






文章目录
Python
一、安装
1、安装python环境
①第一步下载软件
浏览器打开链接下载安装:https://pan.quark.cn/s/6a541e6f0bf4
②安装软件
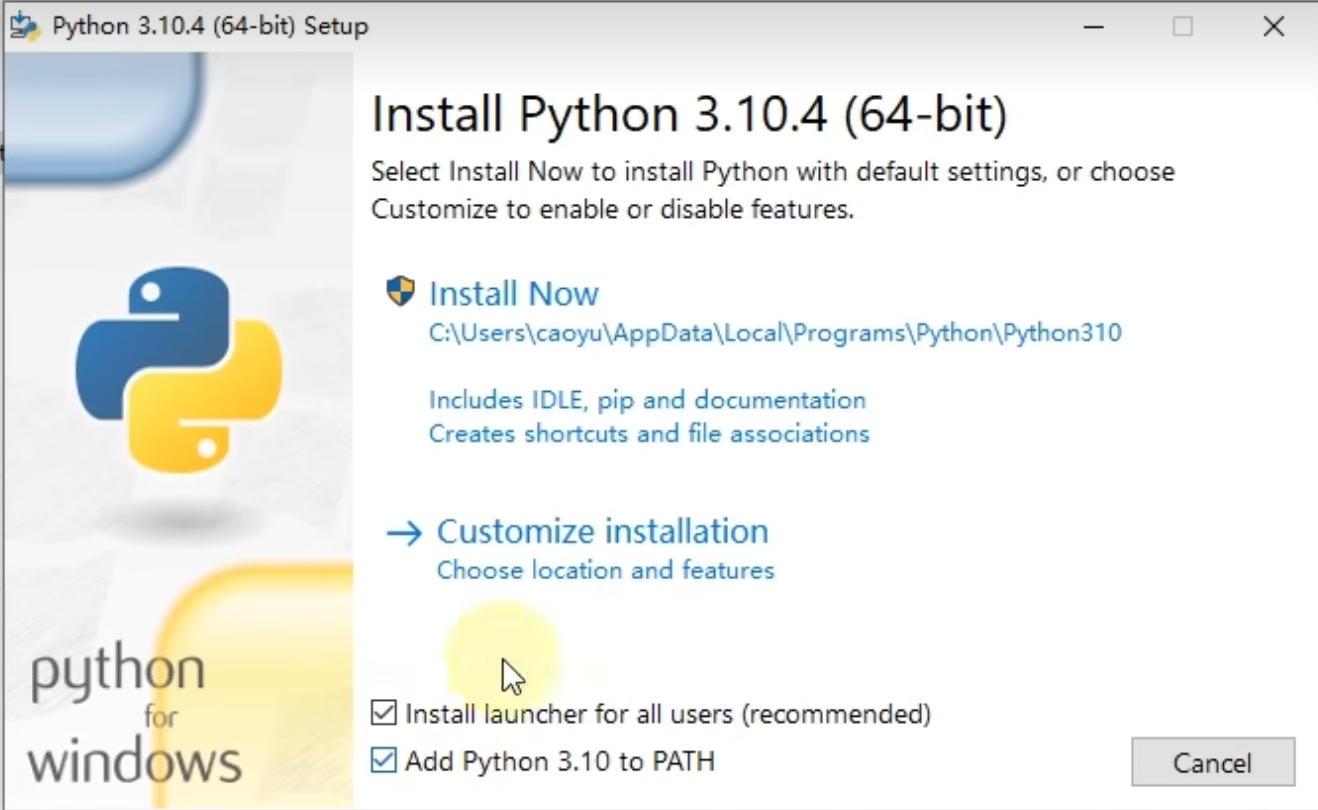
安装路径
 然后无脑下一步
然后无脑下一步
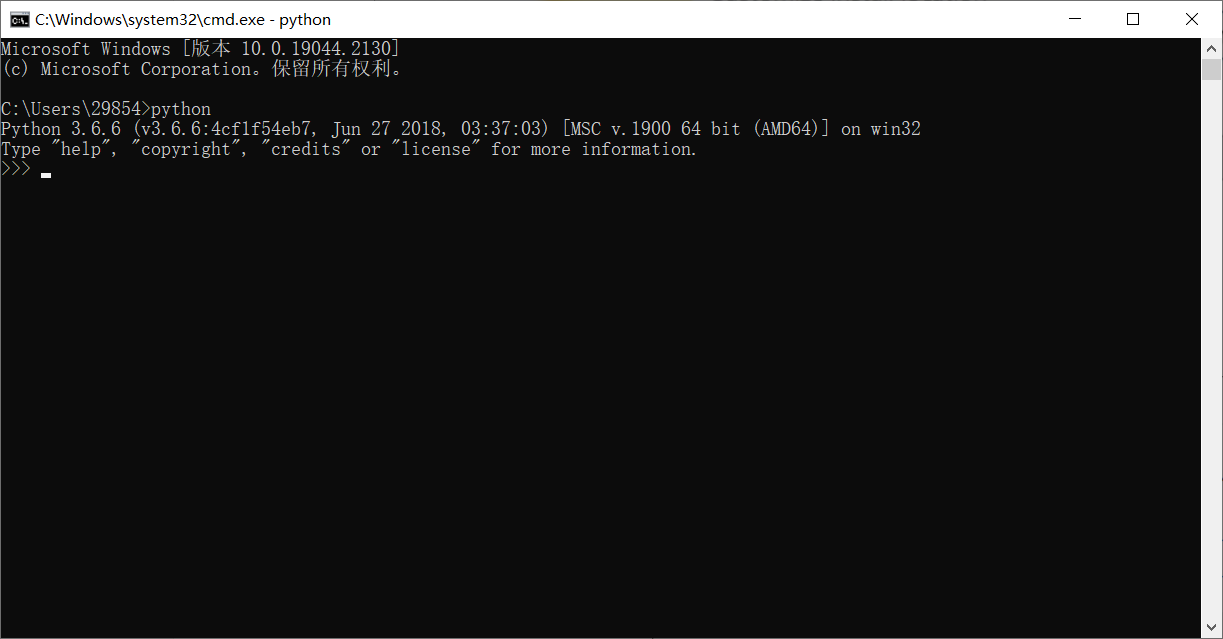
③验证安装是否成功
键盘win键+R,在弹出的小框输入cmd
点击确定,在黑框框(命令提示符)输入python或py(使用python的意思),如下即是安装成功并可以书写python代码
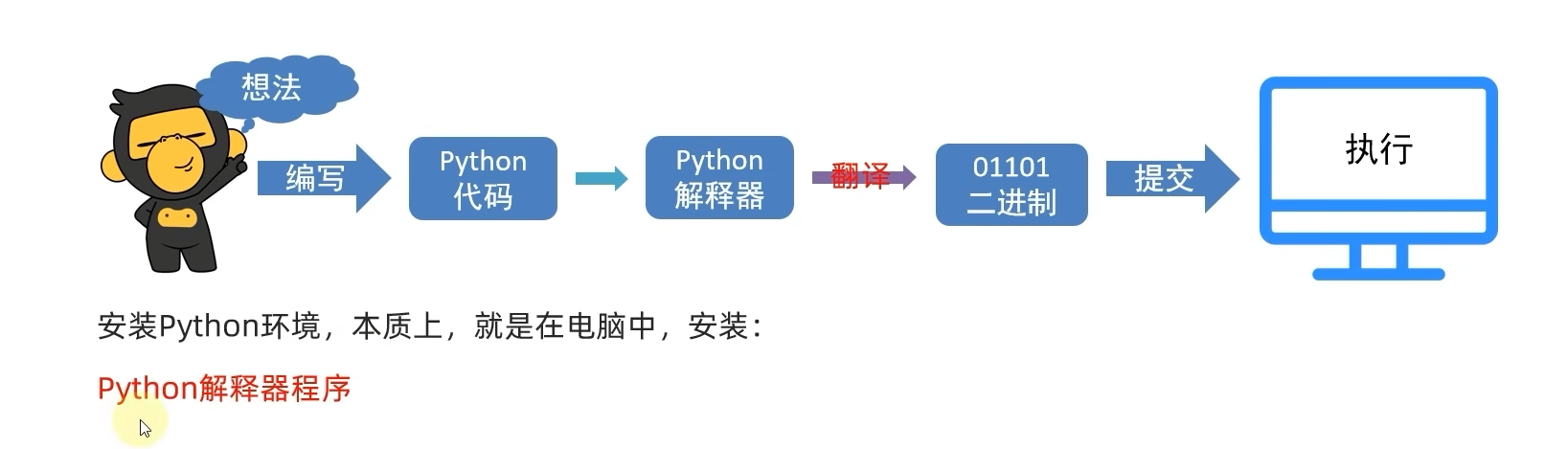
④作用
 2、安装pyCharm开发工具
2、安装pyCharm开发工具
浏览器打开链接下载安装链接:https://pan.quark.cn/s/694b5ac231fa
二、基础语法
1、输出语句
print("您好python")
- 传参不换行语句
print("Hello",end='')
print("World",end='') # 结果:HelloWorld
- 制表符换行
print("Hello\tWorld")
2、执行python文件
①python文件是以.py为后缀

