







自然母亲并没有选择我们思考抽象问题的能力,她选择的是我们适应环境的能力。这样的话,大脑进行的贝叶斯推断其实是对感官接收到的信息进行的无意识处理,尤其是因为对这些数据的处理可能关乎我们在自然界中的生存或者对社会环境的理解。
“人类大脑依靠的是演化而来的古老能力。我们继承的那些能力和直觉在过去和现在对我们这个物种的生存都至关重要。因此,所有婴儿生来就具有某种空间概念和数字概念,而在人类这个物种的情况中,还有专门用于语言的回路。”
斯坦尼斯拉斯·德阿纳详细解释道,“显然,教育尝试超越这些知识。教育让我们拥有新的技能,比如阅读、写作、符号化和形式化的算术,这都是演化没有预见到的。但我们会循环利用(……)那些古老的大脑系统来获取文化上的新技能。”
这样的循环利用可能有缺陷,并且违反概率法则。然而,那些通常处于无意识中的已有认知过程及其实际应用似乎惊人地吻合贝叶斯主义的计算。
来源 | 《贝叶斯的博弈:数学、思维与人工智能》
作者 | 黄黎原(Lê Nguyên Hoang)
译者 | 方弦
山峰还是山谷?
请你打开一幅地形图,也就是一幅记录了地形的地图。你可以在智能手机上打开地图,然后在选项中激活“地形”模式。放大某串山峦或者山谷,比如沙莫尼(Chamonix)山谷。现在将地图倒过来看,如果你用的是手机,那就把手机倒过来,但是不要把图像本身也倒过来。你应该会立刻注意到某种奇怪的现象(图 19.1)……

图 19.1 上面的两幅图是完全一样的,其中一幅上下颠倒了。图中表示的到底是山峰还是山谷?
你应该会觉得山峰好像变成了山谷,而山谷则变成了山峰!特别是在地图上,阴影区域的上面似乎就像是山峰,而山谷就处于阴影区域下面。
但这种感知从何而来?是什么让我们能够区分地图上的山谷和山峰?
与许多无意识的感知一样,我们得出的结论其实来自贝叶斯式的计算。在这个例子中,我们对地图的解释用到的那个不可或缺的偏见就是照明的来源。这是因为,地图中的阴影产生于来自地图上方的照明,即使这种照明在欧洲和美国等北半球地区在物理上是不可能发生的,因为太阳总会从南面照射过来 !
虽然这个偏见在地图的情况中并不正确,但在日常生活中却完全有根有据。无论是阳光还是电灯,照明一般来自上方。所以,当我们观察别人的面孔时,我们一般会看到鼻子处于一片阴影的上面,而眼睛则相反,处于一片阴影的下面。此外,反方向的照明会看起来很惊悚,这也解释了为什么恐怖电影中经常用到从下至上的照明。
一般来说,我们的视皮层拥有出色的无意识能力,可以猜出图像中照明的来源,为的是之后能更好地解释图像中的内容。因此,这个过程与之前提到的贝叶斯网络和玻尔兹曼机非常相似,我们的大脑似乎会立刻利用隐藏变量来理解观察到的变量。
视错觉
关于照明的偏见会让我们对一幅上下颠倒的地图做出错误解释,在我们分析自然世界的大量图像时,这种偏见的效率高得可怕。然而,如果构筑图像的规则在自然界中很不常见的话,这些偏见也会将我们引向歧途。
请你拿两支相同的笔,然后把其中一支横放,把另一支竖直放在前一支上面,构成数学家用来表示垂直的符号“⊥”。现在看看这两支笔,你应该会觉得竖着的那支笔要比横着的更长,但根据这个图形的构造,这两支笔的长度其实是一样的!
