







Python编程学习目录
Python代码学习笔记
本帖子是本人于2023年暑假期间在B站观看《黑马程序员python教程,8天python从入门到精通》,通过基于web的实时编译交互环境Jupyternotebook整理的Python学习笔记,大家可以根据黑马原视频对照学习。
一、基础阶段
print("hello world",end = " ")
print("hello world",end = " ")
# 不换行
print("hello world")
print("hello world")
print("hello world")
# shift + alt 列项选择并同时替换
print("hello world")
print("hello world")
# ctrl+d
name = "Mickey"
identity = " a good boy"
message = "一个叫%s的人是%s" % (name, identity)
print(message)
code = 123.456
print("最终结果为:%3.2f" % code)
name = "XXX大学"
set_year = 2023
print(f"我于{set_year}进入{name}就读")
print("请告诉我你是谁")
name = input()
print("我知道了!你是%s!" % name)
num = input("请告诉我你的编号")
print("你的编号类型是%s" % type(num))
# 选中后ctrl + / 一键注释
# ctrl + 鼠标左击:查看模块源文件
# ctrl + f:搜索
hello world hello world hello world
hello world
hello world
hello world
hello world
一个叫Mickey的人是 a good boy
最终结果为:123.46
我于2023进入XXX大学就读
请告诉我你是谁
Mickey
我知道了!你是Mickey!
请告诉我你的编号001
你的编号类型是<class 'str'>
二、数据容器类型
1. List
str1 = "万过薪月,员序程马黑来,nohtyp学"
str2 = str1[::-1]
# 首:尾:步长,左闭右开
# 步长为负表示倒序
print(str2)
str3 = str2.strip("月薪过万,学python")
str4 = str3.replace("来", "")
print(str4)
# 得到”来黑马程序员“
print("=====================================================================")
mylist = ['Mickey', 'Alan', 'Joke', 'Steven', 'Bob', ['Sally', 'Rose']]
print(mylist)
mylist.insert(1, ['Love', 'you'])
print(mylist)
mylist.append('Mickey')
# 尾部追加元素
mylist.extend([1, 2, 3])
# 尾部追加列表
print(mylist)
index = mylist.index('Bob')
print(f"Bob所在列表的index是:{index}")
del mylist[1][1]
print(mylist)
i = mylist.pop(3)
print(f"列表取出的元素是:{i}")
print(mylist)
count = mylist.count('Mickey')
print(f"列表中Mickey的个数是:{count}")
mylist.remove('Mickey')
# 删除从前往后第一个匹配的元素
print(mylist)
mylist.pop(-2)
# index反向索引取的是列表倒数第二个数字
print(mylist)
s = len(mylist)
print(f"列表长度是:{s}")
学python,来黑马程序员,月薪过万
黑马程序员
=====================================================================
['Mickey', 'Alan', 'Joke', 'Steven', 'Bob', ['Sally', 'Rose']]
['Mickey', ['Love', 'you'], 'Alan', 'Joke', 'Steven', 'Bob', ['Sally', 'Rose']]
['Mickey', ['Love', 'you'], 'Alan', 'Joke', 'Steven', 'Bob', ['Sally', 'Rose'], 'Mickey', 1, 2, 3]
Bob所在列表的index是:5
['Mickey', ['Love'], 'Alan', 'Joke', 'Steven', 'Bob', ['Sally', 'Rose'], 'Mickey', 1, 2, 3]
列表取出的元素是:Joke
['Mickey', ['Love'], 'Alan', 'Steven', 'Bob', ['Sally', 'Rose'], 'Mickey', 1, 2, 3]
列表中Mickey的个数是:2
[['Love'], 'Alan', 'Steven', 'Bob', ['Sally', 'Rose'], 'Mickey', 1, 2, 3]
[['Love'], 'Alan', 'Steven', 'Bob', ['Sally', 'Rose'], 'Mickey', 1, 3]
列表长度是:8
2. Tuple
# 元组内的元素不可修改,只可读取
t1 = (1, 'A', 2)
# 定义三个元素的元组
t2 = (3, )
# 定义单个元素的元组必须带有一个逗号,否则不是元组
t = t1.index('A')
print(f"A所在元组的下标是:{t}")
index = 0
print("t1里面的元素有:")
while index < len(t1):
index += 1
print()
for e in t1:
print(f"{e} ", end="")
print()
t3 = ('Mickey', 'FAFU', [1, 2, 3])
print(f"元组元素修改前:{t3}")
t3[2][1] = 4
print(f"元组元素修改后:{t3}")
# 元组内的元素实际并没有被修改,被修改的是嵌套在元组内的列表list
A所在元组的下标是:1
t1里面的元素有:
1 A 2
元组元素修改前:('Mickey', 'FAFU', [1, 2, 3])
元组元素修改后:('Mickey', 'FAFU', [1, 4, 3])
3. Set
my_list = ['Lucy', 'Kally', 'Candy', 'Bob', 'Mickey', 'Bob']
my_set = set()
# 定义空集合
for element in my_list:
my_set.add(element)
print(my_set)
# my_set = {'Kally', 'Mickey', 'Lucy', 'Candy', 'Bob'}
my_set1 = {'Mickey', 'Bob', 'Bill', 'Lilly'}
my_set2 = my_set1.difference(my_set)
my_set3 = my_set.difference(my_set1)
print(my_set2)
print(my_set3)
# my_set2 = {'Bill', 'Lilly'}
# my_set3 = {'Kally', 'Lucy', 'Candy'}
my_set4 = my_set1.union(my_set)
print(my_set4)
# my_set4 = {'Mickey', 'Kally', 'Bob', 'Candy', 'Bill', 'Lucy', 'Lilly'}
{'Kally', 'Bob', 'Candy', 'Lucy', 'Mickey'}
{'Bill', 'Lilly'}
{'Kally', 'Candy', 'Lucy'}
{'Kally', 'Bill', 'Bob', 'Candy', 'Lucy', 'Mickey', 'Lilly'}
4. String
s = "Mickey is so handsome"
print(s)
s = s.replace("so", "very")
