









参考ramfs实现一个Linux ramfs内核模块,作为Linux文件系统分析的一个脚手架。
Makefile:
ifneq ($(KERNELRELEASE),)
obj-m += zlramfs.o
else
KERNELDIR:=/lib/modules/$(shell uname -r)/build
PWD:=$(shell pwd)
all:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
rm -rf *.o *.mod.c *.mod.o *.ko *.symvers *.mod .*.cmd *.order *.a
endif源码文件zlramfs.c:
#include <linux/fs.h>
#include <linux/pagemap.h>
#include <linux/highmem.h>
#include <linux/time.h>
#include <linux/init.h>
#include <linux/string.h>
#include <linux/backing-dev.h>
#include <linux/sched.h>
#include <linux/parser.h>
#include <linux/magic.h>
#include <linux/slab.h>
#include <linux/uaccess.h>
#include <linux/fs_context.h>
#include <linux/fs_parser.h>
static unsigned long zlramfs_mmu_get_unmapped_area(struct file *file,
unsigned long addr, unsigned long len, unsigned long pgoff,
unsigned long flags)
{
return current->mm->get_unmapped_area(file, addr, len, pgoff, flags);
}
const struct file_operations zlramfs_file_operations = {
.read_iter = generic_file_read_iter,
.write_iter = generic_file_write_iter,
.mmap = generic_file_mmap,
.fsync = noop_fsync,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.llseek = generic_file_llseek,
.get_unmapped_area = zlramfs_mmu_get_unmapped_area,
};
const struct inode_operations zlramfs_file_inode_operations = {
.setattr = simple_setattr,
.getattr = simple_getattr,
};
struct zlramfs_mount_opts {
umode_t mode;
};
struct zlramfs_fs_info {
struct zlramfs_mount_opts mount_opts;
};
#define RAMFS_DEFAULT_MODE 0755
static const struct super_operations zlramfs_ops;
static const struct inode_operations zlramfs_dir_inode_operations;
struct inode *zlramfs_get_inode(struct super_block *sb,
const struct inode *dir, umode_t mode, dev_t dev)
{
struct inode * inode = new_inode(sb);
if (inode) {
inode->i_ino = get_next_ino();
inode_init_owner(&init_user_ns, inode, dir, mode);
inode->i_mapping->a_ops = &ram_aops;
mapping_set_gfp_mask(inode->i_mapping, GFP_HIGHUSER);
mapping_set_unevictable(inode->i_mapping);
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
switch (mode & S_IFMT) {
default:
init_special_inode(inode, mode, dev);
break;
case S_IFREG:
inode->i_op = &zlramfs_file_inode_operations;
inode->i_fop = &zlramfs_file_operations;
break;
case S_IFDIR:
inode->i_op = &zlramfs_dir_inode_operations;
inode->i_fop = &simple_dir_operations;
/* directory inodes start off with i_nlink == 2 (for "." entry) */
inc_nlink(inode);
break;
case S_IFLNK:
inode->i_op = &page_symlink_inode_operations;
inode_nohighmem(inode);
break;
}
}
return inode;
}
/*
* File creation. Allocate an inode, and we're done..
*/
/* SMP-safe */
static int
zlramfs_mknod(struct user_namespace *mnt_userns, struct inode *dir,
struct dentry *dentry, umode_t mode, dev_t dev)
{
struct inode * inode = zlramfs_get_inode(dir->i_sb, dir, mode, dev);
int error = -ENOSPC;
if (inode) {
d_instantiate(dentry, inode);
dget(dentry); /* Extra count - pin the dentry in core */
error = 0;
dir->i_mtime = dir->i_ctime = current_time(dir);
}
return error;
}
static int zlramfs_mkdir(struct user_namespace *mnt_userns, struct inode *dir,
struct dentry *dentry, umode_t mode)
{
int retval = zlramfs_mknod(&init_user_ns, dir, dentry, mode | S_IFDIR, 0);
if (!retval)
inc_nlink(dir);
return retval;
}
static int zlramfs_create(struct user_namespace *mnt_userns, struct inode *dir,
struct dentry *dentry, umode_t mode, bool excl)
{
return zlramfs_mknod(&init_user_ns, dir, dentry, mode | S_IFREG, 0);
}
static int zlramfs_symlink(struct user_namespace *mnt_userns, struct inode *dir,
struct dentry *dentry, const char *symname)
{
struct inode *inode;
int error = -ENOSPC;
inode = zlramfs_get_inode(dir->i_sb, dir, S_IFLNK|S_IRWXUGO, 0);
if (inode) {
int l = strlen(symname)+1;
error = page_symlink(inode, symname, l);
if (!error) {
d_instantiate(dentry, inode);
dget(dentry);
dir->i_mtime = dir->i_ctime = current_time(dir);
} else
iput(inode);
}
return error;
}
static int zlramfs_tmpfile(struct user_namespace *mnt_userns,
struct inode *dir, struct dentry *dentry, umode_t mode)
{
struct inode *inode;
inode = zlramfs_get_inode(dir->i_sb, dir, mode, 0);
if (!inode)
return -ENOSPC;
d_tmpfile(dentry, inode);
return 0;
}
static const struct inode_operations zlramfs_dir_inode_operations = {
.create = zlramfs_create,
.lookup = simple_lookup,
.link = simple_link,
.unlink = simple_unlink,
.symlink = zlramfs_symlink,
.mkdir = zlramfs_mkdir,
.rmdir = simple_rmdir,
.mknod = zlramfs_mknod,
.rename = simple_rename,
.tmpfile = zlramfs_tmpfile,
};
/*
* Display the mount options in /proc/mounts.
*/
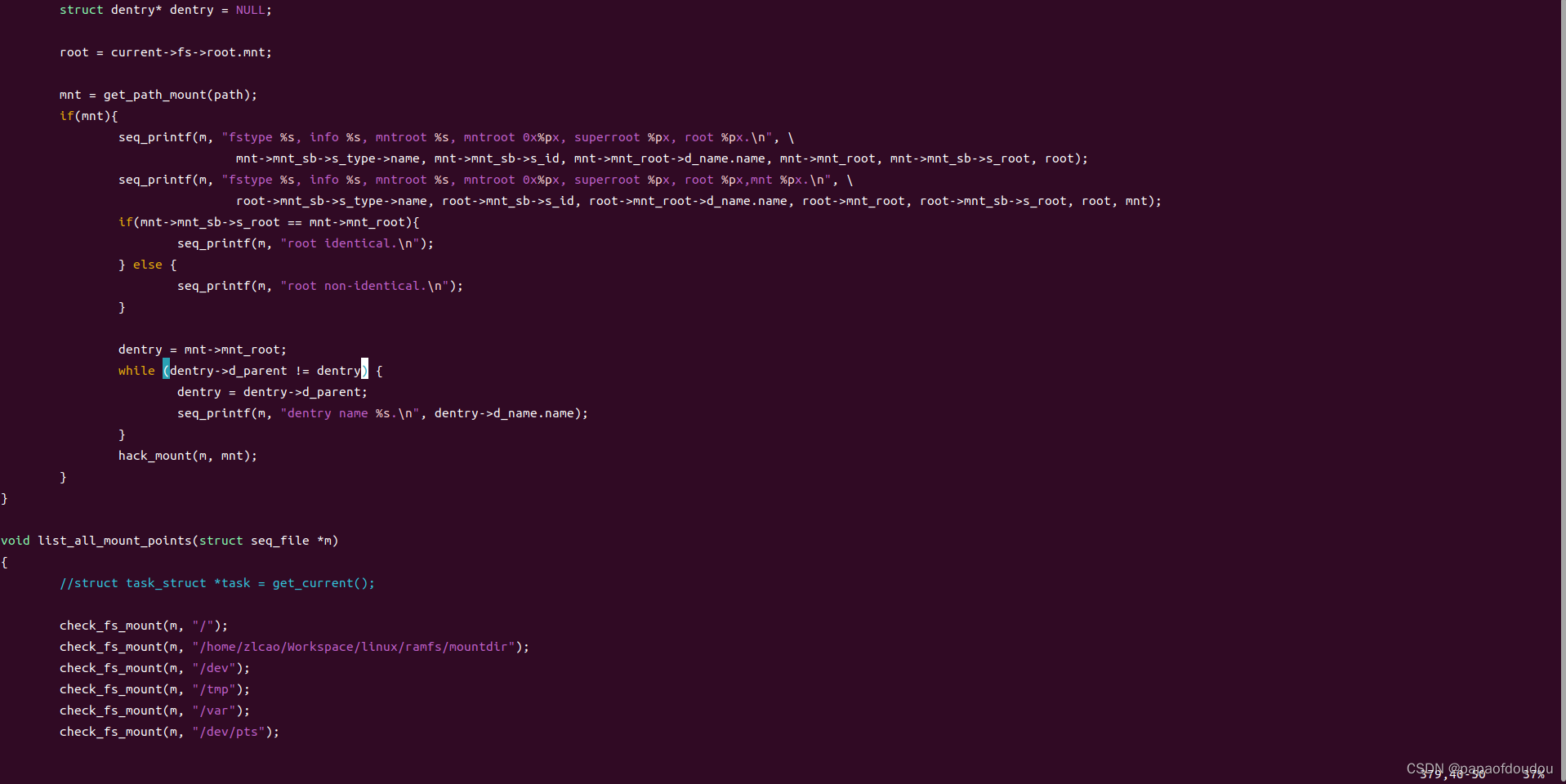
static int zlramfs_show_options(struct seq_file *m, struct dentry *root)
{
struct zlramfs_fs_info *fsi = root->d_sb->s_fs_info;
if (fsi->mount_opts.mode != RAMFS_DEFAULT_MODE)
seq_printf(m, ",mode=%o", fsi->mount_opts.mode);
return 0;
}
static const struct super_operations zlramfs_ops = {
.statfs = simple_statfs,
.drop_inode = generic_delete_inode,
