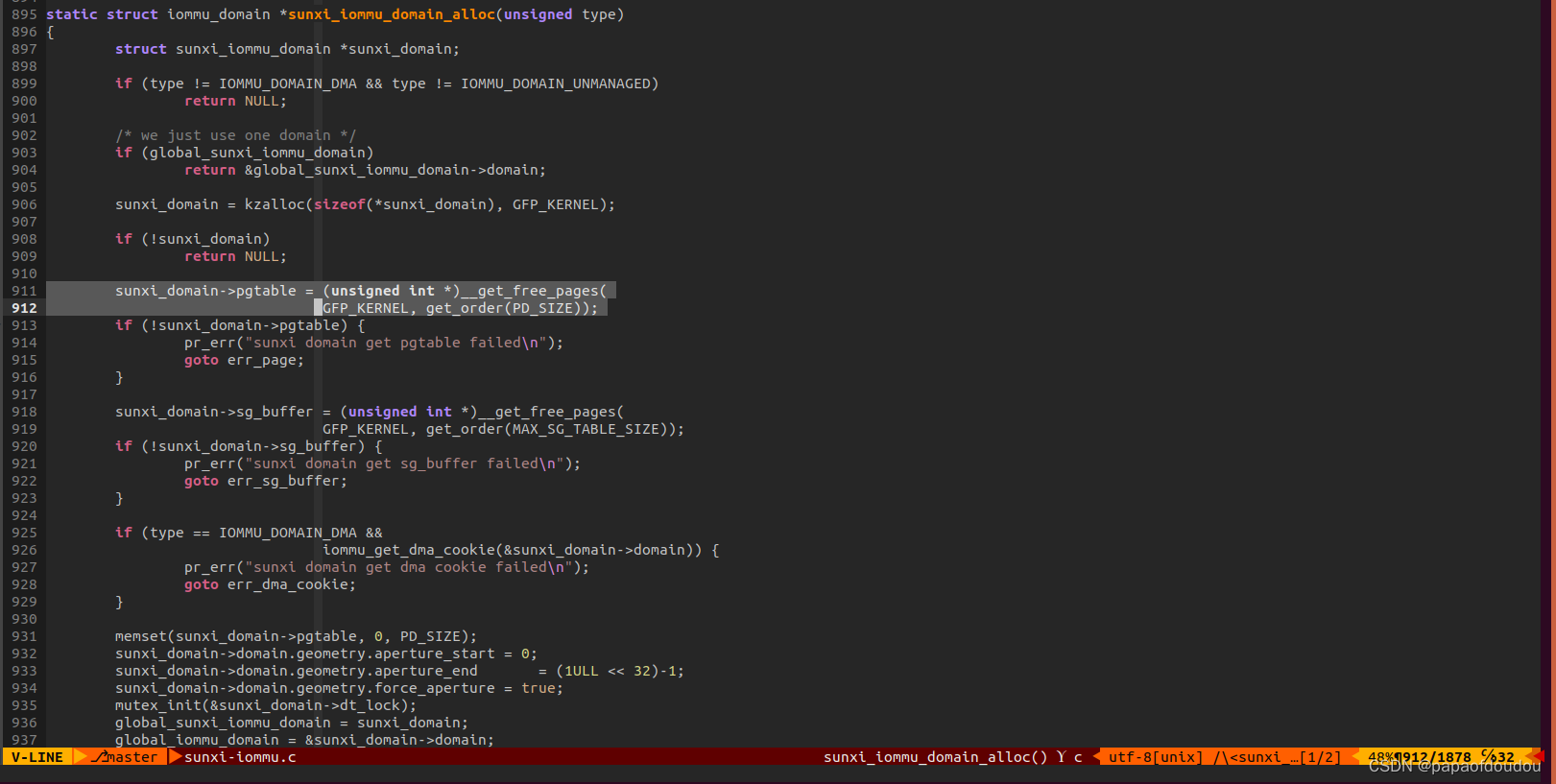
iommu_domain对应了一张page table pgd.
一个struct iommu_group下面可以对应多个或者一个硬件设备,一个struct iommu_domain里面可以有多个iommu_group,然后每个iommu_group通过iommu_domain最终找到dmar_domain进行转换。
acs影响IOMMU 分组的理由
看分析主要是为了保护IOVA地址空间的可见性和隔离。
An IOMMU group is defined as the smallest set of devices that can be considered isolated from the IOMMU’s perspective. The first step to achieve isolation is granularity. If the IOMMU cannot differentiate devices into separate IOVA spaces, they are not isolated. For example, if multiple devices attempt to alias to the same IOVA space, the IOMMU is not able to distinguish between them. This is the reason why a typical x86 PC will group all conventional-PCI devices together, with all of them aliased to the same requester ID, the PCIe-to-PCI bridge. Legacy KVM device assignment allows a user to assign these conventional-PCI devices separately, but the configuration fails because the IOMMU cannot distinguish between the devices. As VFIO is governed by IOMMU groups, it prevents any configuration that violates this most basic requirement of IOMMU granularity.
The next step is to determine whether the transactions from the device actually reach the IOMMU. The PCIe specification allows for transactions to be re-routed within the interconnect fabric. A PCIe downstream port can re-route a transaction from one downstream device to another. The downstream ports of a PCIe switch may be interconnected to allow re-routing from one port to another. Even within a multifunction endpoint device, a transaction from one function may be delivered directly to another function. These transactions from one device to another are called peer-to-peer transactions and can destroy the isolation of devices operating in separate IOVA spaces. Imagine for instance, if the network interface card assigned to a guest virtual machine, attempts a DMA write operation to a virtual address within its own IOVA space. However in the physical space, that same address belongs to a peer disk controller owned by the host. As the IOVA to physical translation for the device is only performed at the IOMMU, any interconnect attempting to optimize the data path of that transaction could mistakenly redirect the DMA write operation to the disk controller before it gets to the IOMMU for translation.
To solve this problem, the PCI Express specification includes support for PCIe Access Control Services (ACS), which provides visibility and control of these redirects. This is an essential component for isolating devices from one another, which is often missing in interconnects and multifunction endpoints. Without ACS support at every level from the device to the IOMMU, it must be assumed that redirection is possible. This will, therefore, break the isolation of all devices below the point lacking ACS support in the PCI topology. IOMMU groups in a PCI environment take this isolation into account, grouping together devices which are capable of untranslated peer-to-peer DMA.
In summary, the IOMMU group represents the smallest set of devices for which the IOMMU has visibility and which is isolated from other groups. VFIO uses this information to enforce safe ownership of devices for user space. With the exception of bridges, root ports, and switches (all examples of interconnect fabric), all devices within an IOMMU group must be bound to a VFIO device driver or known safe stub driver. For PCI, these drivers are vfio-pci and pci-stub. pci-stub is allowed simply because it is known that the host does not interact with devices via this driver[2]. If an error occurs indicating the group is not viable when using VFIO, it means that all of the devices in the group need to be bound to an appropriate host driver. Using virsh nodedev-dumpxml to explore the composition of an IOMMU group and virsh nodedev-detach to bind devices to VFIO compatible drivers, will help resolve such problems.
