






接上一篇pytorch相关可视化内容--HiddenLayer
感觉十分不好用,显示和更新会卡顿,置顶显示,拖动和拉伸窗口会直接卡住,显示的窗口大小和图片保存暂时还不知道咋操作。。
因此产生这篇文章,貌似这篇文章都写了,我就简单记录下过程把
深度学习参数可视化黑科技-TensorBoard 使用方法_可乐要加冰_ice的博客-CSDN博客_conda install tensorboard
1.进入自己的虚拟环境
2.直接执行指令:
conda install tensorboardX
conda install tensorboard
3.测试是否正常
报错,发现是由于终端选的虚拟环境默认是local,需要切换环境,如果遇到其他奇怪的问题,可以参考tensorboard : 无法将“tensorboard”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。_qq_44168575的博客-CSDN博客
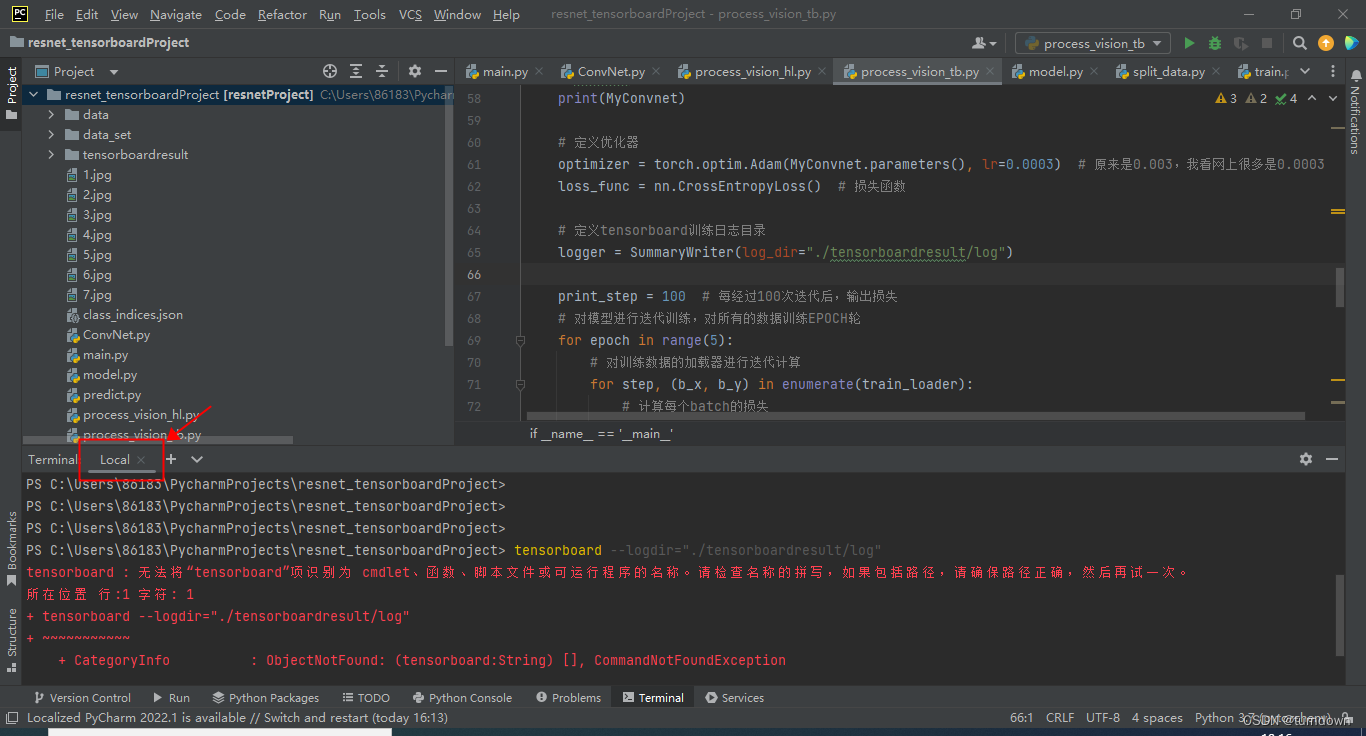
切换环境
弹出了链接,点击
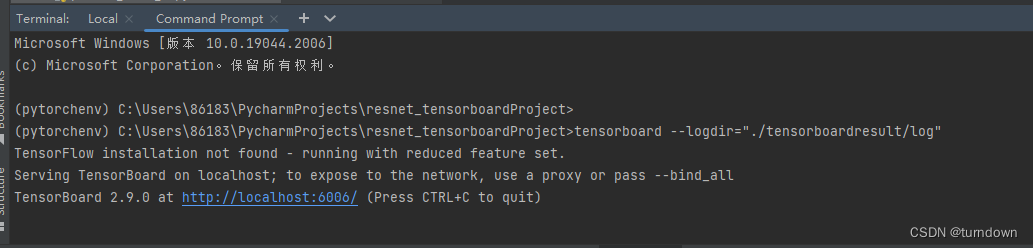
出来了结果,但是还看不太懂,也有可能代码还有点问题 ,不过比起hiddenlayer库确实华丽很多,却只能训练完成后才能展示
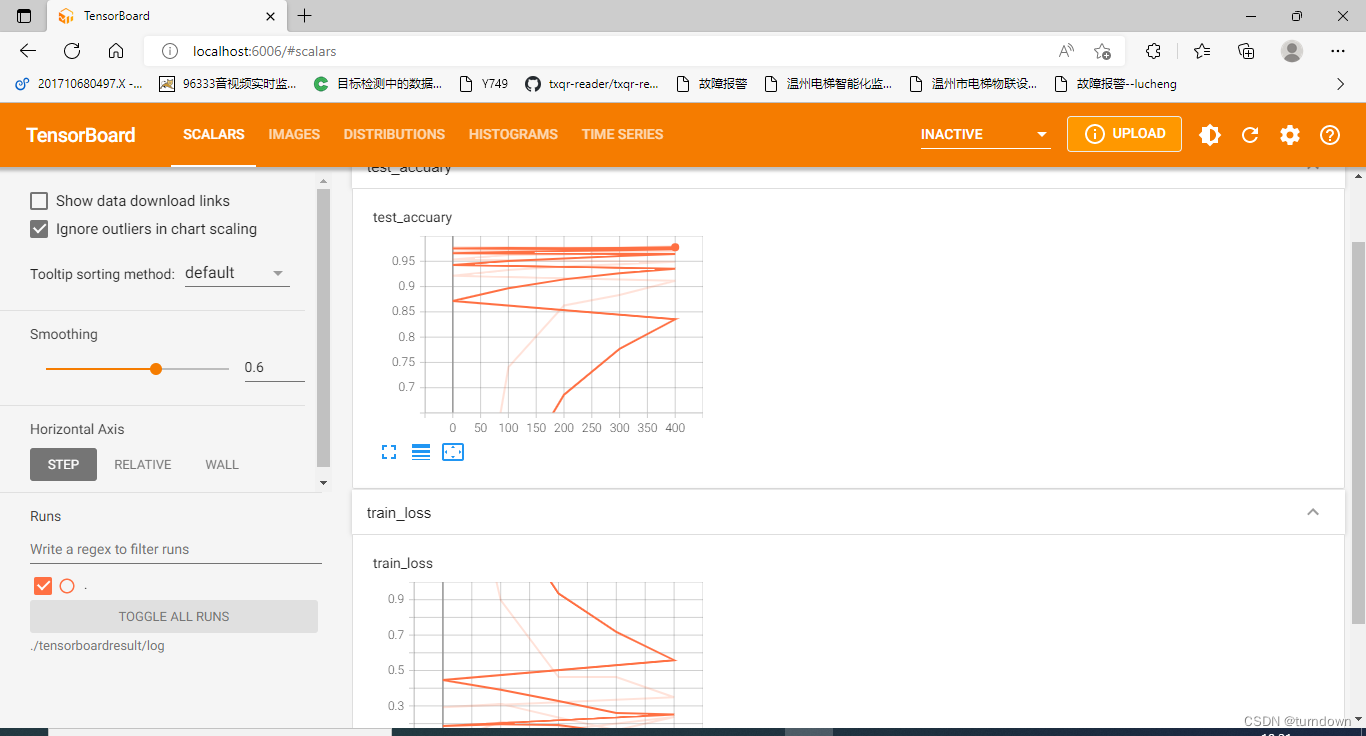

附上参考代码(可能还有点问题,但是能跑,跑的cpu训练):
ConvNet.py
'''
搭建一个卷积神经网络,该网络用于展示如何使用相关包来可视化其网络结构
'''
import torch.nn as nn
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
# 定义第一个卷积层: Conv2d + RELU + AvgPool2d
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1, # 输入的feature map
out_channels=16, # 输出的feature map
kernel_size=3, # 卷积核尺寸3*3
stride=1, # 卷积核步长
padding=1, # 填充边缘,避免数据丢失;值为1表示填充1层边缘像素,默认用0值填充;padding的值一般是卷积核尺寸的一半(向下取整)
),
nn.ReLU(), # 激活函数
nn.AvgPool2d(
kernel_size=2, # 平均值池化层,使用2*2
stride=2, # 池化步长为2
),
)
# 定义第二个卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2) # 最大值池化层
)
# 定义全连接层
self.fc = nn.Sequential(
nn.Linear(
in_features=32 * 7 * 7,
out_features=128,
),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU()
)
self.out = nn.Linear(64, 10) # 最后的分类层
# 定义网络的向前传播路径
def forward(self, x):
'''
定义网络的向前传播路径
:param x: x是数据集的特征值,作为参数传入网络
:return:
'''
x = self.conv1(x)
x = self.conv2(x) # tensor尺寸为[batchsize,channels,h,w]
x = x.view(x.size(0), -1) # 展平多维的卷积图层;展平为[batchsize,channels*h*w]
