







根据上次学习的内容,在进行随机梯度下降算法的时候要不断更新权重,而复杂的loss函数会导致
权重更新的难以计算因此这时候就要用到反向传播算法来方便的进行计算
反向传播--backward
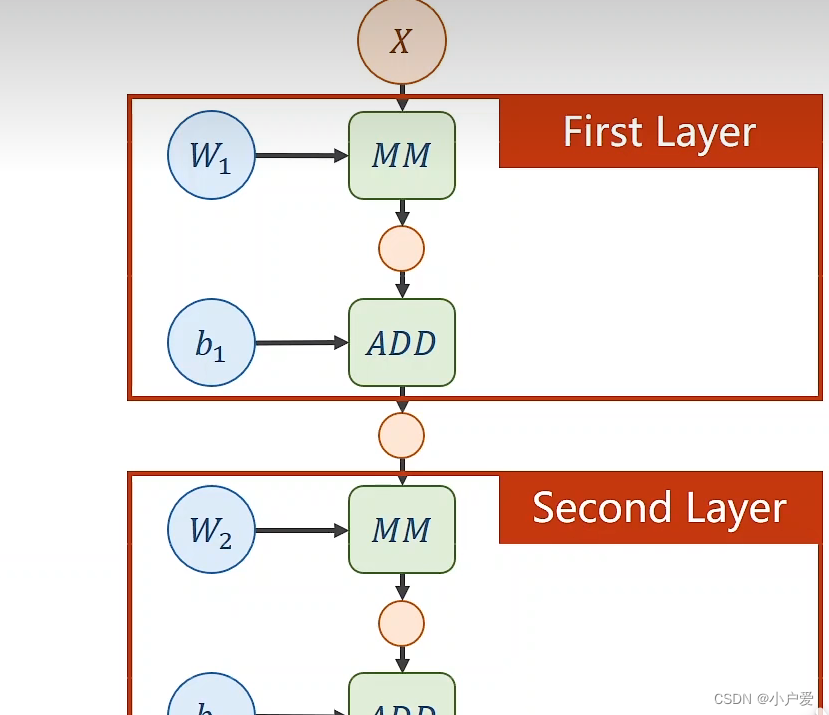
这是全连接神经网络的两层计算 比如 x 可以是n列的向量 w1 可以是一个mxn 的矩阵 MM 就是矩阵乘法的缩写 根据矩阵乘法 计算以后 得到一个m 行 一列的矩阵 接下来再传到第二个计算图中
但是

最后会化简成这样一个形式,那样就没有意义了 所以要在后面加一个 非线性函数来保证他不能展开才是一个神经网络
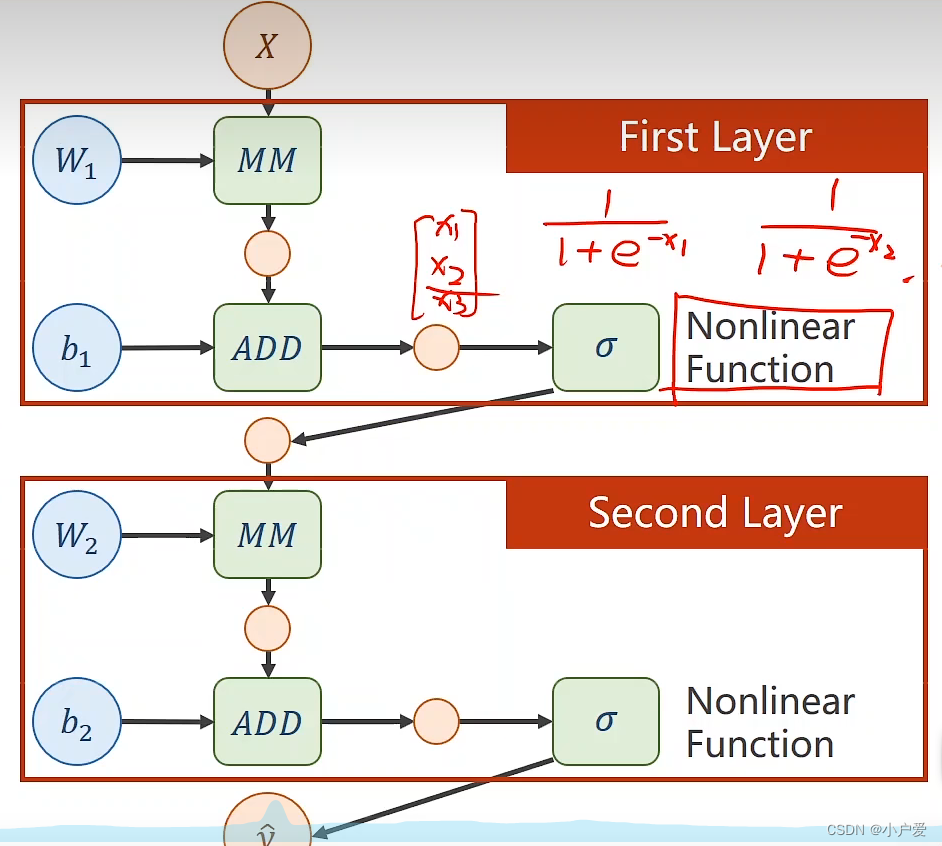
