







CPU为什么会乱序?
原因是为了提高CPU的效率,挖掘程序并行度,将不相关的操作并行执行,排在后面的指令不等前面的指令执行结束就开始执行,并且在前面的指令执行结束前结束,例如在CPU0上执行下面两条指令:

在乱序情况下,b=2可能会早于a=1执行完。这种乱序,在其他流水线上是可见的,因为毕竟内存是共享的,但是CPU无法感知多核之间的数据依赖关系,假如另一条流水线运行的业务依赖这个赋值的先后顺序,如果不加处理,则有可能会导致业务逻辑出现错误。在单个流水线上乱序执行有没有这种问题呢?我认为是没有的,原因如下:
1.首先,如果a先于b完成自闭不言,本身就符合逻辑顺序。
2.b先于a完成,但是都早于assert完成,这种执行上虽然是乱序,但是从结果上和逻辑一致,也不会有问题。
3.b先于a完成,assert执行时,a还没有退役,这种情况下,a虽然没有完成,但是a最新状态要么在保留站中,要么在ROB中,要么由于数据相关指向另一个ROB或者保留站,无论哪种情况,最新状态都会从流水线内部的状态获得,而不会直接取内存(具体分析可以看量化这本书),所以仍然能够获取新值,不会出错。
a的最新值要么在流水线中,要么在内存中,即便执行顺序被打乱,但是仍然能够获取到正确的数据,所以,单条流水线不会有问题。
多流水线多发射就不行了,多流水线下,一条流水线不能从另一条流水线取数据,只能从内存中获取旧值,造成错误。


流水线的乱序和多发射
CPU流水线:

流水线个数不是乱序执行或者多发射的必要条件,乱序或者多发射也可以在单流水线上实现。

suprscaler是超标量,表明系统中存在多个流水线,而超流水线特指流水线的深度。而单流水线也可以多发射,所以图中应该是超流水线,而不是超标量流水线



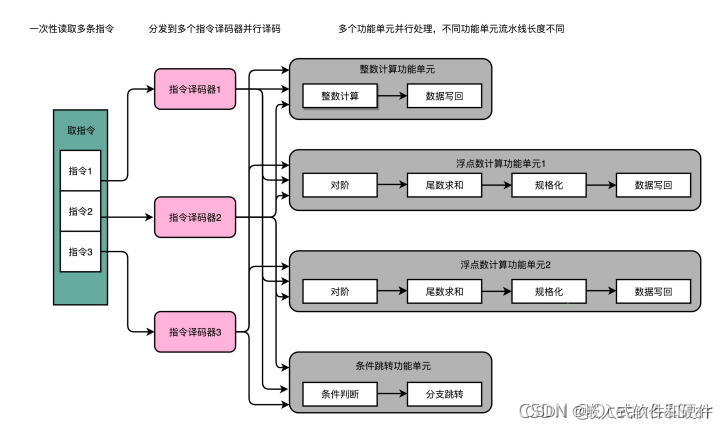


5级双发射流水线
两路PC,红色和黑色两条执行路径。

SMT流水线(参考本等HT超线程技术)
PC和GPR寄存器多出几套。



Cortex-A53/Cortex-A57的多发射:


加上与上面两个正交的概念预测执行,构成计算机体系结构中三个两两正交的概念


以上的体系结构没有概念上的冲突,都可以设计出来。
如何定义读内存和写内存?
int x, y, r1, r2;
#define barrier() __asm__ __volatile__("": : :"memory")
//thread 1
void run1(void)
{
x = 1;
barrier();
r1 = y;
}
//thread 2
void run2(void)
{
y = 1;
barrier();
r2 = x;
}编译为汇编指令
gcc -O3 -S main.c .file "main.c"
.text
.p2align 4,,15
.globl run1
.type run1, @function
run1:
.LFB0:
.cfi_startproc
movl $1, x(%rip)
movl y(%rip), %eax
movl %eax, r1(%rip)
ret
.cfi_endproc
.LFE0:
.size run1, .-run1
.p2align 4,,15
.globl run2
.type run2, @function
run2:
.LFB1:
. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