# 用在卷积和池化之后、全连接层之前;将多维转成一维,因为fc要求输入数据为一维
# 卷积或者池化之后的tensor的维度为(batchsize,channels,x,y),其中x.size(0)指batchsize的值,最后通过x.view(x.size(0), -1)将tensor的结构转换为了(batchsize, channels*x*y),即将(channels,x,y)拉直,然后就可以和fc层连接了
x = self.fc(x)
output = self.out(x)
return output
# 训练过程可视化:tensorboardX库
# tensorboardX库
import torch
import torch.nn as nn
import torchvision
import torch.utils.data as Data
from sklearn.metrics import accuracy_score
from tensorboardX import SummaryWriter
import torchvision.utils as vutils
from ConvNet import ConvNet
if __name__ == '__main__':
# 数据预处理
# 使用手写字体数据,准备训练数据集
train_data = torchvision.datasets.MNIST(
root="./data/MNIST", # 数据的路径
train=True, # 只使用训练数据集
# 将数据转化为torch使用的张量,取值范围为[0,1]
transform=torchvision.transforms.ToTensor(),
download=False # 若数据已经下载过,这里值设为False
)
# 定义一个数据加载器
train_loader = Data.DataLoader(
dataset=train_data, # 使用的数据集
batch_size=128, # 批处理样本大小128,电脑太卡了,试着改为64
shuffle=True, # 每次迭代前打乱数据
num_workers=0 # 使用4个进程,电脑太卡了,我改成0
)
for step, (b_x, b_y) in enumerate(train_loader):
if step > 0:
break
print("b_x.shape", b_x.shape)
print("b_y_shape", b_y.shape)
# 准备需要使用的测试数据集
test_data = torchvision.datasets.MNIST(
root="./data/MNIST",
train=False,
download=False,
)
# 为测试集数据添加一个通道维度,并且取值范围缩放到0~1之间
# 不将数据处理为数据加载器,将整个测试集作为一个batch,方便计算模型在测试集上的预测精度
test_data_x = test_data.data.type(torch.FloatTensor) / 255.0
print("原test_data_x.shape", test_data_x.shape)
test_data_x = torch.unsqueeze(test_data_x, dim=1) # 在第二维添加维度
test_data_y = test_data.targets # 测试集的标签
print("test_data_x.shape", test_data_x.shape)
print("test_data_y.shape", test_data_y.shape)
