







 本文探讨了AMD的HSA异构计算架构和AMD-KFD内核驱动,旨在打破CPU和GPU的界限,实现高效协同工作。HSA允许任何处理单元无缝访问数据,简化编程,提高系统性能。AMD的KFD驱动作为HSA的基础,已集成到Linux内核中,与DRM框架协同工作。同时,文章对比了AMD与NVIDIA的内核驱动策略,强调了AMD在开源方面的优势。
本文探讨了AMD的HSA异构计算架构和AMD-KFD内核驱动,旨在打破CPU和GPU的界限,实现高效协同工作。HSA允许任何处理单元无缝访问数据,简化编程,提高系统性能。AMD的KFD驱动作为HSA的基础,已集成到Linux内核中,与DRM框架协同工作。同时,文章对比了AMD与NVIDIA的内核驱动策略,强调了AMD在开源方面的优势。
当前的CPU和GPU是分立设计的处理器,不能高效率地协同工作,编写同时运行于CPU和GPU的程序也是相当麻烦。由于CPU和GPU拥有独立的地址空间,应用程序不得不明确地控制数据在CPU和GPU之间的流动。CPU代码通过系统调用向GPU发送任务,此类系统调用一般由GPU驱动程序管理,而驱动程序本身又受到其他调度程序管理。这么多的环节造成了很大的调用开销.
为了充分释放并行处理器的计算能力,架构设计者必须打破既有格局,采用新的思路。设计者必须重塑计算系统,把同一个平台上分立的处理单元紧密整合成为不断演进单颗处理器,同时无需软件开发者的编程方式发生重大的改变,这是HSA(Heterogeneous System Architecture)设计中的首要目标。
2012年6月份,AMD联合ARM、Imagination、联发科、德州仪器共同组建了非营利组织“异构系统架构基金会”(HSA Foundation),随后吸引了三星电子、高通以及大批行业公司、科研机构的加盟。
10年前这个消息公布之后,AMD还给业界画了一个大饼——未来是属于HSA异构运算的,十六年前54亿美元收购ATI公司也是为了CPU+GPU异构运算的大业,其中CPU负责通用运算及管理,GPU则依靠强大的浮点性能提供主要输出。
不过10年过去了,HSA并没有推出什么重要的产品,实际上这几年盟主AMD都不怎么提HSA异构的事了,尽管自家的APU产品还在推。
意大利网站bitchips日前表示AMD的HSA异构运算死了,要被埋葬了,CPU、GPU共处一个核心的APU也会停止了,未来将是CPU+GPU同一封装的天下(猜测可能是chiplets 芯粒基数,GPU和CPU封装在一起,但不是同一颗DIE).
APU是“Accelerated Processing Units”的简称,中文名字叫加速处理器,是AMD融聚未来理念的产品,它第一次将处理器和独显核心做在一个晶片上,协同计算、彼此加速,同时具有高性能处理器和最新支持DX11独立显卡的处理性能,大幅提升电脑运行效率,实现了CPU与GPU真正的融合。APU是处理器未来发展的趋势。

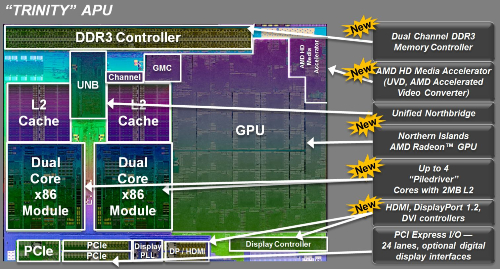
相比INTEL的酷睿系列集成显卡,APU的GPU所占面积要大很多,将近50%,毕竟集成进同一颗芯片的是独立显卡,并非是功能受限,阉割严重的核显。
从APU的发展来看,AMD在做的事情是让CPU和GPU彻底融为一体,无论是AMD的Llano,还是Brazos,目标都是一致的。AMD认为,CPU和GPU的融合将分为四步进行:第一步是物理整合过程(Physical Integration),将CPU和GPU集成在同一块硅芯片上,并利用高带宽的内部总线通讯,集成高性能的内存控制器,借助开放的软件系统促成异构计算。第二步称为平台优化(Optimized Platforms),CPU和GPU之间互连接口进一步增强,并且统一进行双向电源管理,GPU也支持高级编程语言。第三步是架构整合(Architectural Integration),实现统一的CPU/GPU寻址空间、GPU使用可分页系统内存、GPU硬件可调度、CPU/GPU/APU内存协同一致。第四步是架构和系统整合(Architectural & OS Integration),主要特点包括GPU计算上下文切换、GPU图形优先计算、独立显卡的PCI-E协同、任务并行运行实时整合等等。

全功能HSA的特点

HSA将CPU和GPU紧密结合在一起,释放强大,灵活的算力:

再看几个脑洞大开的HSA设计思路,除了hUMA一致性存储外,让人眼前一亮的还有CPU算力和GPU算力一视同仁,统一协调分配,GPU可以向CPU dispatch串行WORK,而CPU也可以向GPU发送并行WORK,将并行和串行算力的利用率发挥到极致。

CPU和GPU的交互更加灵活,甚至都可以在GPU kernel中调用CPU的回调函数,这样可以扩大GPU端kernel实现的粒度,不再需要将大KERNEL切分成小KERNEL,在小KERNEL中间执行CPU流程,增加GPU侧的throughput.