②往文件中写入如下代码:
print("hello")
print("world")
③执行文件
win+R,输入cmd
python 绝对路径
3、字面量
**说明:**代码中被写下的固定的值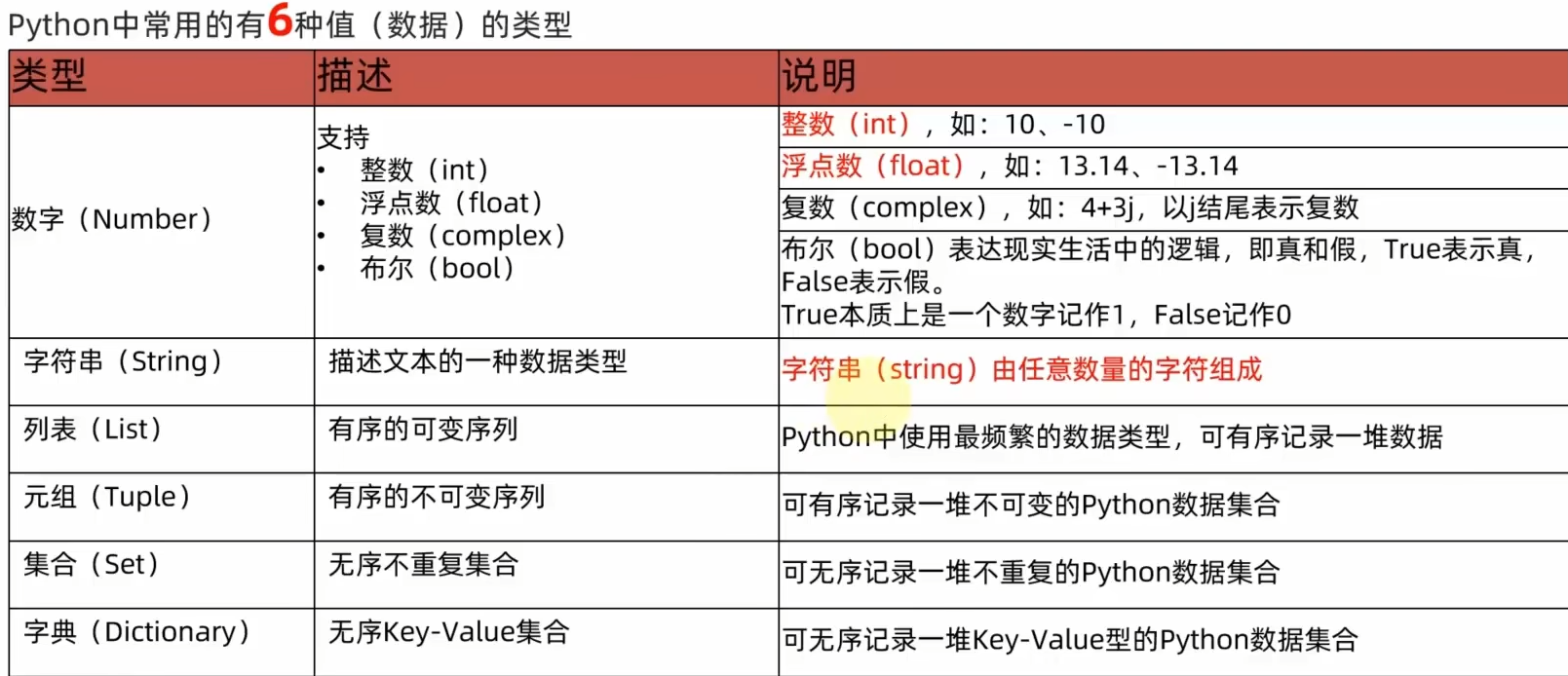
print(字面量)
4、注释
①单行注释:#+ 空格
**②多行注释:**三对双引号
# 单行注释
666 # 整数字面量
13.14 # 浮点字面量
"湖南汽车工程学院" # 字符串类型String,字面量
# 多行注释
"""
通过print输出各字面量
"""
print(666);
print(13.14)
print("湖南汽车工程学院")
③函数注解: 在函数内三对双引号
def __int__(self, request, queryset, page_size=10, page_param="page", plus=5):
"""
:param request: 请求的对象
:param queryset:查询的数据,符合条件的数据对这个进行分页处理
:param page_size:每页显示多条数据
:param page_param:在URL中传递获取分页的参数,列如:/etty/list/?page=12
:param plus:显示当前页的,前、后几页(页码)
"""
5、变量
# 定义变量
money=50
# 变量减去10
money=money-10
# 输出运算后的变量值
print(money) # 打印结果40
6、数据类型
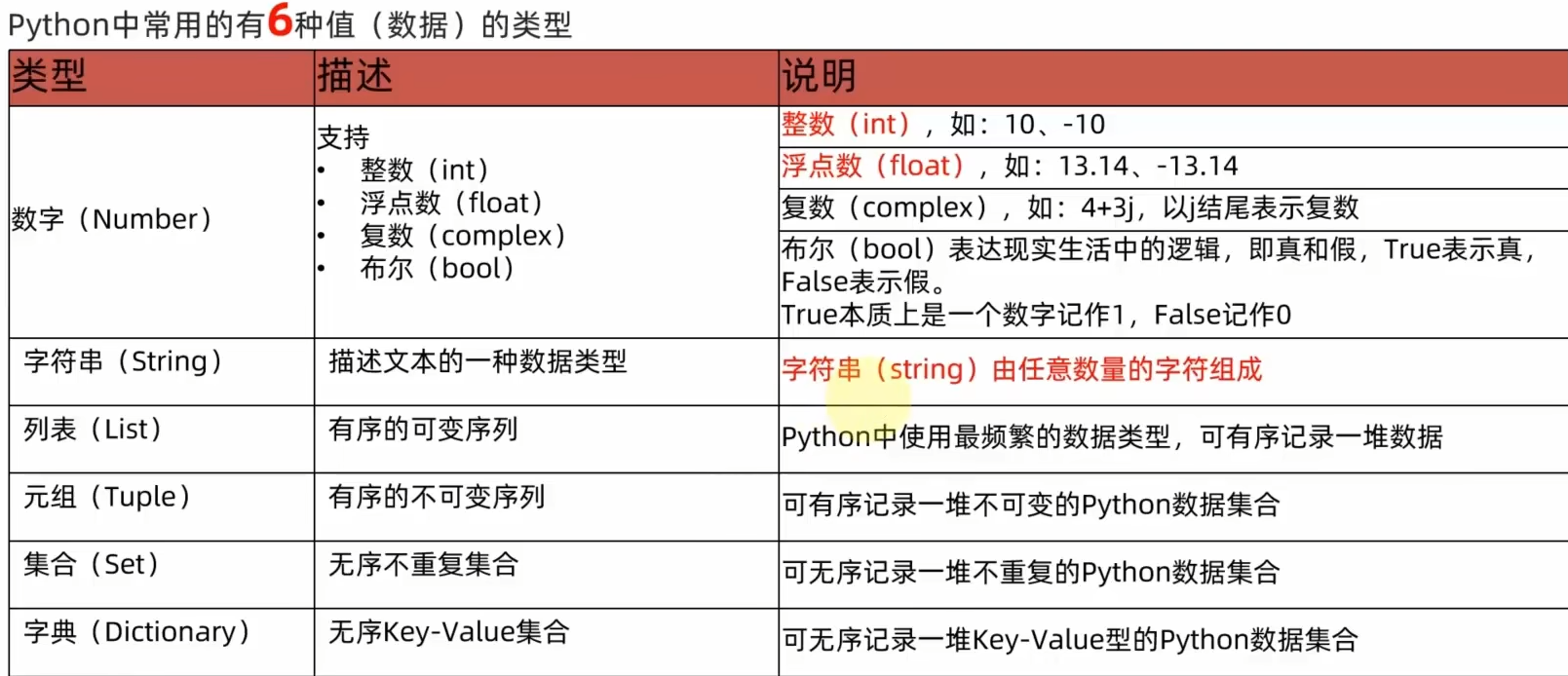
①type()查看数据类型
name ="黑马程序员"
aaa =1
name_t=type(name)
aaa_t = type(aaa)
print(name_t) # 打印结果<class 'str'>
print(aaa_t) #打印结果<class 'int'>
②数据类型转换
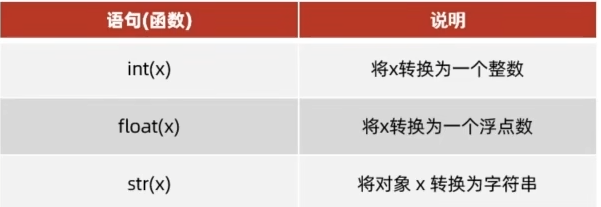
# 将数字类型转换成字符串
num =str(11)
print(type(num),num) # 打印结果:<class 'str'> 11
# 将浮点型转换为数字类型
num2 = float("13.14")
print(type(num2),num2) # 打印结果:<class 'float'> 13.14
7、标识符
**说明:**对变量、类、方法等编写的名字,叫标识符
**命名规则:**只能使用中文、英文、数字、下划线不能以数字开头,大小写敏感,不可以使用关键字
命名规范:见名知意、下划线命名法(两个单词用下划线分割)、英文字母全小写
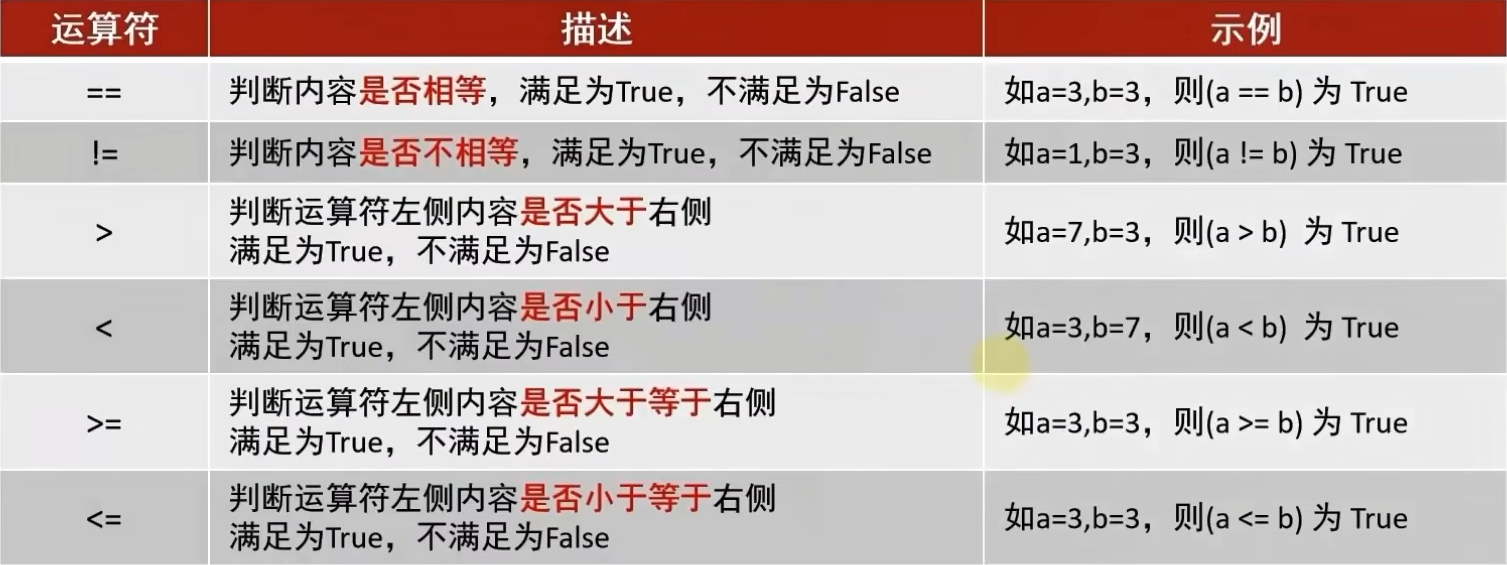
8、运算符
①数学运算符
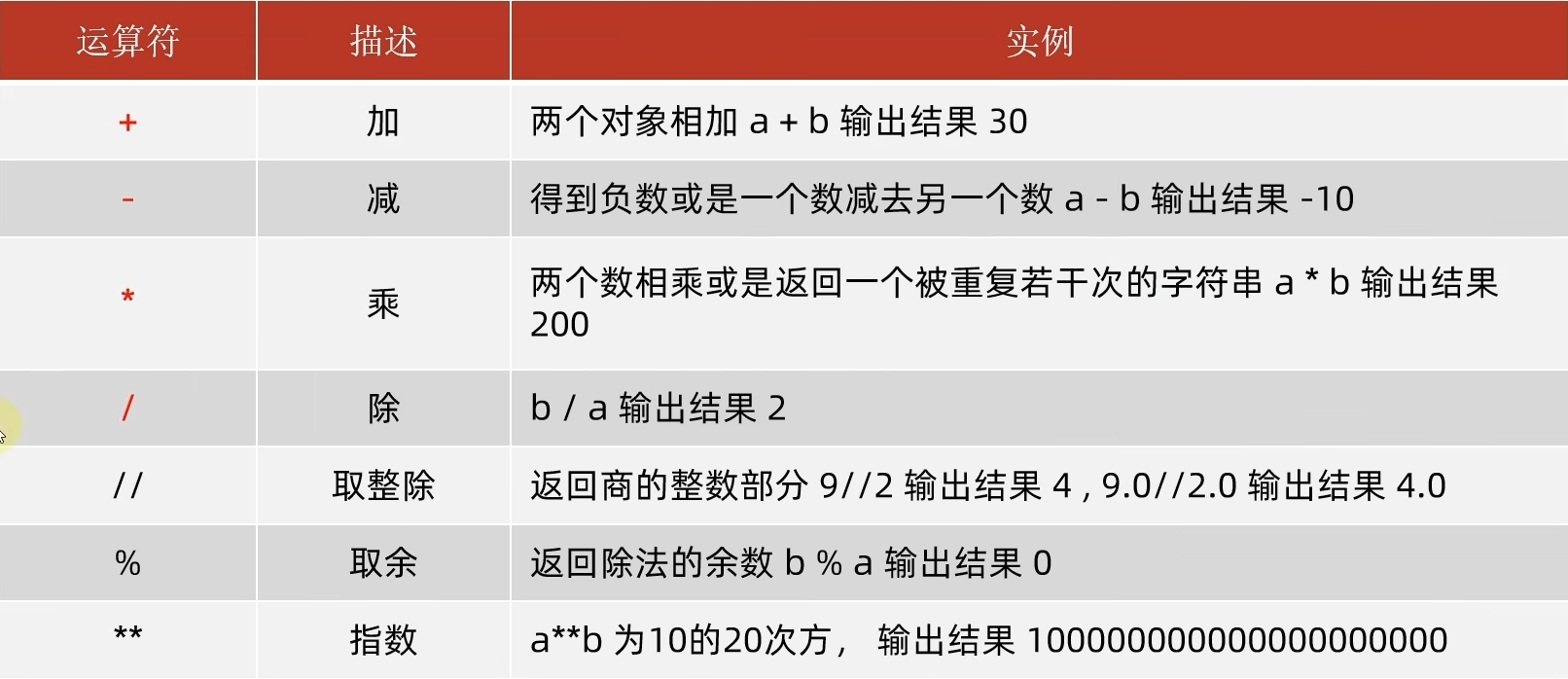
列:
# 算数(数学)运算符
print(11//2) #结果:5
print(2 ** 2) #结果:4
②复合赋值运算符
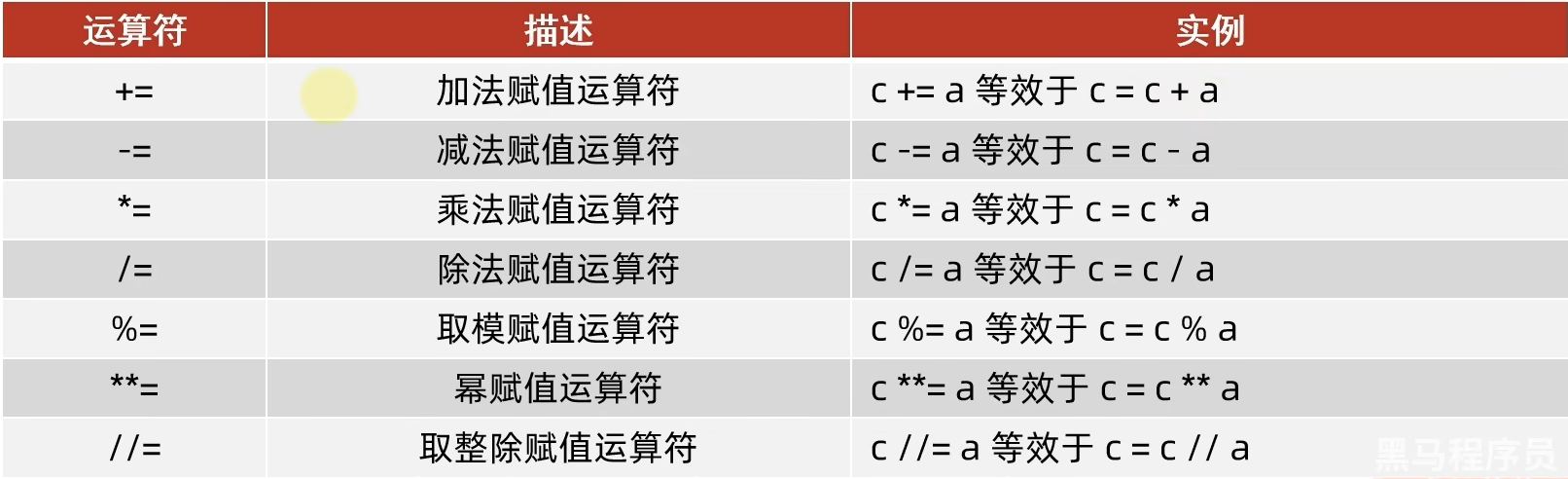
③比较运算符
9、字符串
①字符串的定义
# 单引号定义法
name = '湖南汽车工程学院'
# 双引号定义法
name = "湖南汽车工程学院"
# 三引号定义法 ,结果:换行的湖南\t汽车\t工程
name ="""
湖南
汽车
工程
"""
②转义字符
# 在字符串内包含双引号
name='"大胖子"'
# 在字符串中包含单引号
name = "'大胖子'"
# 使用转义字符\ 转义引号
name = "\"萝卜头"
③字符串的拼接
使用 + 号拼接,在python中字符串没法通过 + 号和整数、浮点数拼接,java中可以
name ="大胖子"
address="株洲市"
number_one=110
print("我是:"+name+",地址:"+address+",电话:"+number_one) # 打印会报错
占位拼接%s
可以做精度控制
- %表示:我要占位
- s表示:将变量变成字符串放入占位的地方
name ="大胖子"
address="株洲市"
number_one=110
ttt="我是:%s,地址:%s,电话:%s" % (name,address,number_one)
print(ttt) # 结果:我是:大胖子,地址:株洲市,电话:110

快速占位符f"{占位}"
不可以做精度控制
name ="大胖子"
address="株洲市"
number_one=110
print(f"我是:{name},地址:{address},电话:{number_one}") # 结果:我是:大胖子,地址:株洲市,电话:110
④数字精度控制
**m.n **:列:%5d
- m.控制宽度,要求是数字,设置的宽度小于数字自身不生效
- n,控制小数点精度,要求是数字,会对小数进行四舍五入
num2=11.242
print("%5d" % num2) # 宽度限制5 结果:11
print("%7.2" % num2) #宽度限制7 ,小数精度2 结果:11.35
print("%.2" % num2) #宽度不限制,小数精度2 结果:11.35
⑤股价计算小程序

答案:
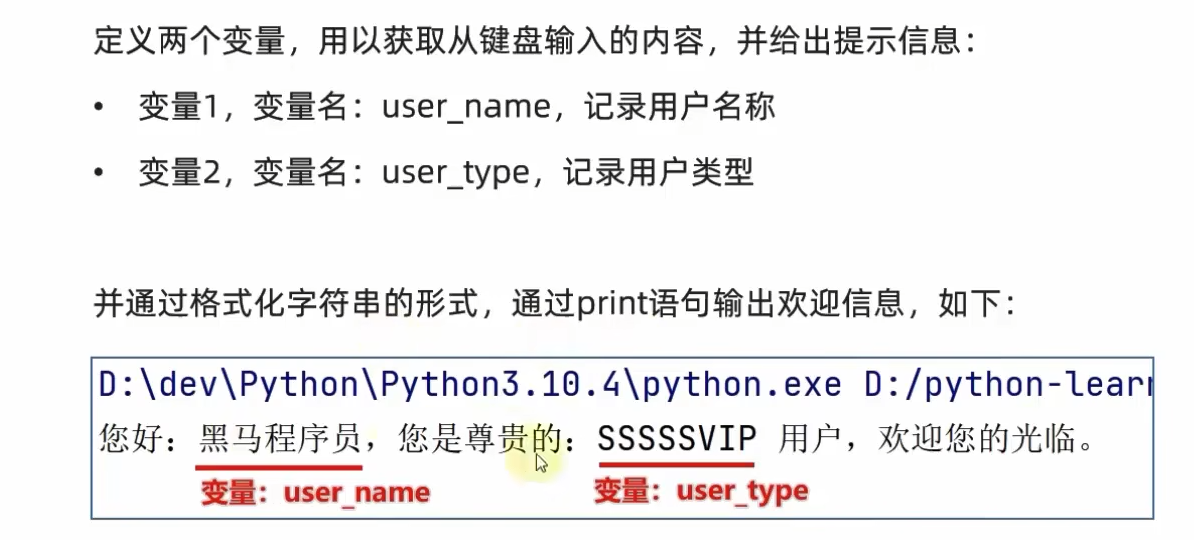
10、键盘录入
①input函数
**说明:**不管输入的什么数据,全部当作String(str)类型数据
print("您是谁")
name = input() # 键盘录入
print("我知道了您是:%s" % name)
优化:与如上代码效果一样
name = input("您是谁") # 括号里内容会优先执行
print("我知道了您是:%s" % name)
②欢迎登录小程序
三、判断语句
① if 判断语句
-
基本格式
age =10 if age >=18: print("判断为true输出我") print("不管结果都会输出我") -
成人判断练习

② if else语句
- 基础语句
age = input("请输入您的年龄:")
if age >= 18:
print("您已成年,请买票进入")
else:
print("您未成年,可以免费游玩")
-
进阶语句
age = input("请输入您的年龄:") if age >= 18: print("您已成年,请买票进入") # 判断为ture输出 else: print("您未成年,可以免费游玩") # 判断为false输出 print("不管结果都会输出我")
③if elif else 语句
- **双if **
age = input("请输入您的年龄:")
if age >= 18:
print("您已成年,请买票进入") # 判断为ture输出
elif day<18:
print("您未成年,可以免费游玩") # 判断为false输出
else:
print("")
print("不管结果都会输出我")
-
练习,猜猜心里数字
-
 猜数字
猜数字

四、循环语句
**序列:**其内容可以一个一个依次取出的一种类型,如:字符串、列表、元组
**作用域:**循环内定义的变量,循环外是可以访问到的,不建议
1、while循环
i=0
while i < 5:
print("萝卜头")
i += 1
-
练习:求1-100的和

-
嵌套
i =1
while i <= 100:
print(f"今天是第{i}天,准备表白...")
j = 1
while j <= 10:
print(f"送给小美第{j}支玫瑰")
j+=1
print("小美,我喜欢你")
i += 1
print(f"坚持到第{i-1}天, 表白成功")
- 练习:打印九九乘法表

- 死循环
while True:
break
2、for循环
**说明:**for是将待处理数据集(序列)的数据一个一个赋值给临时变量
for 临时变量 in 待处理数据集:
循环满足条件时执行的代码
- 列:
# 定义字符串
name="hnqczy"
# for循环处理字符串
for x in name:
print(x) # 结果:把字符串的字母一个一个打印出来
- 练习:数一数有几个a

- for循环嵌套
i =0
for i in range(1,101):
print(f"今天是向小美表白第{i}天,加油坚持。")
# 内层嵌套
for y in range(1,11):
print(f"送给小美的第{i}朵玫瑰花")
print("小美我喜欢你")
print(f"第{i}天,表白成功")
3、range语句
range (序列)
range (序列始,序列末) # 默认步长为1
range (序列始,序列末,步长) # 步长既数列间隔
- 列
for x in range(10):
print(x) # 结果: 1 ~ 8 9
for y in range(5,10): # 从5开始,10结束(不包含10)的一个数字序列
print(y) # 结果:5 6 7 8 9
for z in range(5,10,2): # 从5开始,10结束,步长为2
print(z) # 结果:5 7 9
4、continue关键字
**作用:**中断本次循环,直接进入下次学习
for y in range(1,6):
print("语句1")
for j in range(1,6):
print("语句2")
continue
print("语句3")
print("语句4")
5、break 关键字
**作用:**直接结束循环
for y in range(1,6):
print("语句1")
break
print("语句2")
print("语句3") # 结果:只会打印 语句1 和 语句3
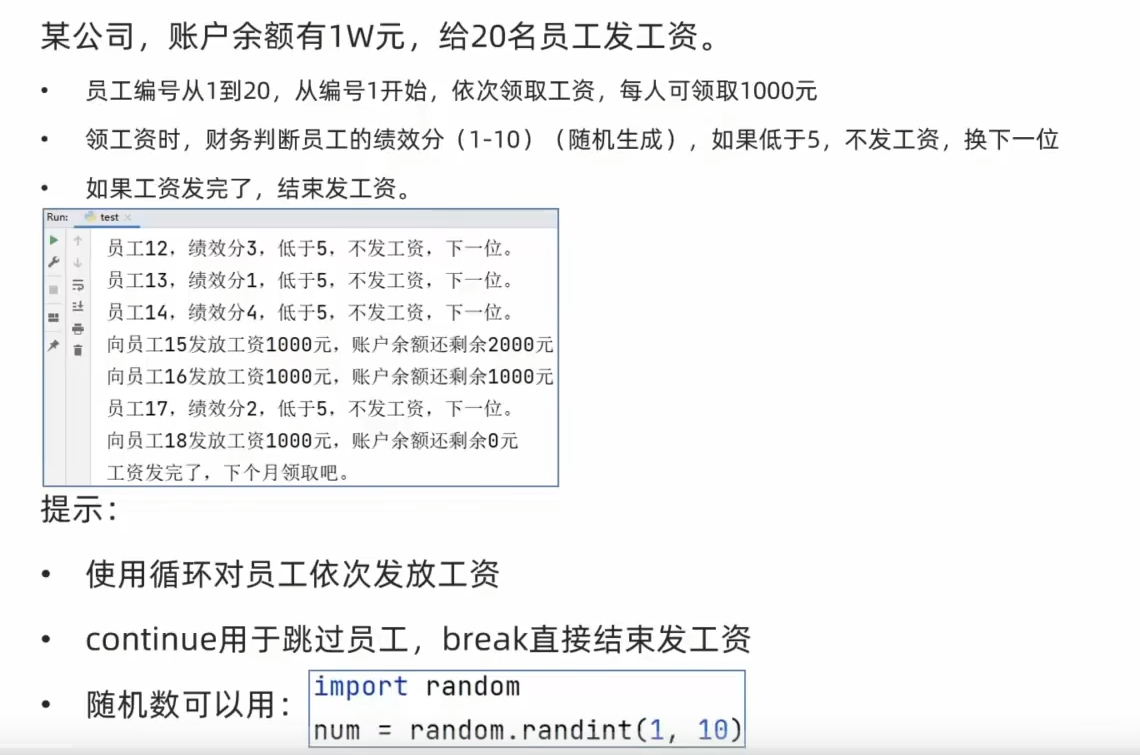
6、练习:发工资
7、for和while区别