# 字符串本身不可以修改
# 这是得到了一个新的字符串再传给s
print(s)
s = s.split(" ")
# 按照空格来分割字符串
print(s)
s1 = " Mickey is a good boy "
print(s1)
s1 = s1.strip()
# 没有传入参数的时候默认是去除首尾空格和换行符
print(s1)
s2 = "12356Mickey is a good boy74565"
print(s2)
s2 = s2.strip("123456789")
# 去除首尾含有123456789的字符
print(s2)
count = s2.count("Mi")
print(count)
len1 = len(s2)
print(len1)
Mickey is so handsome
Mickey is very handveryme
['Mickey', 'is', 'very', 'handveryme']
Mickey is a good boy
Mickey is a good boy
12356Mickey is a good boy74565
Mickey is a good boy
1
20
5. Dictionary
score1 = {'语文': 90, '数学': 110, '英语': 125}
score2 = {'语文': 100, '数学': 135, '英语': 95}
score3 = {'语文': 80, '数学': 100, '英语': 105}
my_dict1 = {}
# 空字典定义方式1
my_dict2 = dict()
# 空字典定义方式2
student_inf = {'Mickey': score1, 'Lucy': score2, 'Bill': score3}
# 键值对的key和value可以是任何数据类型(key不可以为字典)
# key不可以重复,重复添加等于覆盖掉原有的键值对
print(student_inf)
student_inf['Karly'] = {'语文': 120, '数学': 130, '英语': 135}
# 字典中添加或者更新元素
score4 = student_inf.pop('Lucy')
print(f"字典更新后:{student_inf}")
print(f"取出的Lucy的成绩:{score4}")
print(student_inf['Mickey'])
print(student_inf['Mickey']['语文'])
keys = student_inf.keys()
for key in keys:
print(f"字典的key:{key}")
print(f"字典的value:{student_inf[key]}")
# 遍历字典方法1
for key in student_inf:
print(f"字典的key:{key}")
print(f"字典的value:{student_inf[key]}")
# 遍历字典方法2
student_inf.clear()
# 清空字典
print(student_inf)
print("=======================================================")
info_dict = {
"王力宏": {
"部门": "科技部",
"工资": 3000,
"级别": 1
},
"周杰伦": {
"部门": "市场部",
"工资": 5000,
"级别": 2
},
"张学友": {
"部门": "科技部",
"工资": 4000,
"级别": 2
}
}
# 定义字典目录
for name in info_dict:
if info_dict[name]["级别"] == 1:
info_dict[name]["工资"] += 1000
info_dict[name]["级别"] += 1
print(info_dict)
# 更新级别为1的员工并且升职加薪
{'Mickey': {'语文': 90, '数学': 110, '英语': 125}, 'Lucy': {'语文': 100, '数学': 135, '英语': 95}, 'Bill': {'语文': 80, '数学': 100, '英语': 105}}
字典更新后:{'Mickey': {'语文': 90, '数学': 110, '英语': 125}, 'Bill': {'语文': 80, '数学': 100, '英语': 105}, 'Karly': {'语文': 120, '数学': 130, '英语': 135}}
取出的Lucy的成绩:{'语文': 100, '数学': 135, '英语': 95}
{'语文': 90, '数学': 110, '英语': 125}
90
字典的key:Mickey
字典的value:{'语文': 90, '数学': 110, '英语': 125}
字典的key:Bill
字典的value:{'语文': 80, '数学': 100, '英语': 105}
字典的key:Karly
字典的value:{'语文': 120, '数学': 130, '英语': 135}
字典的key:Mickey
字典的value:{'语文': 90, '数学': 110, '英语': 125}
字典的key:Bill
字典的value:{'语文': 80, '数学': 100, '英语': 105}
字典的key:Karly
字典的value:{'语文': 120, '数学': 130, '英语': 135}
{}
=======================================================
{'王力宏': {'部门': '科技部', '工资': 4000, '级别': 2}, '周杰伦': {'部门': '市场部', '工资': 5000, '级别': 2}, '张学友': {'部门': '科技部', '工资': 4000, '级别': 2}}
三、if逻辑
1. Comparison
num1 = int(input("num1="))
num2 = int(input("num2="))
print("num1比num2小是%s" % {num1 < num2})
if num1 < num2:
print("num1小于num2")
elif num1 == num2:
print("num1等于num2")
else:
print("num1大于num2")
# 4个空格缩进不要忘记
num1=432
num2=256
num1比num2小是{False}
num1大于num2
2. Random Game
import random
num = random.randint(1, 10)
while True:
guess = int(input("请输入您所猜测的数字:"))
if guess == num:
print("答对啦!")
break
elif num > guess:
print("猜小了")
else:
print("猜大了")
print(f"被猜的数是{num}")
请输入您所猜测的数字:9
猜大了
请输入您所猜测的数字:4
猜大了
请输入您所猜测的数字:2
答对啦!
被猜的数是2
3. Salary
money = 10000
import random
for i in range(1, 21):
level = random.randint(1, 10)
if level < 5:
print(f"员工{i}绩效不足5分,不予发工资!")
continue
else:
print(f"员工{i}绩效超过5分,发放1000元!")
money -= 1000
if money >0:
print(f"账户还剩{money}元")
else:
print("账户余额不足!")
break # 终止所有循环
员工1绩效不足5分,不予发工资!
员工2绩效超过5分,发放1000元!
账户还剩9000元
员工3绩效超过5分,发放1000元!
账户还剩8000元
员工4绩效超过5分,发放1000元!
账户还剩7000元
员工5绩效超过5分,发放1000元!
账户还剩6000元
员工6绩效超过5分,发放1000元!
账户还剩5000元
员工7绩效超过5分,发放1000元!
账户还剩4000元
员工8绩效超过5分,发放1000元!
账户还剩3000元
员工9绩效不足5分,不予发工资!
员工10绩效超过5分,发放1000元!
账户还剩2000元
员工11绩效超过5分,发放1000元!
账户还剩1000元
员工12绩效超过5分,发放1000元!
账户余额不足!