# 初始化网络并输出网络的结构
MyConvnet = ConvNet()
print(MyConvnet)
# 定义优化器
optimizer = torch.optim.Adam(MyConvnet.parameters(), lr=0.0003) # 原来是0.003,我看网上很多是0.0003
loss_func = nn.CrossEntropyLoss() # 损失函数
# 定义tensorboard训练日志目录
logger = SummaryWriter(log_dir="./tensorboardresult/log")
print_step = 100 # 每经过100次迭代后,输出损失
# 对模型进行迭代训练,对所有的数据训练EPOCH轮
for epoch in range(5):
# 对训练数据的加载器进行迭代计算
for step, (b_x, b_y) in enumerate(train_loader):
# 计算每个batch的损失
output = MyConvnet(b_x) # CNN在训练batch上的输出
loss = loss_func(output, b_y) # 交叉熵损失函数
#
optimizer.zero_grad() # 每个迭代步的梯度初始化为0
loss.backward() # 损失的后向传播,计算梯度
optimizer.step() # 使用梯度进行优化
#
# 计算迭代次数
# 计算每经过print_step次迭代后的输出
if step % print_step == 0:
# 计算在测试集上的精度
output = MyConvnet(test_data_x)
_, pre_lab = torch.max(output, 1)
# torch.max(output, dim=1),dim=1表示输出所在行的最大值,若改写成dim=0则输出所在列的最大值
# 行代表样本、列代表类别,比如128个样本 * 10个类别(该样本是某类别的概率值)
# 返回的是两个值,第一个值是具体的value,第二个值是value所在的index
# 分类任务中,值所对应的index就对应着相应的类别class
acc = accuracy_score(test_data_y, pre_lab)
# 计算每个epoch和step的模型的输出特征,log保存需要可视化的过程
# 控制台输出一下
print("step:{}, loss:{:.2}".format(step, loss.item()))
# 添加的第一条日志:损失函数-全局迭代次数
logger.add_scalar("train loss", loss.item(), global_step=step)
# 添加第二条日志:正确率-全局迭代次数
logger.add_scalar("test accuary", acc.item(), global_step=step)
# 添加第三条日志:这个batch下的128张图像
img = vutils.make_grid(b_x, nrow=12)
logger.add_image("train image sample", img, global_step=step)
# 添加第三条日志:网络中的参数分布直方图
for name, param in MyConvnet.named_parameters():
logger.add_histogram(name, param.data.numpy(), global_step=step)
print("END")
没遇到什么奇怪的问题。就这样了。














 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