五、函数
**说明:**是组织好的并提前写好,可重复使用的代码段,如java中的方法
1、格式及使用
- 格式
def 函数名(参数): # 可以无参,也可以多个参数
函数体
return 返回值
- 调用
函数名(传入参数)
- 列
s1="大胖子"
s2="萝卜头"
def main(data):
count = 0
for i in date:
count += 1
print(f"字符串{data}的长度是{count}")
main(s1)
mian(s2)
2、返回值
每个函数都有返回值,如果不使用return定义返回值,则函数默认返回None
①return关键字
def 函数名(参数):
函数体
return 返回值 # 此返回值既是调用该方法的返回值,可以用变量接收
- 使用变量接收返回值
def add(a,b):
long = a + b
return x
y = add (5,6) # 带参调用add函数方法并使用变量y接收返回值
②None类型
**说明:**表该函数没有返回实际意义的返回值,相当于false可以在判断语句中使用,如java中null
- 利用None类型实现双重判断
# 定义函数
def number(age):
if age > 18:
return:"有返回值"
else:
return None
# 调用函数
x = number(16)
if not x:
print("未成年")
- 声明无初始内容
name = None
3、函数说明
帮助更好的理解函数
def func(x,y):
"""
函数说明
:param x:参数x的说明
:param y:参数y的说明
:return: 返回值的说明
"""
函数体
return 返回值
- :param 用于解释参数
- :return 用于解释返回值
4、变量
**局部变量:**在函数内定义的变量,只在函数内生效
**全局变量:**在函数外定义的变量,所有函数都可以访问
①global关键字
**作用:**在函数内修改全局变量值
num =200
def a():
global num # 设置内部定义的变量为全局变量
num = 500
print(f"test_b:{num}")
print(num)
5、综合案例:ATM机
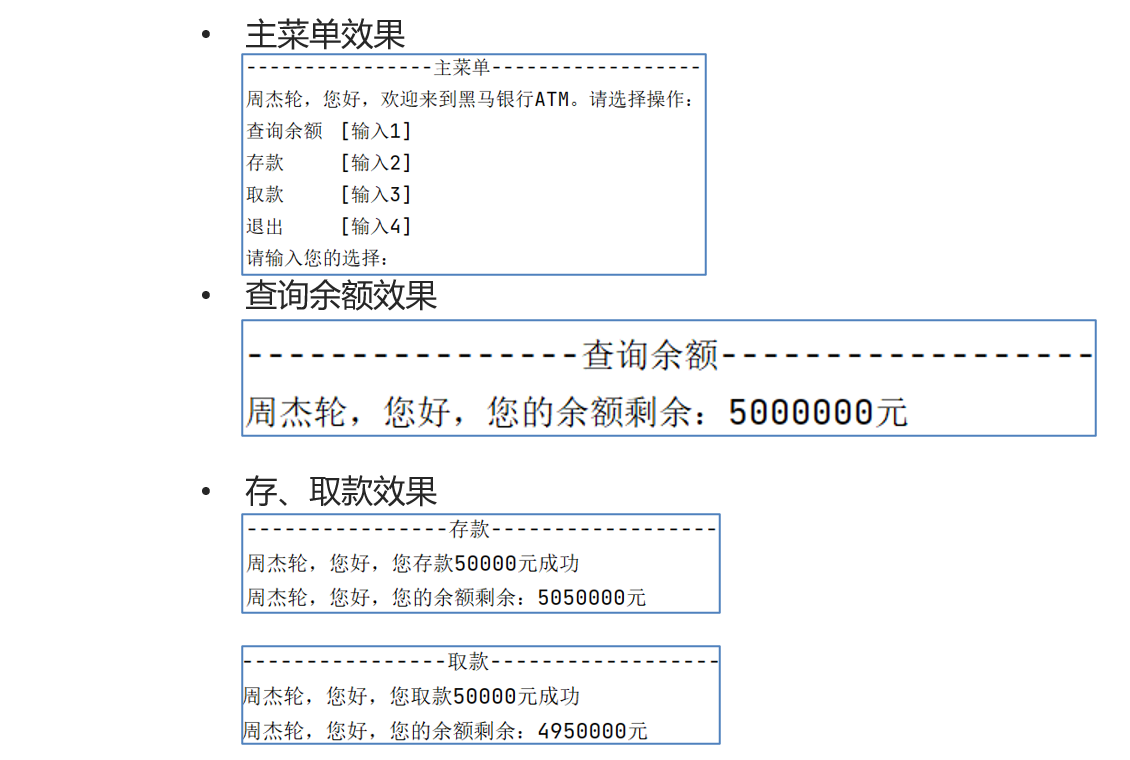
要求:

6、方法
**说明:**将函数定义为类class的成员时,函数称之为方法
- self:方法特有关键字,不是参数
class Student:
def add(self,x,y)
return x+y
- 方法使用
Student = Student() # 获取类
num = Student.add(1,2) # 使用类调用方法
六、数据容器
**概念:**一种可以存储多个元素的Python数据类型
python数据容器:list(列表)、tuple(元组)、str(字符串)、set(集合)、dict(字典)
1、list列表
①定义列表
**语法:**列表名 = [元素一,元素二,元素三]
**下标索引:**从0开始,也可以反向索引-1开始(-1代表最后一个),有索引越界
- 嵌套列表
list1 = [[1,"大胖子"],[2,"萝卜头"]]
print(list1[0][1]) # 输出大胖子
print(list1[1][0]) # 输出2
print(list1[-2][-1]) # 输出大胖子
print(list1[-1][-2]) # 输出2
②查找元素
- 通过元素查找下标索引
接收变量 = 列表名.index("元素值")
- 指定元素,统计元素在列表内数量
接收变量 = 列表名.count("元素值")
- 统计列表元素数量
接收变量 = len(列表名)
②修改元素
- 通过下标修改指定元素
列表名.insert(索引,"新元素值")
③添加元素
- 在列表尾部追加单个新元素
列表名.append("大胖子")
- 在列表尾部追加多个新元素(一个列表)
新列表名 =[元素1,元素2,元素3]
列表名.extend(新列表名)
④删除
- 指定下标索引删除元素
del 列表名[索引]
# 接收变量会收到被删除的变量
接收变量 = 列表名.pop(索引)
- 指定元素删除
mylist=["my","my","me","i"]
mylist.remove("my") # 如果元素有重复只会删除前面(索引小)的 一个
print(mylist) # 结果:["my","me","i"]
- 清空列表
列表名.clear()
⑤练习:列表常用功能练习

⑥遍历列表
- while循环遍历
my_list = ["大胖子", "萝卜头", "熊二"]
i = 0
while i < len(my_list):
print(my_list[i]) # 通过下标获取索引
i += 1
- for循环遍历
my_list = [1,2,3,8,9]
for i in my_list:
print(i)
2、tuple元组
元组一旦定义完成,就不可修改,数据不能被篡改,但元组内部的list内容可以被改变
①定义元组
元组名 = ("元素一","元素二")
元组名 = ()
元组名 = tuple()
- 测试
def my_tuple():
t1 = (1,"大胖子","萝卜头")
t2 = ()
t3 = tuple()
print(f"t1的类型是:{type(t1)},内容是:{t1}")
print(f"t2的类型是:{type(t2)},内容是:{t2}")
print(f"t3的类型是:{type(t3)},内容是:{t3}")
- 结果
t1的类型是:<class 'tuple'>,内容是:(1, '大胖子', '萝卜头')
t2的类型是:<class 'tuple'>,内容是:()
t3的类型是:<class 'tuple'>,内容是:()
定义单个元组
- 定义单个元素如果后面不加逗号和空格,使用type()测试出来是为str字符串类型的
元组名 = ("元素一", )
元组的嵌套
元组名 = (("元素一","元素2"),("元素三","元素四"))
②获取元素
- 下标取出元素
接收变量 = 元组名[索引]
接收变量 = 嵌套元组名[元组1索引][元组2索引]
③ 获取下标
- index获取元素下标
接收变量 = 元组名.index("元素值")
④统计元素
- count统计元素在元组中数量
接收变量 = 变量名.count("元素值")
- len统计元组所有元素数量
接收变量 = len(元组名)
⑤修改内容
- 修改元组内部lst列表内容,元组内容不可以修改
t9 = (1,2,["大胖子","萝卜头"])
t9[2][0] = "胡图图"
print(t9)
⑥遍历元组
- while遍历元组
t8 = ("大胖子","萝卜头")
i =0
while i < len(t8):
print(f"元组元素有:{t8[i]}")
i += 1
- for循环遍历元组
t8 = ("大胖子","萝卜头")
for element in t8:
print(f"元组元素有:{element}")
⑦练习:元组的操作

3、str字符串
- 不可指定位置修改,只能换新字符串
①定义字符串
字符串名 = "胡图图和胡英俊"
②获取元素
-
索引取值
支持正反下标、一个字母、汉字为一个索引
字符串名[索引]
- split()分割字符串
返回值是list数组
my_str="i love you"
my_str_list = my_str.split("")
print(my_str_list) # 结果:["i","love","you"]
③获取下标
- index()元素获取下标
索引从0开始,返回值整数类型
my_str="i love you"
print(my_str.index("you")) # 结果:7
④修改内容
- replace()换新字符串、替换字符串
这个方法是直接换了个新的字符串而不是修改字符串内容
my_str="i love you"
print(my_str.replace("i","he")) # 结果:he love you
- strip()去字符串前后空格
my_str=" i love you "
print(my_str.strip()) # 结果:"i love you"
- 去除指定字符
my_str="去除i 去love 除you除去"
print(my_str.strip("去除")) # 结果:"i love you" ,原因:传入"去除"则字符串中'去'和'除'两个字眼全部去掉
⑤统计元素
- count()统计元素出现次数
my_str="i love you"
print(my_str.count("o")) # 结果:2
- 统计长度
my_str="i love you"
print(len(my_str)) # 结果: 10
⑥常用操作大全
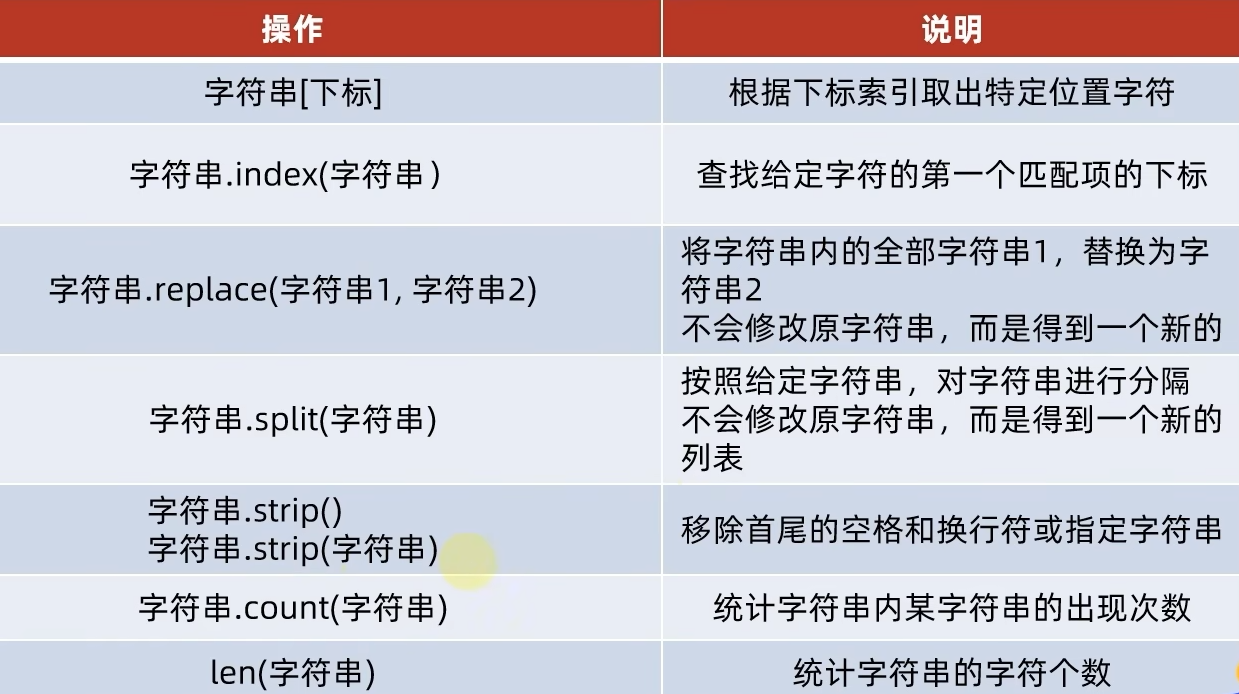
⑦练习:分割字符串

4、序列切片
**序列:**内容连续、有序、可使用下标索引的数据容器。列表、元组、字符串、均可以视为序列
**序列切片:**表示从序列种,从指定位置开始,依次取出元素,到指定位置结束,从而得到一个新序列
**格式:**序列名[ 起始索引:结束索引] # 步长默认为1,及数据间隔
- 起始索引1,结束索引3对序列切片,步长默认1
my_list = [0,1,2,3,4]
print(my_list[1:3]) # 结果:1 2
- 对所有元素切片,步长默认1
my_tuole = (0,1,2,3,4)
print(my_tuole[:]) # 结果:0 1 2 3 4
- 对所有元素切片,步长设置为2
my_str = "01234567"
print(my_str[::2]) # 结果:0 2 4 6
- 对所有元素切片,步长设置为-1
my_str = "0123"
print(my_str[::-1]) # 结果:3 2 1 0 ,等同对序列反转了,反向数
- 切片从3开始,1结束,步长-1
my_list = [0,1,2,3,4]
print(my_list[3:1:-1])
- 练习:序列切片