4. Ticket
condition=input("您是否是vip会员?:")
if condition == "是":
print("您无需购票,免费游玩!")
elif condition == "不是":
height = int(input("请输入你的身高:"))
if height > 120:
if height < 150:
print("您的身高超过120cm,需要补票10元")
else:
print("您的身高超过150cm,需要补票20元")
else:
print("您的低于120cm,无需补票")
else:
print("错误指令!请输入'是'或者'不是'")
您是否是vip会员?:不是
请输入你的身高:160
您的身高超过150cm,需要补票20元
5. Data Type
my_list = [1, 5, 4, 3, 2]
my_tuple = (1, 5, 4, 3, 2)
my_str = "adbgefc"
my_dict = {"key1": 1, "key2": 3, "key3": 2, "key4": 5, "key5": 4}
my_set = {"a", "g", "b", "d", "c", "e", "f"}
print(f"数据长度为:{len(my_list)}")
print(f"数据长度为:{len(my_tuple)}")
print(f"数据长度为:{len(my_str)}")
print(f"数据长度为:{len(my_dict)}")
print(f"数据长度为:{len(my_set)}")
print("=============================================")
print(f"数据最大值为:{max(my_list)}")
print(f"数据最大值为:{max(my_tuple)}")
print(f"数据最大值为:{max(my_str)}")
print(f"数据最大值为:{max(my_dict)}")
print(f"数据最大值为:{len(my_set)}")
print("=============================================")
print(f"数据最小值为:{min(my_list)}")
print(f"数据最小值为:{min(my_tuple)}")
print(f"数据最小值为:{min(my_str)}")
print(f"数据最小值为:{min(my_dict)}")
print(f"数据最小值为:{min(my_set)}")
print("=============================================")
# 字符串比较的是ASCII码,字典类型的数据容器只比较key的大小
# 单个小写字母比大写字母大,对于字符串则从左到右一位一位进行比较
print(f"转换字符串后为:{str(my_list)}")
print(f"转换字符串后为:{str(my_tuple)}")
print(f"转换字符串后为:{str(my_str)}")
print(f"转换字符串后为:{str(my_dict)}")
print(f"转换字符串后为:{str(my_set)}")
print("=============================================")
print(f"转换集合为:{set(my_list)}")
print(f"转换集合为:{set(my_tuple)}")
print(f"转换集合为:{set(my_str)}")
print(f"转换集合为:{set(my_dict)}")
print(f"转换集合为:{set(my_set)}")
print("=============================================")
print(f"转换元组为:{tuple(my_list)}")
print(f"转换元组为:{tuple(my_tuple)}")
print(f"转换元组为:{tuple(my_str)}")
print(f"转换元组为:{tuple(my_dict)}")
print(f"转换元组为:{tuple(my_set)}")
print("=============================================")
print(f"转换列表后为:{list(my_list)}")
print(f"转换列表后为:{list(my_tuple)}")
print(f"转换列表后为:{list(my_str)}")
print(f"转换列表后为:{list(my_dict)}")
print(f"转换列表后为:{list(my_set)}")
print("=============================================")
# 其他数据容器不能转换为字典,因为根本不是键值对
print(f"排序后为:{sorted(my_list)}")
print(f"排序后为:{sorted(my_tuple)}")
print(f"排序后为:{sorted(my_str)}")
print(f"排序后为:{sorted(my_dict)}")
print(f"排序后为:{sorted(my_set)}")
print("=============================================")
# sorted语句默认第二项参数为reverse = False,升序排列
# 无论什么类型的数据容器,排序之后都变成了列表对象
print(f"排序后为:{sorted(my_list, reverse= True)}")
print(f"排序后为:{sorted(my_tuple, reverse= True)}")
print(f"排序后为:{sorted(my_str, reverse= True)}")
print(f"排序后为:{sorted(my_dict, reverse= True)}")
print(f"排序后为:{sorted(my_set, reverse= True)}")
print("=============================================")
# sorted语句的第二项参数为reverse= True时,降序排列
数据长度为:5
数据长度为:5
数据长度为:7
数据长度为:5
数据长度为:7
=============================================
数据最大值为:5
数据最大值为:5
数据最大值为:g
数据最大值为:key5
数据最大值为:7
=============================================
数据最小值为:1
数据最小值为:1
数据最小值为:a
数据最小值为:key1
数据最小值为:a
=============================================
转换字符串后为:[1, 5, 4, 3, 2]
转换字符串后为:(1, 5, 4, 3, 2)
转换字符串后为:adbgefc
转换字符串后为:{'key1': 1, 'key2': 3, 'key3': 2, 'key4': 5, 'key5': 4}
转换字符串后为:{'d', 'e', 'a', 'b', 'g', 'c', 'f'}
=============================================
转换集合为:{1, 2, 3, 4, 5}
转换集合为:{1, 2, 3, 4, 5}
转换集合为:{'b', 'f', 'd', 'a', 'c', 'g', 'e'}
转换集合为:{'key4', 'key5', 'key1', 'key3', 'key2'}
转换集合为:{'d', 'e', 'a', 'b', 'g', 'c', 'f'}
=============================================
转换元组为:(1, 5, 4, 3, 2)
转换元组为:(1, 5, 4, 3, 2)
转换元组为:('a', 'd', 'b', 'g', 'e', 'f', 'c')
转换元组为:('key1', 'key2', 'key3', 'key4', 'key5')
转换元组为:('d', 'e', 'a', 'b', 'g', 'c', 'f')
=============================================
转换列表后为:[1, 5, 4, 3, 2]
转换列表后为:[1, 5, 4, 3, 2]
转换列表后为:['a', 'd', 'b', 'g', 'e', 'f', 'c']
转换列表后为:['key1', 'key2', 'key3', 'key4', 'key5']
转换列表后为:['d', 'e', 'a', 'b', 'g', 'c', 'f']
=============================================
排序后为:[1, 2, 3, 4, 5]
排序后为:[1, 2, 3, 4, 5]
排序后为:['a', 'b', 'c', 'd', 'e', 'f', 'g']
排序后为:['key1', 'key2', 'key3', 'key4', 'key5']
排序后为:['a', 'b', 'c', 'd', 'e', 'f', 'g']
=============================================
排序后为:[5, 4, 3, 2, 1]
排序后为:[5, 4, 3, 2, 1]
排序后为:['g', 'f', 'e', 'd', 'c', 'b', 'a']
排序后为:['key5', 'key4', 'key3', 'key2', 'key1']
排序后为:['g', 'f', 'e', 'd', 'c', 'b', 'a']
=============================================
四、循环结构
1. for Loop
name = "Mickey"
for x in name:
print(x) # 遍历字符串
i = 0
s = "wjbfjejfefklmfdjgngriguig"
for x in s:
if x == "j":
i += 1
print("该字符串内有%d个j" % i)
M
i
c
k
e
y
该字符串内有4个j
2. for Loop Practice
for x in range(10):
print(x, end="")
print()
for s in range(5, 10): # 不包括10本身
print(s, end="")
print()
for w in range(3, 10, 2): # 步长为2
print(w, end="")
print()
i = 0
for i in range(1, 10):
print(f"今天是向小美表白的第{i}天")
for j in range(1, 10):
print(f"今天送了第{j}朵玫瑰")
print(f"表白的第{i}天结束")
print("表白成功!")