这种视错觉同样可以利用我们的贝叶斯大脑中有凭有据的偏见做出完美的解释。我们的大脑习惯于观看符合透视原则的图像,其中看到的竖线通常对应着透视中的水平线——铁路的铁轨就是一种典型的情况。然而,在透视的情况下,这些直线会被压缩,看起来要比实际上更短。我们的贝叶斯大脑因此会在无意识中将这种关于透视的正确偏见纳入考虑。这就会导致大脑推断出竖线要比看起来更长。可能就是出于这个原因,我们会本能地误认为自己摆出的垂直符号⊥中的竖线要比横线更长(图 19.2 左图)。
其他视错觉也用到了这种透视效应,一个经典例子就是同一个人像被复制粘贴到前后两个不同的透视平面上(图 19.2 中图)。我们会觉得处于后面的透视平面上的人像更大,那是因为我们的贝叶斯大脑在无意识中应用了贝叶斯公式(的一个近似),以此推断出后面的透视平面上的人像很有可能比看上去更大。这个视错觉可以通过贝叶斯推断来解释。
另一个经典视错觉与此类似,那是其中一部分有阴影的国际象棋盘(图 19.2 右图)。阴影中的白色格子看起来比照明之下的黑色格子颜色更浅,但实际上并不是这样的。虽然如此,我们的贝叶斯大脑在无意识中进行的贝叶斯推断也会考虑照明的效应,由此得到“有用”的结论,也就是被照亮的黑色格子的颜色比阴影中的白色格子更深。
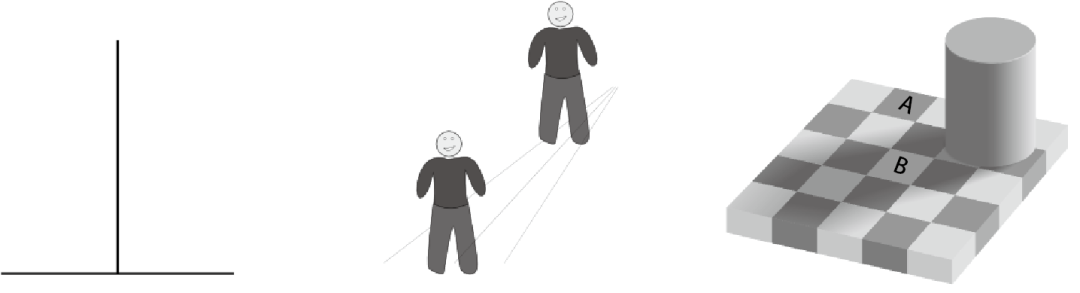
图 19.2 几个经典的视错觉。左图中两条线段的长度相同,中图中的两个小人大小相同,右图中的格子 A 和 B 的亮度相同
运动的感知
取一个非常扁的菱形,然后将它倾斜,使其最长的对称轴基本上沿着从右上到左下的对角线,再将这个菱形从左移到右。如果菱形与背景之间的对比度很高(一般会用黑色菱形和白色背景),那么我们就会清楚地看到菱形从左移到右。然而奇怪的是,如果将对比度降低(比如浅灰色菱形和白色背景),有些神奇的事情就会发生。很多人会看到菱形似乎在往右下方移动。我自己在 Twitter 上重复了这个实验,根据我发起的统计调查,回答问卷的 376 个人中的 39% 说看到菱形似乎也有点向下方移动了!
我们睿智的贝叶斯大脑是怎么得出这种错误结论的?在一篇出色的论文之中 ,魏斯、西蒙切利和阿德尔森证明了这个错误的结论正是贝叶斯大脑在计算中整合了弱对比度导致的不确定性之后理应得出的结论。
但在介绍这三位作者的贝叶斯式解释之前,我们先来看一项大脑经常被低估的惊人能力:当与背景颜色对比度高的菱形移动的时候,我们能够确定它的运动。这真是项非凡的成就!毕竟从感官的角度来看,我们看到的所有东西都只是或明或灭的像素。视频中像素亮度的改变是怎么被翻译为视频中物体的运动的呢?
我们之前看到,我们的大脑皮层首先能够做到的就是检测出图像中的线条。这样的话,当菱形移动时,大脑明显会看到菱形的边在移动。但菱形的每条边都是倾斜的,所以,当菱形从左往右移动时,菱形的边却似乎在往另一个方向移动。实际上,所有移动中的线段都像是在以垂直于直线的方向往右边移动。对于无限长的直线来说,这样的移动其实无法与任何往右的平移区分。
虽然如此,作为优秀的贝叶斯“计算器”,我们的大脑知道,直线以垂直于直线的方向往右移动只不过是直线往右移动的其中一种可能的解释。虽然在先验上这也许是最有可能的移动方式,但其他移动方式的概率并不为 0。根据魏斯、西蒙切利和阿德尔森的说法,大脑会结合菱形所有边可能的运动,并且假设菱形本身只沿一个方向移动。也就是说,在给定不同边可能的移动方式的情况下,大脑会计算出菱形在后验中最有可能的移动方式。正是这种方法让大脑能够从边的移动推断出菱形本身的运动——即使这些边的移动并不确定!
这就解释了为什么大脑能在对比度足够高的情况下做出正确的推断。那么在对比度低的情况下又怎么样呢?在这种情况下,大脑难以辨识线条的运动,这些线条移动的速度对它而言有某种不确定性(还要加上对于线条运动方向的不确定性)。令人惊奇的是,这种额外的不确定性会导致贝叶斯式计算产生差异。当不确定性足够大的时候,贝叶斯推断得出的结论就会更倾向菱形往右下方移动这个假设,也就是说这种移动方式是最大的后验估计。
真是难以置信!大脑的错误预测可以解释为大脑的贝叶斯计算中因引入对比度下降带来的额外不确定性而得到的结果!这种预测是错误的,但这种错误有它的理由,因为这就是贝叶斯大脑在面对不确定性时最好的处理方法!