5、set集合
集合内元素不允许重复 且不支持下标索引
my_set = {"python","java","python"}
print(my_set) # 结果:{"python","java"},不允许重复
①语法
- 定义集合变量
变量名 = {元素一,元素二}
- 定义空集合
变量名 = set()
②修改
- add 添加新元素
语法:集合.add(元素)。将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素
my_set = set()
print(my_set("python")) # 结果:python
- 移除元素
语法:集合.remove(元素),将指定元素,从集合内移除
结果:集合本身被修改,移除了元素
my_set = {"python","java","python"}
print(my_set.remove("java")) # 结果:{"python"}
- 从集合中随机取出元素
语法:集合.pop(),功能,从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除
my_set = {"python","java","python"}
myset.pop()
- 清空集合
语法:集合.clear(),功能,清空集合
结果:集合本身被清空
- 取两集合的差集
语法:集合1.difference(集合2),功能:取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.difference(set2)
print(set1) # 结果:{2,3}
print(set2) # 结果:{1,2,3}
print(set3) # 结果:{1,5,6}
- 消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素。
结果:集合1被修改,集合2不变
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.difference_update(set2)
print(set1) # 结果:{2,3}
print(set2) # 结果: {1,5,6}
-
合并集合
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变
③集合长度
- len()统计集合长度
语法:len(集合)
功能:统计集合内有多少元素
结果:得到一个整数结果
set1 = {1,2,3}
print(len(set1)) # 结果:3
④集合遍历
集合不支持下标索引,不能使用while循环
- for循环遍历集合
my_set = {1,2,3,4}
for xxx in set1:
print(xxx,end='') # 结果:1234
⑤常用操作
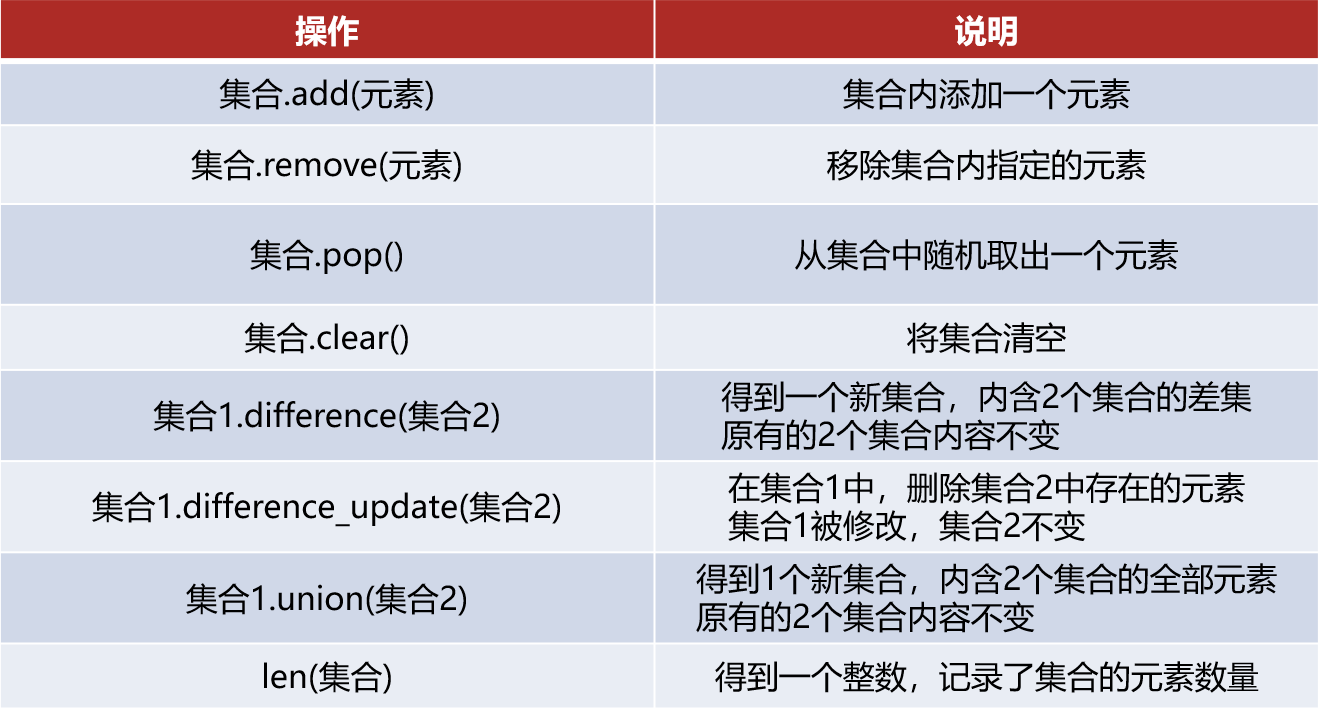
⑥集合特点
-
可以容纳多个数据
-
可以容纳不同类型的数据(混装)
-
数据是无序存储的(不支持下标索引)
-
不允许重复数据存在
-
可以修改(增加或删除元素等)
-
支持for循环
6、dict字典
键值对,如同java种Map集合,key和value可以为任意数据类型,key不能为字典
①定义
ddd = {"大胖子":99,"萝卜头":88}
- 定义空字典
my_dict2 = {}
my_dict3 = dict()
- 定义重复key
my_dict4 = {"大胖子":88,"大胖子":33}
print(my_dict4) # 结果:{"大胖子":33},后面的把前面的重复key覆盖掉了
- 字典嵌套
my_dict = {
"大胖子":{
"语文":77,
"数学":88
},
"萝卜头":{
"语文":88,
"数学":77
}
}
print(my_dict["大胖子"]["语文"]) # 结果 :77
②常用操作
- 基于key获取value
my_dict5 = {"大胖子":88,"大胖子":33}
print(my_dict["大胖子"]) # 结果:33
- 新增、更新元素
语法:字典名[Key] = Value,结果:字典被修改,新增了元素
ddd = {"大胖子":99,"萝卜头":88}
# 新增
ddd["胡图图"] = 66
# 更新
ddd[萝卜头] = 100
print(ddd) # 结果:{"大胖子":99,"萝卜头":100,"胡图图": 66}
- 删除元素
语法:字典.pop(Key),结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除
ddd = {"大胖子":99,"萝卜头":88}
print(ddd.pop("大胖子"))
- 清空字典
语法:字典.clear(),结果:字典被修改,元素被清空
ddd = {"大胖子":99,"萝卜头":88}
ddd.clear()
- 获取全部的key
语法:字典.keys(),结果:得到字典中的全部Key
ddd = {"大胖子":99,"萝卜头":88}
print(ddd.keys()) # 结果:['大胖子','萝卜头']
- 统计元素个数
语法:len(字典)
** 结果**:得到一个整数,表示字典内元素(键值对)的数量
ddd = {"大胖子":99,"萝卜头":88}
print(ddd.len()) # 结果:2
③遍历字典
- for循环遍历
方式一:通过获取key完成遍历
ddd = {"大胖子":99,"萝卜头":88}
keys = ddd.keys()
for key in keys:
print(f"字典的key是:{key}")
print(f"字典的value是:"ddd[keys])
方式二:直接循环字典,每一次循环直接得到key
ddd = {"大胖子":99,"萝卜头":88}
for key in ddd:
print(f"字典的key是:{key}")
print(f"字典的value是:"ddd[keys])
④总结
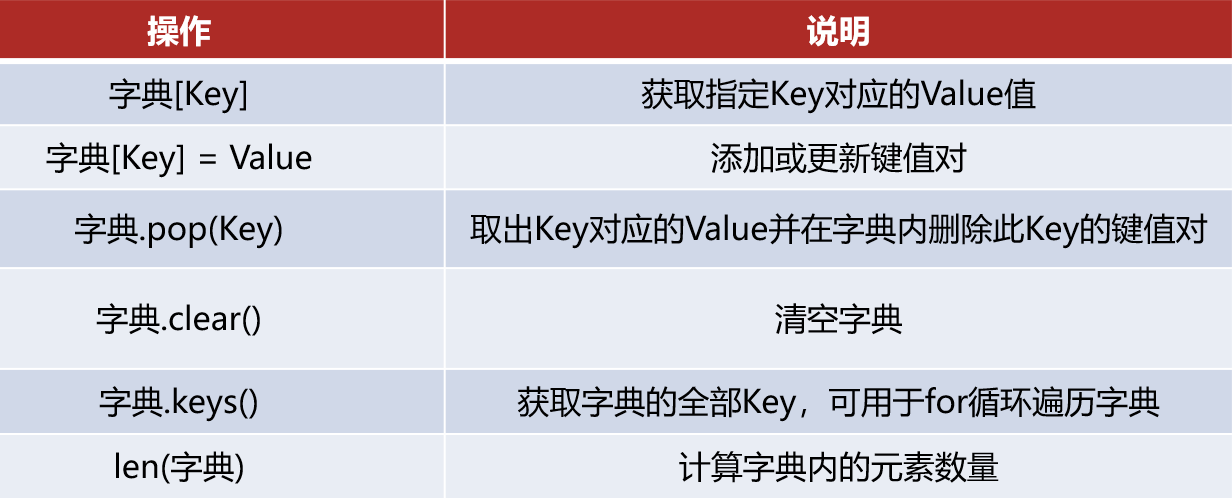
⑤特点
-
可以容纳多个数据
-
可以容纳不同类型的数据
-
每一份数据是KeyValue键值对
-
可以通过Key获取到Value,Key不可重复(重复会覆盖)
-
不支持下标索引
-
可以修改(增加或删除更新元素等)
-
支持for循环,不支持while循环
⑥练习:升值加薪
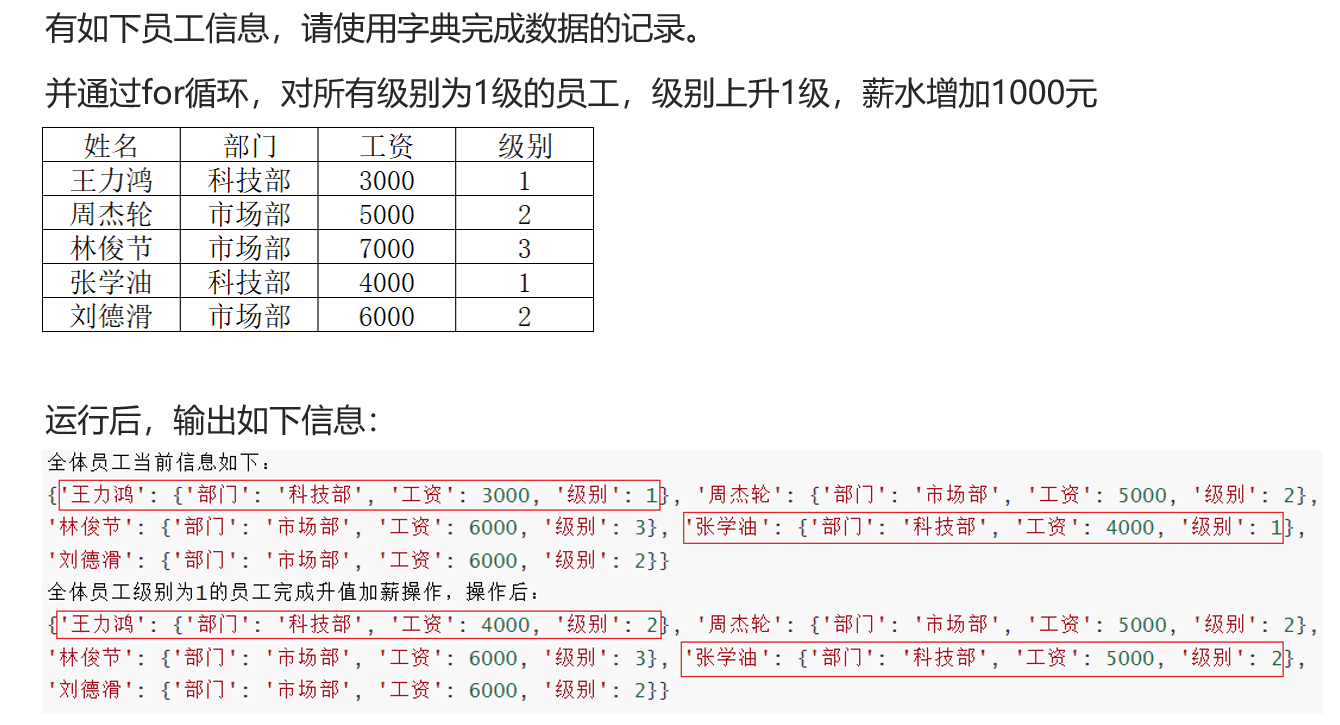
7、数据容器通用操作
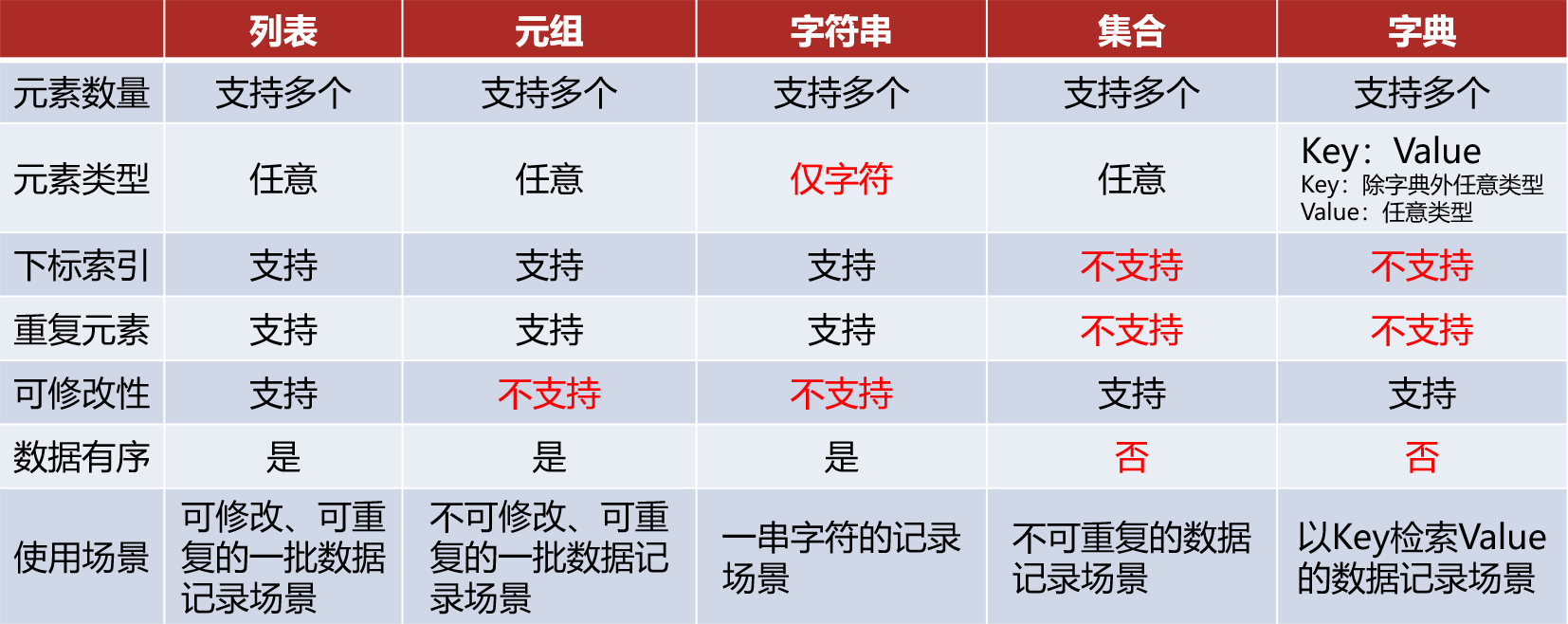
①数据容器分类
- 是否支持下标索引
-
支持:列表、元组、字符串序列类型
-
不支持:集合、字典、非序列类型
- 是否支持重复元素
-
支持:列表、元组、字符串序列类型
-
不支持:集合、字典、非序列类型
- 是否可以修改
-
支 持:列表、集合、字典
-
不支持:元组、字符串
②特点对比
③通用遍历
-
5类数据容器都支持for循环遍历
-
列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引)
-
尽管遍历的形式各有不同,但是,它们都支持遍历操作。
④通用统计
- max()统计容器最大元素
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"
print(max(my_list)) # 结果3
print(max(my_tuple)) # 结果5
print(max(my_str)) # 结果t
- min()统计容器最小元素
my_list = [1, 2, 3]
my_tuple = (1, 2, 3, 4, 5)
my_str = "itiheima"
print(min(my_list)) # 结果1
print(min(my_tuple)) # 结果1
print(min(my_str)) # 结果a
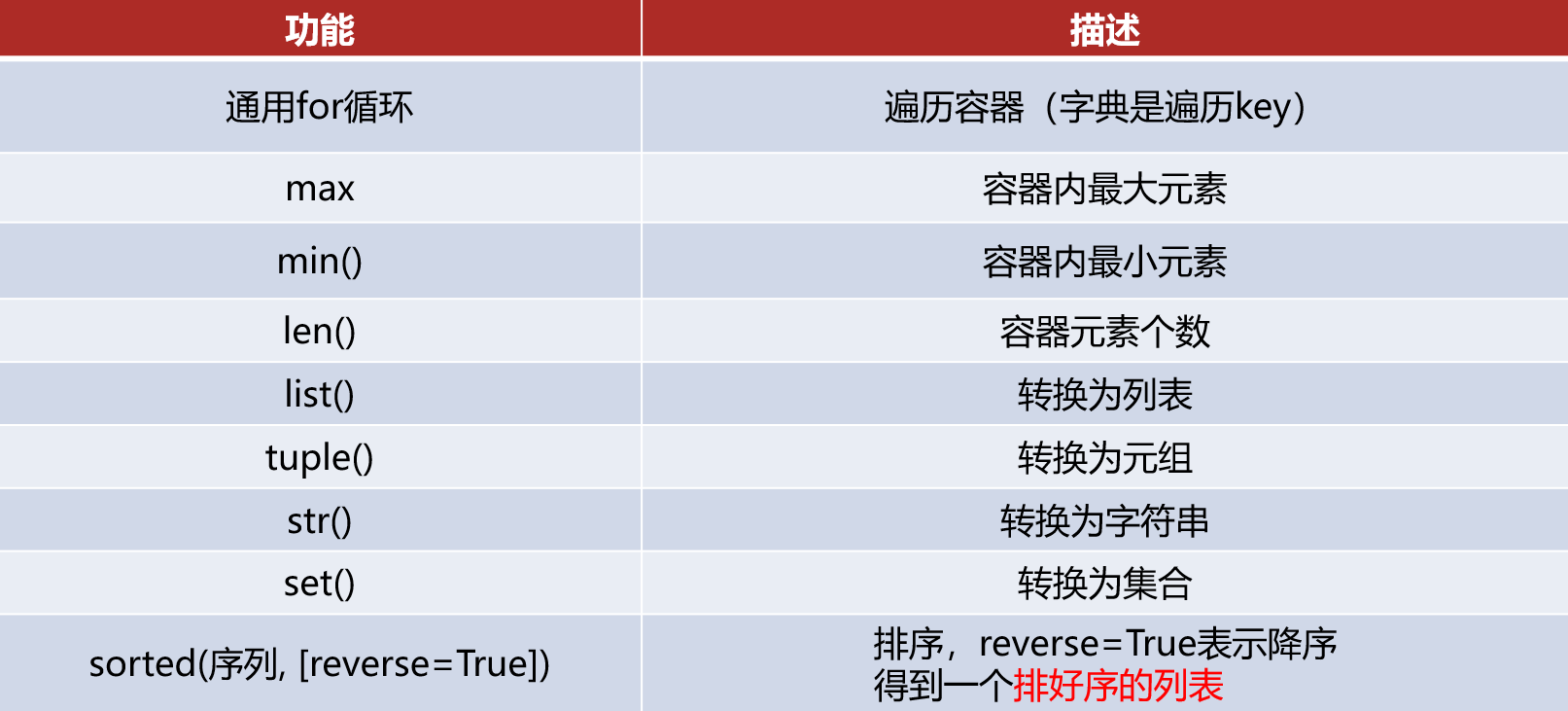
⑤转换功能
- list(容器)
将给定容器转换为列表
-
tuple(容器)
将给定容器转换为元组
-
str(容器)
将给定容器转换为字符串
-
set(容器)
将给定容器转换为集合
⑦排序功能
- sorted(容器, [reverse=True])
将给定容器进行排序
注意,排序后都会得到列表(list)对象。
⑧功能总结
8、字符串比较
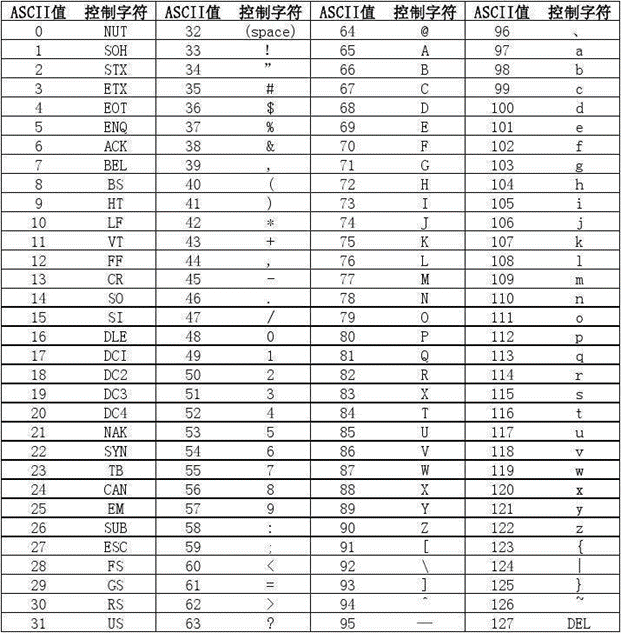
①ASCII编码
②字符串如何比较
从头到尾,一位位进行比较,其中一位大,后面就无需比较了。
③单个字符之间如何确定大小?
通过ASCII码表,确定字符对应的码值数字来确定大小
七、函数进阶
1、多返回值
def xxx():
return 1, 2,"胡图图"
x,y,z = xxx() # 结果:使用三个变量接收
print(x,y,z) # 结果:1 2 "胡图图"
2、多种传参方式
①位置参数
调用函数时根据函数定义的参数位置来传递参数,传参和定义的顺序及个数必须一致
def xxx(name,age,gender):
print(f"名字:{name},年龄:{age},性别:{gendeer}")
xxx("胡图图",3,"帅哥")
②关键字参数
**关键字参数:**函数调用时通过“键=值”形式传递参数.
作用: 可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求.
def xxx(name,age,gender):
print(f"名字:{name},年龄:{age},性别:{gendeer}")
# 关键字传参、可以不按顺序
xxx(name="胡图图",age="3",gender="男")
# 可以和位置参数混用,但位置参数必须在前且匹配参数顺序
xxx("胡英俊",gender="男",age="3")
③缺省参数
**缺省参数:**缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用).
作用:当调用函数时没有传递参数, 就会使用默认是用缺省参数对应的值.
**注意:**函数调用时,如果为缺省参数传值则修改默认参数值, 否则使用这个默认值
# 参数有默认值
def xxx(name,age,gender='男'):
print(f"名字:{name},年龄:{age},性别:{gendeer}")
xxx('大胖子',18)
xxx('小呆瓜',18,'女')
④不定长参数
**说明:**不定长参数也叫可变参数. 用于不确定调用的时候会传递多少个参数(不传参也可以)的场景.
**作用:**当调用函数时不确定参数个数时, 可以使用不定长参数,则可以传递任意个参数
- 位置传递形式,一个星号
注意:传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
def xxx(*args):
print(args)
xxx('胡图图') # 结果:('tom',)
xxx('胡图图',3) # 结果:('胡图图',3)
- 关键字传递形式,两个星号
注意:
参数是“键=值”形式的形式的情况下, 所有的“键=值”都会被kwargs接受, 同时会根据“键=值”组成字典.
def xxx(**kwargs):
print(kwargs)
xxx(name='大胖子',age=18,id=110) # 结果:{'name':'大胖子','age':18,'id':110}
⑤传参方式特点
Ⅰ、掌握位置参数
根据参数位置来传递参数
Ⅱ、掌握关键字参数
通过“键=值”形式传递参数,可以不限参数顺序
可以和位置参数混用,位置参数需在前
Ⅲ、掌握缺省参数
·不传递参数值时会使用默认的参数值
·默认值的参数必须定义在最后
Ⅳ、掌握不定长参数
· 位置不定长传递以*号标记一个形式参数,以元组的形式接受参数,形式参数一般命名为args
· 关键字不定长传递以**号标记一个形式参数,以字典的形式接受参数,形式参数一般命名为kwargs
3、匿名函数
①函数作为参数传递
如同java种递归
def xxx(yyy):
i = yyy(int(input()),int(input()))
print(i)
def yyy(x,y):
return x + y
xxx(yyy)
②lambda匿名函数
-
def关键字,可以定义带有名称的函数,有名称的函数,可以基于名称重复使用。
-
lambda关键字,可以定义匿名函数(无名称),无名称的匿名函数,只可临时使用一次。
-
匿名函数定义语法:
传入参数表示匿名函数的形式参数,如:x, y 表示接收2个形式参数
函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
lambda 传入参数:
函数体(一行代码)
- 列:
def xxx(com):
print(com(1,2)) # 结果:3
yyy(lambda x , y : x + y)
八、文件操作
1、文件的编码
①常见编码格式
- UTF-8:是目前全球通用的编码格式,除非有特殊需求,否则,一律以UTF-8格式进行文件编码即可。
- GBK:以前中文体系经常用
- Big5:繁体字编码
②进制转换
2、文件操作
①open()打开文件
- 语法
New_open = open(name, mode, encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读(r)、写入(w)、追加(a)等。
encoding:编码格式(推荐使用UTF-8)
**New_open:**open()函数的文件对象,对象是Python中一种特殊的数据类型,拥有属性和方法,可以使用对象.属性或对象.方法对其进行访问