0123456789
56789
3579
今天是向小美表白的第1天
今天送了第1朵玫瑰
今天送了第2朵玫瑰
今天送了第3朵玫瑰
今天送了第4朵玫瑰
今天送了第5朵玫瑰
今天送了第6朵玫瑰
今天送了第7朵玫瑰
今天送了第8朵玫瑰
今天送了第9朵玫瑰
表白的第1天结束
今天是向小美表白的第2天
今天送了第1朵玫瑰
今天送了第2朵玫瑰
今天送了第3朵玫瑰
今天送了第4朵玫瑰
今天送了第5朵玫瑰
今天送了第6朵玫瑰
今天送了第7朵玫瑰
今天送了第8朵玫瑰
今天送了第9朵玫瑰
表白的第2天结束
今天是向小美表白的第3天
今天送了第1朵玫瑰
今天送了第2朵玫瑰
今天送了第3朵玫瑰
今天送了第4朵玫瑰
今天送了第5朵玫瑰
今天送了第6朵玫瑰
今天送了第7朵玫瑰
今天送了第8朵玫瑰
今天送了第9朵玫瑰
表白的第3天结束
今天是向小美表白的第4天
今天送了第1朵玫瑰
今天送了第2朵玫瑰
今天送了第3朵玫瑰
今天送了第4朵玫瑰
今天送了第5朵玫瑰
今天送了第6朵玫瑰
今天送了第7朵玫瑰
今天送了第8朵玫瑰
今天送了第9朵玫瑰
表白的第4天结束
今天是向小美表白的第5天
今天送了第1朵玫瑰
今天送了第2朵玫瑰
今天送了第3朵玫瑰
今天送了第4朵玫瑰
今天送了第5朵玫瑰
今天送了第6朵玫瑰
今天送了第7朵玫瑰
今天送了第8朵玫瑰
今天送了第9朵玫瑰
表白的第5天结束
今天是向小美表白的第6天
今天送了第1朵玫瑰
今天送了第2朵玫瑰
今天送了第3朵玫瑰
今天送了第4朵玫瑰
今天送了第5朵玫瑰
今天送了第6朵玫瑰
今天送了第7朵玫瑰
今天送了第8朵玫瑰
今天送了第9朵玫瑰
表白的第6天结束
今天是向小美表白的第7天
今天送了第1朵玫瑰
今天送了第2朵玫瑰
今天送了第3朵玫瑰
今天送了第4朵玫瑰
今天送了第5朵玫瑰
今天送了第6朵玫瑰
今天送了第7朵玫瑰
今天送了第8朵玫瑰
今天送了第9朵玫瑰
表白的第7天结束
今天是向小美表白的第8天
今天送了第1朵玫瑰
今天送了第2朵玫瑰
今天送了第3朵玫瑰
今天送了第4朵玫瑰
今天送了第5朵玫瑰
今天送了第6朵玫瑰
今天送了第7朵玫瑰
今天送了第8朵玫瑰
今天送了第9朵玫瑰
表白的第8天结束
今天是向小美表白的第9天
今天送了第1朵玫瑰
今天送了第2朵玫瑰
今天送了第3朵玫瑰
今天送了第4朵玫瑰
今天送了第5朵玫瑰
今天送了第6朵玫瑰
今天送了第7朵玫瑰
今天送了第8朵玫瑰
今天送了第9朵玫瑰
表白的第9天结束
表白成功!
3. 9×9 Multiplication
i = 1
while i <= 9:
j = 1
while i >= j:
print(f"{j} * {i} = {j * i}\t", end=" ") # 制表符\t
j += 1
i += 1
print() # 换行
print()
for i in range(1,10):
j = 1
for j in range(1,10):
if i >=j:
print(f"{j} * {i} = {i*j}\t", end="")
print()
1 * 1 = 1
1 * 2 = 2 2 * 2 = 4
1 * 3 = 3 2 * 3 = 6 3 * 3 = 9
1 * 4 = 4 2 * 4 = 8 3 * 4 = 12 4 * 4 = 16
1 * 5 = 5 2 * 5 = 10 3 * 5 = 15 4 * 5 = 20 5 * 5 = 25
1 * 6 = 6 2 * 6 = 12 3 * 6 = 18 4 * 6 = 24 5 * 6 = 30 6 * 6 = 36
1 * 7 = 7 2 * 7 = 14 3 * 7 = 21 4 * 7 = 28 5 * 7 = 35 6 * 7 = 42 7 * 7 = 49
1 * 8 = 8 2 * 8 = 16 3 * 8 = 24 4 * 8 = 32 5 * 8 = 40 6 * 8 = 48 7 * 8 = 56 8 * 8 = 64
1 * 9 = 9 2 * 9 = 18 3 * 9 = 27 4 * 9 = 36 5 * 9 = 45 6 * 9 = 54 7 * 9 = 63 8 * 9 = 72 9 * 9 = 81
1 * 1 = 1
1 * 2 = 2 2 * 2 = 4
1 * 3 = 3 2 * 3 = 6 3 * 3 = 9
1 * 4 = 4 2 * 4 = 8 3 * 4 = 12 4 * 4 = 16
1 * 5 = 5 2 * 5 = 10 3 * 5 = 15 4 * 5 = 20 5 * 5 = 25
1 * 6 = 6 2 * 6 = 12 3 * 6 = 18 4 * 6 = 24 5 * 6 = 30 6 * 6 = 36
1 * 7 = 7 2 * 7 = 14 3 * 7 = 21 4 * 7 = 28 5 * 7 = 35 6 * 7 = 42 7 * 7 = 49
1 * 8 = 8 2 * 8 = 16 3 * 8 = 24 4 * 8 = 32 5 * 8 = 40 6 * 8 = 48 7 * 8 = 56 8 * 8 = 64
1 * 9 = 9 2 * 9 = 18 3 * 9 = 27 4 * 9 = 36 5 * 9 = 45 6 * 9 = 54 7 * 9 = 63 8 * 9 = 72 9 * 9 = 81
4. Random Game Plus
import random
num = random.randint(1,10)
guess = int(input("请猜测数字:"))
i = 0
flag = True
while flag:
i += 1
if guess != num:
if guess < num:
print("猜小了")
elif guess >num:
print("猜大了")
print("你已经猜错%d次了" % i)
guess = int(input("请再次猜测数字:"))
else:
print("猜对了!")
flag = False
请猜测数字:5
猜小了
你已经猜错1次了
请再次猜测数字:9
猜大了
你已经猜错2次了
请再次猜测数字:8
猜对了!