虽然我们为这个实验选定的条件非常不自然,目的就是欺骗我们的贝叶斯大脑,但在实践中,贝叶斯式的预测通常可能更为贴切!
贝叶斯抽样
认知科学中最令我印象深刻的现象之一,就是人类大脑进行有代表性的抽样的能力。我们之前也谈到过,抽样方法对于概率性现象的描述通常相当有效,尤其是当相关的概率分布难以利用数学语言来描述时。然而,在实践中,绝大部分概率分布本身难以描述,也难以直接处理。
我们的贝叶斯大脑似乎理解了这一点。与其像纯粹贝叶斯主义者那样同时利用多个互不相容的理论来得出结论,大脑更倾向于顺次思考,首先考虑非常可信的模型,如果还有时间的话,然后再考虑其他可信模型。
一般来说,人们会以这种方式来尝试解释那些模棱两可的图像。你以前可能也见过这幅模棱两可的图像,它从某个角度看像鸭子,但从另一个角度看却像兔子(图 19.3)。最奇怪的是,我们似乎不可能同时看到这幅图像的两种解释方式。我们的贝叶斯大脑似乎一次只能观察到其中一种解释!
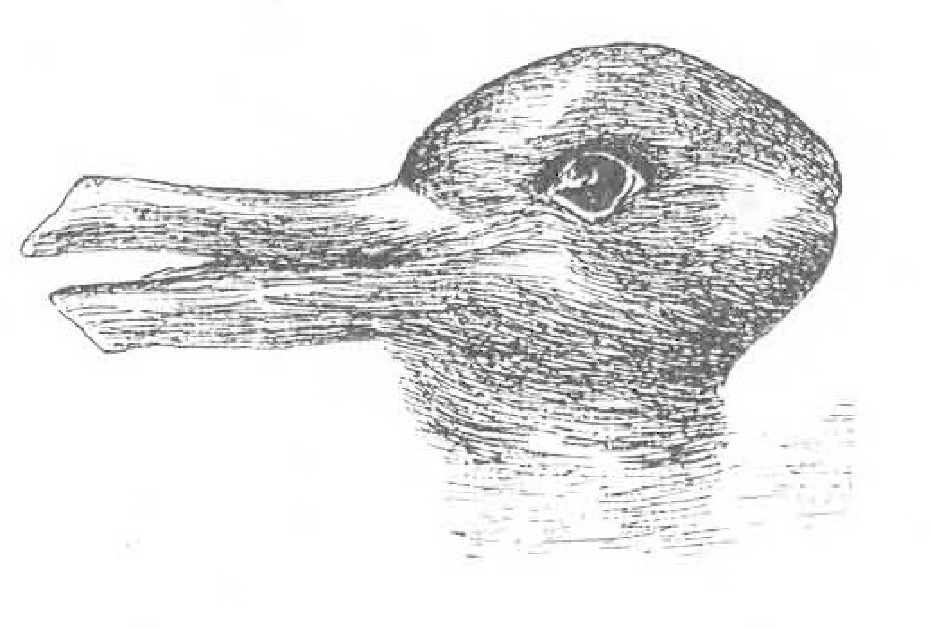
图 19.3 鸭还是兔?
在 2011 年,莫雷诺–博特、尼尔和普热研究了这一现象。他们让被试观看两个黑色网格在白色背景上相对移动的情景,然后询问被试哪一个网格在上。被试在两种可能的解释之间摇摆不定。贝叶斯大脑假设指出,在这种情况下,被试采用某种解释的时间比例就是被试对于这一解释的贝叶斯置信度。
为了测试这一假设,这三位研究者的天才想法就是先研究两个不同的变量对于被试在不同解释上花费的时间有什么影响,然后验证两个变量的叠加影响正是各自影响的乘积。他们研究的这两个变量就是其中一个网格的直线密度与相对速度。令人吃惊的是,将贝叶斯大脑假设所预言的效应相乘之后,正好完美符合两种效应的实际叠加效果!贝叶斯大脑进行的抽样似乎恰好遵循概率法则!更神奇的是,王公发(音译)和汪小京确定了可能与此相关的神经机制,可以具体解释神经元进行这类贝叶斯抽样的能力!