- 测试代码:
New_open = open("D:/HelloWorld.txt","r",encoding="UTF-8")
print(Type(New_open)) # 结果:<class '_io.TextIOWrapper'>
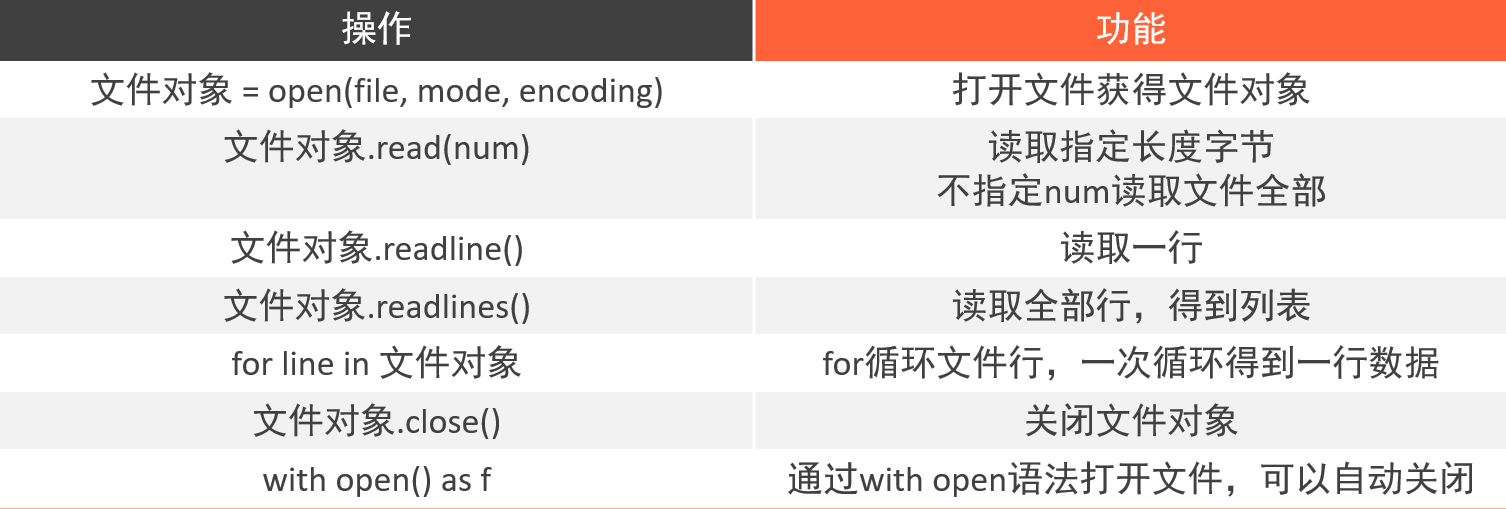
②读取文件
Ⅰ、read()读取文件
一次读取一个字节
文件对象.read(num)
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
测试代码:
New_open = open("D:/HelloWorld.txt","r",encoding="UTF-8")
print(New_open.read(10)) # 读取十个字节
Ⅱ、readlines()读取文件
读取文件全部行,封装到列表中。其中每行数据为一元素,\n表换行
测试代码:
f = open('D:/HelloWorld.txt')
content = f.readlines()
# ['hello world\n', 'abcdefg\n', 'aaa\n', 'bbb\n', 'ccc']
print(content)
# 关闭文件
f.close()
Ⅲ、readline()方法读取文件
每调用一次读取一行,与上个方法少了个s
Ⅳ、for循环读取文件
for line in open("Helloworld.txt", "r"):
print(line)
# 每一个line临时变量,就记录了文件的一行数据
Ⅴ、close()关闭文件流
关闭文件流,则会使文件解除占用
f = open("python.txt", "r")
f.close()
Ⅵ、with open语法自动关闭文件流
在语法内操作文件,执行结束会自动关闭文件流
with open("python.txt", "r") as f:
f.readlines()
Ⅶ、读取文件操作总结
Ⅷ、练习:单词计数

③文件写入
Ⅰ、write()写数据
当没有该文件会自动创建
注意:
-
直接调用write(),内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
-
当调用flush()刷新流的时候,内容会真正写入文件
-
这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
-
文件如果不存在,使用”w”模式,会创建新文件
•文件如果存在,使用”w”模式,会将原有内容清空
测试代码:
New_open = ("D:/HelloWorld.txt","w",encoding=UTF-8)
New_open.write("您好世界") # 书写"您好世界"到文件中,如果没有该文件自动创建
New_open.flush() # 刷新流
New_open.close() # 关闭流
九、异常 模块与包
1、异常
①异常的捕获方法
Ⅰ、常规异常
语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码
测试代码:
# 尝试以`r`模式打开文件,如果文件不存在,则以`w`方式打开
try:
f = open('linux.txt', 'r')
except:
f = open('linux.txt', 'w')
Ⅱ、指定异常
语法:
try:
print(name)
except NameError as e:
print('name变量名称未定义错误')
注意:
-
如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。
-
一般try下方只放一行尝试执行的代码。
Ⅲ、捕获多个异常
测试代码:
try:
print(1/0)
except (NameError, ZeroDivisionError):
print('ZeroDivision错误...')
注意:
- 当捕获多个异常时,可以把要捕获的异常类型的名字,放到except 后,并使用元组的方式进行书写。
Ⅳ、捕获所有异常
语法:
try:
可能报错代码
except Exception as e: # Exception:异常类型
异常执行代码
Ⅴ、异常else
测试代码:
try:
print(1)
except Exception as e:
print(e)
else:
print('我是else,是没有异常的时候执行的代码')
Ⅵ、异常的finally
测试代码:
try:
f = open('test.txt', 'r')
except Exception as e:
f = open('test.txt', 'w')
else:
print('没有异常,真开心')
finally:
f.close()
②异常的传递
-
当所有函数都没有捕获异常的时候, 程序就会报错
-
异常可以不及时捕获

2、模块
①定义
- 是一个python文件,以,py结尾
模块作用:
- 当作工具包,调用模块实现模块内功能
②模块导入
使用模块需要先导入模块
语法:
[from 模块名] import [模块|类|变量|函数][as 别名]
Ⅰ、导入一个模块
# 导入时间模块
import time
# 让程序睡眠1秒(阻塞)
time.sleep(1) # 使用模块调用方法
Ⅱ、导入模块中指定方法
# 导入时间模块中的sleep方法
from time import sleep
# 让程序睡眠1秒(阻塞)
sleep(1)
sleep换成占位符 * 就可以导入模块中所有方法,调用方法不需要用模块名点方法。
Ⅲ、给导入的方法取别名
as定义别名
语法:
# 模块定义别名
import 模块名 as 别名
# 功能定义别名
from 模块名 import 功能 as 别名
测试代码:
# 模块别名
import time as tt
tt.sleep(2)
# 功能别名
from time import sleep as sl
sl(2)
③自定义模块
Ⅰ、_all_ 管理模块
- 如果一个模块文件中有
__all__变量,当使用from xxx import *导入时,只能导入这个列表中的元素
_all_ = ['test_A']
def test_A():
print("只能用我")
def test_B():
print("我没被管理,不能用")
④pip下载外部模块
Ⅰ、安装模块
语法:
pip install 模块名
列:
Ⅱ、卸载模块
语法:
pip uninstall 模块名
列:

3、包
- 本质是模块,文件夹(包)来管理模块
- 导入包了才能调用模块
Ⅰ、作用
当我们的模块文件越来越多时,包可以帮助我们管理这些模块, 包的作用就是包含多个模块,但包的本质依然是模块
Ⅱ、导入包
方法一:
# 导入包
import 包名.模块名
# 导入模块
包名.模块名.目标
方法二:
注意:
- __ all__ 针对的是 ’ from … import * ‘ 这种方式
对 ‘ import xxx ’ 这种方式无效
- 必须在改包的
__init__.py文件(每个python软件包都有的文件)中添加__all__ = ["包中可以用的模块名字"],控制允许导入的模块列表
from 包名 import *
模块名.目标
Ⅲ、第三方包
是非python官方的包,差不多就是拓展插件。
4、综合案例:自定义工具包