五、函数
1. Bank System
print("----------------主菜单----------------")
print("Mickey你好,欢迎来到中国农业银行。请选择操作:")
print("查询余额\t", end="")
print("[输入1]")
print("存款\t\t", end="")
print("[输入2]")
print("取款\t\t", end="")
print("[输入3]")
print("退出\t\t", end="")
print("[输入4]")
money = 5000000
def check_money():
print("----------------查询余额----------------")
print(f"Mickey你好,余额剩余{money}元")
def in_money(money):
"""
:param money: 开始的余额
:return: 存完钱后的金额
"""
prof = int(input("请输入存钱金额"))
money += prof
print(f"你的余额还剩余{money}元")
return money
def out_money(money):
decre = int(input("请输入取出金额"))
money -= decre
print(f"你的余额还剩余{money}元")
return money
flag = True
while (flag):
num = int(input("请输入你的选择:"))
if num == 1:
check_money()
elif num == 2:
money = in_money(money)
elif num == 3:
money = out_money(money)
elif num == 4:
print("系统已退出")
break
else:
print("请重新输入数字!")
----------------主菜单----------------
Mickey你好,欢迎来到中国农业银行。请选择操作:
查询余额 [输入1]
存款 [输入2]
取款 [输入3]
退出 [输入4]
请输入你的选择:1
----------------查询余额----------------
Mickey你好,余额剩余5000000元
请输入你的选择:3
请输入取出金额500
你的余额还剩余4999500元
请输入你的选择:2
请输入存钱金额5000
你的余额还剩余5004500元
请输入你的选择:4
系统已退出
2. Function Parameter
def function_test():
return 1, 2, 3
x, y ,z = function_test()
print(f"xyz的值分别是{x},{y},{z}")
def user_info(name, age, gender = "男" ):
# 缺省参数(默认值)只能是最后一个参数
print(f"你的名字是{name},性别是{gender},今年{age}岁")
user_info("Mickey", 21,)
# 未填写gender则默认为”男“
user_info("Lucy", 22, "女")
# 可以覆盖默认参数
user_info(gender="女", name="Alan", age=18)
# 利用键值对传参,位置就无所谓,但是必须的key = value形式
def user_uncertain(*args):
print(f"数据内容为{args},数据类型为{type(args)}")
# 不定长定义的形式参数,接收不定长数量的数据传入,最终会转换成元组数据类型
user_uncertain(1, 2, "Mickey")
def user_uncertains(**kwargs):
print(f"数据内容为{kwargs},数据类型为{type(kwargs)}")
# 传递进来的参数可以是任意数量的键值对类型(key=value),最终会转换成字典数据类型
user_uncertains(gender="男", age=21, name="Mickey")
xyz的值分别是1,2,3
你的名字是Mickey,性别是男,今年21岁
你的名字是Lucy,性别是女,今年22岁
你的名字是Alan,性别是女,今年18岁
数据内容为(1, 2, 'Mickey'),数据类型为<class 'tuple'>
数据内容为{'gender': '男', 'age': 21, 'name': 'Mickey'},数据类型为<class 'dict'>
3. Function Plus
def print_process(compute, x, y):
result2 = compute(x, y)
print(f"计算结果是{result2},compute的数据类型是{type(compute)}")
# 函数体也可以作为参数传入另一个函数,传入的是计算逻辑而非数据
def add(x, y):
result1 = x + y
return result1
a = 10
b = 22
print_process(add, a, b)
print_process(lambda x, y: x*y, a, b)
# 匿名参数:临时构建一个函数场景,只能定义一行,定义的关键字是匿名的,无法二次使用
计算结果是32,compute的数据类型是<class 'function'>
计算结果是220,compute的数据类型是<class 'function'>
六、文件的读写
1. File to Read
import time
f = open("C:/Users/lenovo/Desktop/1.txt", "r", encoding="UTF-8")
print(type(f))
print(f"读取10个字节的内容结果:{f.read(10)}")
print(f"读取h全部字节的内容结果:{f.read()}")
# 第二次read从上一个read的结尾处继续读取
lines = f.readlines()
print(lines)
# 读取文件的全部行,封装到列表中
f.close()
f = open("C:/Users/lenovo/Desktop/1.txt", "r", encoding="UTF-8")
line1 = f.readline()
line2 = f.readline()
line3 = f.readline()
print(f"第一行的数据是:{line1}")
print(f"第二行的数据是:{line2}")
print(f"第三行的数据是:{line3}")
for line in f:
print(f"每一行的数据是:{line}")
# for循环读取文件行
f.close()
# 接触对于文件的占用
with open ("C:/Users/lenovo/Desktop/1.txt", "r", encoding="UTF-8") as f:
for line in f:
print(f"每一行的数据是:{line}")
# 程序执行完自动关闭,可以避免我们忘记close的操作,解除pycharm继续对文件的持续占用
time.sleep(50000)
<class '_io.TextIOWrapper'>
读取10个字节的内容结果:浅谈中国传统的鼓文化
读取h全部字节的内容结果:
【摘要】中国的传统民族音乐,是近千年来优秀的文化在不断创新和发展站的一个缩影,它既富有中国传统的地域特色,又极富有包容性,在世界的音乐历史中占据了重要的地位,并且对世界音乐的多元化、融合性起到了一定的作用。而其中的鼓文化更是历久弥新,击鼓是鼓舞人们的精神力量,在使人在获得一定美感的同时,也能得到警醒与启迪,弘扬中华的传统美德。
【关键词】音乐传承 历史悠久 鼓乐器 舞动击鼓 去粗取精
在本学期的音乐课堂中,我们了解了音乐表达形式的多样性,欣赏了大师的史诗级创作,以及音乐对于中国发展史的重要性。不过重点展开了中国历史上的传统乐器,他们有的至今仍被广为使用,而有的随着社会的发展和新流行音乐的产生,逐渐消磨殆尽!对于历史更迭,“优胜劣汰”我们是无法掌控的客观事实。作为当代大学生的我们,很少有人愿意去传承和学习一门传统民族乐器,所以我们唯有做到的是主动了解这些祖祖辈辈留下的民族乐器,知晓他们背后的故事和经典曲目,让他们不至于随着社会的发展彻底消失在历史的长河!
