









在互联网应用中,了解用户的行为对产品的优化和公司的战略至关重要,市面上主要涵盖这三种埋点方式,分别是全埋点、可视化埋点和代码埋点,各有优缺点,一般有实力的企业都会选择代码埋点,更加灵活而且能获取到更加丰富的信息。
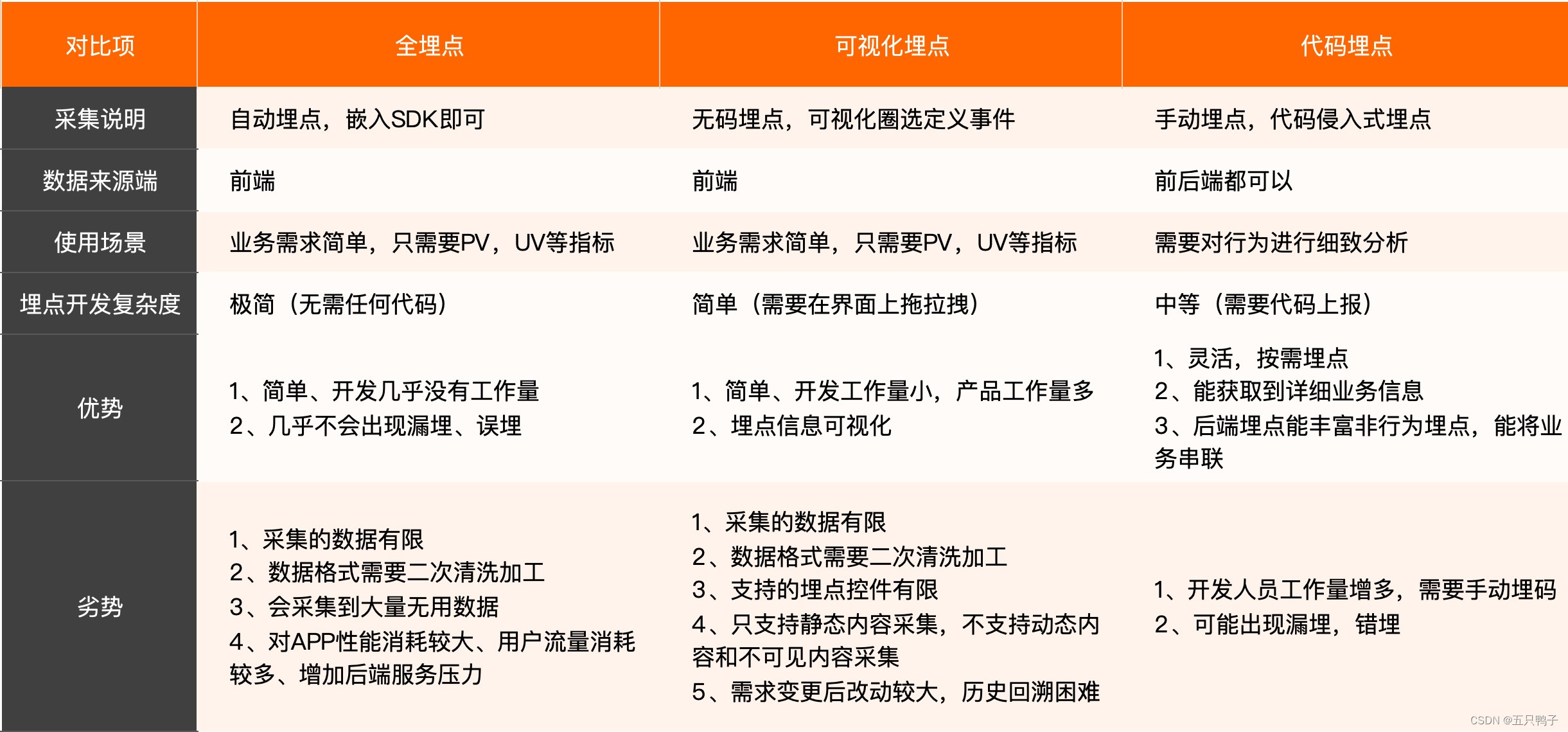
图1 :三种埋点方式的对比
我们详细讨论下代码埋点的架构和基本概念
架构设计
对于一般性企业来说,埋点采集系统通常不会自研,而是采用第三方的埋点产品,因为埋点产品的自研成本相对较高,需要适配不同的客户端。采用第三方专业的埋点产品性价比更高。
a) 整体架构