对于一个张量进行求导也要遵循链式法则 由此引出了 反向传播算法
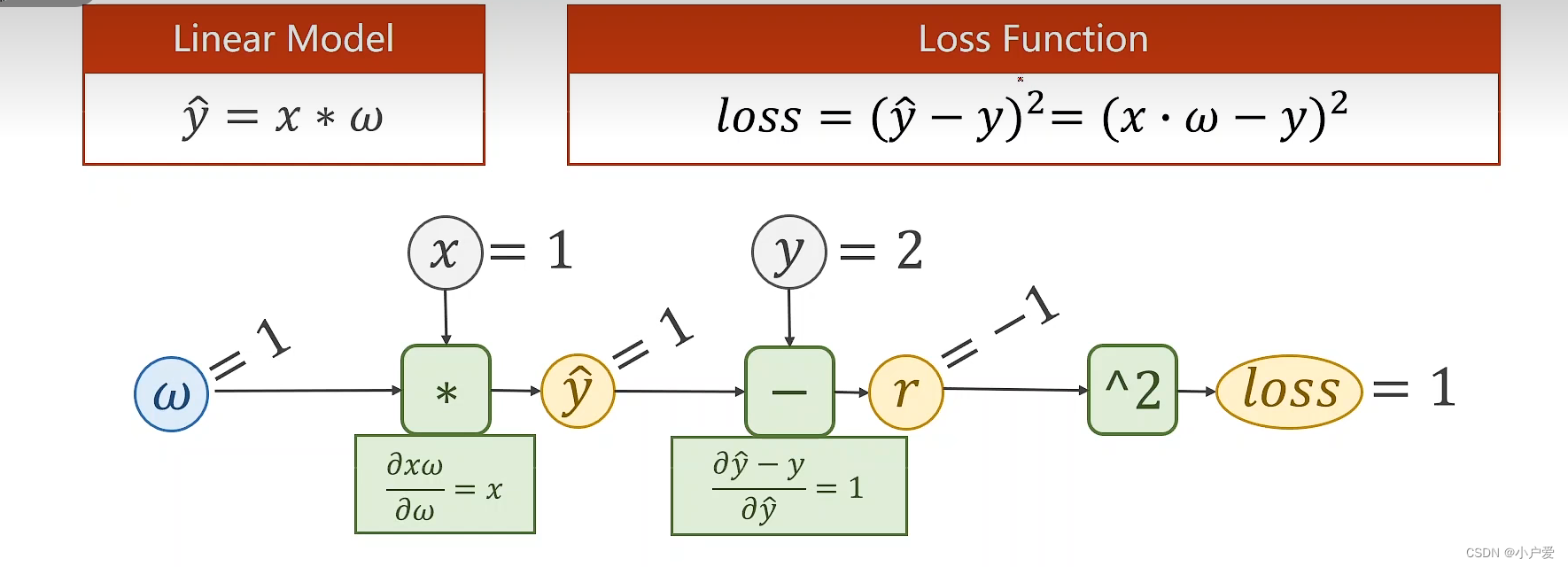
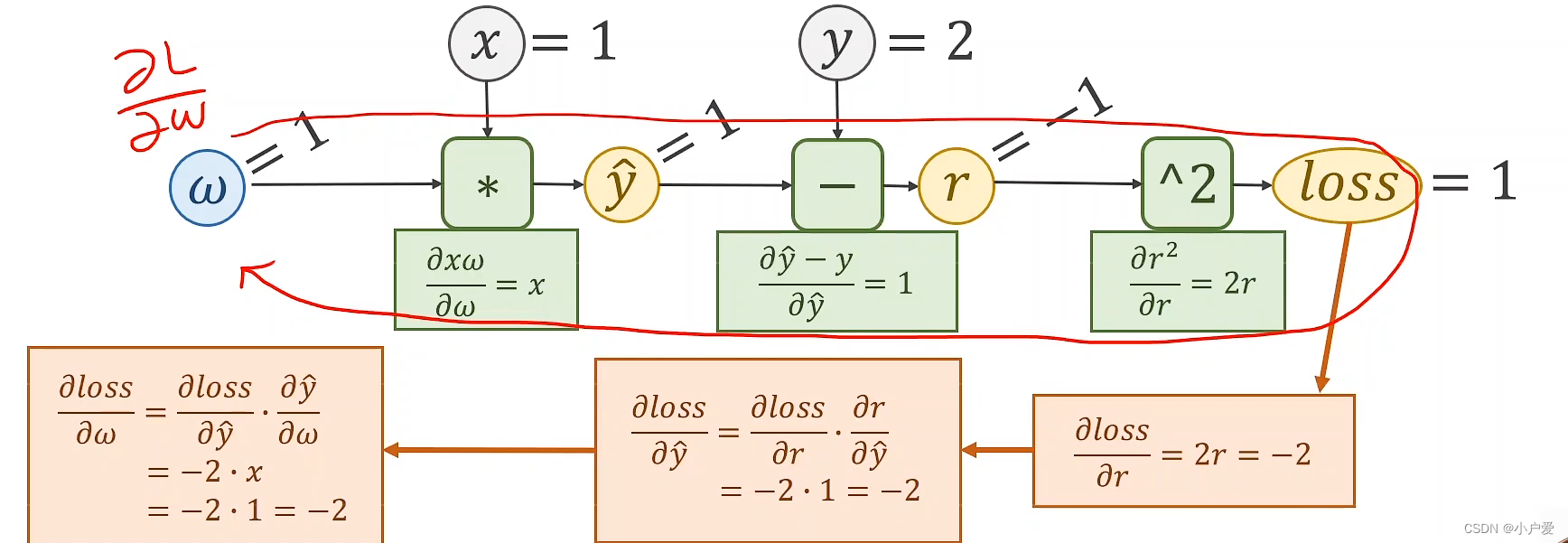
反向传播的原理就是先正向传播到最后,再反向逆推回去从而方便求导
在pytorch 如何进行前馈和反馈的计算
还是之前的线性模型的例题
代码如下:
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor([1.0])
w.requires_grad = True
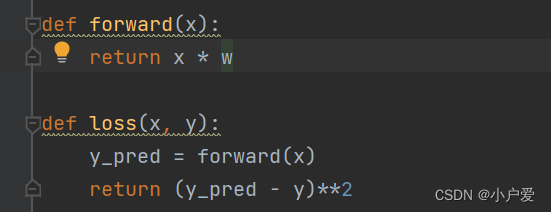
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y)**2