对于本学期学习的众多传统民族乐器中,最能引起我情感共振的当属“动次打次的家族”模块。也就是我们常说的打击乐器。我国的打击乐器具有鲜明的民族风格,品种繁多,演奏技巧相当丰富!对于发音的不同和有无固定音高可对打击乐器分别进行分类。例如我们常说的木鱼,就属于打击乐器响木的一种。
而让我最感兴趣,是隶属于皮革类的鼓家族。鼓文化与中华文明相伴而生数千年,中国鼓,其所承载的精神内涵已经远超其乐器的用途。先贤孔子曾说过“鼓之舞之”,可见“鼓舞”一词起源之早。早在中学时期,我们便学习到了一篇《安塞腰鼓》。作为第一批进入国家级非物质文化遗产名录的民族传统乐器舞蹈,它的精湛表现力令人陶醉:阵势浩大、气势磅礴,可由几人甚至几千人一同进行!当时的我,便被老师播放的这充满热血沸腾、豪情满志一幕震撼到了。从此,鼓在我的心目中就是“热血”和“力量”的代名词。
[]
第一行的数据是:浅谈中国传统的鼓文化
第二行的数据是:
第三行的数据是:【摘要】中国的传统民族音乐,是近千年来优秀的文化在不断创新和发展站的一个缩影,它既富有中国传统的地域特色,又极富有包容性,在世界的音乐历史中占据了重要的地位,并且对世界音乐的多元化、融合性起到了一定的作用。而其中的鼓文化更是历久弥新,击鼓是鼓舞人们的精神力量,在使人在获得一定美感的同时,也能得到警醒与启迪,弘扬中华的传统美德。
每一行的数据是:
每一行的数据是:【关键词】音乐传承 历史悠久 鼓乐器 舞动击鼓 去粗取精
每一行的数据是:
每一行的数据是: 在本学期的音乐课堂中,我们了解了音乐表达形式的多样性,欣赏了大师的史诗级创作,以及音乐对于中国发展史的重要性。不过重点展开了中国历史上的传统乐器,他们有的至今仍被广为使用,而有的随着社会的发展和新流行音乐的产生,逐渐消磨殆尽!对于历史更迭,“优胜劣汰”我们是无法掌控的客观事实。作为当代大学生的我们,很少有人愿意去传承和学习一门传统民族乐器,所以我们唯有做到的是主动了解这些祖祖辈辈留下的民族乐器,知晓他们背后的故事和经典曲目,让他们不至于随着社会的发展彻底消失在历史的长河!
每一行的数据是:
每一行的数据是: 对于本学期学习的众多传统民族乐器中,最能引起我情感共振的当属“动次打次的家族”模块。也就是我们常说的打击乐器。我国的打击乐器具有鲜明的民族风格,品种繁多,演奏技巧相当丰富!对于发音的不同和有无固定音高可对打击乐器分别进行分类。例如我们常说的木鱼,就属于打击乐器响木的一种。
每一行的数据是:
每一行的数据是: 而让我最感兴趣,是隶属于皮革类的鼓家族。鼓文化与中华文明相伴而生数千年,中国鼓,其所承载的精神内涵已经远超其乐器的用途。先贤孔子曾说过“鼓之舞之”,可见“鼓舞”一词起源之早。早在中学时期,我们便学习到了一篇《安塞腰鼓》。作为第一批进入国家级非物质文化遗产名录的民族传统乐器舞蹈,它的精湛表现力令人陶醉:阵势浩大、气势磅礴,可由几人甚至几千人一同进行!当时的我,便被老师播放的这充满热血沸腾、豪情满志一幕震撼到了。从此,鼓在我的心目中就是“热血”和“力量”的代名词。
每一行的数据是:浅谈中国传统的鼓文化
每一行的数据是:
每一行的数据是:【摘要】中国的传统民族音乐,是近千年来优秀的文化在不断创新和发展站的一个缩影,它既富有中国传统的地域特色,又极富有包容性,在世界的音乐历史中占据了重要的地位,并且对世界音乐的多元化、融合性起到了一定的作用。而其中的鼓文化更是历久弥新,击鼓是鼓舞人们的精神力量,在使人在获得一定美感的同时,也能得到警醒与启迪,弘扬中华的传统美德。
每一行的数据是:
每一行的数据是:【关键词】音乐传承 历史悠久 鼓乐器 舞动击鼓 去粗取精
每一行的数据是:
每一行的数据是: 在本学期的音乐课堂中,我们了解了音乐表达形式的多样性,欣赏了大师的史诗级创作,以及音乐对于中国发展史的重要性。不过重点展开了中国历史上的传统乐器,他们有的至今仍被广为使用,而有的随着社会的发展和新流行音乐的产生,逐渐消磨殆尽!对于历史更迭,“优胜劣汰”我们是无法掌控的客观事实。作为当代大学生的我们,很少有人愿意去传承和学习一门传统民族乐器,所以我们唯有做到的是主动了解这些祖祖辈辈留下的民族乐器,知晓他们背后的故事和经典曲目,让他们不至于随着社会的发展彻底消失在历史的长河!