.show_options = zlramfs_show_options,
};
enum zlramfs_param {
Opt_mode,
};
const struct fs_parameter_spec zlramfs_fs_parameters[] = {
fsparam_u32oct("mode", Opt_mode),
{}
};
static int zlramfs_parse_param(struct fs_context *fc, struct fs_parameter *param)
{
struct fs_parse_result result;
struct zlramfs_fs_info *fsi = fc->s_fs_info;
int opt;
opt = fs_parse(fc, zlramfs_fs_parameters, param, &result);
if (opt < 0) {
/*
* We might like to report bad mount options here;
* but traditionally zlramfs has ignored all mount options,
* and as it is used as a !CONFIG_SHMEM simple substitute
* for tmpfs, better continue to ignore other mount options.
*/
if (opt == -ENOPARAM)
opt = 0;
return opt;
}
switch (opt) {
case Opt_mode:
fsi->mount_opts.mode = result.uint_32 & S_IALLUGO;
break;
}
return 0;
}
static int zlramfs_fill_super(struct super_block *sb, struct fs_context *fc)
{
struct zlramfs_fs_info *fsi = sb->s_fs_info;
struct inode *inode;
sb->s_maxbytes = MAX_LFS_FILESIZE;
sb->s_blocksize = PAGE_SIZE;
sb->s_blocksize_bits = PAGE_SHIFT;
sb->s_magic = RAMFS_MAGIC;
sb->s_op = &zlramfs_ops;
sb->s_time_gran = 1;
inode = zlramfs_get_inode(sb, NULL, S_IFDIR | fsi->mount_opts.mode, 0);
sb->s_root = d_make_root(inode);
if (!sb->s_root)
return -ENOMEM;
return 0;
}
static int zlramfs_get_tree(struct fs_context *fc)
{
return get_tree_nodev(fc, zlramfs_fill_super);
}
static void zlramfs_free_fc(struct fs_context *fc)
{
kfree(fc->s_fs_info);
}
static const struct fs_context_operations zlramfs_context_ops = {
.free = zlramfs_free_fc,
.parse_param = zlramfs_parse_param,
.get_tree = zlramfs_get_tree,
};
int zlramfs_init_fs_context(struct fs_context *fc)
{
struct zlramfs_fs_info *fsi;
fsi = kzalloc(sizeof(*fsi), GFP_KERNEL);
if (!fsi)
return -ENOMEM;
fsi->mount_opts.mode = RAMFS_DEFAULT_MODE;
fc->s_fs_info = fsi;
fc->ops = &zlramfs_context_ops;
return 0;
}
static void zlramfs_kill_sb(struct super_block *sb)
{
kfree(sb->s_fs_info);
kill_litter_super(sb);
}
static struct file_system_type zlramfs_fs_type = {
.name = "zlramfs",
.init_fs_context = zlramfs_init_fs_context,
.parameters = zlramfs_fs_parameters,
.kill_sb = zlramfs_kill_sb,
.fs_flags = FS_USERNS_MOUNT,
};
static int init_zlramfs_fs(void)
{
return register_filesystem(&zlramfs_fs_type);
}
static void deinit_zlramfs_fs(void)
{
unregister_filesystem(&zlramfs_fs_type);
return;
}
module_init(init_zlramfs_fs);
module_exit(deinit_zlramfs_fs);
MODULE_AUTHOR("zlcao");
MODULE_LICENSE("GPL");编译:

加载:

/proc/filesystems查看文件系统注册信息:

挂载文件系统:
$ mkdir testmount
$ sudo mount -t zlramfs zlramfs ./testmount/

查看挂载结果:
cat /proc/mounts |tail -6
zlramfs的后端设备为NONE,说明这个文件系统不需要后端磁盘作为介质。

调试:
在创建node的地方添加打印,创建目录和创建文件会经过这里:


dmesg信息:

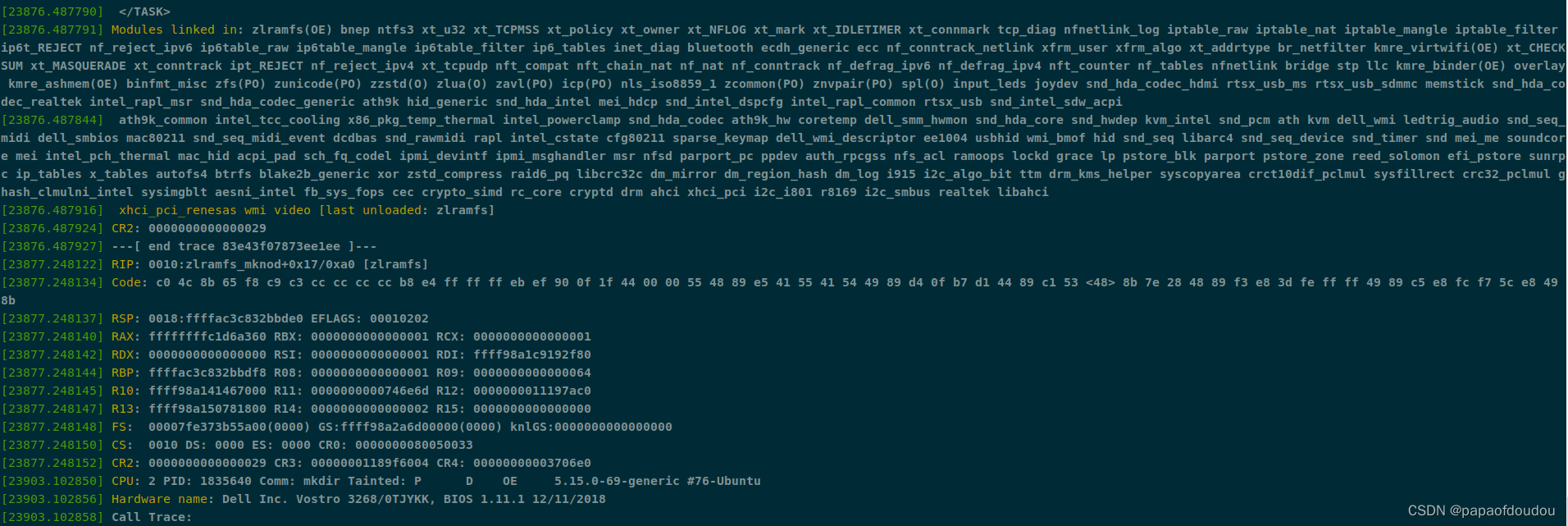
lsmount输出
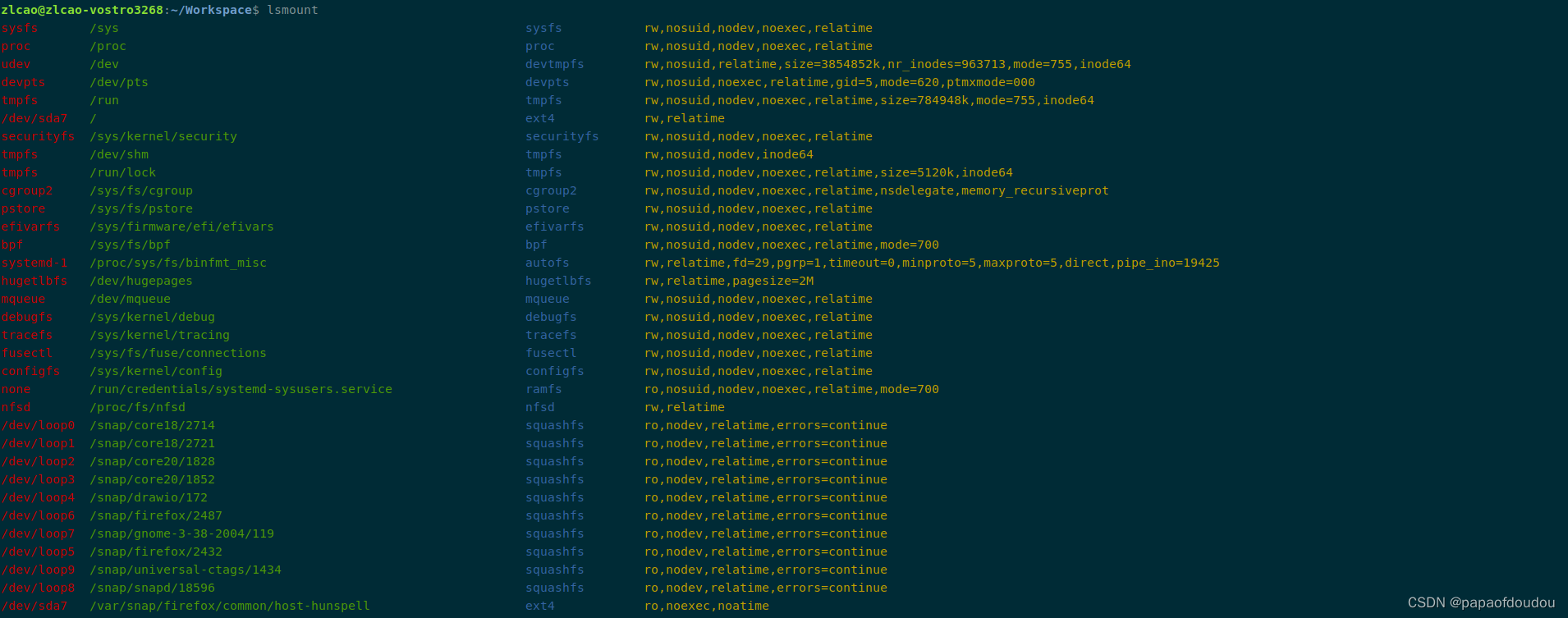