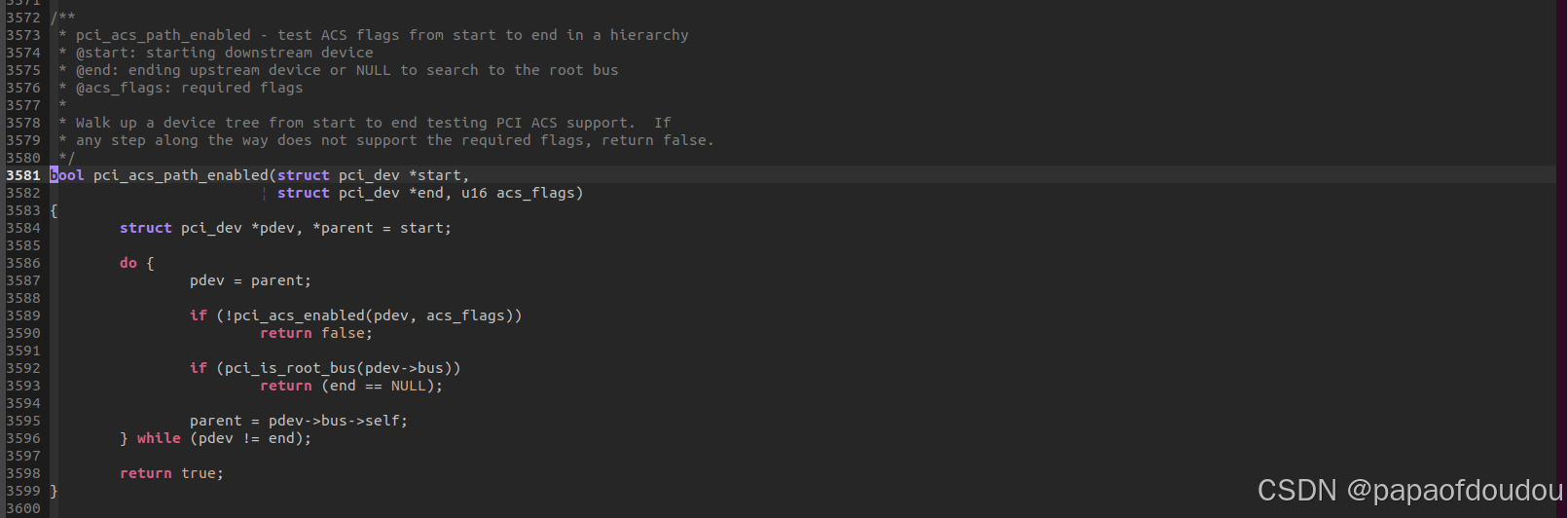
这个函数的核心逻辑在于pci_acs_path_enabled,简单来说如果是pcie的设备则检查该设备到root complex的路径上如果都开启了ACS则这个设备就单独成一个iommu_group,如果不是则找到它的alias group就行了比如如果这个是传统的pci bus(没有pcie这些ACS的特性)则这个pci bus下面的所有设备就组合成一个iommu_group。
intel iommu关闭情况下的物理地址和IOMMU映射地址是相同的
void dma_alloc_test(struct seq_file *m)
{
struct device *dev;
dma_addr_t phys, real_phys;
void *cpu_addr;
char *pci_dev_name = "0000:02:00.0";
//char *pci_dev_name = "0000:00:14.0";
size_t alloc_size;
struct sg_table *table;
struct scatterlist *slist, *sprev;
int i;
dev = bus_find_device_by_name(&pci_bus_type, NULL, pci_dev_name);
seq_printf(m, "dev = 0x%px.\n", dev);
cpu_addr = dma_alloc_coherent(dev, PAGE_SIZE, &phys, GFP_KERNEL);
if (!cpu_addr) {
pr_err("%s line %d, fatal error.\n", __func__, __LINE__);
return;
}
seq_printf(m, "%s line %d, cpu_addr = 0x%px, phys = 0x%llx.\n", __func__, __LINE__, cpu_addr, phys);
#if 0
if(iommu_get_domain_for_dev(dev))
real_phys = iommu_iova_to_phys(iommu_get_domain_for_dev(dev), phys);
else
#endif
real_phys = phys;
seq_printf(m, "%s line %d, real_phys = 0x%llx.\n", __func__, __LINE__, real_phys);
dma_free_coherent(dev, PAGE_SIZE, cpu_addr, phys);
table = (struct sg_table *)kzalloc(sizeof(*table), GFP_KERNEL);
if (table == NULL) {
pr_err("%s line %d, alloc sgtable failure.\n", __func__, __LINE__);
return;
}
//alloc_size = 0x40000;
alloc_size = 16 * PAGE_SIZE;
if (sg_alloc_table(table, alloc_size / PAGE_SIZE, GFP_KERNEL)) {
pr_err("%s line %d, fatal error, alloc sgtable failure.\n", __func__, __LINE__);
return;
}
slist = NULL;
sprev = NULL;
for_each_sg(table->sgl, slist, table->orig_nents, i) {
struct page *pg = alloc_page(GFP_KERNEL);
if (pg == NULL) {
pr_err("%s line %d, alloc pages failure.\n", __func__, __LINE__);
return;
}
sg_set_page(slist, pg, PAGE_SIZE, 0);
sg_dma_len(slist) = PAGE_SIZE;
}
table->nents = dma_map_sg(dev, table->sgl, table->orig_nents, DMA_BIDIRECTIONAL);
if (!table->nents) {
pr_err("%s line %d, dma map failure.\n", __func__, __LINE__);
return;
}
for_each_sg(table->sgl, slist, table->orig_nents, i) {
#if 0
if(iommu_get_domain_for_dev(dev))
real_phys = iommu_iova_to_phys(iommu_get_domain_for_dev(dev), sg_dma_address(slist));
else
#endif
real_phys = phys;
seq_printf(m, "%s line %d, mapped nents %d, origin nents %d, realphys 0x%llx, iova 0x%llx.\n", \
__func__, __LINE__, table->nents, table->orig_nents, real_phys, sg_dma_address(slist));
}
for_each_sg(table->sgl, slist, table->orig_nents, i) {
struct page *pg = sg_page(slist);
put_page(pg);
}
return;
}
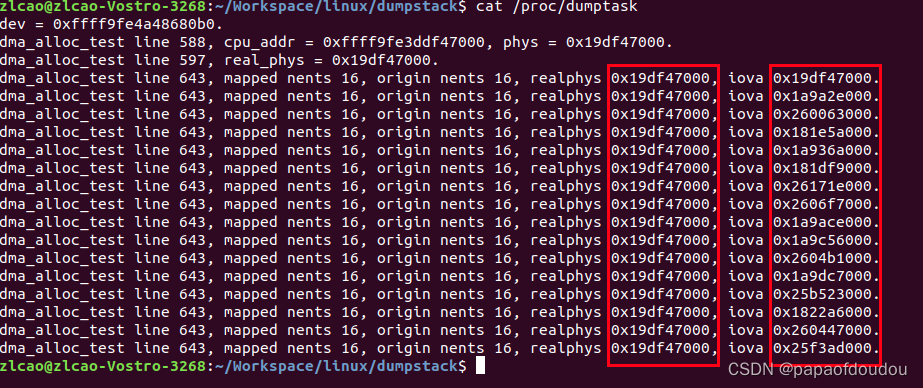
enable iommu后,IOVA和物理地址不相同了:
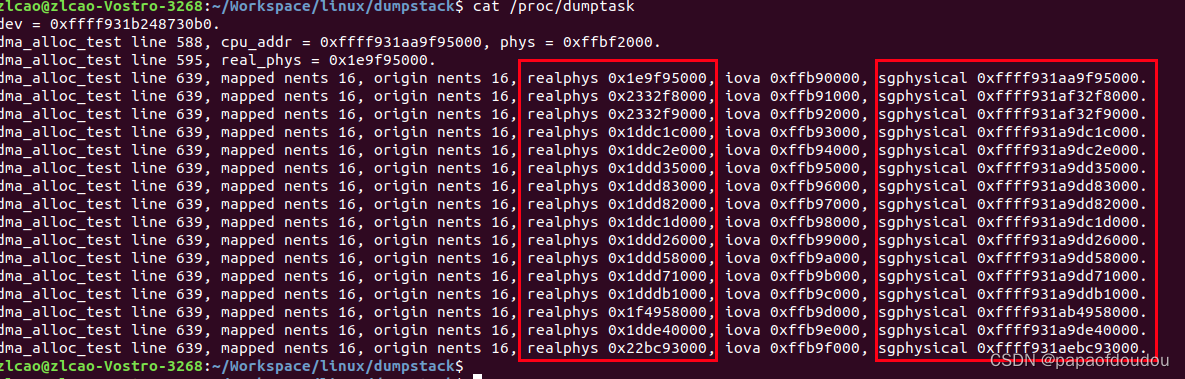
地址特征随IOMMU参数的变化
1.IOMMU 关闭
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash pci=realloc=on strict cma=16M@0x26c000000 log_buf_len=16M"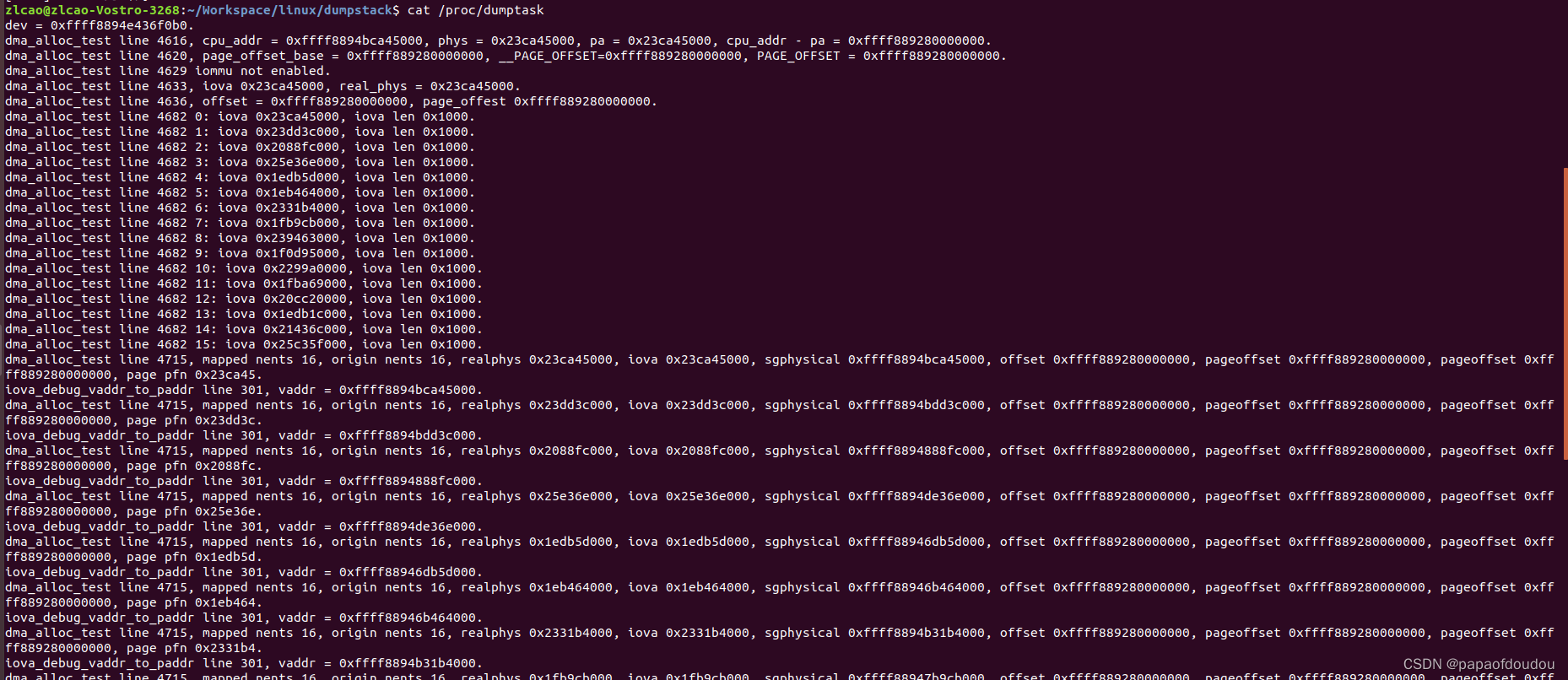
realphys和iova相等。
2.打开IOMMU,非PT(passthrough)模式,设置-intel_iommu=on(依赖于CONFIG_IOMMU_DEFAULT_PASSTHROUGH=n)或者-intel_iommu=on iommu.passthrough=0.
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash pci=realloc=on intel_iommu=on,strict cma=16M@0x26c000000 log_buf_len=16M"
或者
"quiet splash pci=realloc=on intel_iommu=on,strict iommu.passthrough=1"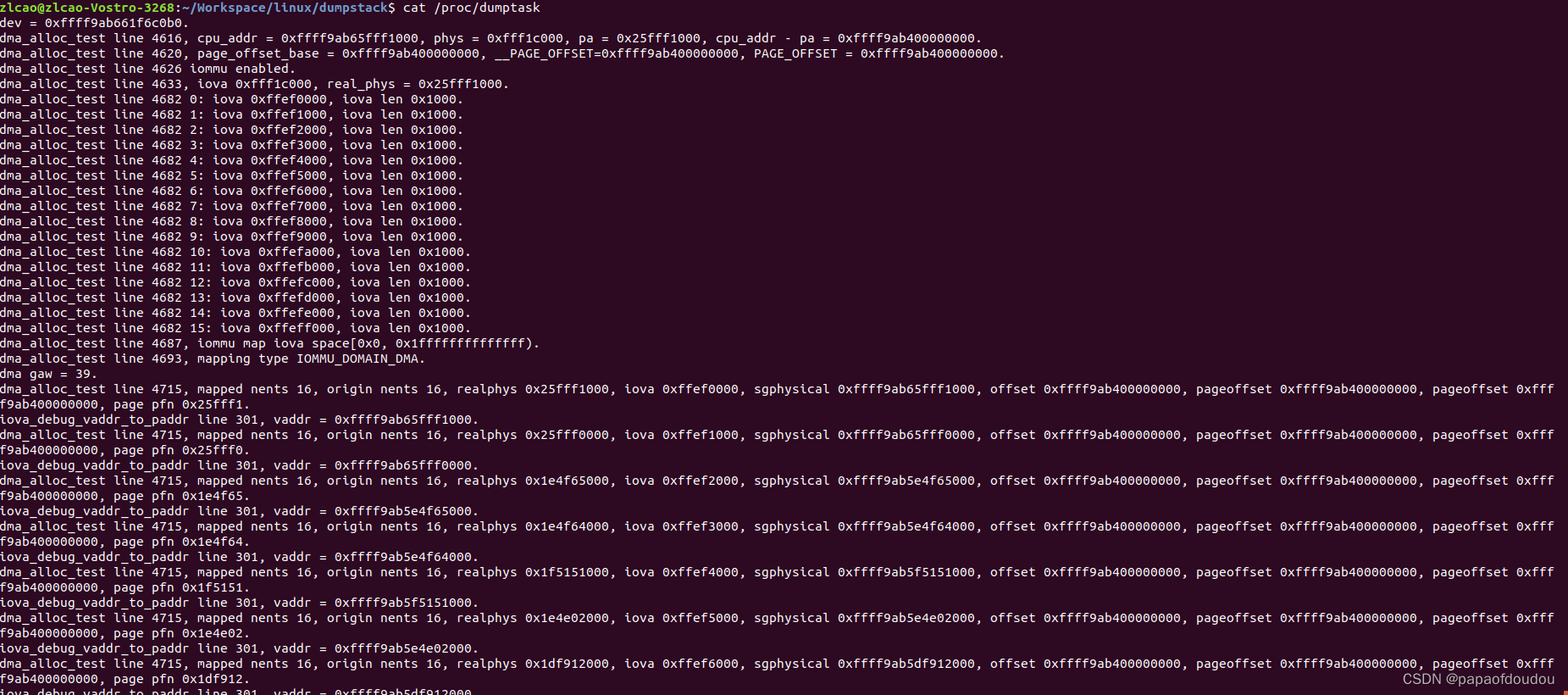
此时,realphys和iova不相等,map type 为IOMMU_DOMAIN_DMA。
3.设置为pass through模式intel_iommu=on iommu=pt 或者iommu.passthrough=1(等价于iommu=pt)。
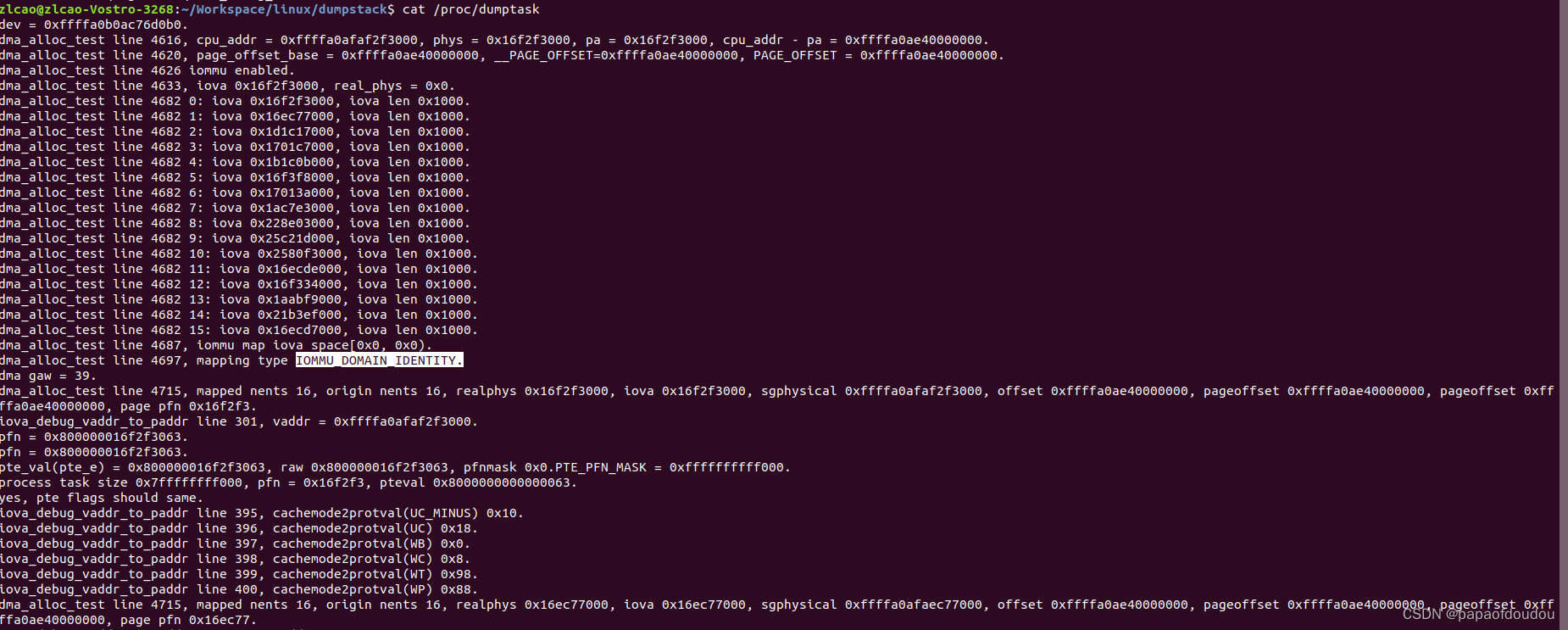
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash pci=realloc=on intel_iommu=on iommu=pt,strict cma=16M@0x26c000000 log_buf_len=16M"此时map type为IOMMU_DOMAIN_IDENTITY, iova为物理地址,从vaddr-iova=pageoffset即可看出。
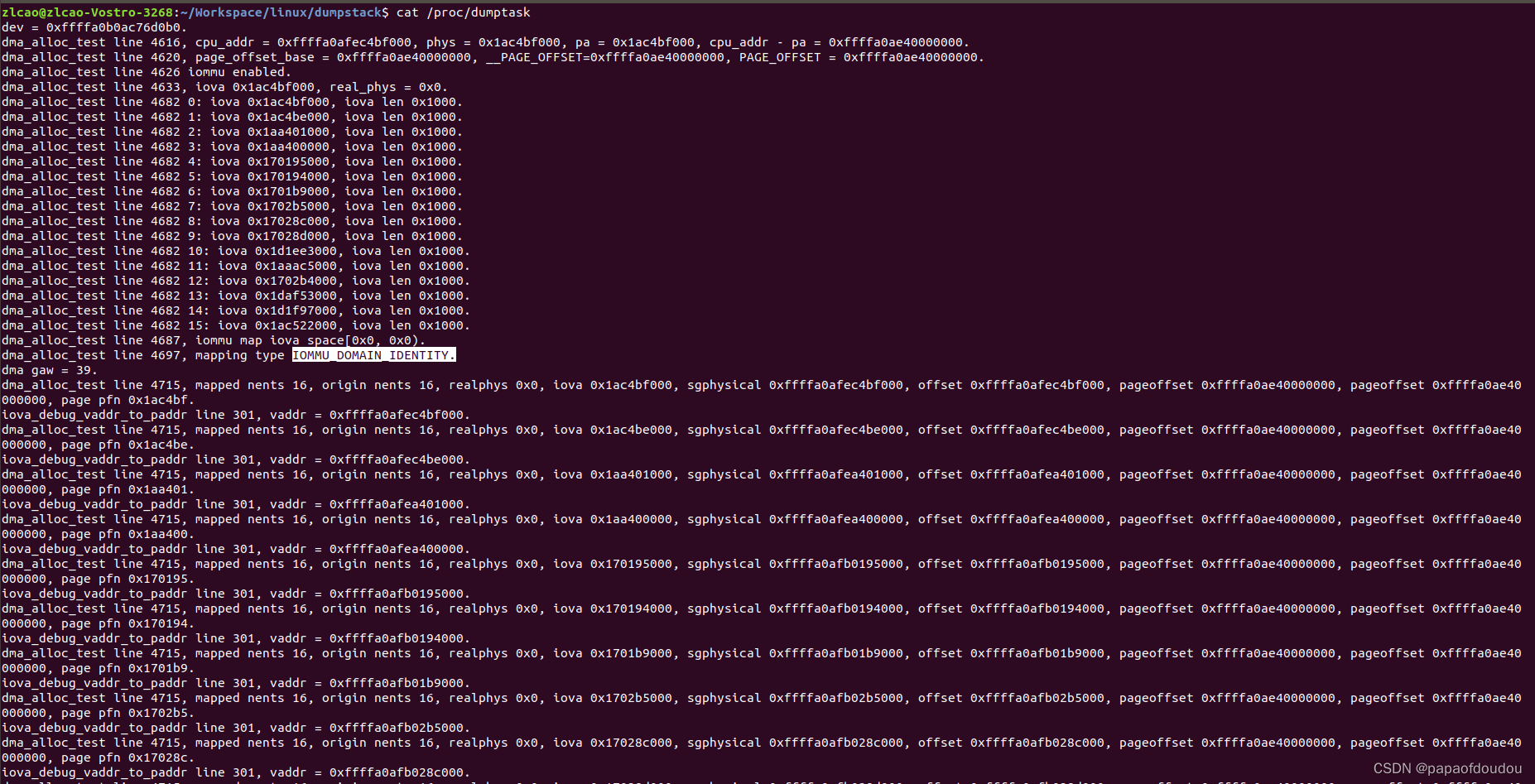
并且,此时通过iommu_iova_to_phys函数返回的realphys为0。修改逻辑后,realphys和iova相等,都为物理地址,所以pt(passthrough)就是IOVA和物理地址相同的设定。