HSA Arch BLock:
异构系统架构(HSA,Heterogeneous System Architecture)用一句话来概括就是:一种智能计算架构,通过无缝地分配相应的任务至最适合的处理单元,使CPU、GPU和其他处理器和谐工作在单一芯片上。上一代APU虽然已经将CPU和GPU无缝融合在了一起,但并没有实现“分配相应的任务至最适合的处理单元”,这就是HSA架构的精髓,也是AMD未来APU想要努力实现的方向。


PS:根据这段描述,似乎可以得出结论,APU是 HSA发展过程中的一个阶段,两者关系用欧拉图表示可以表示成:

HSA系统的几大特性:
1. 任何处理单元的数据可以轻易地被其它处理单元所访问;
2. 异构计算不仅包括GPU,还包括其它专用处理单元或协处理器;
3. 编程人员不用知道程序在什么处理单元上运行;
4. GPU和其它处理单元无缝访问虚拟内存,解决数据搬迁瓶颈,数据无需复制。
在硬件层面,HSA架构当中的异构统一内存访问是一项关键技术。将CPU,GPU和内存全部封装为一体,大幅缩短了DDR内存行程,和CPU-GPU PCIe行程,从而大幅提高了性能和效率。这样做的优势还有很多,以多媒体解码应用为例,在基于PCIE GPU解码加速的卡上,为了缩短数据访问的行程,通常解码在GPU上进行,但是CPU上必须同时保留framebuffer和vbv的buffer,以便做数据缓冲和frambuffer的下一步处理(比如显示,后处理等等),如果CPU和GPU共享一个物理存储,两边访问行程一样,这样会节省两个buffer。
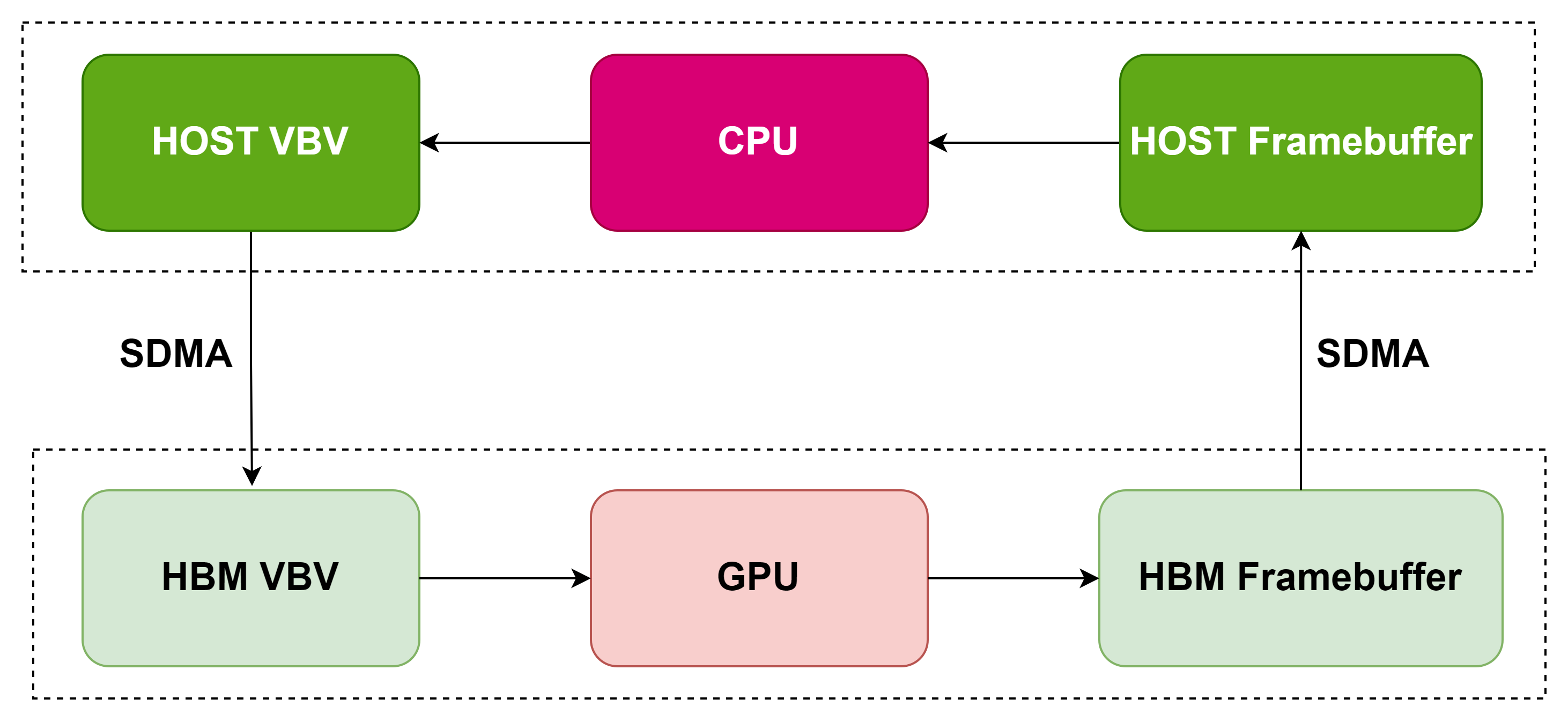
AMD在技术创新上相对int
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2111
2111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