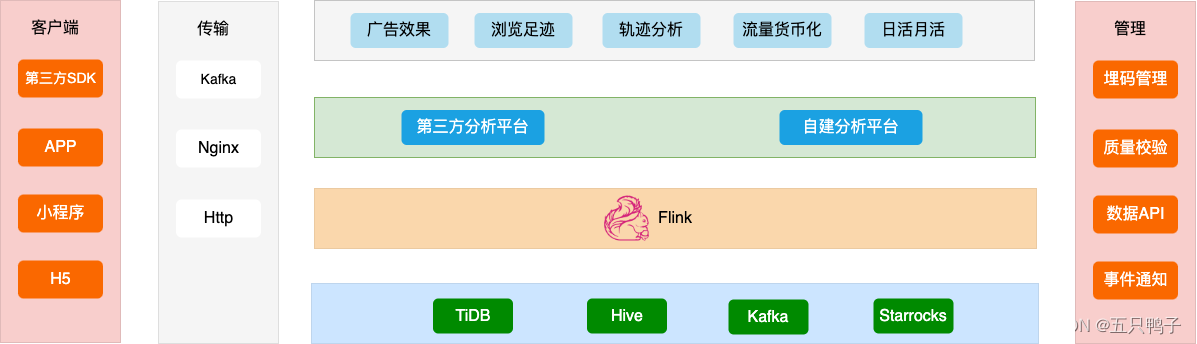
图2 - 埋点采集整体架构图
b) 数据流转过程
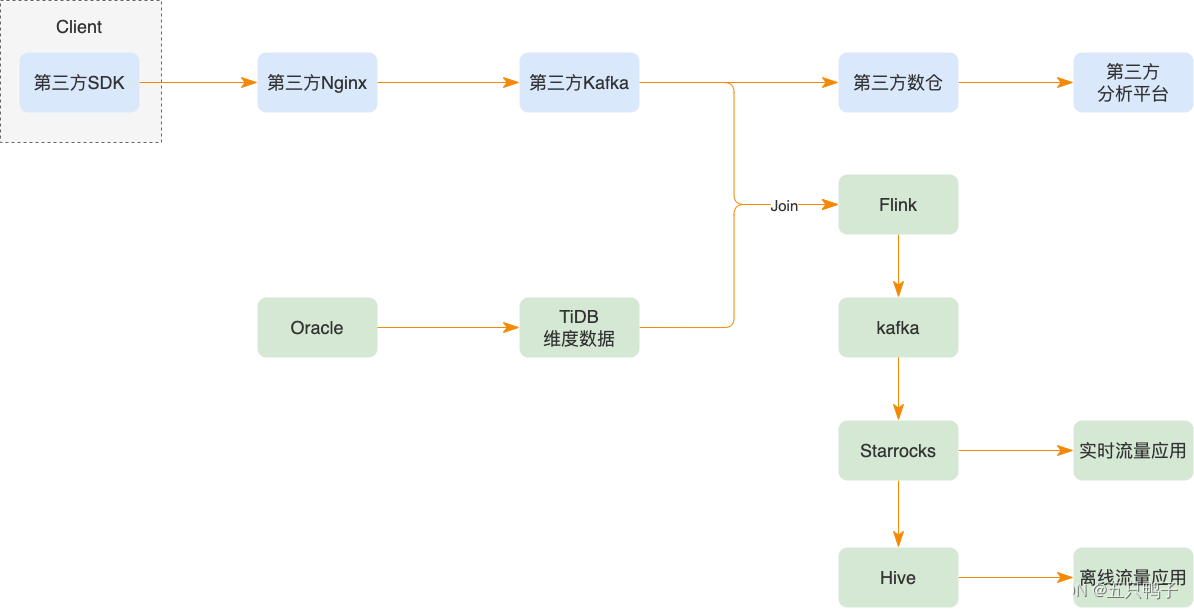
图3 - 埋点数据流转过程
数据模型
a) Event模型
Event模型是埋点建设中最为核心的模型,描述了谁在什么时间,什么地方以什么样的方式做了一件什么样的事情。比如张三在2023-01-22 09:30:21在京东iOS端点击了商品ID为12345的“收藏”按钮。
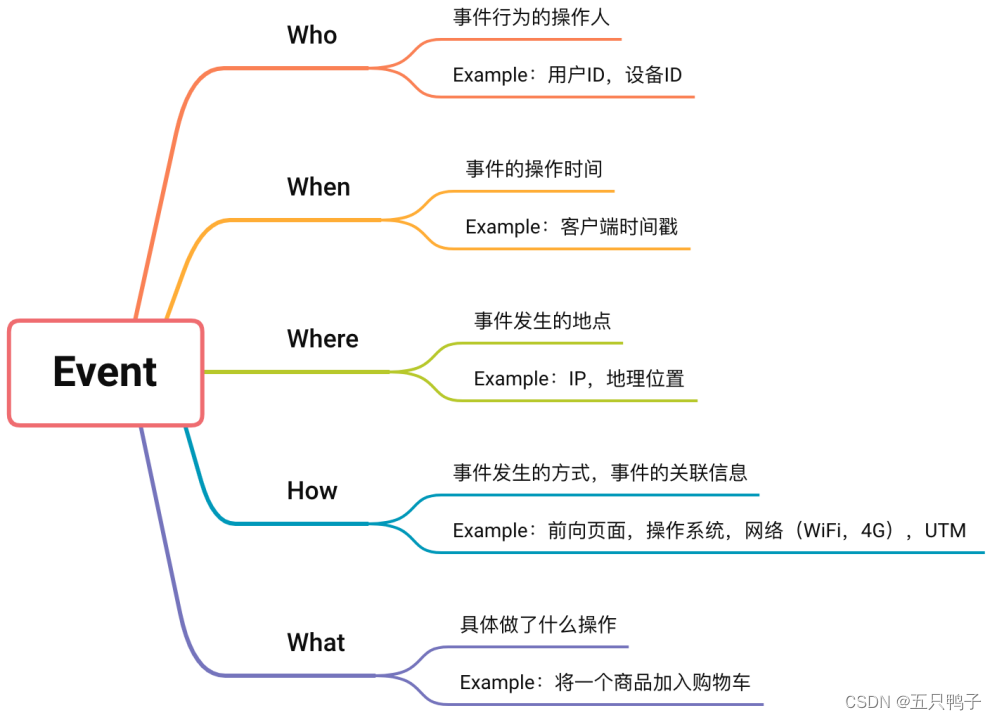 图4 - Event模型
