







 本文通过Python对鸢尾属植物数据集进行统计分析,计算了萼片长度的平均值、中位数及标准差,并筛选出特定条件下的数据行。
本文通过Python对鸢尾属植物数据集进行统计分析,计算了萼片长度的平均值、中位数及标准差,并筛选出特定条件下的数据行。
使用鸢尾属植物数据集.\iris.data,在这个数据集中,包括了三类不同的鸢尾属植物:Iris Setosa,Iris Versicolour,Iris Virginica。每类收集了50个样本,因此这个数据集一共包含了150个样本。
求出鸢尾属植物萼片长度(Sepal.Length)的平均值、中位数和标准差:(我用的python中的spyder敲的代码)
import csv
filename=csv.reader(open('iris.csv',encoding='utf-8'))
a=[]
for row in filename:
a.append(row[1])
del a[0] #删除标题行
a=list(map(float,a)) #将字符串转化为浮点型数据
# print("除标题后的萼片长度:",a)
#求平均数
pingjun=sum(a)/len(a)
print("平均数是:",pingjun)
#求中位数
a=sorted(a,reverse=False) #从小到大排列
if (type(len(a)/2)==int): #判断有偶数个数据还是奇数个数据
zhongwei=(a[len(a)/2]+a[len(a)/2+1])/2
print("中位数是:",zhongwei)
else:
zhongwei=a[len(a)//2+1]
print("中位数是:",zhongwei)
#求百分位数
print("第10百分位数是:",a[9])
print("第80百分位数是:",a[79])
#求标准差
c=0
for i in range(0,len(a)):
b=(a[i]-zhongwei)**2
c=c+b
c=(c/len(a))**0.5
print("标准差是:",c)下面的这个是我的结果:

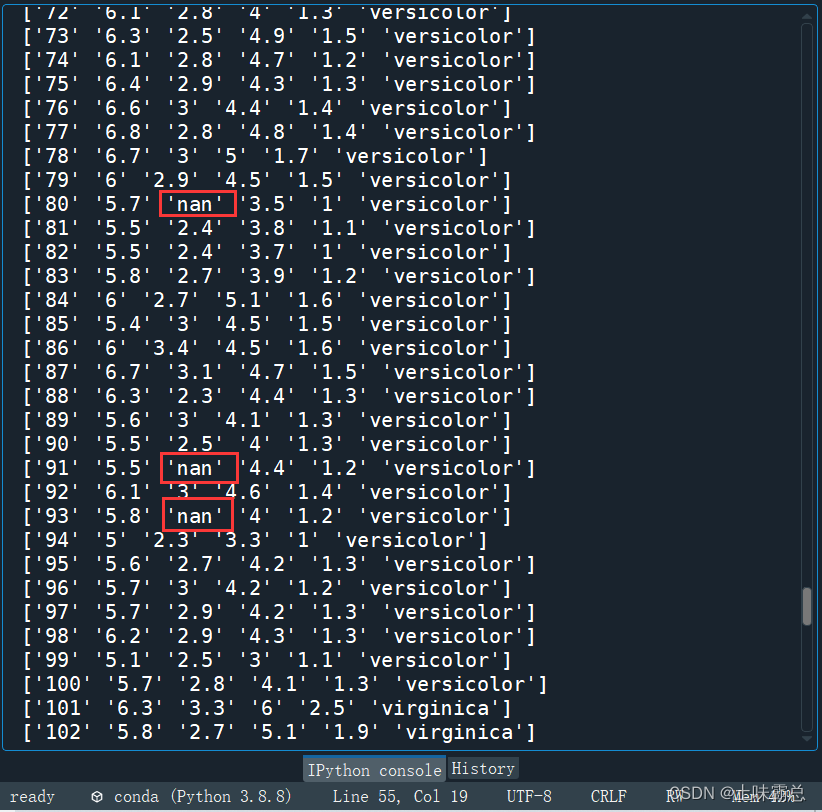
把iris_data数据集中的30个随机位置修改为np.nan值:
#修改nan值
import csv
import random
import numpy as np
filename=csv.reader(open('iris.csv',encoding='utf-8'))
data=[]
for row in filename:
data.append(row)
# print(data)
s=sum(data,[]) #转为一维数组
s1=random.sample(s,30)
print("选取的30个数据分别是:",s1)
count=0
for m in range(0,len(s)):
for n in range(0,len(s1)):
if (s[m]==s1[n] and count<=30): #当修改到30次后跳出循环
s[m]=np.nan
count+=1
else:
break
s=np.array(s)
s=s.reshape(151,6)
print("修改过后的数组为:",s)下面是修改了nan值的结果:
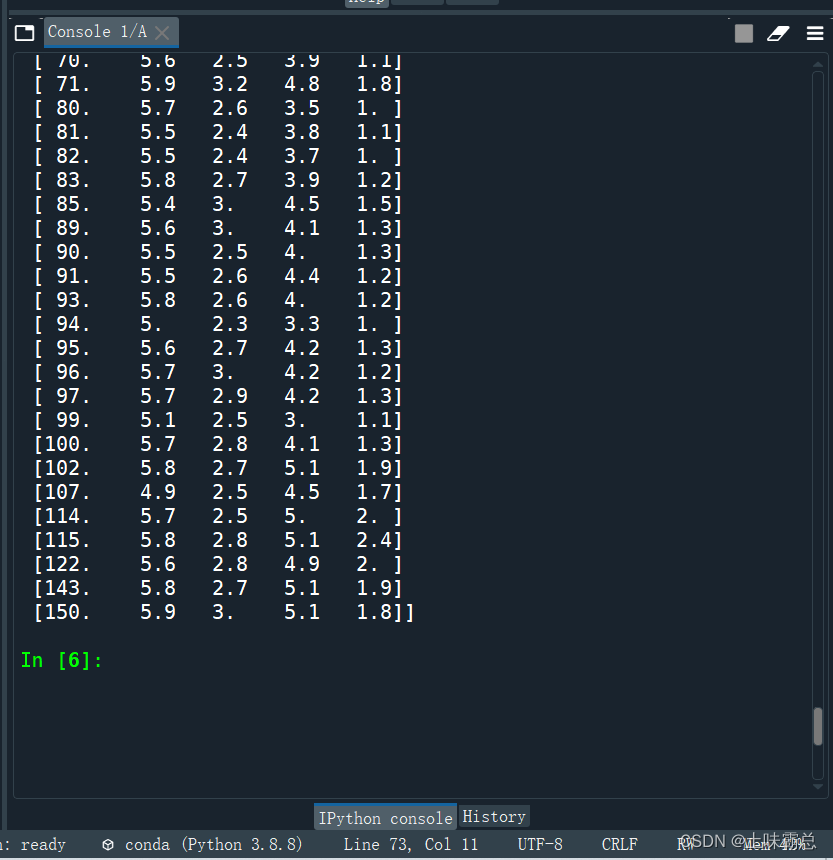
 最后的要求就是筛选具有 sepallength(第1列)< 6.0 并且 petallength(第3列)> 1 的 iris_data行:
最后的要求就是筛选具有 sepallength(第1列)< 6.0 并且 petallength(第3列)> 1 的 iris_data行:
import csv
import numpy as np
from itertools import chain
filename=csv.reader(open('iris.csv',encoding='utf-8'))
demo=[]
for row in filename:
demo.append(row)
demo=np.array(demo)
demo=np.delete(demo,-1,axis=1) #删除最后一列
demo=np.delete(demo,0,axis=0) #删除第一行
demo=list(chain.from_iterable(demo)) #转化为列表
demo=list(map(float,demo)) #将列表中的字符串类型转化为浮点型
demo=np.array(demo) #转为矩阵
demo=demo.reshape(150,5) #转为和表格一样的矩阵维度
np.set_printoptions(suppress=True) #不以科学计数法显示
row_index=np.logical_and(demo[:,1]<6.0,demo[:,3]>1.0) #逻辑与的应用
print("满足条件的行有:",demo[row_index])很明显可以看见一些行已经没有再展现出来:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