设置PASS-THROUGH的方式有多种,还可以通过编译内核时打开CONFIG_IOMMU_DEFAULT_PASSTHROUGH宏定义去设置PASS THROUGH模式,见如下说明。

PASSTHROUGH并非是DISABLE掉IOMMU,虽然效果上类似,但应该还是有区别的。如果IOMMU支持硬件PASS-THROUGH翻译模式,则si_domain_init什么都不用设直接返回,而如果不支持PASSTHROUGH,则需要进行恒等映射,也就是IOVA==PA映射。
iommu.passthrough=0/1 如何控制设备默认的IOMMU DOMAIN?
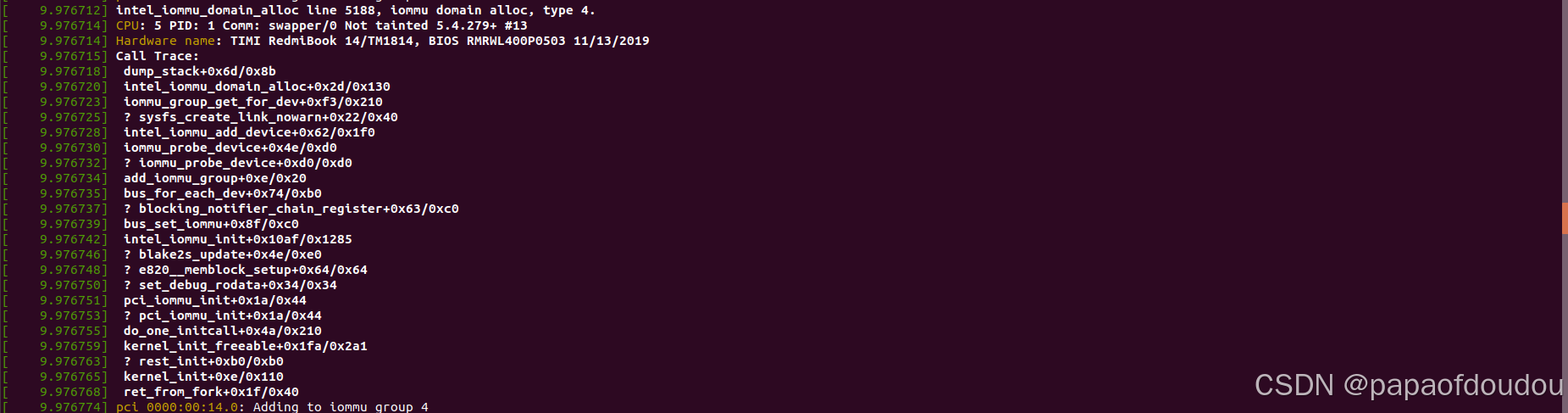
系统初始化时,会通过如下的调用堆栈为设备分批IOMMU DOMAIN,intel_iommu_add_device->iommu_group_get_for_dev,如果设备所在组还没有DOMAIN,会调用__iommu_domain_alloc为设备分配归属的DOMAIN,传入的DOMAIN TYPE即为iommu_def_domain_type,而iommu_def_domain_type则是由于系统配置或者命令行参数设置的,通过这种方式把控系统的IOMMU DOMAIN默认类型。
在实际的分配函数intel_iommu_domain_alloc中,只有DMA/UNMANAGED两种类型会真正分配IOMMU DOMAIN 对象实体,如果是IDENTICAL类型的IOMMU DOMAIN,则统一分配指向si_domain实体。
正是由于这个原因,我们看到了当默认iommu为pt模式时,所有设备(IOMMU GROUP)指向的IOMMU DOMAIN都是同一个SI DOMAIN,而当默认的IOMMU为DMA模式时,每个IOMMU GROUP都会分配自己的IOMMU DOMAIN对象。
iommu.passthrough=1:

iommu.passthrough=0:

不同的iommu domain,映射方式可以不同,也可以相同:
在我的XIAOMI 笔记本上,BDF0000:00:14.0的USB设备和BDF为0000:02:00.0 独立显卡设备的DOMAIN是不同的,0000:02:00.0独立显卡即便你系统设置为PASS THROUGH模式,其实际的映射也是IOMMU_DOMAIN_DMA,IOVA和物理地址不同。
但是BDF0000:00:14.0 USB设备所在的domain则为IOMMU_DOMAIN_IDENTITY类型的map type.其IOVA和物理地址相同。
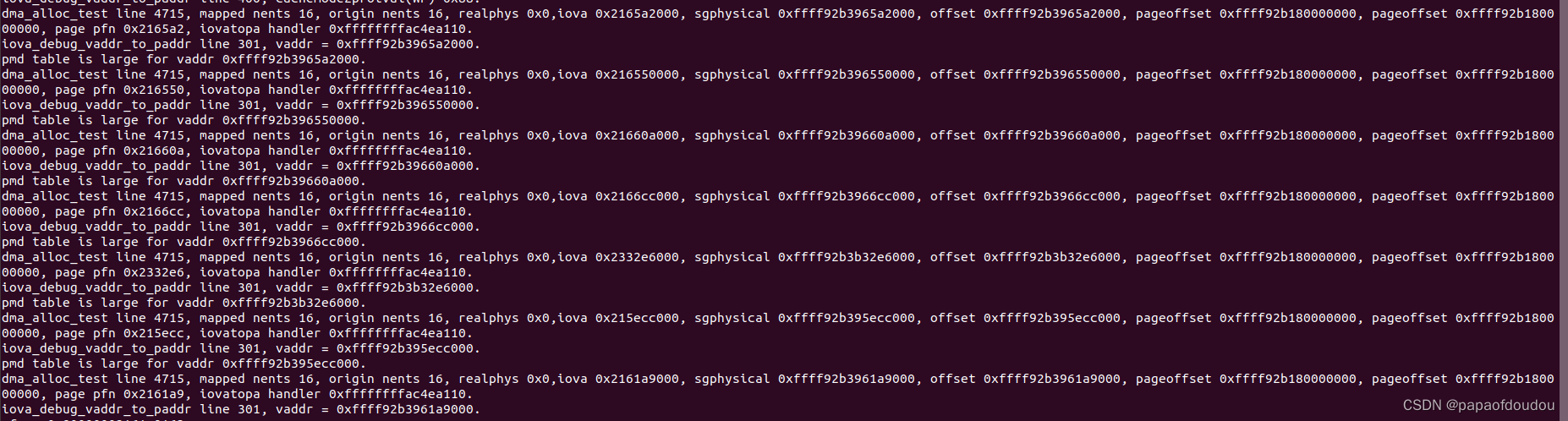
并且,identical map下,iommu_iova_to_phys返回物理地址为0的原因也可以澄清,在实际函数intel_iommu_iova_to_phys下加入打印:
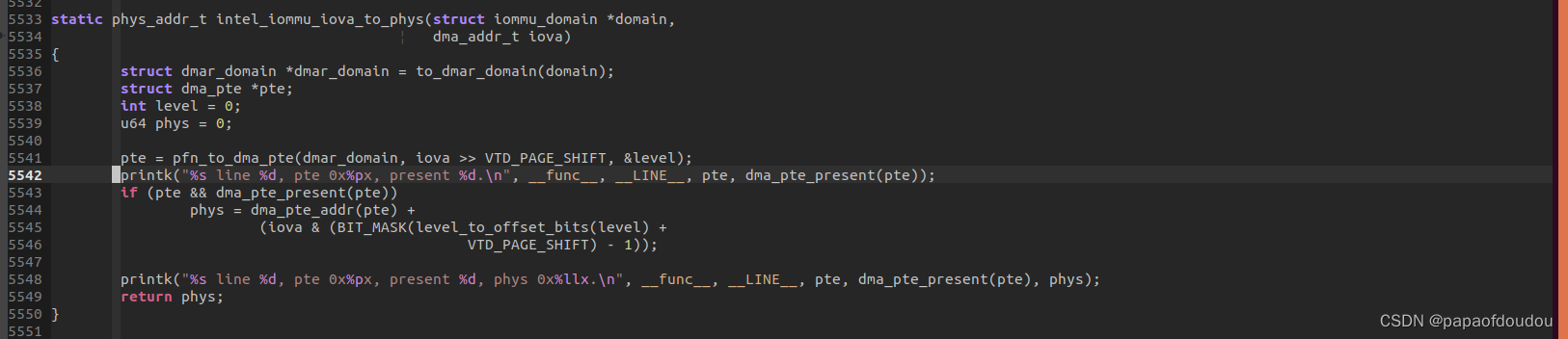
可以看到其PTE页表的present标志并没有设置,所以相当于不需要查找页表,返回0。

所以,map type 是 per domain的。
查看每个设备所属domain的映射类型
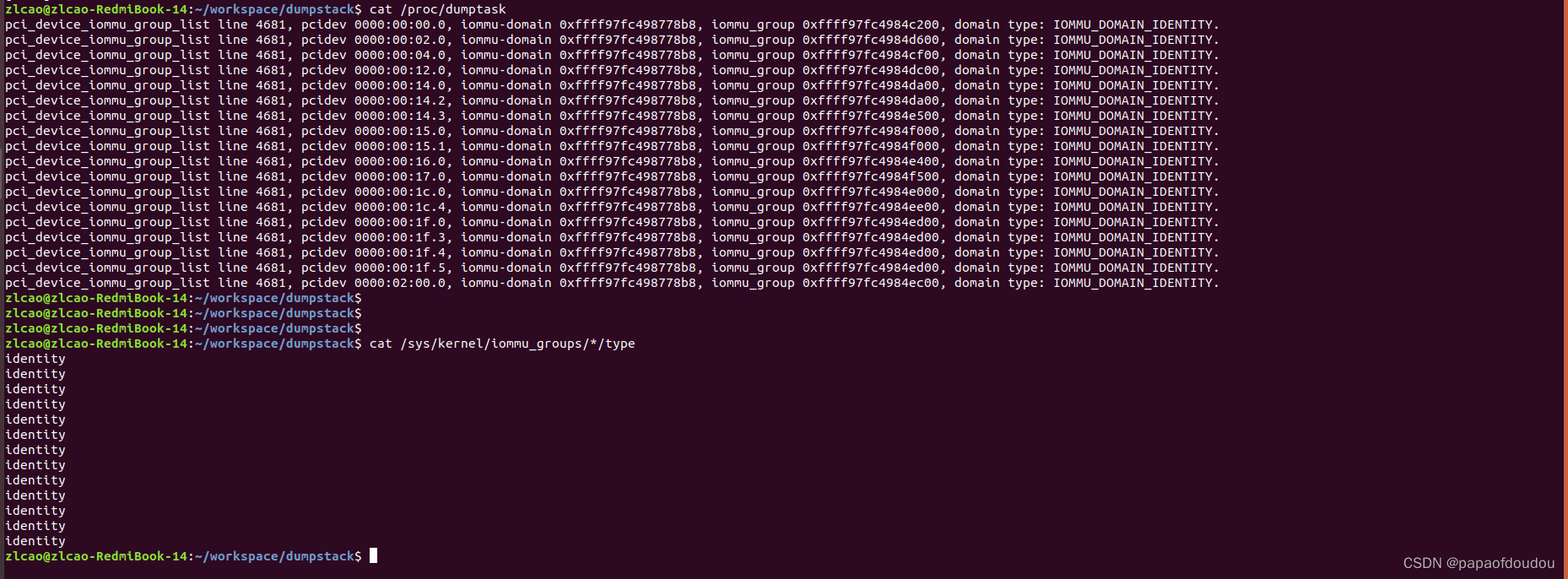
可以看到,只有高通的无线网络适配器是DMA Map的,而其它设备都是IDENTICAL的。

$ cat /sys/kernel/iommu_groups/*/type
分析dma_map_sg的实现,发现其建立IOVA到PHYS映射的时候,其顶层页目录pgd是从domain字段中获取的,所以,如果设备的domain相同,则它们的映射表共用一个,只要做一把映射,所有设备都可以访问这个IOVA地址:

蓝色框为IOMMU GROUP的个数,domain则只有两个,分别为identical 14个,DMA 映射的1个。
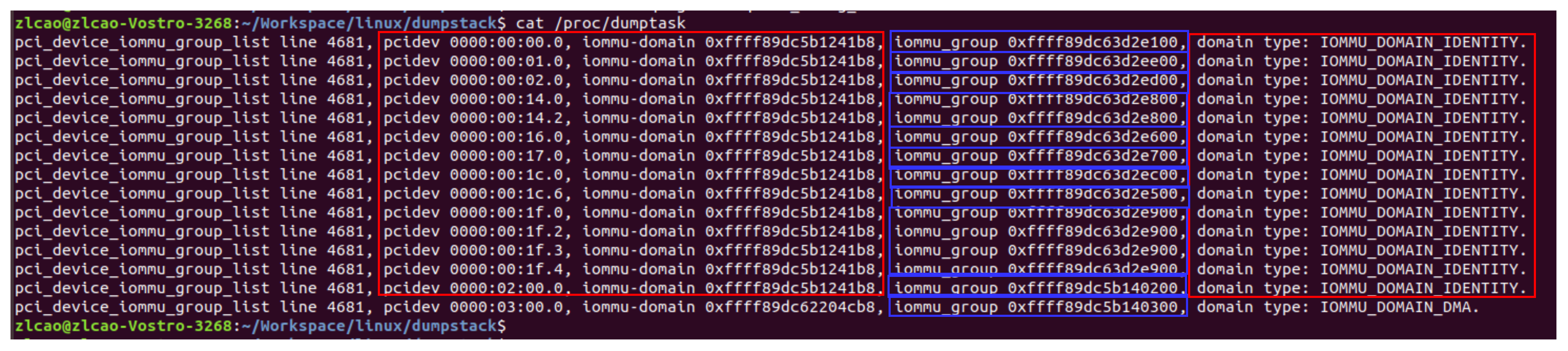
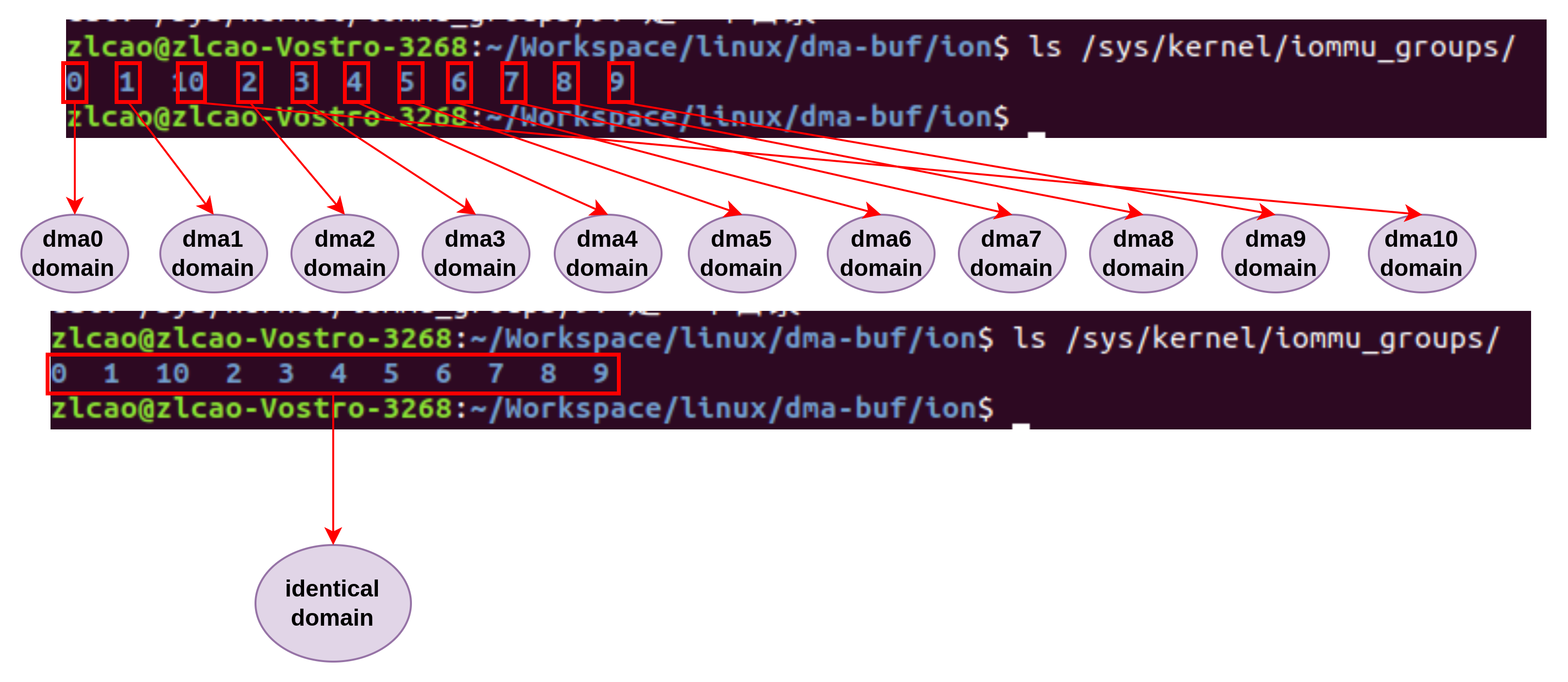
另一台电脑的情况似乎略有不同,这台电脑的信息显示,同一个GROUP内属于一个domain,不同的group,即便有相同的map type,仍然属于不同的domain.
在 xiaomi pc上打开CONFIG_IOMMU_DEFAULT_PASSTHROUGH后重新编译内核,所有设备的IOMMU MAP类型都变为了IOMMU_DOMAIN_IDENTITY,分组不变还是13组,但是DOMAIN数量从13变为了1个,不再和GROUP数目对应相同。
所以这样来看,前面分析的IOMMU GROUP和IOMMU DOMAIN是一一对应的结论并不全面,也可能会出现有多个GROUP对应1个domain的情况.一个GROUP最多只对应一个DOMAIN,而1个domain可以由一个GROUP或者多个GROUP对应的情况,用公式表示就是:
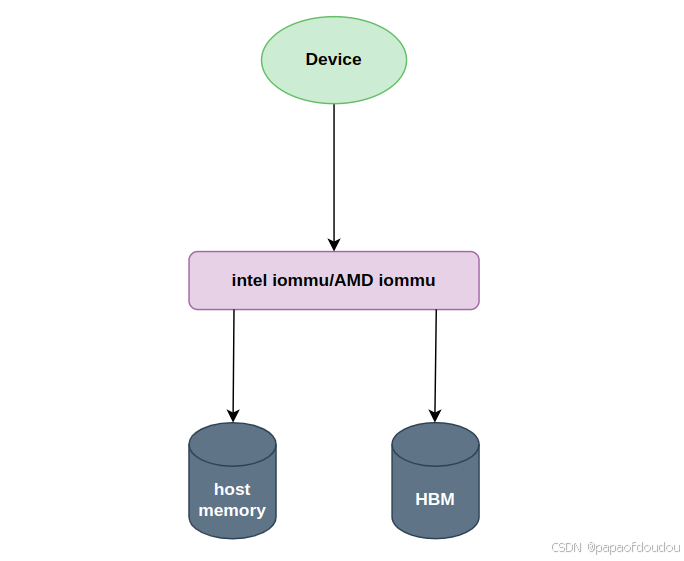
测试发现,对于DMA映射模式,8张GPU卡访问HOST MEMORY,每张卡都要以自身设备为参数调用dma_map_sg对HOST MEMORY进行一次映射才可以访问,本质上是通过设备找到iommu group,进而找到iommu domain,最终找到页面表PGD,由于设备归属不同的IOMMU group,意味着有可能属于不同的DOMAIN,所以同一个HOST BUFFER必须对每个设备单独映射一遍才可以被设备共享访问,如下图显示了8张卡的IOMMU GROUP,可以看到8张卡归属不同的IOMMU GROUP。