十、数据可视化
1、使用的技术
Echarts 是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可. 而 Python 是门富有表达力的语言,很适合用于数据处理. 当数据分析遇上数据可视化时pyecharts 诞生了
2、json数据格式
主要功能:
json就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互.
格式:
# json数据的格式可以是:
{"name":"admin","age":18}
# 也可以是:
[{"name":"admin","age":18},{"name":"root","age":16},{"name":"张三","age":20}]
3、json与python的数据转化:
# 导入json模块
import json
# 准备符合格式json格式要求的python数据
data = [{"name": "老王", "age": 16}, {"name": "张三", "age": 20}]
# 通过 json.dumps(data) 方法把python数据转化为了 json数据
data = json.dumps(data)
# 通过 json.loads(data) 方法把json数据转化为了 python数据
data = json.loads(data)
4、PyEcharts模块
- 如果想要做出数据可视化效果图, 可以借助pyecharts模块来完成
①安装PyEcharts框架模块
数据可视化技术,和百度的Echarts一同使用
官方文档:https://gallery.pyecharts.org/#/README
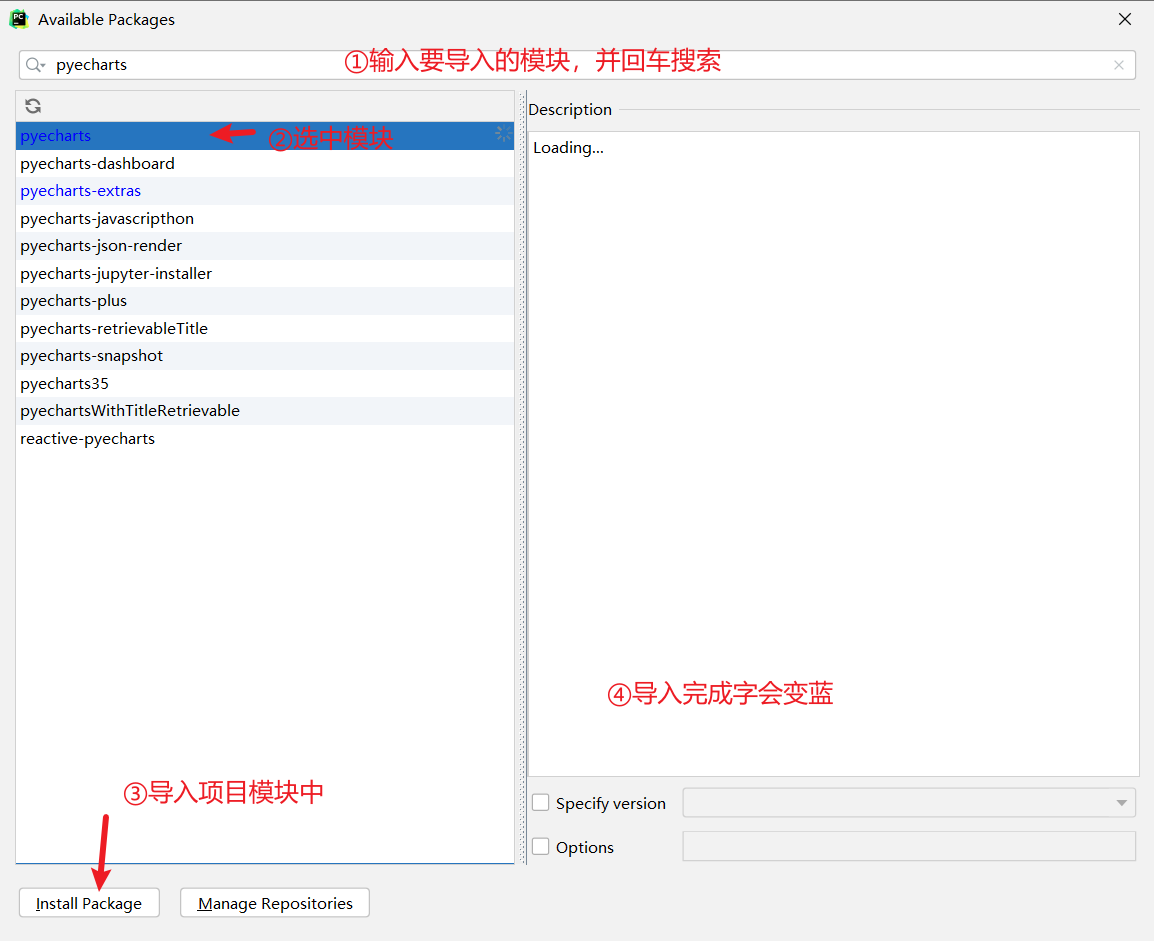
安装:
在windos的命令管理员黑框框直接输入
pip install pyecharts
列:
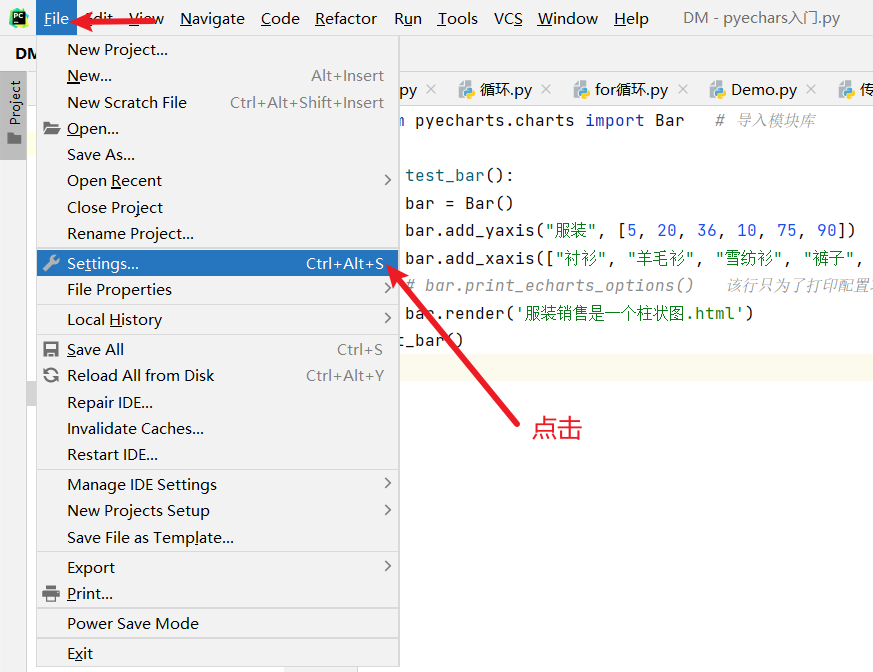
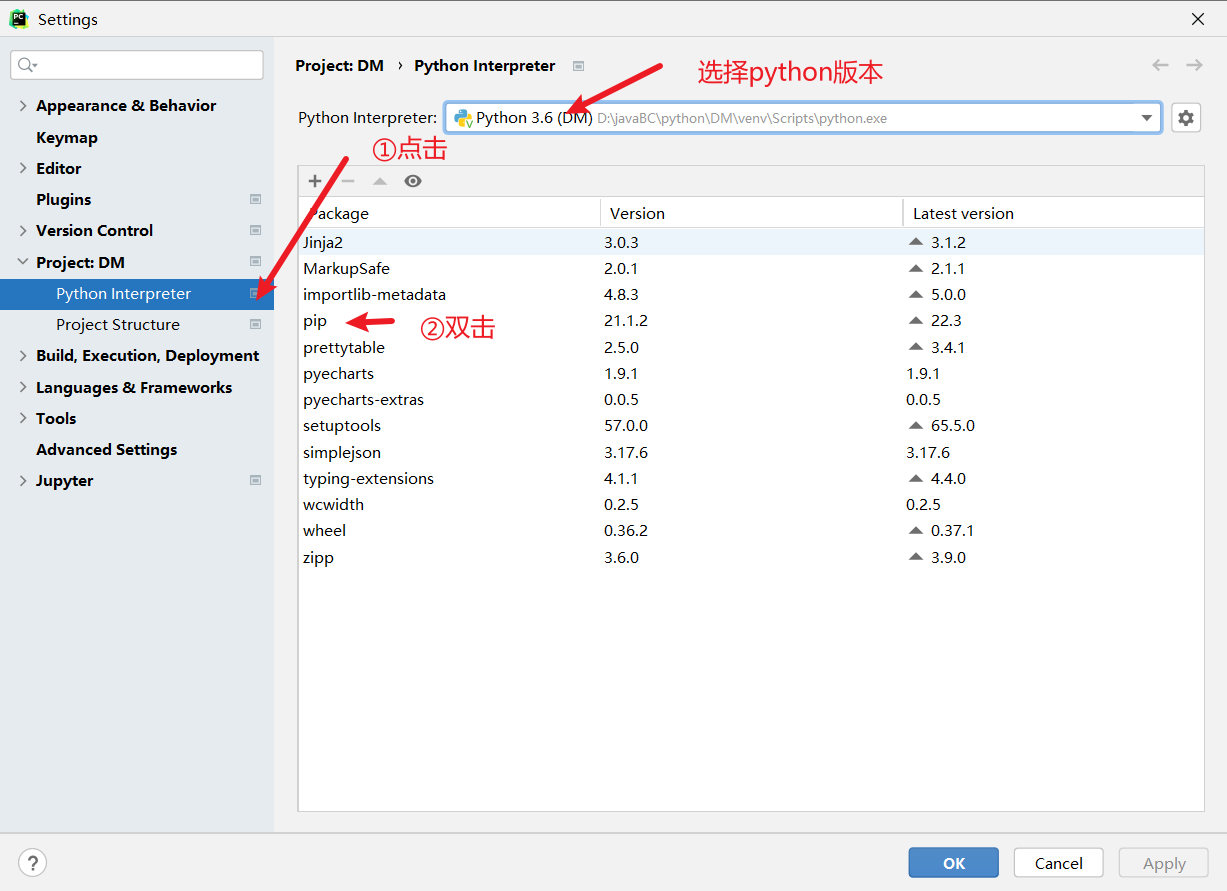
在PyCham中导入
- 设置
- 打开插件
- 导入需求模块
②折线图
Ⅰ、基础折线图快速入门
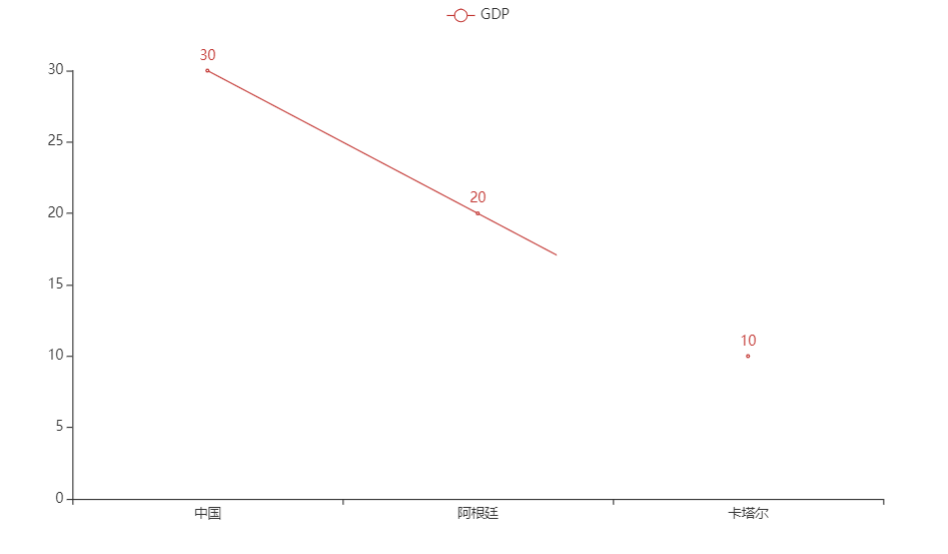
- 代码:
# 导包
from pyecharts.charts import Line
# 创建一个折线图对象
line = Line()
# 给折线图对象添加x轴的数据
line.add_xaxis(["中国", "阿根廷", "卡塔尔"])
# 给折线图对象添加y轴的数据
line.add_yaxis("GDP", [30, 20, 10])
# 通过render方法,将代码生成为图像
line.render("这里取生成文件名字.html")
- 生成文件:
Ⅱ、全局配置项
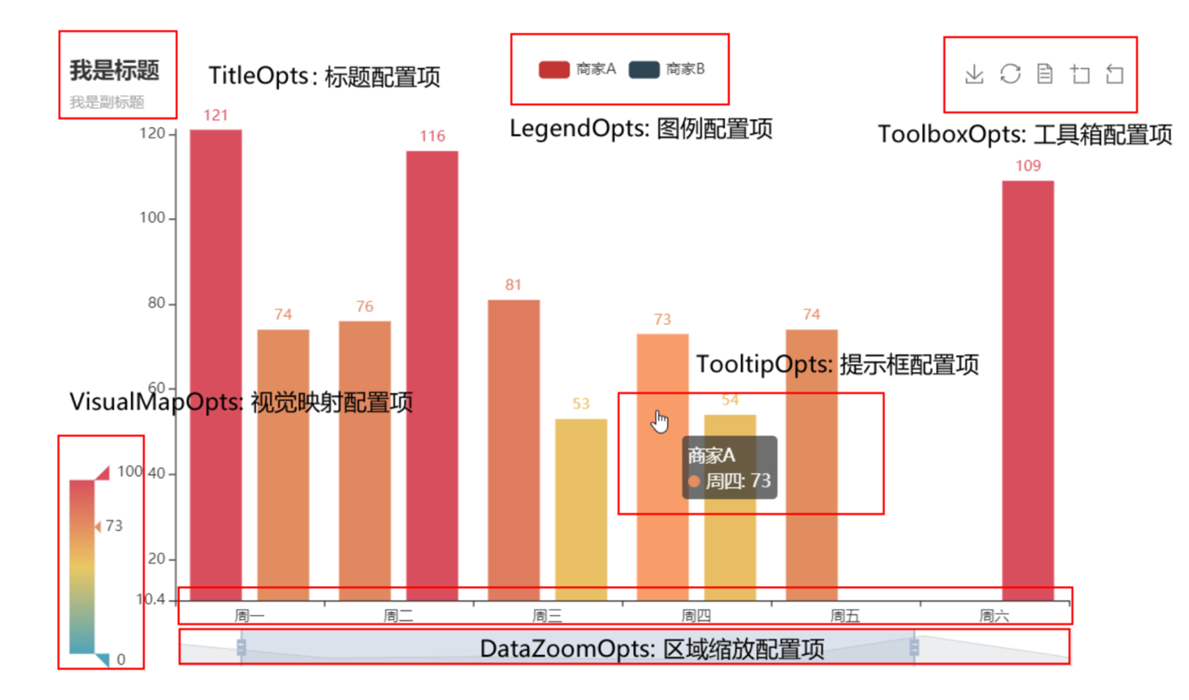
- set_global_opts方法进行配置
- 代码:
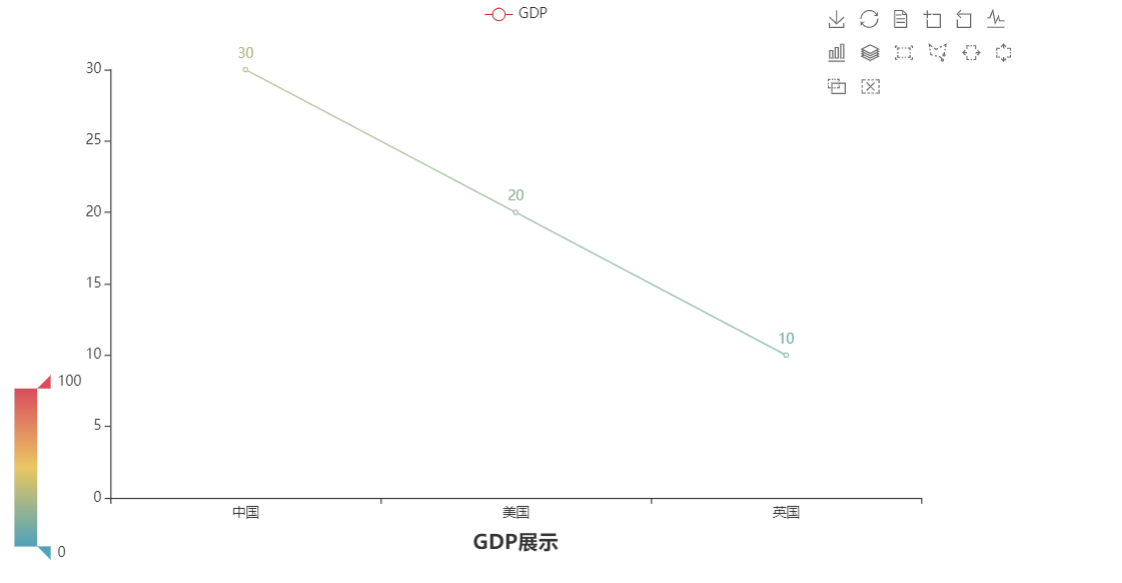
# 导包
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts # 全局配置项包
line = Line()# 创建一个折线图对象
line.add_xaxis(["中国", "美国", "英国"])# 给折线图对象添加x轴的数据
line.add_yaxis("GDP", [30, 20, 10])# 给折线图对象添加y轴的数据
# 设置全局配置项set_global_opts来设置,
line.set_global_opts(
title_opts=TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"),
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True),
)
line.render("全局配置项.html")# 通过render方法,将代码生成为图像
- 生成文件:
5、数据处理
- 原始数据格式

- 整理数据
import json # 导入Json模块
# 把不符合json数据格式的 "jsonp_1629350871167_29498(" 去掉
data = data.replace("jsonp_1629350871167_29498(", "")
# 把不符合json数据格式的 ");" 去掉
data = data[:-2]
# 数据格式符合json格式后,对数据进行转化
data = json.loads(data)
# 获取日本的疫情数据
data = data["data"][0]['trend’]
# x1_data存放日期数据
x1_data = data['updateDate’]
# y1_data存放人数数据
y1_data = data['list'][0]["data"]
# 获取2020年的数据
x1_data = data['updateDate'][:314]
# 获取2020年的数据
y1_data = data['list'][0]["data"][:314]
6、Line()疫情折线图
- 折线图相关配置