每一行的数据是:
每一行的数据是: 对于本学期学习的众多传统民族乐器中,最能引起我情感共振的当属“动次打次的家族”模块。也就是我们常说的打击乐器。我国的打击乐器具有鲜明的民族风格,品种繁多,演奏技巧相当丰富!对于发音的不同和有无固定音高可对打击乐器分别进行分类。例如我们常说的木鱼,就属于打击乐器响木的一种。
每一行的数据是:
每一行的数据是: 而让我最感兴趣,是隶属于皮革类的鼓家族。鼓文化与中华文明相伴而生数千年,中国鼓,其所承载的精神内涵已经远超其乐器的用途。先贤孔子曾说过“鼓之舞之”,可见“鼓舞”一词起源之早。早在中学时期,我们便学习到了一篇《安塞腰鼓》。作为第一批进入国家级非物质文化遗产名录的民族传统乐器舞蹈,它的精湛表现力令人陶醉:阵势浩大、气势磅礴,可由几人甚至几千人一同进行!当时的我,便被老师播放的这充满热血沸腾、豪情满志一幕震撼到了。从此,鼓在我的心目中就是“热血”和“力量”的代名词。
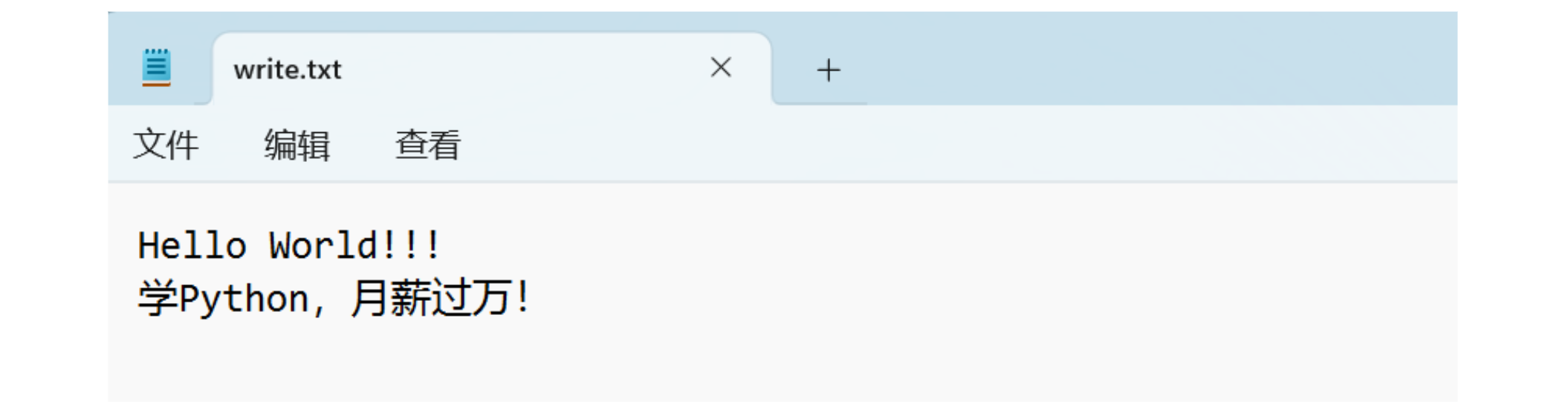
2. File to Write and Assign
f = open("C:/Users/lenovo/Desktop/write.txt", "w", encoding="UTF-8")
# 在write模式下,当没有此文件的时候,pycharm会帮我们创建
# 当文件存在时,会将内容清空再重新写入
f.write("Hello World!!!")
# 直接调用write,内容并未真正写入文件,而是会积攒在程序内存中,称之为缓冲区
f.flush()
# 当调用flush的时候,内容才会真正写入文件
# 这样做是避免频繁操作硬盘,导致速率下降(攒一堆,一次性写磁盘)
f.close()
# close是内置了flush功能的
f = open("C:/Users/lenovo/Desktop/write.txt", "a", encoding="UTF-8")
# 追加模式,文件不存在时会创建,文件存在的时候也不会清空内容
f.write("\n学Python,月薪过万!")
f = open("C:/Users/lenovo/Desktop/1.txt", "r", encoding="UTF-8")
lines = f.readlines()
lines = str(lines)
count1 = lines.count("鼓")
print(f"文件中鼓的个数是:{count1}")
f.close()
print("=================================================")
f = open("C:/Users/lenovo/Desktop/1.txt", "r", encoding="UTF-8")
count2 = 0
for line in f:
line = line.strip()
words = line.split(" ")
print(words)
for word in words:
if word == "浅谈中国传统的鼓文化":
count2 += 1
print(f"文件中'浅谈中国传统的鼓文化'的个数是:{count2}")
文件中鼓的个数是:13
=================================================
['浅谈中国传统的鼓文化']
['']
['【摘要】中国的传统民族音乐,是近千年来优秀的文化在不断创新和发展站的一个缩影,它既富有中国传统的地域特色,又极富有包容性,在世界的音乐历史中占据了重要的地位,并且对世界音乐的多元化、融合性起到了一定的作用。而其中的鼓文化更是历久弥新,击鼓是鼓舞人们的精神力量,在使人在获得一定美感的同时,也能得到警醒与启迪,弘扬中华的传统美德。']
['']
['【关键词】音乐传承', '历史悠久', '鼓乐器', '舞动击鼓', '去粗取精']
['']
['在本学期的音乐课堂中,我们了解了音乐表达形式的多样性,欣赏了大师的史诗级创作,以及音乐对于中国发展史的重要性。不过重点展开了中国历史上的传统乐器,他们有的至今仍被广为使用,而有的随着社会的发展和新流行音乐的产生,逐渐消磨殆尽!对于历史更迭,“优胜劣汰”我们是无法掌控的客观事实。作为当代大学生的我们,很少有人愿意去传承和学习一门传统民族乐器,所以我们唯有做到的是主动了解这些祖祖辈辈留下的民族乐器,知晓他们背后的故事和经典曲目,让他们不至于随着社会的发展彻底消失在历史的长河!']
['']
['对于本学期学习的众多传统民族乐器中,最能引起我情感共振的当属“动次打次的家族”模块。也就是我们常说的打击乐器。我国的打击乐器具有鲜明的民族风格,品种繁多,演奏技巧相当丰富!对于发音的不同和有无固定音高可对打击乐器分别进行分类。例如我们常说的木鱼,就属于打击乐器响木的一种。']
['']
['而让我最感兴趣,是隶属于皮革类的鼓家族。鼓文化与中华文明相伴而生数千年,中国鼓,其所承载的精神内涵已经远超其乐器的用途。先贤孔子曾说过“鼓之舞之”,可见“鼓舞”一词起源之早。早在中学时期,我们便学习到了一篇《安塞腰鼓》。作为第一批进入国家级非物质文化遗产名录的民族传统乐器舞蹈,它的精湛表现力令人陶醉:阵势浩大、气势磅礴,可由几人甚至几千人一同进行!当时的我,便被老师播放的这充满热血沸腾、豪情满志一幕震撼到了。从此,鼓在我的心目中就是“热血”和“力量”的代名词。']
文件中鼓的个数是:1
七、第三方扩展包
1. Import package
import time
# 导入python内置的time模块(time.py这个代码文件)
# time里面的所有功能都可以用
time.sleep(0.1)
print("Hello")
from time import sleep
# 只导入了time模块中的sleep功能
sleep(0.2)
print("world")
from time import *
sleep(0.3)
print("Mickey")
# 导入了time模块的全部内容,函数都可以直接使用
import time as tt
tt.sleep(0.5)
print("haha")
from time import sleep as sl
sl(0.3)
print("end")
# 为了使用方便,给模块名或者函数名复杂的设置一个别名
Hello
world
Mickey
haha
end
2. My package
2.1 my_module1.py
def add(x, y):
z = x + y
return z
if __name__ == '__main__':
print(add(1, 5))
# 当在该程序下运行,内置变量就会为main,该语句运行
# 反之在其它程序下导入此模块,内置变量就不是main,该语句也不会运行
6
2.2 my_module2.py
def minus(x, y):
z = x - y
return z
2.2 my_module3.py
# __all__ = ['multiply']
# from xxx import *只能导入all列表中的函数
def multiply(x, y):
z = x * y
return z
def division(x, y):
z = x / y
return z
2.3 init.py
# 创建包时会自动默认创造的文件夹
# 通过这个文件来表示一个文件夹是python的包而不是普通的文件夹
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
2.2 my_main_function
from time import sleep as sl
from 自导包模块.my_package.my_module1 import add as a
print(a(1, 4))
sl(0.2)
import my_package.my_module2 as m
from 自导包模块.my_package.my_module3 import *
print(m.minus(3, 1))
sl(0.2)
print(multiply(5, 9))
sl(0.5)
try:
print(division(9, 3))
except Exception as e:
print(e)
# 不同的模块,同名的功能,后导入的会覆盖先导入的
5
2
45
name 'division' is not defined
八、异常
try:
f = open("D:/123.txt", "r", encoding="UTF-8")
except:
print("出现异常了,因为文件不存在,应该将open的模式改为w模式去打开")
f = open("D:/123.txt", "w", encoding="UTF-8")
# 基本捕获语法
try:
print(name)
except NameError as e:
print("出现了变量未定义的异常")
print(e)
try:
i = 1/0
except (ZeroDivisionError, NameError) as e:
print("出现异常")
print(e)
# 捕获指定异常
try:
f = open("D:/233.txt", "r", encoding="UTF-8")
except Exception as e:
print("又出现异常")
# 捕获所有异常
try:
print("Hello")
except Exception as e:
print("又又出现异常了")
else:
print("好高兴,没有出现异常!")