分析内核代码,发现CONFIG_IOMMU_DEFAULT_PASSTHROUGH影响的地方只有1处,经过验证,这里正是造成IDENTICAL和DMA MAP不同的原因。

为什么Indentical map下,domain和group不再是一对一?
从dma main切换到identical map,domain 和 group之间的关系从一对一到一多对,造成这种改变的的原因是什么?我们还是从代码分析入手:
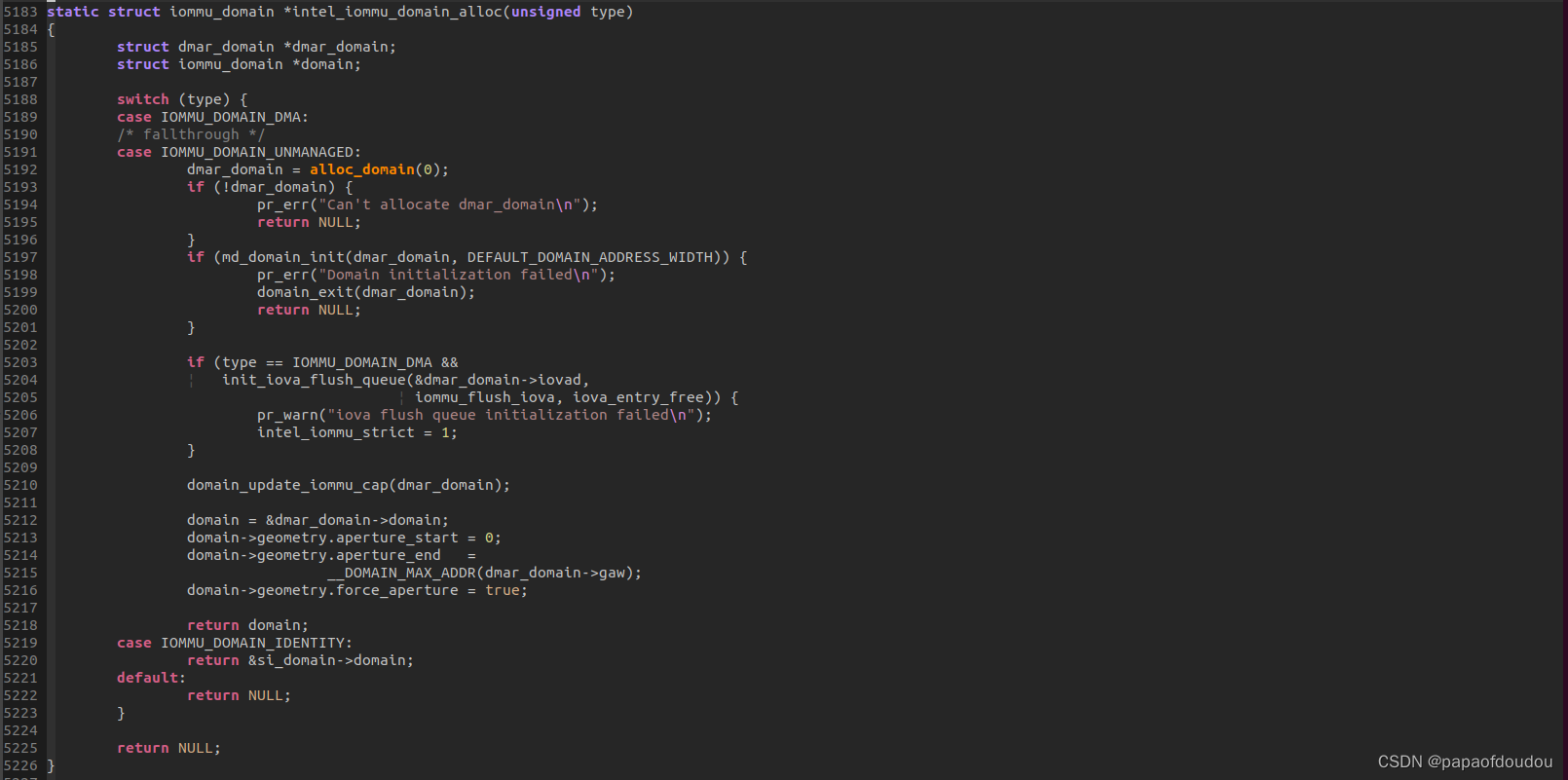
从intel_iommu_domain_alloc可以看到,在IOMMU_DOMAIN_DMA/IOMMU_DOMAIN_UNMANAGED两种模式下,流程会为每个GROUP分配一个新的domain,但是当映射类型为IOMMU_DOMAIN_IDENTITY时,流程返回的是唯一的一个静态分配的domain&si_domain->domain,所有group共享,所以造成了如此差异。
si_domain在系统启动时初始化,初始化过程中,调用函数iommu_domain_identity_map对每个内存节点进行一次全范围内的恒等映射,使IOVA==PA。
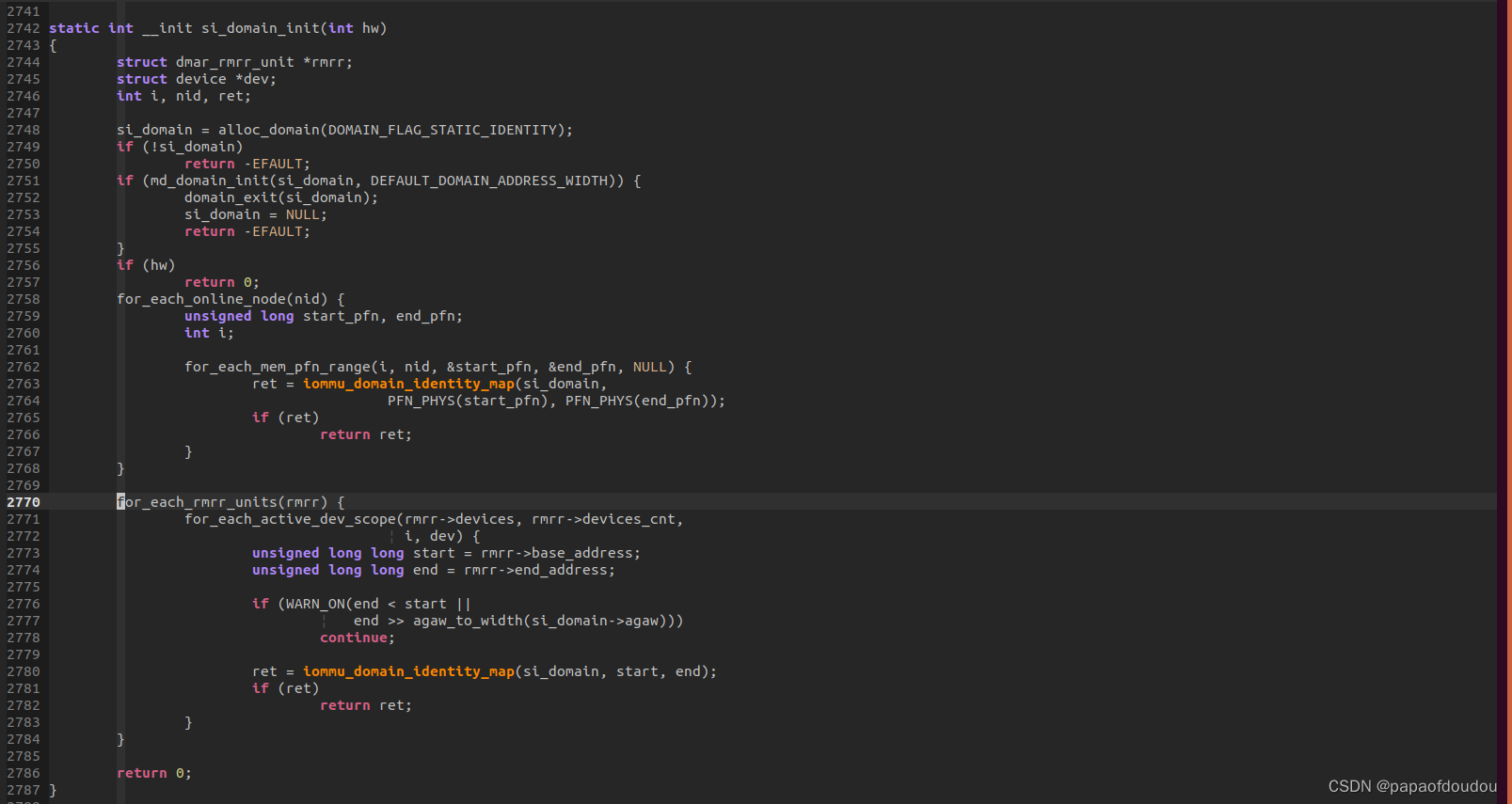
但是如果硬件支持硬件BYPASS机制,则会设置hw_pass_through变量,传递给si_domain_init,也就是si_domain_init函数中的hw参数,当hw为1时,无需建立iova与pa 1:1映射的iommu页表,仅仅分配一个si_domain对象管理所与PT设备即可,否则需要对all usable memory建立iova与pa 1:1映射的iommu页表。


在启用命令行参数iommu=pt与否两种情况下,PCI设备的MAP TYPE类型是不同的:

不传递iommu=pt启动参数时,所有设备的MAP类型为DMA,并且group num == domain num.