这一结论有个奇怪的推论:如果利用各种不同解释来进行多次预测的话,那么我们就能得到更好的预测结果。你可能还记得,纯粹贝叶斯主义者会通过取不同可信模型的预测的加权平均来优化自己的预测。为了测试贝叶斯大脑利用 MCMC 进行预测这一假设的推论,武尔和帕什勒 向 428 位被试提出了下面的问题:“全世界的机场有百分之几位于美国?”他们要求被试给出两个答案。第二个答案通常比第一个答案更不准确,但令人惊异的是,尽管如此,这两个答案的平均值却明显比其中较准确的那个答案更准确!
更妙的是,对于其中一半被试,武尔和帕什勒等了三个星期才让他们给出第二个答案,这让被试在第二次回答之前有机会真正改变对问题的诠释。猜猜发生了什么?这时,答案的平均值变得比紧接着第一次回答给出第二个答案的情况更准确了。德阿纳这样总结道:“将同一个问题问上两遍也不错。”
归纳问题
2011 年,乔希·特南鲍姆和三位合作者在英语中引入了一个新的词——“tufa”。为了解释这个概念是什么,特南鲍姆给出了 3 张“tufa”的例图。我们之中的那些纯粹主义者自然会说,这种定义新概念的方法真的非常糟糕。
尽管如此,这四位研究者观察到,在只有 3 个“tufa”的例子,而且没有任何不是“tufa”的范例的情况下,我们仍然能够基本上对“tufa”到底是什么达成一致。实际上,特南鲍姆之后给出了 39 张图片,对大家来说,其中 6 张图片似乎显然就是“tufa”,而其余的图像都不是“tufa”!实在难以置信!
这种惊人的现象有时候也被称为归纳问题。它当然远远达不到 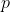 值以及费希尔的各种方法的标准,然而,据特南鲍姆及其合作者所说,这种现象可以完美地用贝叶斯原则来解释,只需要从“‘tufa’的 3 个例子对‘tufa’具有代表性”这一偏见出发,然后假设与这些例子不够相似的例子就不是“tufa”,这样就解释得通了。更妙的是,通过例子学习似乎正是我们学习词汇意义的真正方式。我们从来没听过“猫”的形式定义,只是看过类似的形状,然后父母告诉我们,大家把它们叫作“猫”。
值以及费希尔的各种方法的标准,然而,据特南鲍姆及其合作者所说,这种现象可以完美地用贝叶斯原则来解释,只需要从“‘tufa’的 3 个例子对‘tufa’具有代表性”这一偏见出发,然后假设与这些例子不够相似的例子就不是“tufa”,这样就解释得通了。更妙的是,通过例子学习似乎正是我们学习词汇意义的真正方式。我们从来没听过“猫”的形式定义,只是看过类似的形状,然后父母告诉我们,大家把它们叫作“猫”。
归纳问题的一个简单但有说服力的解释,就是从先验上假设所有事物组成的集合构成了树的结构,就像生命演化树那样。这样的话,当且仅当某个定义与树的结构相容,也就是它必须对应于树的一个结点时,它是可以接受的。这也是系统发生学所用的方法,这门学科会将哺乳动物等物种类群定义为拥有某个共同祖先的所有派生物种。所有可能的定义也就组成了演化树上所有结点的集合。
我们知道,“tufa”必定是这棵树上的一个结点,接下来要做的就是确定它到底是哪个结点。特南鲍姆与合作者提出可以研究简化的情况,其中所有结点的先验概率都相同。那么 MAP 模型就是似然度最大的模型,也就是使得特南鲍姆的 3 个例子属于“tufa”的概率最大的定义。通过非常简单的计算就能看出,那就是包含所有例子但又最远离树根的那个结点。
特南鲍姆及其合作者提出,正是借助类似的计算,我们仅仅通过 3 个例子就能对“tufa”一词的意义达成共识。他们还推测,在更普遍的情况中,婴儿也是这样学会语言中的词汇的。
学习如何学习
但这个解释似乎相当不完善。人们也许会问,大脑是如何确定那棵对所有事物分类的树的?此外,树这个结构从何而来?特南鲍姆与合作者的回答令人着迷:对树结构的必要性的学习,以及对事物分类的树结构的学习,似乎都是层次贝叶斯计算的推论。也就是说,大脑似乎进行的是层次贝叶斯计算。
要理解这一点,请想象一下又圆又重的物体 A、又圆又非常重的物体 B、非常圆但只是一般重的物体 C,然后有人跟你说,物体 A 用来烹调“tufa”正合适。你能够将这个结论推广到物体 B 和物体 C 上吗?而如果你手头上只有物体 B 和物体 C,你应该用哪一个物体来烹调“tufa”呢?