- .add_yaxis配置项
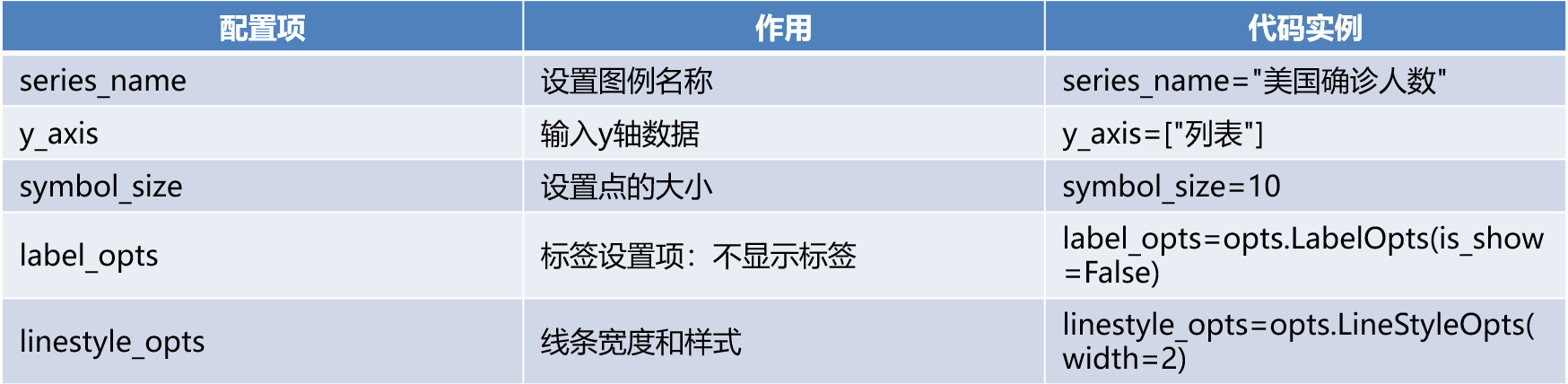
- .add_yaxis配置项

- .set_global_opts全局配置项
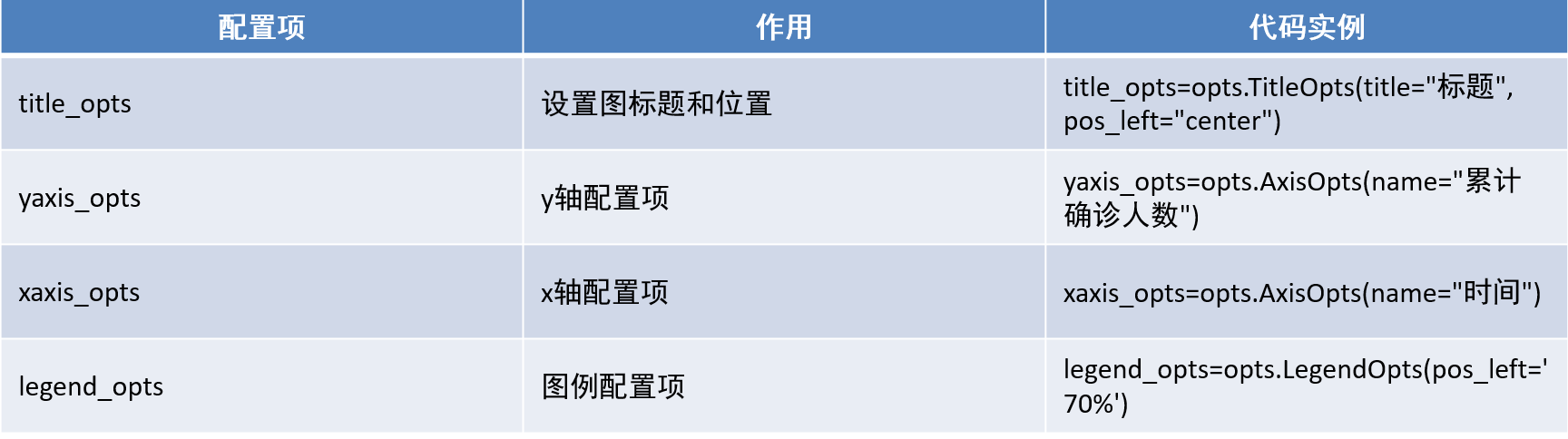
.set_global_opts(
# 设置图标题和位置
title_opts=opts.TitleOpts(title="2020年 印🇮🇳美🇺🇸日🇯🇵 累计确诊人数对比图",pos_left="center"),
# x轴配置项
xaxis_opts=opts.AxisOpts(name=“时间”), # 轴标题
# y轴配置项 ```
yaxis_opts=opts.AxisOpts(name=“累计确诊人数”), # 轴标题
# 图例配置项
legend_opts=opts.LegendOpts(pos_left=‘70%‘), # 图例的位置
)
- 文件:修改代码中注意路径,代码中是放到了D盘上
折线图:https://wwt.lanzouy.com/b03jgvkwh 密码:d0hu
- 代码:
"""
演示可视化需求1:折线图开发
"""
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts
# 处理数据
f_us = open("D:/美国.txt", "r", encoding="UTF-8")
us_data = f_us.read() # 美国的全部内容
f_jp = open("D:/日本.txt", "r", encoding="UTF-8")
jp_data = f_jp.read() # 日本的全部内容
f_in = open("D:/印度.txt", "r", encoding="UTF-8")
in_data = f_in.read() # 印度的全部内容
# 去掉不合JSON规范的开头
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
in_data = in_data.replace("jsonp_1629350745930_63180(", "")
# 去掉不合JSON规范的结尾
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]
# JSON转Python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']
# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]
# 获取确认数据,用于y轴,取2020年(到314下标结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]
# 生成图表
line = Line() # 构建折线图对象
# 添加x轴数据
line.add_xaxis(us_x_data) # x轴是公用的,所以使用一个国家的数据即可
# 添加y轴数据
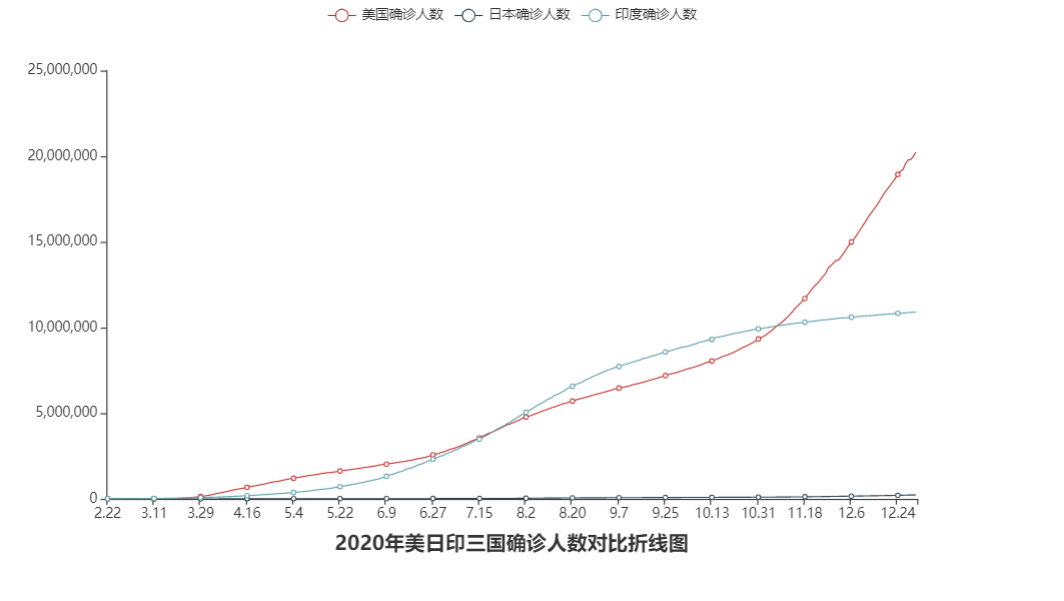
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 添加美国的y轴数据
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加日本的y轴数据
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据
# 设置全局选项
line.set_global_opts(
# 标题设置
title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%")
)
# 调用render方法,生成图表
line.render()
# 关闭文件对象
f_us.close()
f_jp.close()
f_in.close()
- 效果:
7、Map()地图可视化
- 文件:
疫情地图:https://wwt.lanzouy.com/b03jgvkyj 密码:6tqo
①、国内疫情地图
"""
演示全国疫情可视化地图开发
"""
import json
from pyecharts.charts import Map
from pyecharts.options import *
# 读取数据文件
f = open("D:/疫情.txt", "r", encoding="UTF-8")
data = f.read() # 全部数据
# 关闭文件
f.close()
# 取到各省数据
# 将字符串json转换为python的字典
data_dict = json.loads(data) # 基础数据字典
# 从字典中取出省份的数据
province_data_list = data_dict["areaTree"][0]["children"]
# 组装每个省份和确诊人数为元组,并各个省的数据都封装入列表内
data_list = [] # 绘图需要用的数据列表
for province_data in province_data_list:
province_name = province_data["name"] # 省份名称
province_confirm = province_data["total"]["confirm"] # 确诊人数
data_list.append((province_name, province_confirm))
# 创建地图对象
map = Map()
# 添加数据
map.add("各省份确诊人数", data_list, "china")
# 设置全局配置,定制分段的视觉映射
map.set_global_opts(
title_opts=TitleOpts(title="全国疫情地图"),
visualmap_opts=VisualMapOpts(
is_show=True, # 是否显示
is_piecewise=True, # 是否分段
pieces=[
{"min": 1, "max": 99, "lable": "1~99人", "color": "#CCFFFF"},
{"min": 100, "max": 999, "lable": "100~9999人", "color": "#FFFF99"},
{"min": 1000, "max": 4999, "lable": "1000~4999人", "color": "#FF9966"},
{"min": 5000, "max": 9999, "lable": "5000~99999人", "color": "#FF6666"},
{"min": 10000, "max": 99999, "lable": "10000~99999人", "color": "#CC3333"},
{"min": 100000, "lable": "100000+", "color": "#990033"},
]
)
)
# 绘图
map.render("全国疫情地图.html")
②、河南省疫情图
- 数据结构:

- 代码:
# 导入模块
import json
from pyecharts.charts import Map
from pyecharts.options import *
# 读取文件
f = open("D:/疫情.txt", "r", encoding="UTF-8")
data = f.read()
# 关闭文件
f.close()
# 获取河南省数据
# json数据转换为python字典
data_dict = json.loads(data)
# 取到河南省数据
cities_data = data_dict["areaTree"][0]["children"][3]["children"]
# 准备数据为元组并放入list,把各市数据汇总到一个列表
data_list = []
for city_data in cities_data:
city_name = city_data["name"] + "市"
city_confirm = city_data["total"]["confirm"]
data_list.append((city_name, city_confirm))
# 手动添加济源市的数据
data_list.append(("济源市", 5))
# 构建地图
map = Map()
map.add("河南省疫情分布", data_list, "河南")
# 视觉映射器,给严重省份加颜色
# 设置全局选项
map.set_global_opts(
title_opts=TitleOpts(title="河南省疫情地图"),
visualmap_opts=VisualMapOpts(
is_show=True, # 是否显示
is_piecewise=True, # 是否分段
pieces=[
{"min": 1, "max": 99, "lable": "1~99人", "color": "#CCFFFF"},
{"min": 100, "max": 999, "lable": "100~9999人", "color": "#FFFF99"},
{"min": 1000, "max": 4999, "lable": "1000~4999人", "color": "#FF9966"},
{"min": 5000, "max": 9999, "lable": "5000~99999人", "color": "#FF6666"},
{"min": 10000, "max": 99999, "lable": "10000~99999人", "color": "#CC3333"},
{"min": 100000, "lable": "100000+", "color": "#990033"},
]
)
)
# 绘图
map.render("河南省疫情地图.html")
8、bar()动态树状图
- 文件:
①基础柱状图
Ⅰ、代码:
# 导包
from pyecharts.charts import Bar
from pyecharts.options import LabelOpts
# 使用Bar构建基础柱状图
bar = Bar()
# 添加x轴的数据
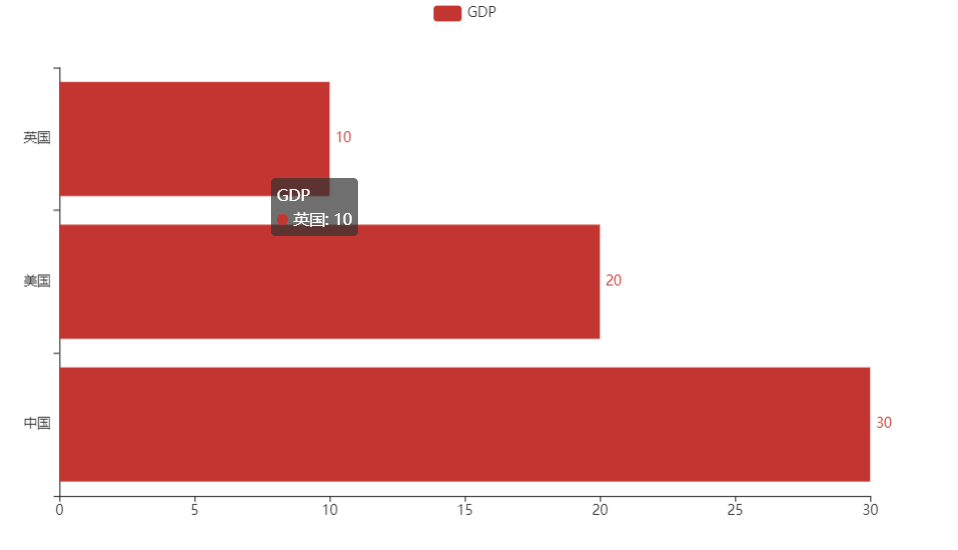
bar.add_xaxis(["中国", "阿根廷", "卡塔尔"])
# 添加y轴数据
bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))# 表数值标签在右侧
# 反转x和y轴
bar.reversal_axis() # 变成水平显示了,原来垂直显示
# 绘图
bar.render("基础柱状图.html")
Ⅱ、效果
Ⅲ、总结:
-
通过Bar()构建一个柱状图对象
-
和折线图一样,通过add_xaxis()和add_yaxis()添加x和y轴数据
-
通过柱状图对象的:reversal_axis(),反转x和y轴
-
通过label_opts=LabelOpts(position=“right”)设置数值标签在右侧显示
②基础时间柱状图
Ⅰ、Timeline()时间线
如果说一个BarLine对象是一张图表的话,时间线就是创建一个一维的x轴,轴上每一个点就是一个图表对象
- 时间线主题

Ⅱ、代码:
from pyecharts.charts import Bar, Timeline
from pyecharts.options import LabelOpts
from pyecharts.globals import ThemeType
bar1 = Bar()
bar1.add_xaxis(["中国", "阿根廷", "卡塔尔"])
bar1.add_yaxis("GDP", [30, 30, 20], label_opts=LabelOpts(position="right"))
bar1.reversal_axis()
bar2 = Bar()
bar2.add_xaxis(["中国", "阿根廷", "卡塔尔"])
bar2.add_yaxis("GDP", [50, 50, 50], label_opts=LabelOpts(position="right"))
bar2.reversal_axis()
bar3 = Bar()
bar3.add_xaxis(["中国", "阿根廷", "卡塔尔"])
bar3.add_yaxis("GDP", [70, 60, 60], label_opts=LabelOpts(position="right"))
bar3.reversal_axis()
# 构建时间线对象
timeline = Timeline({"theme": ThemeType.LIGHT})
# 在时间线内添加柱状图对象
timeline.add(bar1, "点1")
timeline.add(bar2, "点2")
timeline.add(bar3, "点3")
# 自动播放设置
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=True
)
# 绘图是用时间线对象绘图,而不是bar对象了
timeline.render("基础时间线柱状图.html")
③动态树状图
- 文件:
全球GDP数据:https://wwt.lanzouy.com/iNWtz0ea6c5i 密码:eihy
Ⅰ、列表的sort方法
- 使用方式:
- 列表.sort(key=选择排序依据的函数, reverse=True|False)
- 参数key,是要求传入一个函数,表示将列表的每一个元素都传入函数中,返回排序的依据
- 参数reverse,是否反转排序结果,True表示降序,False表示升序
- 使用:

- 匿名函数使用:

Ⅱ、效果:
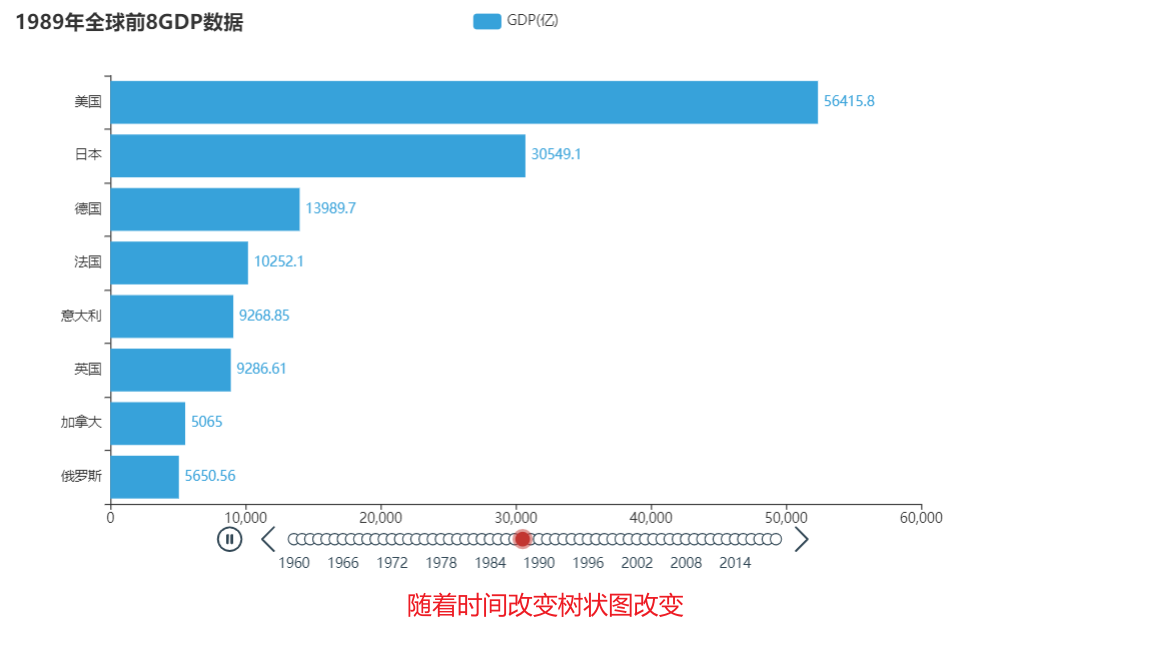
Ⅲ、代码:
# 导包
from pyecharts.charts import Bar, Timeline
from pyecharts.options import *
from pyecharts.globals import ThemeType
"""
处理数据
"""
# 读取数据
f = open("D:/1960-2019全球GDP数据.csv", "r", encoding="GB2312")
data_lines = f.readlines()
# 关闭文件
f.close()
# 删除第一条数据
data_lines.pop(0)
# 将数据转换为字典存储,格式为:
# { 年份: [ [国家, gdp], [国家,gdp], ...... ], 年份: [ [国家, gdp], [国家,gdp], ...... ], ...... }
# { 1960: [ [美国, 123], [中国,321], ...... ], 1961: [ [美国, 123], [中国,321], ...... ], ...... }
# 先定义一个字典对象
data_dict = {}
for line in data_lines:
year = int(line.split(",")[0]) # 年份
country = line.split(",")[1] # 国家
gdp = float(line.split(",")[2]) # gdp数据
# 如何判断字典里面有没有指定的key呢?
try:
data_dict[year].append([country, gdp])
except KeyError:
data_dict[year] = []
data_dict[year].append([country, gdp])
"""
创建时间线
"""
# print(data_dict[1960])
# 创建时间线对象
timeline = Timeline({"theme": ThemeType.LIGHT})
# 排序年份
sorted_year_list = sorted(data_dict.keys())
for year in sorted_year_list:
data_dict[year].sort(key=lambda element: element[1], reverse=True)
# 取出本年份前8名的国家
year_data = data_dict[year][0:8]
x_data = []
y_data = []
for country_gdp in year_data:
x_data.append(country_gdp[0]) # x轴添加国家
y_data.append(country_gdp[1] / 100000000) # y轴添加gdp数据
# 构建柱状图
bar = Bar()
x_data.reverse()
y_data.reverse()
bar.add_xaxis(x_data)
bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right"))
# 反转x轴和y轴
bar.reversal_axis()
# 设置每一年的图表的标题
bar.set_global_opts(
title_opts=TitleOpts(title=f"{year}年全球前8GDP数据")
)
timeline.add(bar, str(year))
# for循环每一年的数据,基于每一年的数据,创建每一年的bar对象
# 在for中,将每一年的bar对象添加到时间线中
# 设置时间线自动播放
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=False
)
# 绘图
timeline.render("1960-2019全球GDP前8国家.html")
十一、面向对象
1、类和对象
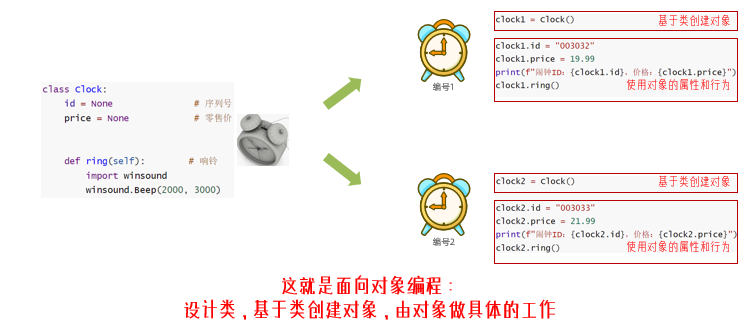
①基于类创建对象
②类和对象的使用
- 程序中设计表格,我们称之为:设置类(class)
class Student:
name = None # 记录学生姓名
- 程序中打印生产表格,称为:创建对象
# 基于上面创建的类创建对象
stu_1 = Student()
stu_2 = Student()
- 程序中填写表格,称为:对象属性赋值
# 基于上面创建的对象赋值
stu_1.name = "胡图图"
stu_2.name = "大胖子"
2、类的成员
①成员方法
类内部的方法称为成员方法,就是类里面的方法
- 定义成员方法
class Student: # 类
name = None # 成员变量
def xxx(self,参数1,参数二): # 成员方法,在方法内部访问成员变量必须0使用self
print(self.name) # 方法体
- 调用
class Student:
name = None
def xxx(self): # 传参时self是透明的不必理会
print("我是成员方法xxx")
def yyy(self,ms):
print(f"是谁在调用我?是:{ms}")
# 调用类中成员方法
stu = Student()
stu.xxx() # 调用方法
stu.yyy("胡图图") # 结果:是谁在调用我?是:胡图图
②成员变量
直接定义在类中的变量
- 调用
class Student: # 类
name = "萝卜头" # 成员变量
def xxx(self): # 成员方法,在方法内部访问成员变量必须0使用self
print(self.name) # 访问成员变量
# 调用成员方法
s = Student()
s.xxx()
③私有
Ⅰ、私有成员变量
隐藏在类里的变量,不给其他使用
- 定义:
- 变量名以 __ 开头(两个下划线)
class Student:
__old__ = 18 # 私有变量
Ⅱ、私有方法
- 定义:
- 方法名以__开头(两个下划线)
class Student:
def __xxx__(self): # 私有方法
print("hellowold")
3、构造方法
①__init()__ 内置方法给成员变量赋值
Ⅰ、作用
-
创建类时会自动执行
-
创建类时,将传入参数自动传递给
__init()__构造方法使用 -
需要使用self关键字
Ⅱ、使用
class Student:
# 因为可以在_init_中直接定义成员变量默认值为None
def __init__(self, name, age):
self.name = name
self.age = age
print(f"我被自动执行并赋值了,{self.name,self.age}")
stu = Student("胡图图", 3)
Ⅲ、练习:学生信息录入

4、内置方法
①__str__字符串方法
把类的地址值转换为字符串,如java中toString()方法
- 代码
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"Student类对象,name={self.name},age={self.age}"
s = Student("胡图图",3)
print(s) # 结果:Student类对象,name=胡图图,age=3
print(str(Student) # 结果:<class '__main__.Student'>
②__it__ < 和>比较
不可以直接比较对象,但实现__it__方法,即可同时完成:小于符号和大于符号的比较
- 代码
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __lt__(self, other):
return self.age < other.age
s1 = Student("胡图图",3)
s2 = Student("大胖子",18)
print(s1 < s2) # 结果:true
print(s1 > s2) # 结果:false
③__le__ <=和>=等于比较
- 代码:
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __le__(self, other):
return self.age <= other.age
s1 = Student("胡图图",3)
s2 = Student("大胖子",18)
print(s1 <= s2) # 结果:true
print(s1 >= s2) # 结果:false
④__eq__比较运算符
- 代码:
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, other):
return self.age == other.age
s1 = Student("胡图图",3)
s2 = Student("大胖子",18)
print(s1 == s2) # 结果:false
⑤总结

5、封装
①实现
将数据存放在私有成员变量的类中
②定义私有
③练习:设计带有私有成员的手机

6、继承
- 将从父类那里继承(复制)来成员变量和方法(不含私有),来给自己使用
①单继承
- 语法
calss 类名(父类名):
类内容体
②多继承
可以继承多个父类,多个父类有同名成员,按默认继承顺序为优先级
- 语法
class 类名(父类名1,父类名2):
类内容体
- 代码:
class Phone:
IMEI = None # 序列号
PRoducer = None # 厂商
def my_5g(self):
print("我可以支持5g通话")
class NFCReader:
nfc_type = "第五代"
producer = "大米"
def read_card(self):
print("读取NFC")
def write_card(self):
print("写入NFC卡")
class RemoteControl:
rc_type = "红外遥控"
def control(self):
print("红外遥控开启")
class MyPhone(Phone,NFCReader,RemoteControl):
pass
③复写
在子类修改父类的功能,如java中的重写。
- 代码
class Phone:
IMEI = None # 序列号
PRoducer = None # 厂商
def my_5g(self):
print("我可以支持5g通话")
class MyPhone(Phone):
proucer = "ITHEIMA" # 复写父类属性
def my_5g(self): # 复写父类方法
print("子类重写父类5g通话方法")
7、类型注释
伪装强类型语言
①注解类型
Ⅰ、注解中类型注解
var_1 = random.random(1,10) # type:int ,这里的int会高亮,并标记变量var_1为int类型
- 下面的了解即可
Ⅱ、变量注解
调用方法时有提示数据是什么类型,不影响变量类型,只是告诉PyCham工具变量的类型,方便书写
- 语法:
变量名:数据类型
- 代码
并赋值了
var_1: int = 10
var_2: str = "hnqcgc"
var_3: bool = True
Ⅲ、类的注解
class Student:
pass
stu: Student=Student()
Ⅳ、容器注解
- 基础
my_list = [1,2,3]
- 进阶
[]内数据顺序要对应,但后面可以使用Union解决
my_list: list[int]=[1,2,3] # 表这个list集合是int类型
my_tuple: tuple[str,int,bool]=("afas",32,Flase) # 表这个元组第一个数据是字符串,int,然后布朗
my_dict: dict[str,int] = {"胡图图",23}
②函数方法的类型注解
Ⅰ、参数类型注解
def add(x:int,y:int): # 对参数进行类型注解
return x + y
add() # ctrl+p可以查看类型注解,从而知道要传什么类型数据
Ⅱ、对返回值类型注解
def xxx(data) -> list: # 箭头后面表示返回值为list
return data
③Union类型
需导包
from typing import Union
my_list: list[Union[int,str]]=[1,2,"fsfs",3]
def xx(data: Union[int,str]) -> Union[int,str]:
pass
8、多态
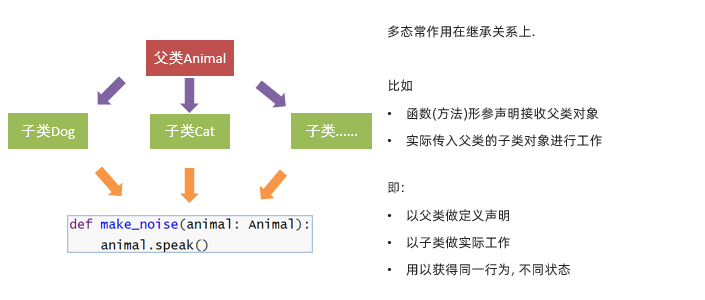
①多态的使用
②抽象类(接口)
pass关键字,没有被实现的类,如接口。要求子类必须实现的标准。
- 语法
class AC:
def xxx(self):
pass
③演示
class AC:
def xxx(self):
# 功能一
pass
def yyy(self):
# 功能二
pass
# 子类胡图图
class htt(AC):
def xxx(self):
print("胡图图实现了父类的方法一")
def yyy(self):
print("胡图图实现了方法二")
# 子类大胖子
class dpz(AC):
def xxx(self):
print("大胖子实现了父类的方法一")
def yyy(self):
print("大胖子实现了父类的方法二")
# 调用子类方法
"""d= dpz()
d.yyy()
h = htt()
h.xxx()"""
# 执行方法,多态的实现
def aaa(ac:AC):
ac.xxx()
# 获取子类对象
htt_A = htt()
dpz_B = dpz()
# 传哪个对象调用哪个子类的方法
aaa(htt_A)
aaa(dpz_B)
9、综合案例:数据分析
①需求
- 某公司有两份数据文件,用python计算每日销售额并以柱状图展示
②文件
-
数据: https://wwt.lanzouy.com/b03jh0prc 密码:g2ut
-
1月份数据是普通文本,使用逗号分割记录,从前到后是(日期,订单id,销售额,销售省份)
-
2月份数据是JSON数据,同样包含(日期,订单id,销售额,销售省份)
③需求分析
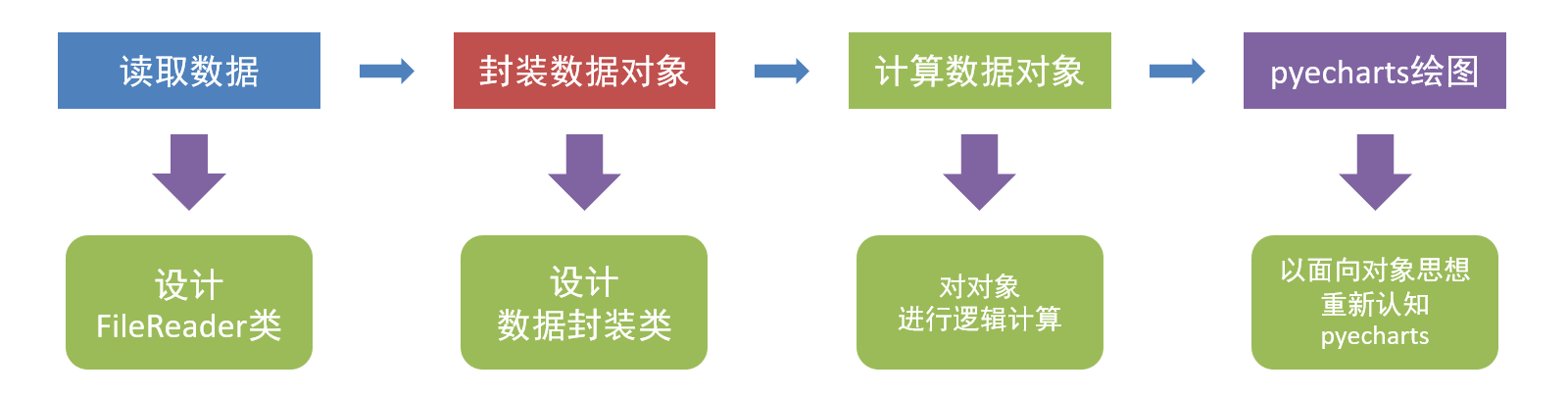
④代码
十二、SQL与Python
1、python整合mysql
①基础使用
windows命令员
Ⅰ、安装插件
pip install pymysql
- 效果
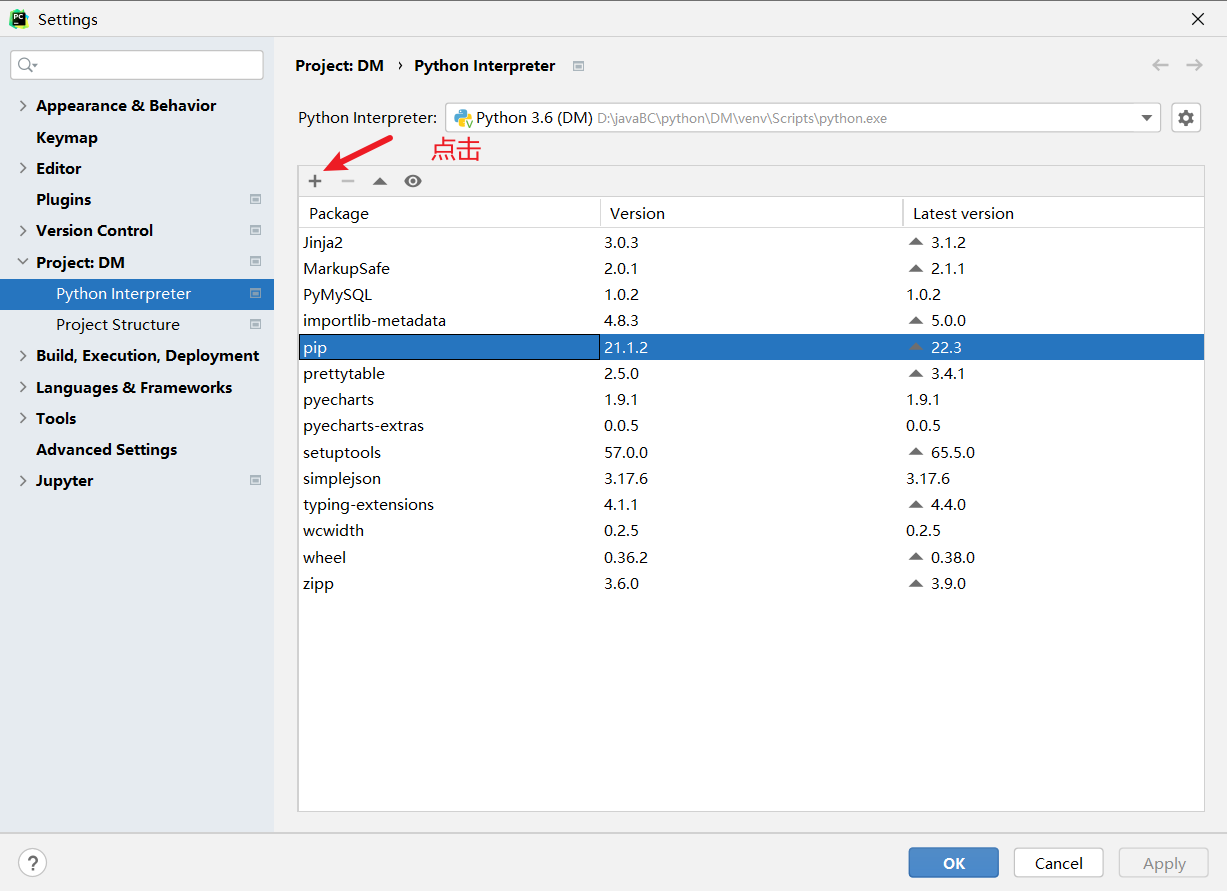
- PyCham集成PyMysql
Ⅱ、创建连接
- 使用Connection连接数据库
from pymysql import Connection
# 获取到mysql数据库连接
conn = Connection(
host='localhost',
port=3306,
user='root',
password='1234'
)
# 打印Mysql数据库软件信息a
print(conn.get_server_info())
conn.close()
Ⅲ、查询数据库
- 使用execute()查询数据库
from pymysql import Connection
# 获取到mysql数据库连接
conn = Connection(
host='localhost',
port=3306,
user='root',
password='1234'
)
# 获取游标对象
cursor = conn.cursor()
# 选择数据库,数据库名
conn.select_db("db1")
# 使用游标对象,执行sql语句
cursor.execute("SELECT * FROM tb_user")
# 获取查询结果
results = cursor.fetchall() # type:tuple
for r in results:
print(r)
# 关闭数据库连接
conn.close()
Ⅳ、插入数据
mysql数据库添加、修改、删除数据需要commit()提交事务
- 添加数据
数据库连接对象.commit() 提交事务,或者连接时设置自动提交
from pymysql import Connection
# 获取到mysql数据库连接
conn = Connection(
host='localhost',
port=3306,
user='root',
password='1234'
autocommit=True # 设置自动提交
)
# 获取游标对象
cursor = conn.cursor()
# 选择数据库,数据库名
conn.select_db("db1")
# 使用游标对象,执行sql语句
execute = cursor.execute("INSERT INTO tb_user VALUES(36,'小兔兔','aaa110110')")
# 提交事务
conn.commit()
# 获取查询结果
print(f"受影响行数:{execute}")
# 关闭数据库连接
conn.close()


















 9993
9993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