传递iommu=pt的情况下,就是如下图的样子,domain num和group num是1对多的关系:
小结
配置了iommu=pt就会实现identity mapping:
- 如果Hardware supports pass-through translation type,则配置pass-through translation type即可实现identity mapping,此时无需配置iommu页表;
- 如果Hardware doesn’t support pass-through translation type,则需要配置iommu页表,使得iova与pa 1:1映射。
当hw_pass_through=0时,依然要走iommu页表,因此性能是不如hw_pass_through=1的。
Notes about iommu=pt kernel parameter - L
设备 iommu domain切换
在某些场景下,直接映射可能不满足要求,映射流程会判断这种情况,随之建立新的DMA Domain MAP,并且将设备和新的DMA domain进行关联。
前面图中在DEFAULT为IDENTICAL MAP的情况下,唯一出现的DMA TYPE 映射就是因为设备发生了DOMAIN 切换情况。iommu domain切换由函数iommu_need_mapping进行,切换的依据是判断设备IOVA是否只支持32位,由于SI IDENTICAL DOMAIN只支持64位IOVA,所以必须切换到DMA TYPE支持32位IOVA,调用iommu_request_dma_domain_for_dev重新分配一个DMA TYPE的IOMMU DOMAIN。关于这个逻辑,后面还要再分析一下。

iommu_need_mapping
当dma_mask < dma_direct_get_required_mask(dev)时,会为当前设备分配一个DMA 类型的IOMMU DOMAIN,而非默认的si_domain, 注释中提到原因是因为si_domain不支持32位的映射。这两者之间有什么联系呢?
由于在IDENTICAL MAP下,IOVA和PHYSICAL地址相等,所以设备DMA_MASK表示的IOVA范围应该大于dma_direct_get_required_mask返回的系统可用于DMA的物理内存范围(IOVA等于物理内存嘛),也就是说,必须要保证DMA MASK表示的IOVA能力能够覆盖物理内存的范围。而当条件不满足时,需要通过IOMMU 页表映射,由于IOMMU 页表是64位的,将过大的物理内存映射到符合DMA MASK要求的IOVA范围之上,这样,就可以通过 IOVA访问物理内存了。代价就是必须分配新的IOMMU DOMAIN做 DMA 映射而非IDENTICAL映射。
kernel的处理中,非IOMMU_DOMAIN_DMA映射都是direct映射,所以看上去 IDENTICAL MAP参数对于内核和设备来说是suggestion,不是mandatory.

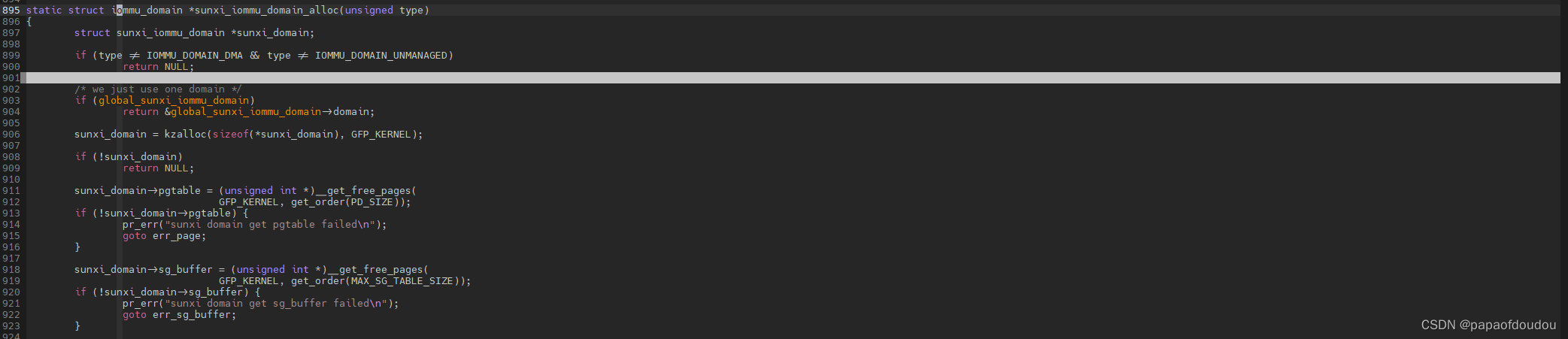
sunxi-iommu
sunxi-iommu就是只有一个GROUP/DOMAIN,所有MASTER 设备共享同一个IOVA分配空间,只有一份页表。由于在一个DOMAIN中,设备之间可以互相访问。
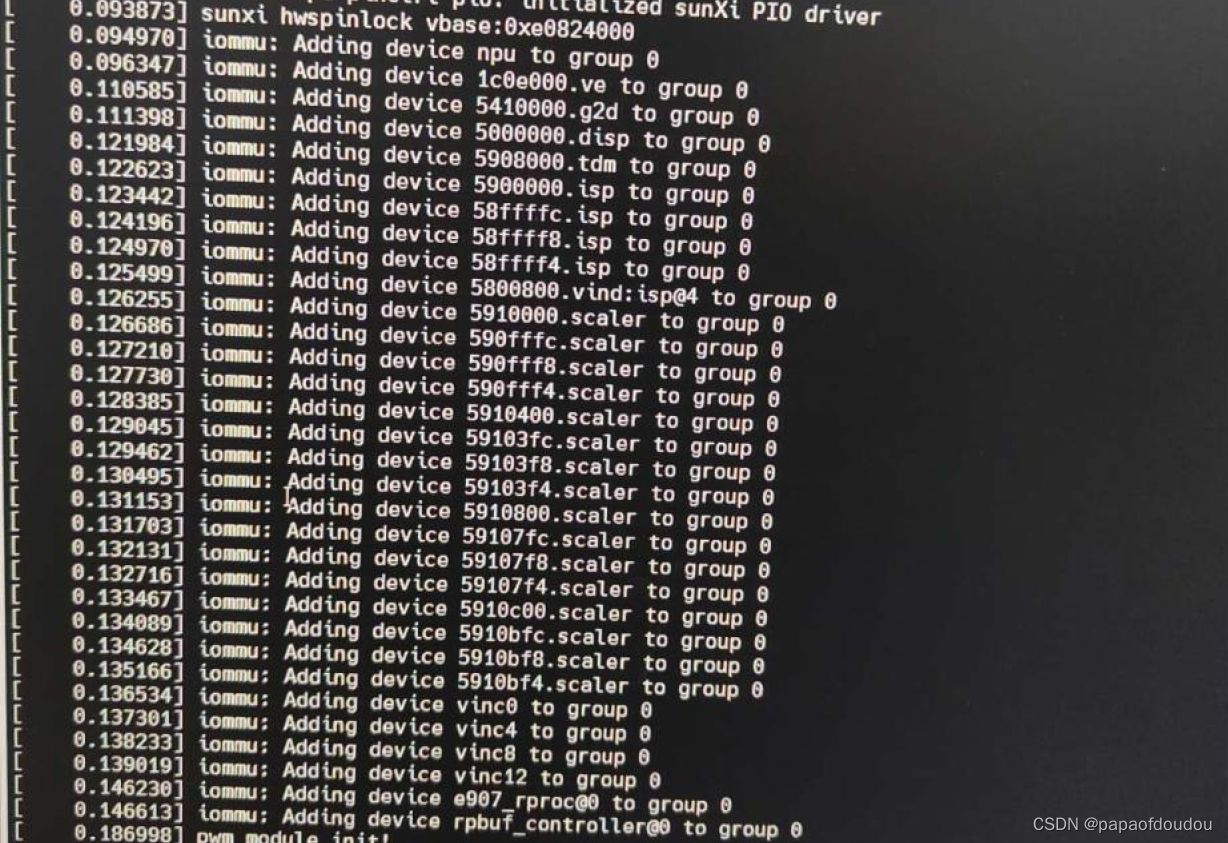
sunxi iommu只有一个iommu group,如上图的iommu group 0.使用单例模式初始化。
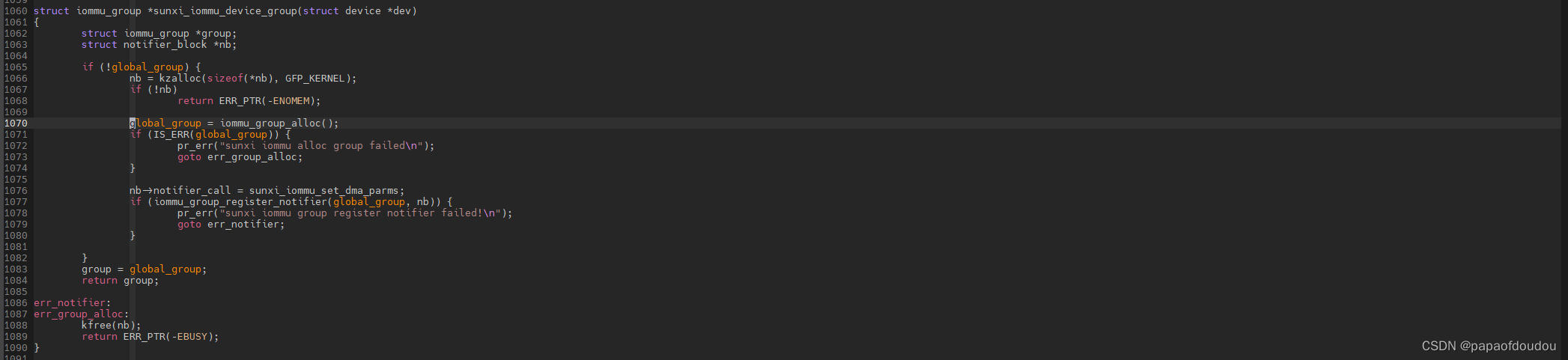
不同的设备分配到同一个组的调用堆栈如下:
Linux iommu Debug
intel和AMD对 IOMMU DEBUG的支持需要在内核中开启DEBUG配置选项,对于INTEL,尝试打开:
CONFIG_IOMMU_DEBUGFS=y
CONFIG_INTEL_IOMMU_DEBUGFS=yAMD:
CONFIG_IOMMU_DEBUGFS=y
CONFIG_AMD_IOMMU_DEBUGFS=y以INTEL为例,打开选项后重新编译内核,DEBUGFS会出现/sys/kernel/debug/iommu/intel目录:

查看dmar_translation_struct文件内容:
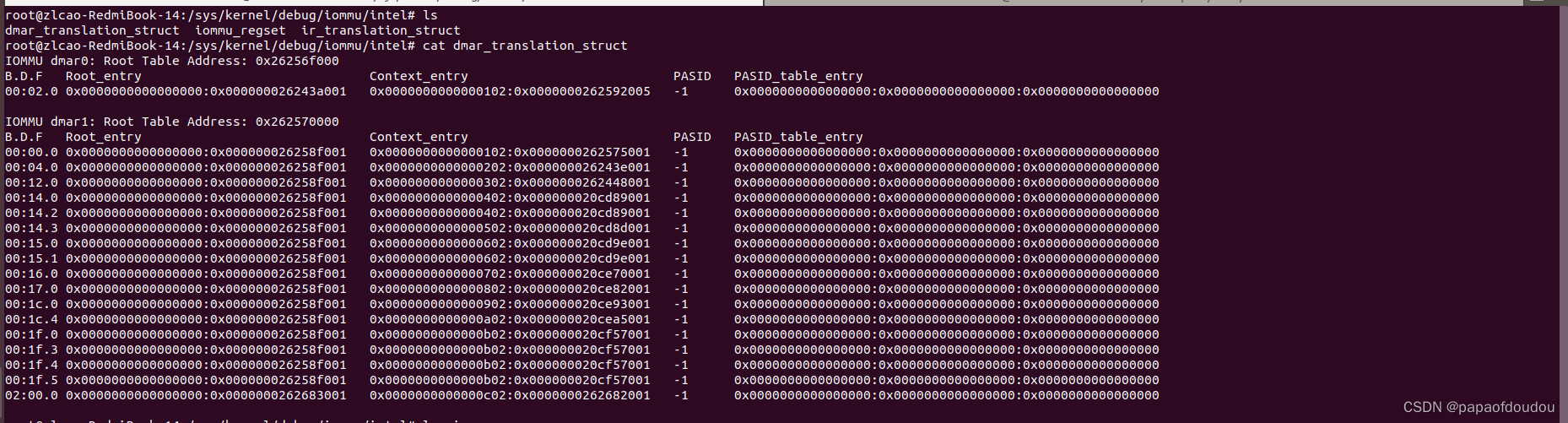
可以看到,同一GROUP下的设备的context entry是一样的,代表使用同样的IOMMU映射表。
context_entry存储的就是设备映射的PGD,同一个domain下的pgd是一样的。
当IOMMU映射被设置为PASS-THROUGH模式时,可以明显看到和DMA模式的区别,首先,PGD不存在了,另外,translation type变成了2,也就是CONTEXT_TT_PASS_THROUGH,所以,IOMMU硬件来说,PASS THROUGH是硬件感知的一种模式。