要回答这个问题,我们就必须知道,对于烹调“tufa”来说,物体的圆度是不是比它的重量更重要,以及圆度和重量的变化在什么程度上会影响“tufa”的烹调。然后,层次贝叶斯计算就会利用其他类似的例子作为启发,比如说,在烹调其他食物时用到的物体的圆度和重量的影响。
这正是我们在解决斯坦悖论时用到的方法。回忆一下,为了根据相关数据判断某位飞行员的水平,同时考虑其他飞行员的水平也不无益处。同样,这个原则在解决苏格兰绵羊问题时也至关重要。为了将一只绵羊的黑色毛色推广到其他绵羊,关于其他物种的毛色如何根据地理环境变化的知识也有用处。
最迷人的地方在于,这种层次贝叶斯主义的做法可以被视为一种学习“如何学习”的方法。在学习到圆度和重量一般会对烹饪有什么影响之后,我们就能更有效地确定物体 B 和物体 C 在烹调“tufa”时用处有多大,即使我们得到的唯一信息只与物体 A 有关!层次学习让我们能够忽略那些无关紧要的变量,专注于那些重要的变量。
当然,我在这里给出的只是一个极端简化的例子。但在更普遍的情况中,层次贝叶斯方法能够迅速确定用什么方式才能将有关世界的模型正确地组织起来,比如对物体分类时用到的图结构的选择,或者研究物理现象时用到的因果法则。一旦发现了这些模型的正确结构,学习过程就能大大加速,因为之后的学习可以在恰当的受限模型中进行。
其实我们已经看到了这种学习的一个更明确的例子,那就是 LDA。这个贝叶斯结构能让我们逐步学会在为文件分类时选择合适、贴切的类别,也会让日后的文件分类变得更简单。此外,这个模型也与特南鲍姆和其他合作者在 2011 年研究过的模型很相似,他们得出的结论就是所谓的“抽象的恩赐”。
抽象的恩赐
特南鲍姆及其合作者用下面的方法展示了这种抽象的恩赐。他们首先考虑了一个层次结构,换句话说,他们考虑了多个一般性的模型,其中每一个模型都可以分为不同的特殊因果模型,而这些模型又可以细分为不同的特殊情况。然后,他们考虑了一个贝叶斯人工智能,它会在这个层次结构中的每一个层次都应用贝叶斯公式进行计算。
所罗门诺夫归纳法可以很好地解释这种做法。回忆一下,所罗门诺夫的做法就是学习那些能够解释过往数据并预测此后数据的理论。我们可以打赌,最优秀的理论就是那些利用贝叶斯公式从过去数据出发做出预测的理论。所罗门诺夫妖在理论之间进行的贝叶斯计算很可能会将置信度放在那些符合贝叶斯主义的理论上,而这些理论也会将贝叶斯公式应用到下一层上。更进一步,这些贝叶斯理论会研究众多子理论,最终会偏好那些符合贝叶斯主义的子理论,以此类推。
无论如何,特南鲍姆及其合作者进行的模拟指出,层次贝叶斯学习一开始在所有层次上都很缓慢,但在研究几百到数千个抽样之后,整个层次结构最终会将贝叶斯置信度放在正确的一般性理论之中。令人感兴趣的是,对正确的一般性理论的学习要比更低层次的学习快得多。这个观察结果的推论之一,就是直接从正确的一般性理论开始学习,基本上不会节省多少时间!
我们之后也会重新谈到一个现象:儿童有着强大的学习能力,使某些心理学家惊奇不已,他们甚至提出儿童大脑中有着大量由遗传信息预先编码的模型。比如说,儿童似乎有着应用因果法则的天性。然而特南鲍姆及其同事进行的模拟指出,对于利用层次贝叶斯主义的智能来说,学习模型中一般性原则的速度其实相对较快,它们无须预先处理好的学习模型。贝叶斯主义似乎能让智能以出人意料的效率来发现贴合这个世界的思考范式!