lsmount命令也是从/proc/mounts节点获取信息的,以下是strace的输出:

zlramfs挂载图
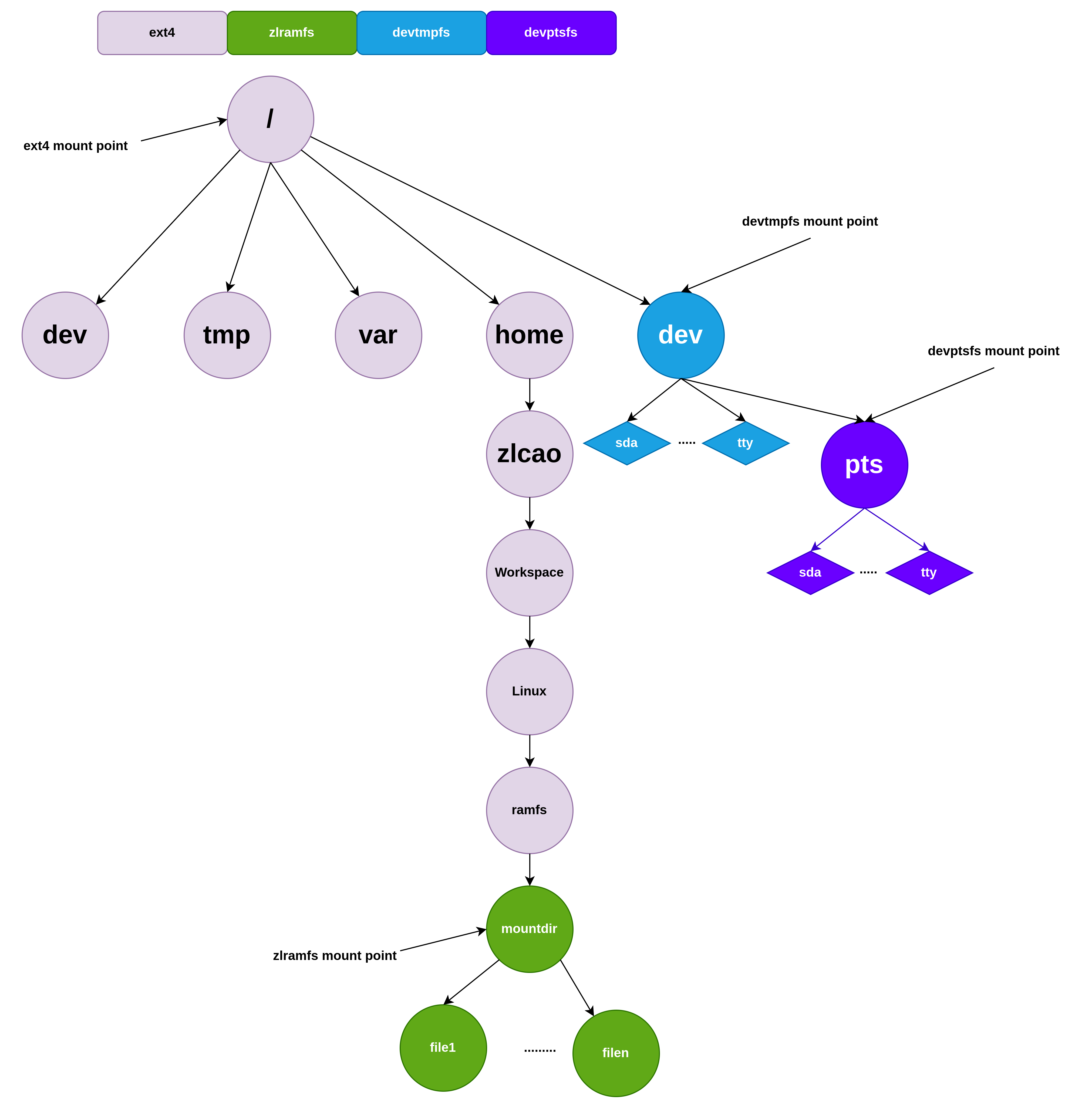
Ramfs
以上代码参考内核RAMFS的实现,代码路径在fs/ramfs,当MMU打开时,编译file-mmu.c,忽略掉file-nommu.c(注意是赋值语句,而非累加,所以MMU打开情况下忽略前面的赋值)。

ramfs编译文件包括file-mmu.c/inode.c。

struct dentry的引用计数
struct dentry的生命期由引用计数控制,引用计数在分配到时候初始化为1:

通过dget/dput增加/减少引用。


经过调试,发现内核对struct dentry的管理符合如下规律:
1.struct dentry 有被引用(引用计数大于0,就不会被销毁).
2.struct dentry引用计数被初始化为1,代表当前目录"."对其的引用。
3.每一个子目录都会递增父目录的引用计数。
4.如果应用将目录作为当前工作目录,会递增目录的引用计数,离开目录后(无论去上级还是下一级目录),引用计数将会减1。
5.引用计数只会被子目录递增(包括表示当前目录的.),不会被孙目录隔代递增。
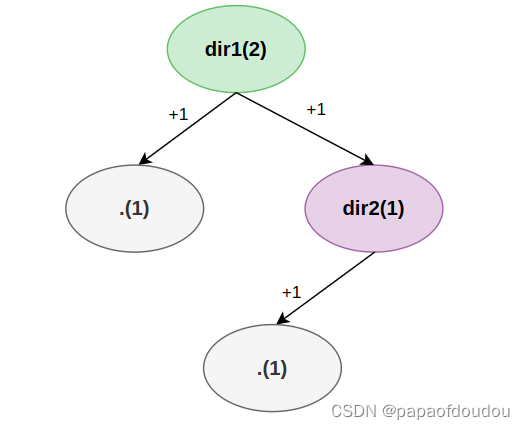
如下的目录等级:

在没有控制台将此目录树中的目录作为工作目录时,dir1引用计数为2,dir2引用计数为5。


当删除dir2下所有子目录,dir1不变,dir2的引用计数变为1:

参考资料
Linux系统的各个mount点以及文件系统挂载分析_linux挂载点_papaofdoudou的博客-CSDN博客

















 8082
8082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