我用的电脑INTEL IOMMU有两个DMAR,每一套DMAR提供一个root entry table寄存器存放root entry。正好对应DMAR寄存器的内容:

INTEL IOMMU DMAR貌似有两套,对应截图上的DMAR0,DMAR0:

PASID
PASID的范围由PCIE设备指定,不过设备页表中的PASID全部为0,没有用到,暂时不清楚INTEL IOMMU中的PASID的具体用途。

下图是PCIE配置空间中的PASID/ATS capability 配置:
系统启动时IOMMU默认的工作状态
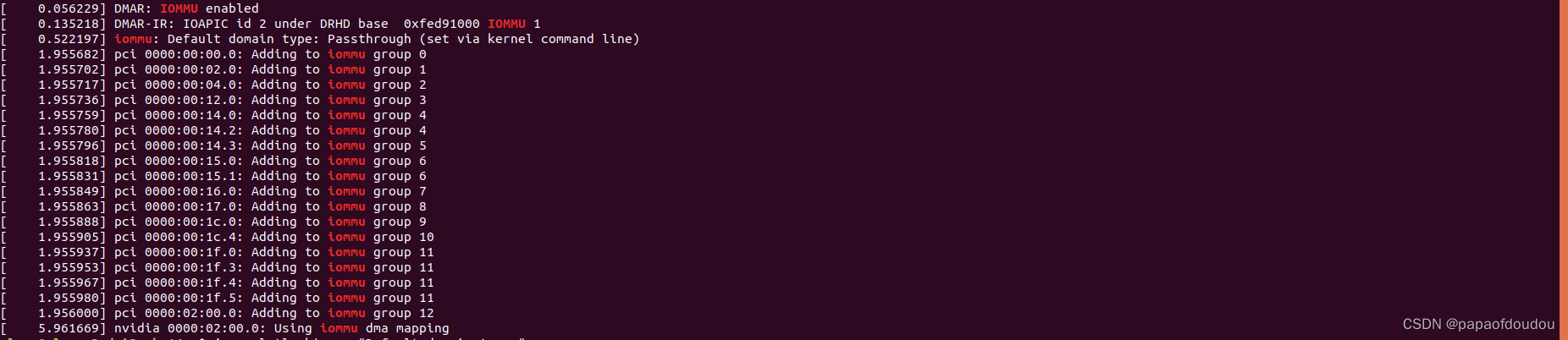
系统正常启动时,其IOMMU可以工作在Passthrough/Translated等状态,并且在DMESG中打印出来,其状态可以由默认的CONFIG内核配置控制,也可以通过启动命令行设置:
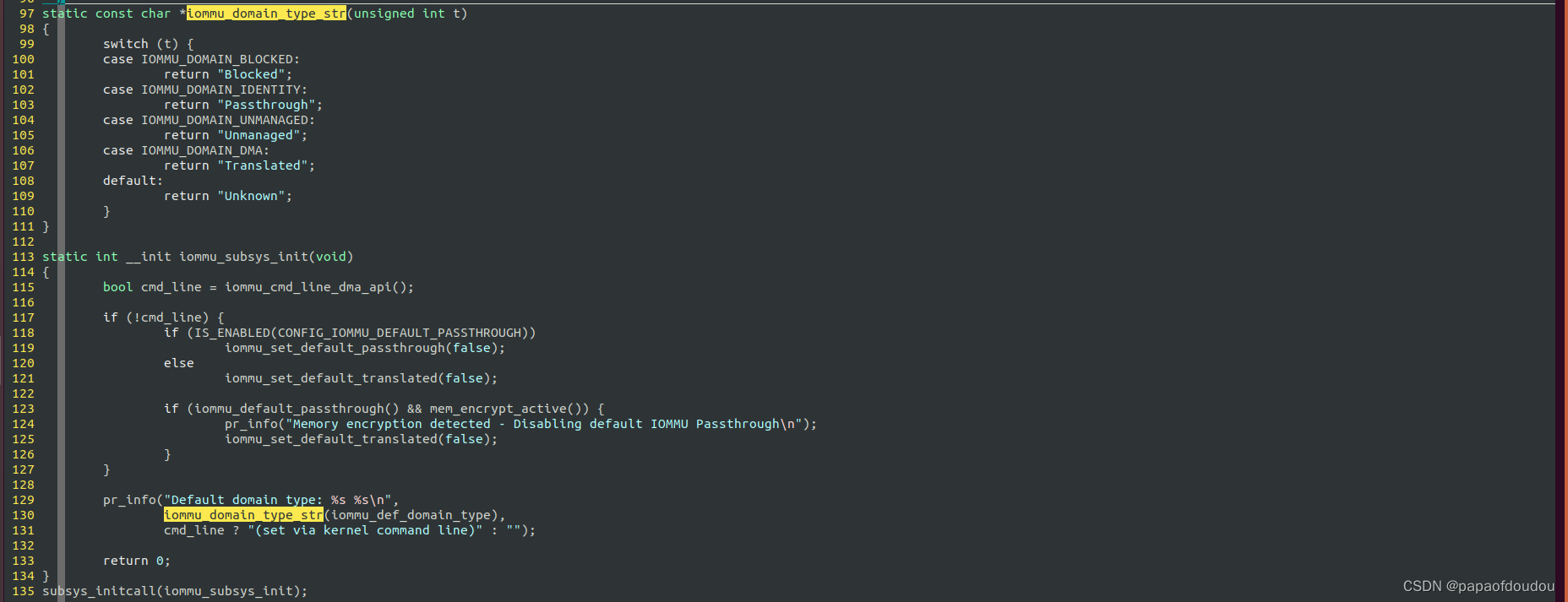
当设置方是命令行时(iommu = pt),LOG中将会显示设置源“set via kernel command line”。
iommu ops的作用域
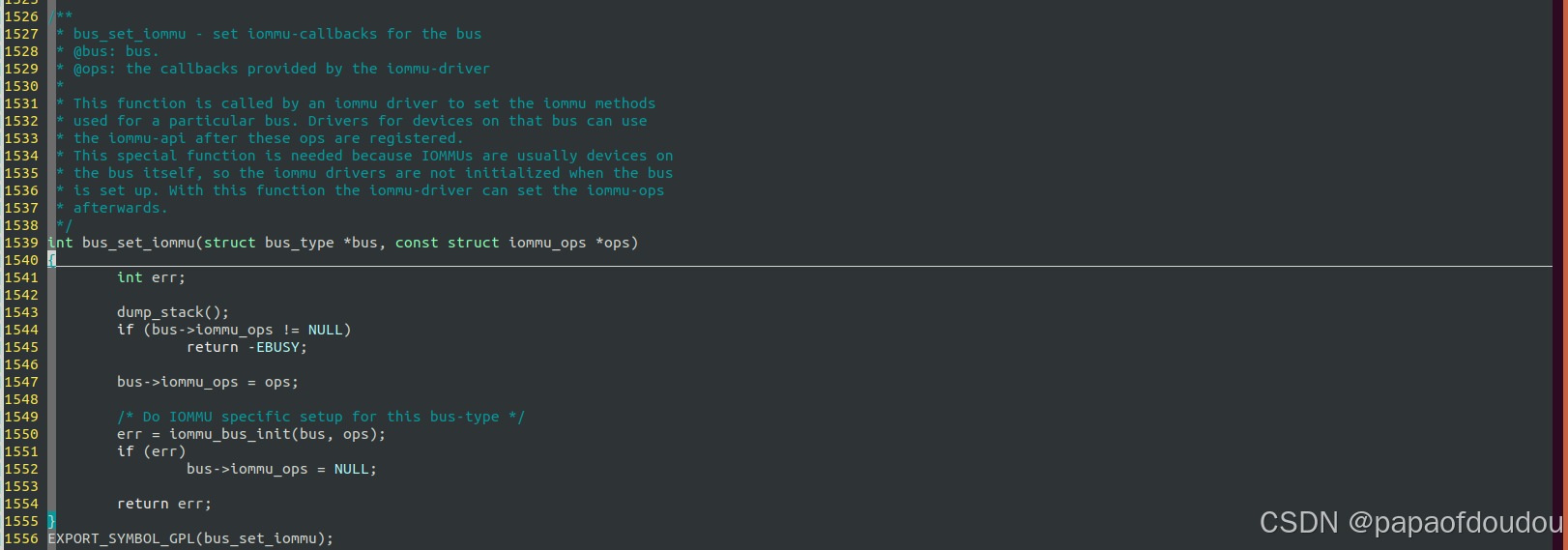
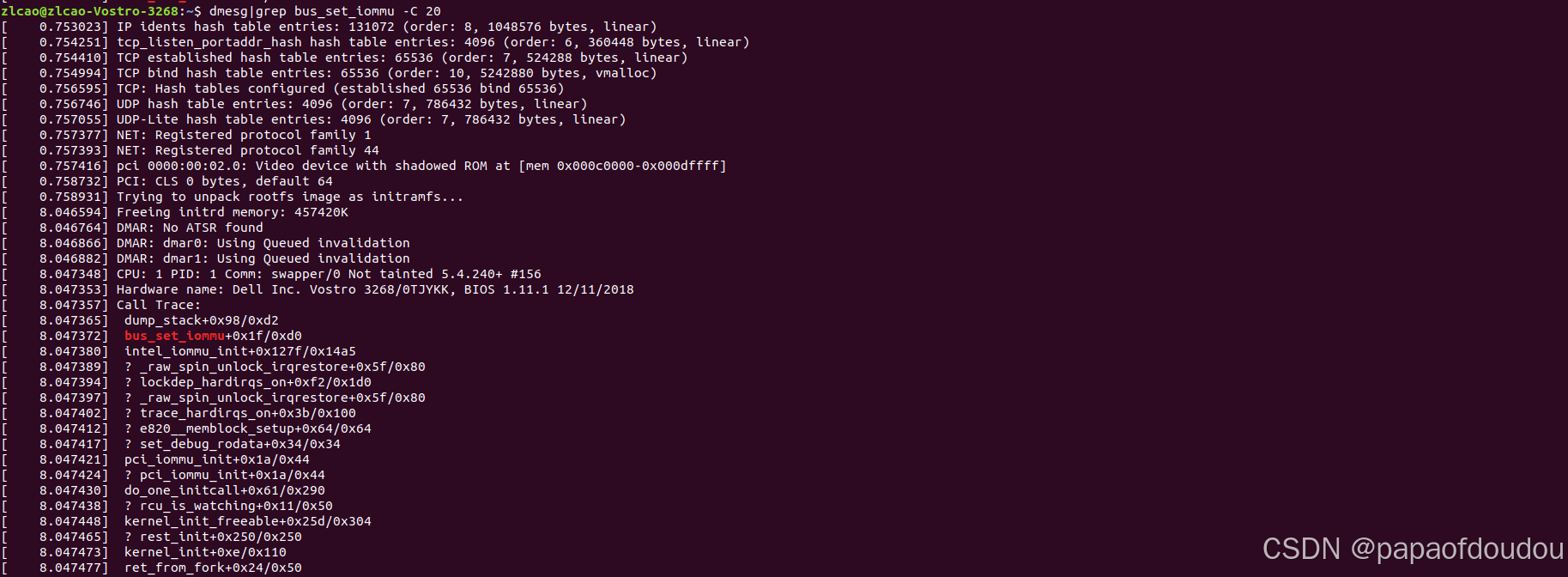
iommu ops 的作用域是总线,如果总线支持iommu映射,则其上的所有设备均支持IOMMU映射。IOMMU初始化阶段会调用bus_set_iommu设置总线上所有设备对象的IOMMU支持信息。