某些理论研究者有时候会抱怨,科学研究中对人工智能的使用过于泛滥。他们称,对大数据的探索不可能让我们发现优雅普适的公式,也不能让我们找到如爱因斯坦的广义相对论那样美妙的公式。机器学习似乎过于机械,欠缺只有伟大的心灵才拥有的那种才气。
然而,这种说法忽略了贝叶斯方法中抽象的恩赐。层次贝叶斯方法似乎完全能够从大量理论的一般结构之中分辨出最能对经验数据做出适当解释的结构。它似乎也能够辨别出最优秀的理论的一般形式,由此为思考经验数据给出合适的范式。
如果优雅的公式就是对这些数据建模的正确方法,那么我们可以打赌,足够接近所罗门诺夫妖的人工智能必定知道如何得出这个公式,正如神经科学家发现,贝叶斯框架对于研究认知过程来说非常贴切。
婴儿都是天才
我们之前看到,图灵将儿童的大脑比作一本记事本,其中“没什么机关,但有许多张白纸”。这个理念长期以来占据主流。然而,这种想法被心理学家史蒂文·平克和现代神经科学打破,贝叶斯主义对此也有所贡献。
在谈这个问题之前,我们注意到,即使是不满 1 岁的婴儿也已经拥有一组所谓的“核心知识”(core knowledge),对物体、数字、空间和语法都有着某种直觉上的理解。除此之外,这些婴儿似乎已经具有统计能力,一般会花很长时间好奇地盯着他们的贝叶斯大脑认为不太可能发生的事件。
在 2008 年,徐绯和加西亚 对 8 个月大的婴儿进行实验,证实了这一点。这个实验的灵感来自拉普拉斯瓶子模型。一个瓶子里装着大量小球,这些小球要么是红色的,要么是白色的。然后我们从中抽出 5 个小球,假设其中有 4 个红球和 1 个白球。第 6 章谈到过的拉普拉斯接续法则会提示我们,瓶子中红球所占的比例大概是 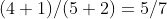 。
。
然后,我们清点瓶子里的小球。如果瓶子里大部分是红球的话,婴儿一点都不吃惊;然而,如果瓶子里实际上大部分是白球的话,婴儿就会花上很长时间盯着瓶子,好像里边藏着什么秘密似的。真是难以置信!8 个月大的婴儿似乎已经能够从直觉上把握拉普拉斯的贝叶斯式计算,并且就像科学家那样,会去调查那些贝叶斯的预测被观察结果否定的情况!
语言
婴幼儿最令人惊异的学习过程就是语言的学习。人人对此都有经验。即使经过数十年的学习,甚至在国外浸淫多年,要把一门语言说得像本地人一样也是非常困难的。旅居英语国家的法国人仍然会保留他们的法国口音。与之相反,婴幼儿有着从父母那里学习语言的惊人能力。仅需数年,婴幼儿对一门语言的掌握程度就能达到许多外国人终其一生都达不到的水平。两岁孩子的词汇量会以每天 10 ~ 20 个词语的疯狂速度增长!他们是怎么做到的?
神经科学指出,婴幼儿的语言学习可能强烈依赖于对语言中被称为“音位”的基本语音单位的统计性质的考察。例如,在扎弗兰、阿斯林和纽波特进行的实验中,他们让婴幼儿聆听一连串音节,这些音节的播放节奏恒定,以至于不可能从中推断出那些音节的任何信息。然而,在这一连串的音节背后隐藏着某种统计规律。比如说,“to”这个音节后面跟着的一定是“ki”,而只有在三分之一的情况下“bu”后面才会跟着“gi”。这就是一个马尔可夫链 。
令人震惊的是,婴幼儿似乎除了能够辨别这些统计规律以外,甚至还能够确定有可能作为单词分界的音节划分方式,这大概是通过贝叶斯推断做到的。也就是说,要从口语中学习单词的话,似乎必须进行某种贝叶斯计算。然后,婴幼儿能够将单词结合起来,以此区分句子。这是一项非凡的成就!因为要做到这一点的话,婴幼儿就必须能够辨别句子的语法结构,也就是识别出其中某些词语是动词,而另一些词语则是名词。在某些语言中,婴幼儿还必须学会在问句中把词语顺序反过来。然而,这些在学习语句的构建中必不可少的努力,对于单词学习来说也有很大的用处。
我举个例子解释一下。假设桌子上有两个碗,一个是蓝色的,另一个是镀铬的。父母让孩子把镀铬的碗拿来。孩子不知道“镀铬”是什么意思,但是他知道这是一个用来描述碗的形容词。此外,孩子还会猜想父母说的可能不是那个蓝色的碗,否则父母可能就会说“蓝色的碗”了。因此,孩子得出结论,镀铬的碗应该不是那个蓝色的碗,而“镀铬”这个词形容的就是那个镀铬的碗的颜色。
真是不可思议!这个孩子刚刚在没有数据的情况下预测并学习了“镀铬”这个词的含义,虽然他之前从来没有听过这个词语,但他仍然确定了词语的意义。孩子的天才之处就是依靠自身的偏见。跟所罗门诺夫所说的一样:“没有数据也能预测,但没有先验概率就不可能预测。”
学习计数
当孩子学习字母表或者数字的时候,他们记住了一连串词语或者声音。此外,学习字母表通常也伴随着一段帮助记忆的旋律。学习数字有时候也会伴随着数手指的行为。
然而,认识一串词语并把它熟记于心,并不代表能够在其他情况中恰当使用这些词语。很多小孩子的确能够背诵那些数字,但如果有人让他们找来 3 个物体,他们却会拿来一堆东西,而不是只拿 3 个。
更奇妙的是,孩子一开始只会理解“一”这个词语的概念,然后他们会学会“二”这个词语,但这一过程就到此为止了。在之后几个月中,即使他们能够背诵“一”和“二”以外的数字,他们都只知道这两个数字的意义。之后他们会学会“三”,然后又止步于此。
大概在三岁半的时候,孩子似乎一下子就完成了一项概念上的巨大飞跃,能够将数字的序列与数字的意义对应起来。他们建立了“加上一个额外的物体”和“换用序列中的下一个数字”之间的联系。这种联系是如何建立起来的呢?