print("predect (before training)", 4, forward(4).item())
for epoch in range(100):
for x ,y in zip(x_data, y_data):
l = loss(x, y)
l.backward()
print("epoch", epoch, x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.item()
print("predice (after training)", 4, forward(4).item())
重点问题:
1. 在计算图里面进行运算的量都要是张量 也就是里面直接 x*w 等,且标注w 是需要计算梯度的
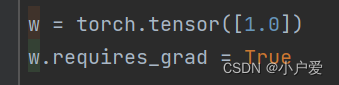
2.随机梯度下降算法的随机体现在样本的随机提取上。随机梯度下降算法不是用所有的数据来计算梯度,而是每次只用一个或者一小批数据来计算梯度。这样可以加快计算速度,也可以避免陷入局部最优解。 这里对应的就是梯度下降算法是将所有样本呢求完以后求均值

3.进行权重更新的时候使用的是w的数据而不是这个张量本身, 如果你使用了w而非w.data的话,那么结果会是错误的。你的w会变成一个新的张量,它的数值和梯度都会和原来的w不一样。你的模型就不能正确地学习了,你的loss也不会下降了。所以你一定要用w.data来更新w,这样才能保证你的模型能够正确地优化,如果你用w进行计算,PyTorch会把它当作一个新的计算图的节点,而不是原来的计算图的参数。