图4 - Event模型
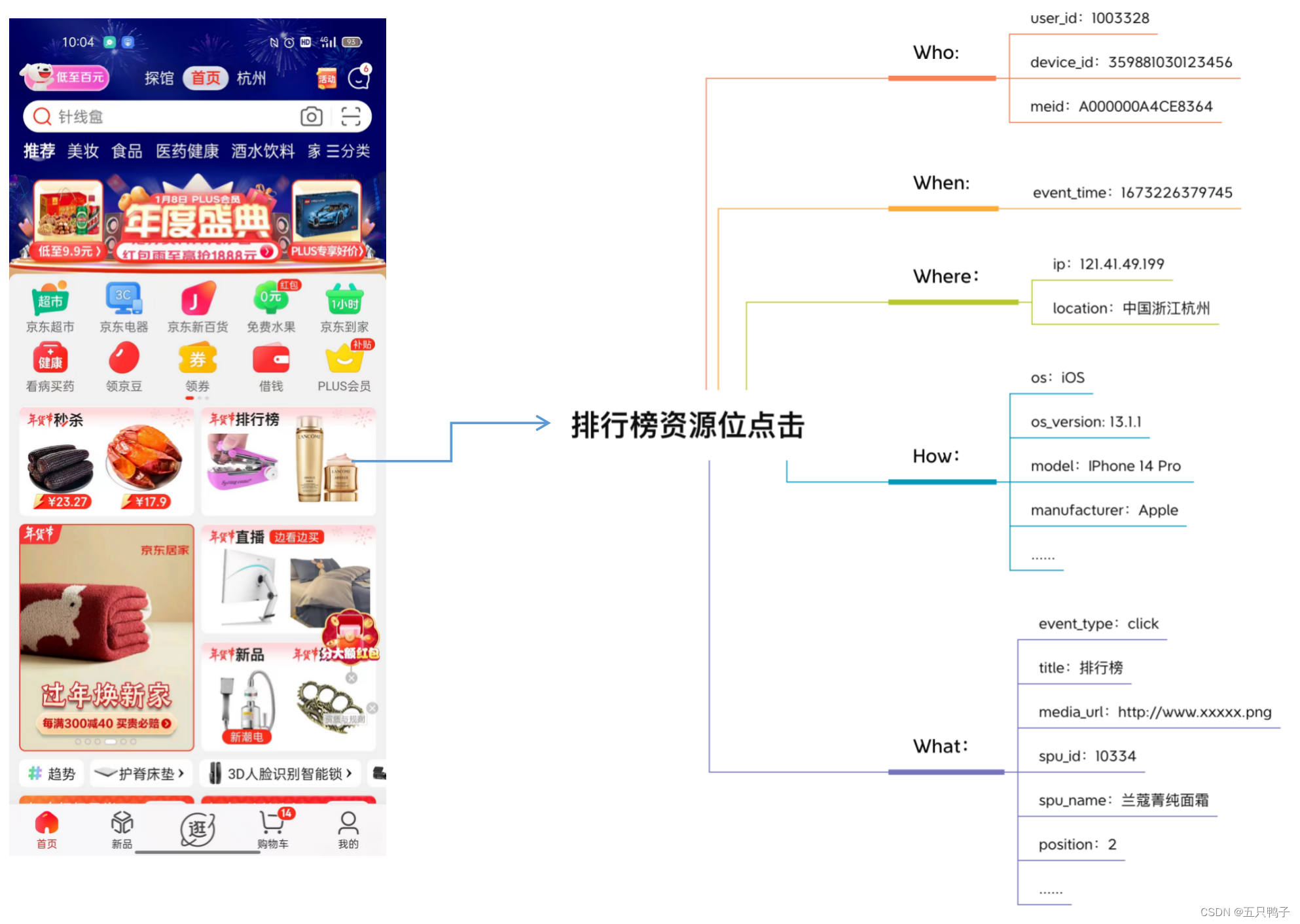
图4 - Event模型示例
b) User模型
User模型描述了一个立体的用户,每个用户有各种属性,例如:年龄、性别、地区、注册时间、VIP等级、用户价值等。
c) Item模型
Item模型作为Event事件的维度补充模型,可以简单理解为Event的维表,比如一些商品,网点等基础维度信息
Event事件设计原则
a) 埋点基本原则
Event的个数不宜偏多,同一个类别的事件可以合并为一个,不能具体到每个元素的点击都是一个不同的事件。
在设计埋点的时候需要抽象事件行为,将相似的事件抽象为一个事件,用不同的属性值来区分每个具体的事件。
相似事件可以按以下三个维度抽象:
1. 业务BU
2. 功能:比如登录、搜索、扫描、操作 等
3. 展现形式:比如banner轮播、弹窗、开屏广告等
基于以上原则,整体上事件量应该控制在一定范围内,例如1000个以内
具体的埋点属性设计方案参考另一篇文章:埋点事件属性设计方案
















 7824
7824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