根据特南鲍姆及其合作者皮安塔多西和古德曼所说,孩子刚刚完成的这一奇妙壮举就是学会了一个递归算法。这个算法以任意一堆物体为输入。如果集合中什么都没剩下,那么算法就会以最后一个数作为输出的结论。否则,算法会从这堆物体之中抽出一个,然后说出数字序列之中的下一个数字——如果抽出的是第一个物体,那么孩子会说“一”,然后算法会记住前一步说出来的数字,接着数剩下的物体。
我在这里用了抽象的说法,描述的正是你所知道的(字面意义上的)数手指算法,你每次挨个数一堆东西的时候应用的就是这个算法。但这个人人都将学会的算法其实抽象得惊人,而最惊人的还是,只能通过统计学习的小孩子能够辨别并选择这个抽象的递归算法。
德阿纳指出,这种思考并利用递归算法的能力可能就是人类与动物的大脑之间的根本性差异。无论如何,这项利用贝叶斯主义对递归算法进行的研究,尤其暗示了我们的贝叶斯大脑可能跟所罗门诺夫妖之间没有那么大的差距。
心智理论
我们的贝叶斯大脑在儿童时期学习到的最基础的能力之一就是心智理论,也就是思考其他人正在思考什么的能力,以及利用对他人的思考建立的模型来建立预测或者学习新概念的能力。因此,孩子甚至在不到两岁的时候就能够跟随别人的目光,模仿别人的动作,甚至辨认出未完成的动作的意图。再大一点时,孩子就会学习到对方的信念并不一定与第三者的信念完全相同,以及别人可能会说谎,或者用反讽、挖苦、幽默的语气说一些话里有话的东西,而且别人还会不自觉做出各种动作。也许正因为我们是社交性的动物,所以心智理论对于我们的学习来说必不可少。
假设有一个透明的瓶子,里边装着许多蓝色玩具,以及寥寥几个相似的黄色玩具。一位成年人将手伸进瓶子中,拿出了 3 个蓝色玩具,然后按压其中的每一个,每一个玩具都发出了声音。然后成年人从瓶子里拿出一个黄色玩具交给孩子。我们要提出的问题就是,目睹整个情景的孩子会不会将蓝色玩具发出声音的能力推广到黄色玩具上?答案是肯定的。孩子会按压黄色玩具大概 3 次,玩具没有发出声音,这时孩子才放弃继续尝试。
到此为止,事情还在意料之中。但这个实验的如下变体却相当好玩儿:瓶子里只有几个蓝色玩具,却有一大堆黄色玩具,而这一次,成年人取出了 3 个蓝色玩具,也展示了按压这些玩具就会发出声音。然后成年人取出一个黄色玩具,孩子会不会认为这个黄色玩具也会发出声音呢?奇怪的是,孩子的确会去试试这个玩具,但现在却只会尝试一次!
所以,在第二种实验中,孩子似乎会意识到成年人的抽样有偏差。孩子可能会觉得成年人故意只取出蓝色玩具,因为它们与黄色玩具的差别非常大。孩子理解了选择偏差的存在,而他们通过贝叶斯计算得出结论,蓝色玩具的性质并不一定适用于黄色玩具!
孩子不仅知道如何确定选择偏差会怎样影响观察结果的泛化,(我们成年人在更抽象的情况中却完全没有这种智慧!)而且他们也知道为了做到这一点应该如何对成年人的想法建模。孩子拥有心智理论,而且知道怎么应用心智理论避免做出错误的结论。
先天还是后天?