这样的话,你就不能更新原来的w了,而是创建了一个新的张量。所以你要用w.data来表示w的数值,这样PyTorch才能知道你是在更新原来的w,而不是创建一个新的张量
其中 tensor 是一个张量 用来在计算图中进行运算 , tensor.data 也是张量但用于 权重的更行 tensor.item(),用来将张量转化为标量用来展示数据
课后作业
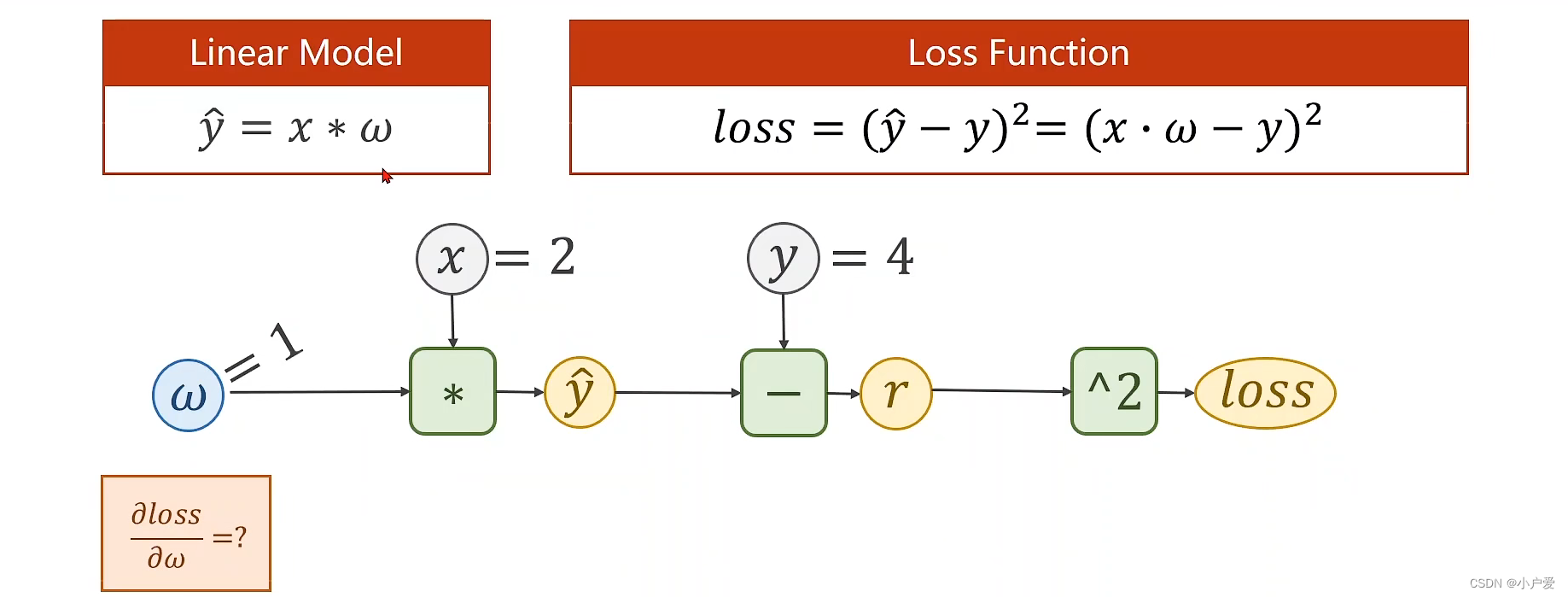
1: x = 2 ,y = 4
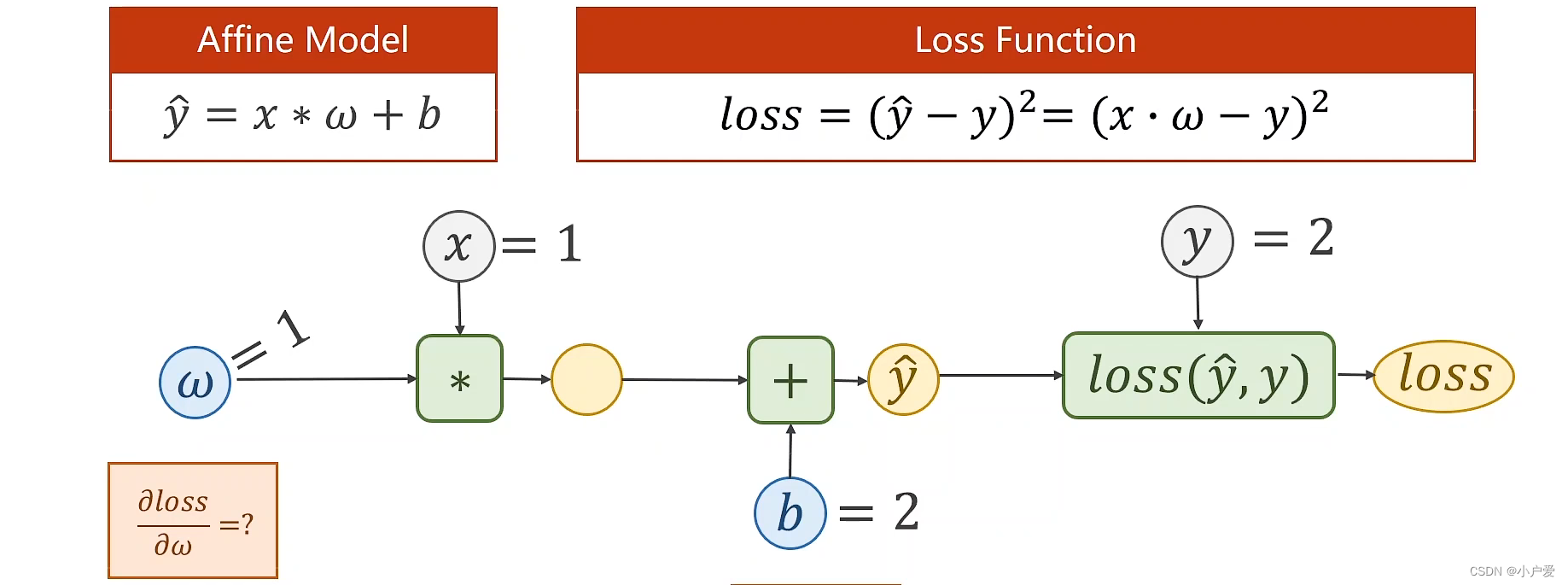
2. 将模型变更为y = x*w +b
作业答案:
1.
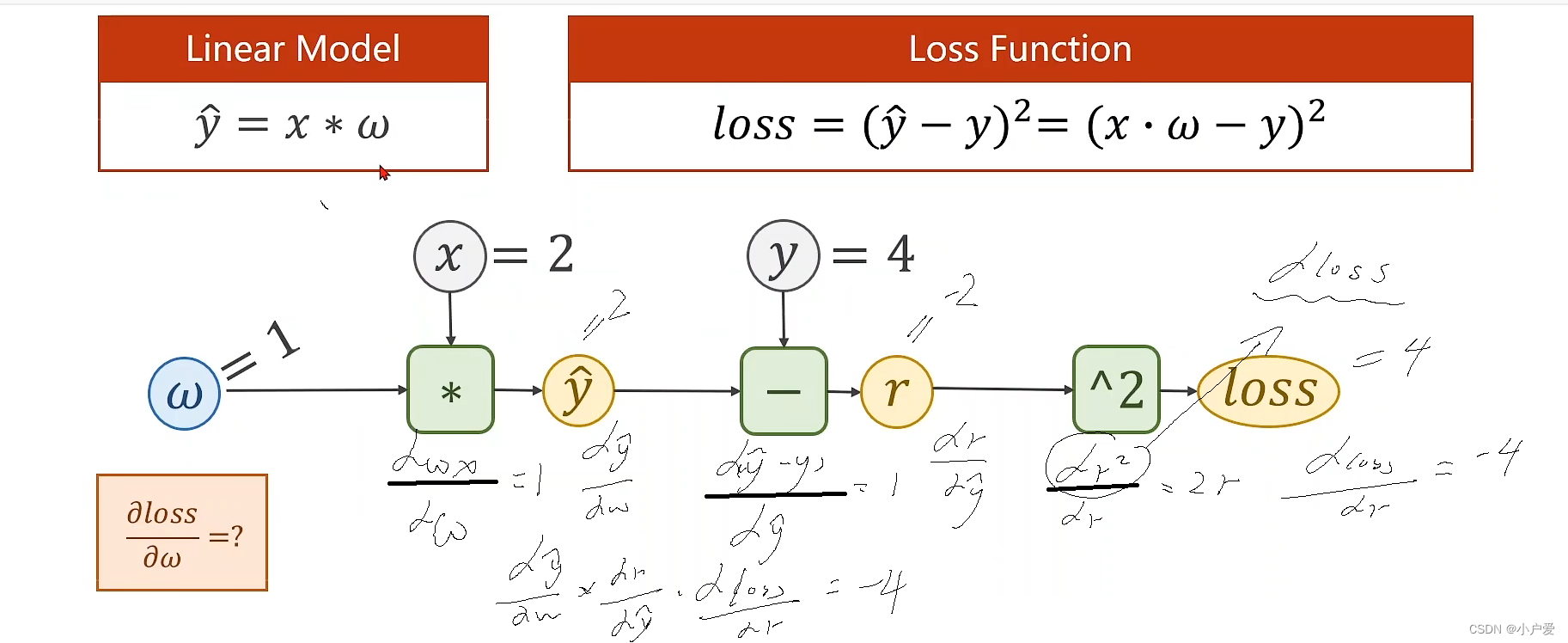
2.
