







分类常用的指标
Accuracy , Precision , Recall , F1,ROC,P-R,AUC
Confusion Matrix (混淆矩阵)
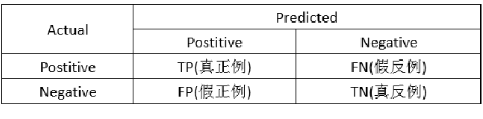
首先明白表格中出现的概念:
1.正确肯定(True Positive,TP):预测为真,实际为真
2.正确否定(True Negative,TN):预测为假,实际为假
3.错误肯定(False Positive,FP):预测为真,实际为假
4.错误否定(False Negative,FN):预测为假,实际为真
查准率(Precision)和查全率(Recall)
查准率(precision):指被分类器判定正例中的正样本的比重指被分类器判定正例中的正样本的比重
查全率(recall): 指的是被预测为正例的占总的正例的比重
Precision(P)= TP / (TP+FP)
Recall ( R) = TP / (TP+FN)
F1-score
F1-SCOR = (2PR) /( P+R)
Accuracy
Accuracy (ACC ) = (TP+TN) / (TP+FN+FP+TN)
python调库实现
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix,f1_score,precision_score,recall_score
from sklearn.tree import DecisionTreeClassifier
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=22)
clf2 = DecisionTreeClassifier(criterion='entropy') //决策树算法
clf2.fit(X_train, y_train)
y_pred = clf2.predict(X_test) //获得预测标签
c=confusion_matrix(y_test, y_pred) //混淆矩阵
f1=f1_score(y_test, y_pred,average='macro') //多分类求f1值
ps=precision_score(y_test, y_pred,average='macro') //多分类求precision
rs=recall_score(y_test, y_pred,average='macro') //多分类求recall















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