德阿纳谈到了“神经科学中的贝叶斯革命”,不仅因为贝叶斯大脑的理论容纳了难以用其他方法解释的海量实验结果,贝叶斯观点的魔力同样在于它能够解答与儿童学习过程有关的古老辩论之一,而且这个解答完整得惊人。在这一历史悠久的辩论中,对阵双方分别是认为大脑在出生时就有关于语言和语法的先验知识的先天论(innatism)支持者,以及认为所有这些知识都要经过学习才能获得的经验论(empiricism)支持者。这场辩论的象征就是心理学家斯金纳和乔姆斯基之间史诗般的对抗。
拉开战幕的是伯勒斯·斯金纳在 1958 年出版的著作《语言行为》(Verbal Behavior)。斯金纳以他所做的一些实验为重要论据,证明了鸽子能够学会“啄”和“转圈”等词。的确,斯金纳发现,如果在鸽子做出与展示给它们的词语相关的行动时给它们奖励的话,那么这些鸽子最后都能理解这些词语的意义,或者至少说,它们可以将看到的词语联系到能获得奖励的行动上。
然而诺姆·乔姆斯基反驳道,掌握人类语言远比学会词语与事件之间的相关性更复杂、更困难。乔姆斯基认为,要学会语言和语法的精细复杂之处,就必须借助具有这一潜能的大脑。乔姆斯基提出,我们的大脑从基因层面上就编入了理解和操作他所谓的“普遍语法”的能力。
然而,我们之前已经看到,贝叶斯大脑这个假设有着难以置信的预测能力,而根据这一假设,所有婴儿都首先应该具有这样的能力,能够建立与环境中各种现象相关的复杂模型,也能够应用贝叶斯公式来保留并探索那些最有用的模型。关键在于,特南鲍姆及其合作者进行的模拟暗示了婴儿的这一能力对于建立周围环境的模型、理解语言和学习说话来说似乎是充分且必要的条件——这也印证了所罗门诺夫完备性定理!
从某种意义上来说,婴儿大脑天生的结构给主张人类大脑必然具有某种禀赋的先天论提供了论据。然而,这种先天结构似乎比乔姆斯基提出的结构更抽象、简洁、出色。我们已经看到了这一结构,层次贝叶斯方法实际上能够迅速确定那些宏大的思考框架。
反过来说,经验数据在通过贝叶斯公式对实用模型进行的选择中扮演了关键的角色。然而在这里,这种对数据的学习也绝对不能完全归结于通过强化学习对相关性进行的简单计算。这一学习针对的是极端复杂、精妙的模型,它会在不同的层次上进行贝叶斯计算。
这真是令人叹为观止。贝叶斯公式对我来说如此难以理解,甚至令我觉得自己没有足够的能力来计算概率,但我的大脑似乎就在用它进行计算,而这同一个大脑却无谓地期望着成为有自觉、有能力的贝叶斯思考者,我觉得这一点极其迷人,但又令人困惑。似乎人人都有着某种非常精细、高效的机制来进行复杂的贝叶斯计算,而这种计算高度并行,在能量消耗效率上也无可比拟。然而奇怪的是,我们对于这种计算毫不自觉,而且完全无法利用这种能力来正确地思考。
01

《贝叶斯的博弈:数学、思维与人工智能》
作者:黄黎原
译者:方弦
法国数学类科普书、大学数学参考及教材类图书畅销书目,在机器学习、人工智能、逻辑学和哲学等众多领域中,探索贝叶斯定理蕴藏的智慧与哲理。
贝叶斯定理一旦与算法相结合,就不再是一套枯燥的数学理论或认识论,而变成了应用广泛的知识宝库,催生了众多现代数学定理,以及令人称道的实践成果。
03

《趣学贝叶斯统计:橡皮鸭、乐高和星球大战中的统计学》
作者:[美] 威尔·库尔特(Will Kurt)
译者:王凌云
本书用十余个趣味十足、脑洞大开的例子,将贝叶斯统计的原理和用途娓娓道来。你将从直觉出发,自然而然地习得数学思维。读完本书,你会发现自己开始从概率角度思考每一个问题,并能坦然面对不确定性,做出更好的决策。

《概率论沉思录》
作者:埃德温·汤普森·杰恩斯
译者:廖海仁
著名数学物理学家,圣路易斯华盛顿大学和斯坦福大学教授,统计力学和概率统计推断方面权谋埃德温·汤普森·杰恩斯,40年思想著作;
无数读者苦等15年的概率论神作,英文版豆瓣评分9.4高分;
概率论作为逻辑的延伸,是所有科学推断的基础。本书收集了概率统计的各种线索,将概率和统计推断融合在一起,用新的观点生动地描述了概率论在物理学、数学、经济学、化学和生物学等领域中的广泛应用,尤其是阐述了贝叶斯理论的丰富应用,弥补了传统概率论和统计学的不足,并揭开了众多悖论背后的玄机。


















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