对于没有调用bus_set_iommu的总线,比如platform总线,其上的设备不支持IOMMU映射。总线上可以挂接多个IOMMU DOMAIN,创建IOMMU DOMAIN时的入参是BUS,并将iommu domain ops赋值为bus->iommu_ops:

如果再调用bus_set_iommu时,设备还没有注册也没有关系,bus_set_iommu调用时会注册iommu_bus_notifier函数,当新增加的设备调用device_add时,会通过iommu_bus_notifier函数触发对iommu_probe_device的回调,把设备增加到IOMMU中来。
而对于platform_bus_type设备,即使手动调用bus_set_iommu注册intel_iommu_ops也不会起作用,因为在X86平台上,调用链中的intel_iommu_add_device会判断设备是PCI相关设备,如果不是,返回-ENODEV。所以可以看出来,在PC上,只有PCI设备才能使用IOMMU。返回的-ENODEV并不会被认为失败,因为它仅仅表示设备不能使用IOMMU进行地址翻译,但是并不意味着它无法使用。

虽然X86上的平台设备没有使用IOMMU进行地址映射,但是设备本身是绑定dma_map_ops的,虽然这个dma_map_ops会因为前面讨论的原因,没有IOMMU关联而无法执行真正的映射。

根据get_dma_ops的实现,当设备中有自己的dma_map_ops,也就是dma_ops时,将返回设备自身的,当设备没有的时候,调用get_arch_dma_ops返回平台的,在X86系统上,默认设备的为空,使用全局平台的dma_map_ops, dma_ops是一个全剧变量:

iommu是否可以嵌套使用?
一般情况下,IOMMU在实现设备透传和HOST 设备地址重映射中发挥关键作用,HPA可以经过EPT和MMU两级映射到VCPU的 GVA上,但是似乎IOMMU只能完成 IOVA到HPA的映射,GUEST OS内的设备驱动似乎无法再使用IOMMU作 GUEST IOVA到GPA的映射。比如,在GUEST OS中 HACK struct device dma ops 和struct bus_type->iommu_ops,得到的都是空指针。但是似乎QEMU提供了一种IOMMU设备,可以在GUEST OS中使用IOMMU,在启动QEMU时候增加一些参数,就可以在虚拟机中看到DMAR 设备:
sudo qemu-system-x86_64 -machine q35,accel=kvm,kernel_irqchip=split -m 4096 -smp 4 --enable-kvm -drive file=./zlcao.img -device intel-iommu,intremap=on,caching-mode=on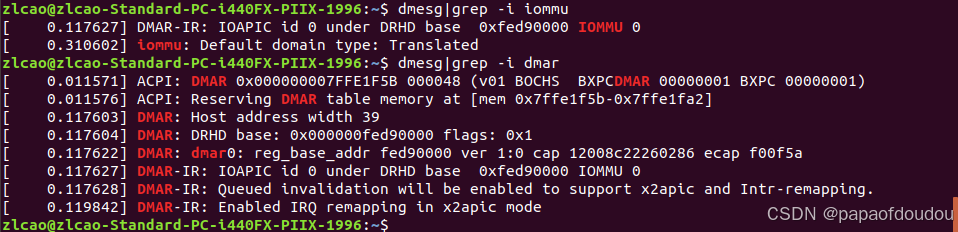
而如果使用如下参数启动虚拟机,则启动后GUEST OS中不会发现DMAR设备:
sudo qemu-system-x86_64 -machine q35,accel=kvm,kernel_irqchip=split -m 4096 -smp 4 --enable-kvm -drive file=./zlcao.img -device intel-iommu,intremap=on,caching-mode=on
Linux kernel 有一个变量"iommu_detected"用于记录系统中是否存在IOMMU硬件。在HOST机中为1,在GUEST OS中为0:

桌面系统中,哪些BUS会和IOMMU OPS绑定?
bus_set_iommu会将BUS和IOMMU OPS绑定,所有挂到这条BUS上的的设备都会通过IOMMU访问内存,经过实测,发现桌面系统中,只有PCI BUS才会和IOMMU OPS绑定,所以,桌面系统中只有PCI 设备通过IOMMU访问内存。
一些理解
只要涉及到访问IOMMU的路径,就没有CPU的事情,IOMMU的 master只能是设备,而SLAVE可以是Host Memory或者通过Bar映射的设备Memory总线地址。
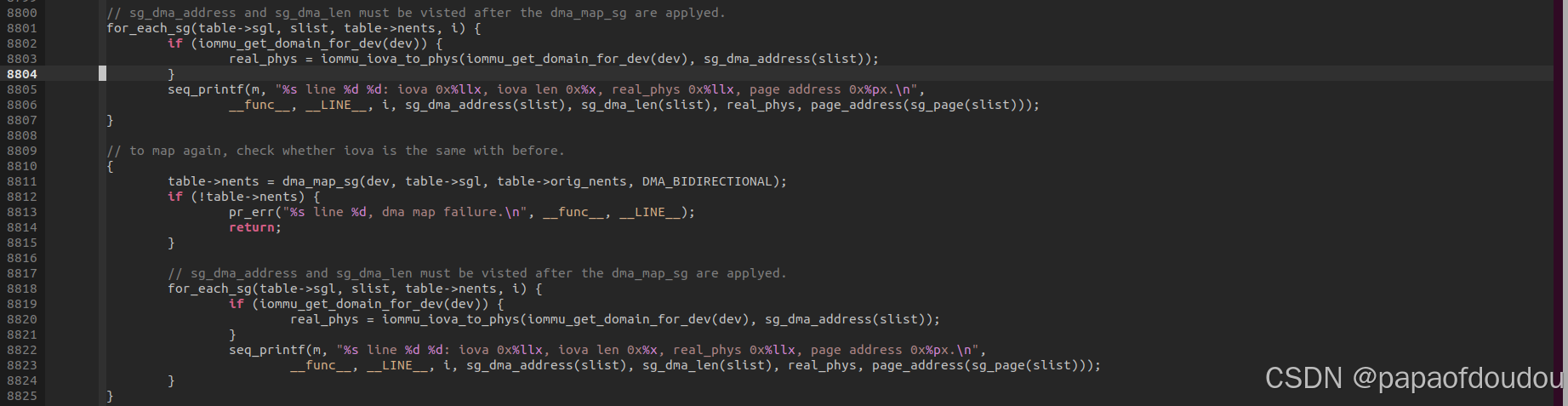
一个设备连续调用两次iommu_map/dma_map_sg对同一个物理页面进行映射,会返回不一样的IOVA吗?
是的,看下面的测试用例,对同一个物理页面连续进行两次dma_map_sg调用,前后两次分别返回0xffe20000和0xffe10000,利用API iommu_iova_to_phys翻译后确实是同一个物理页面。

进程之于MMU就相当于设备之于IOMMU,IOMMU不需要保留进程信息,只需要保留设备信息。设备之所以不象进程那样,每个进程有独立的IOVA空间,是因为进程会退出,生命期是暂时的,但是设备就在那里,它一致存在,所以同一个DOMAIN下不同设备的IOVA映射在同一个地址空间,进程要访问存储,需要经过设备的中转。
"iommu=pt"内核启动参数哪里生效的?
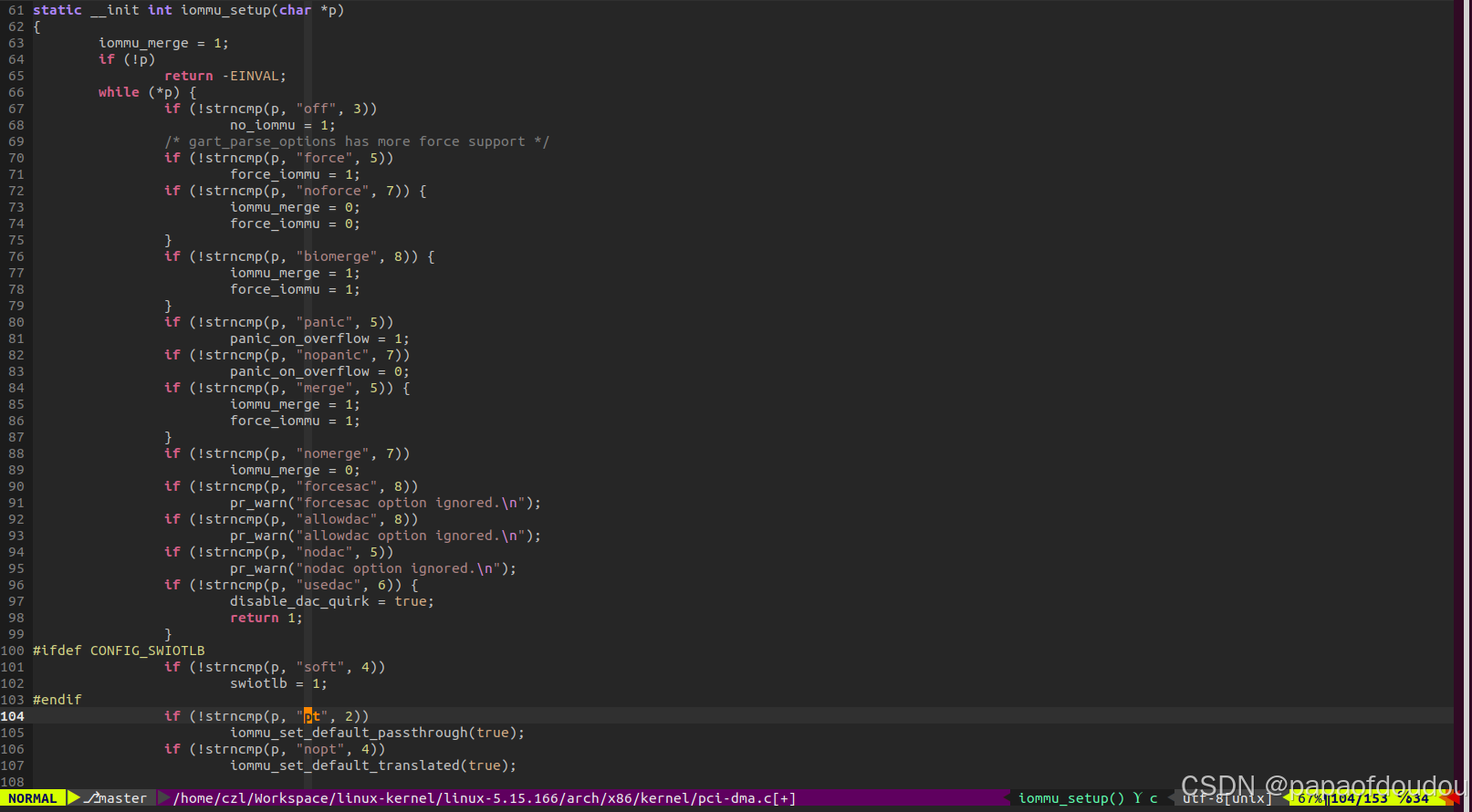
无论是AMD还是INTEL处理器上,都可以通过传给内核启动参数"iommu=pt"设置IOMMU PASS THROUGH,但是在AMD和INTEL的IOMMU驱动中,并没有处理这个参数的逻辑,实际处理"iommu=pt"的逻辑在x86/kernel/pci-dma.c中,这也是AMD和X86同时支持的原因。
参考文档
https://zhuanlan.zhihu.com/p/610416847
Documentation/core-api/dma-api-howto.rst
Documentation/admin-guide/kernel-parameters.txt
https://blog.linuxplumbersconf.org/2012/wp-content/uploads/2012/09/2012-lpc-virt-vfio-williamson.pdf
https://www.linux-kvm.org/images/b/b4/2012-forum-VFIO.pdf
设备穿透之IOMMU分组 - 知乎
Linux ion&dma-buf&iommu的原理_papaofdoudou的博客-CSDN博客



















 2705
2705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