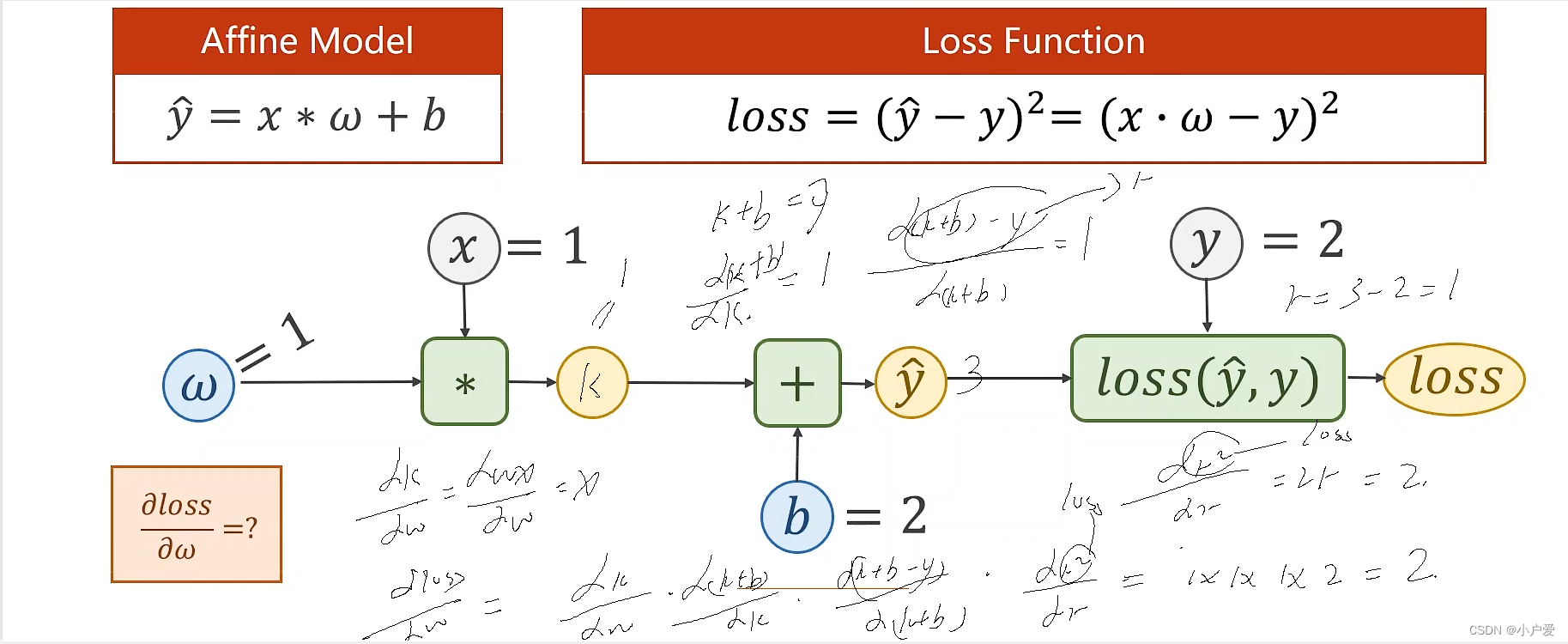

















 3512
3512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