finally:
print("finally必须执行")
f.close()
# try和except必须,else和finally非必须
# 捕获异常不需要去最底层函数捕获,异常具有传递性,在最高层级捕获异常即可
出现了变量未定义的异常
name 'name' is not defined
出现异常
division by zero
又出现异常
Hello
好高兴,没有出现异常!
finally必须执行
九、数据图绘制
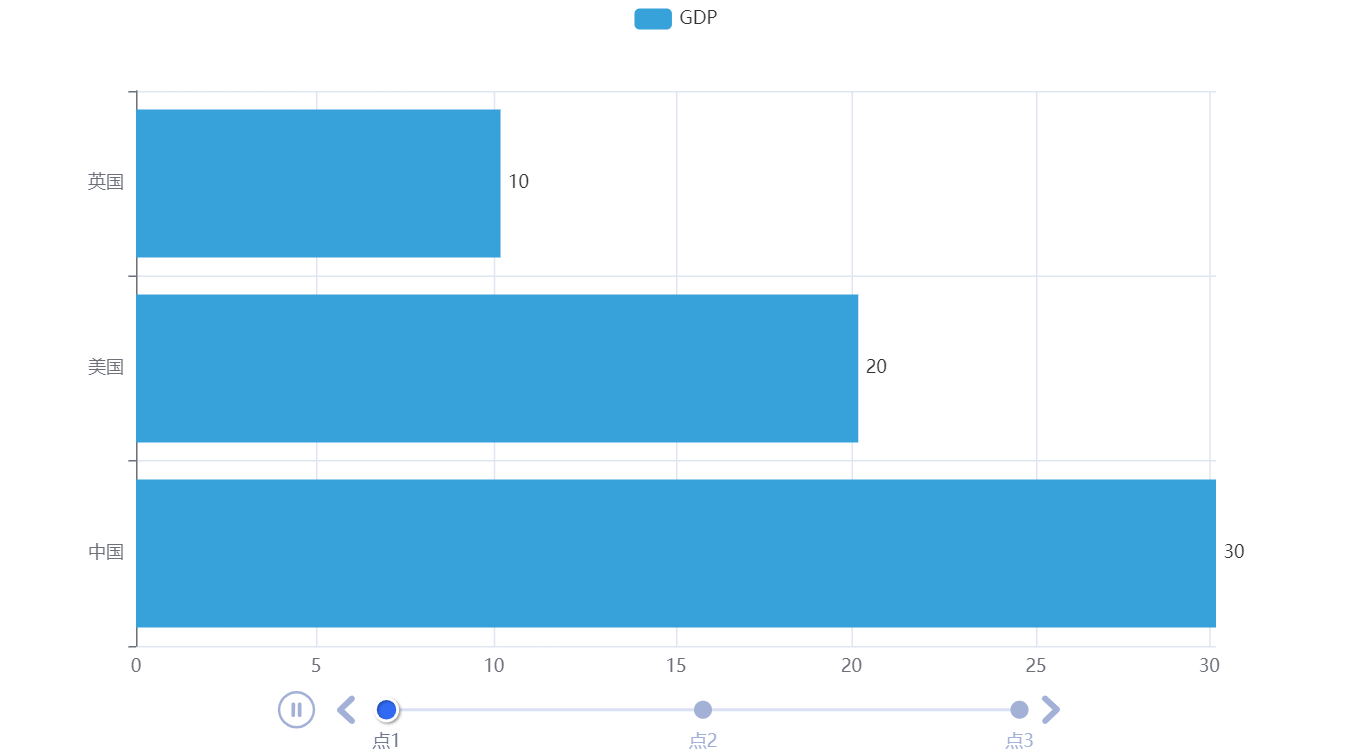
1. Bar Chart
from pyecharts.charts import Bar, Timeline
from pyecharts.options import LabelOpts
from pyecharts.globals import ThemeType
bar1 = Bar()
bar1.add_xaxis(["中国", "美国", "英国"])
bar1.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
bar1.reversal_axis()
bar2 = Bar()
bar2.add_xaxis(["中国", "美国", "英国"])
bar2.add_yaxis("GDP", [50, 50, 40], label_opts=LabelOpts(position="right"))
bar2.reversal_axis()
# 横纵轴反转
bar3 = Bar()
bar3.add_xaxis(["中国", "美国", "英国"])
bar3.add_yaxis("GDP", [70, 60, 50], label_opts=LabelOpts(position="right"))
bar3.reversal_axis()
timeline = Timeline({"theme": ThemeType.LIGHT})
# 构建时间线对象,设置柱状图主题
timeline.add(bar1, "点1")
timeline.add(bar2, "点2")
timeline.add(bar3, "点3")
# 绘图是时间线对象绘图,而不是bar对象
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
)
# 自动播放设置
# timeline.render("基础时间线绘图.html")
timeline.render_notebook()
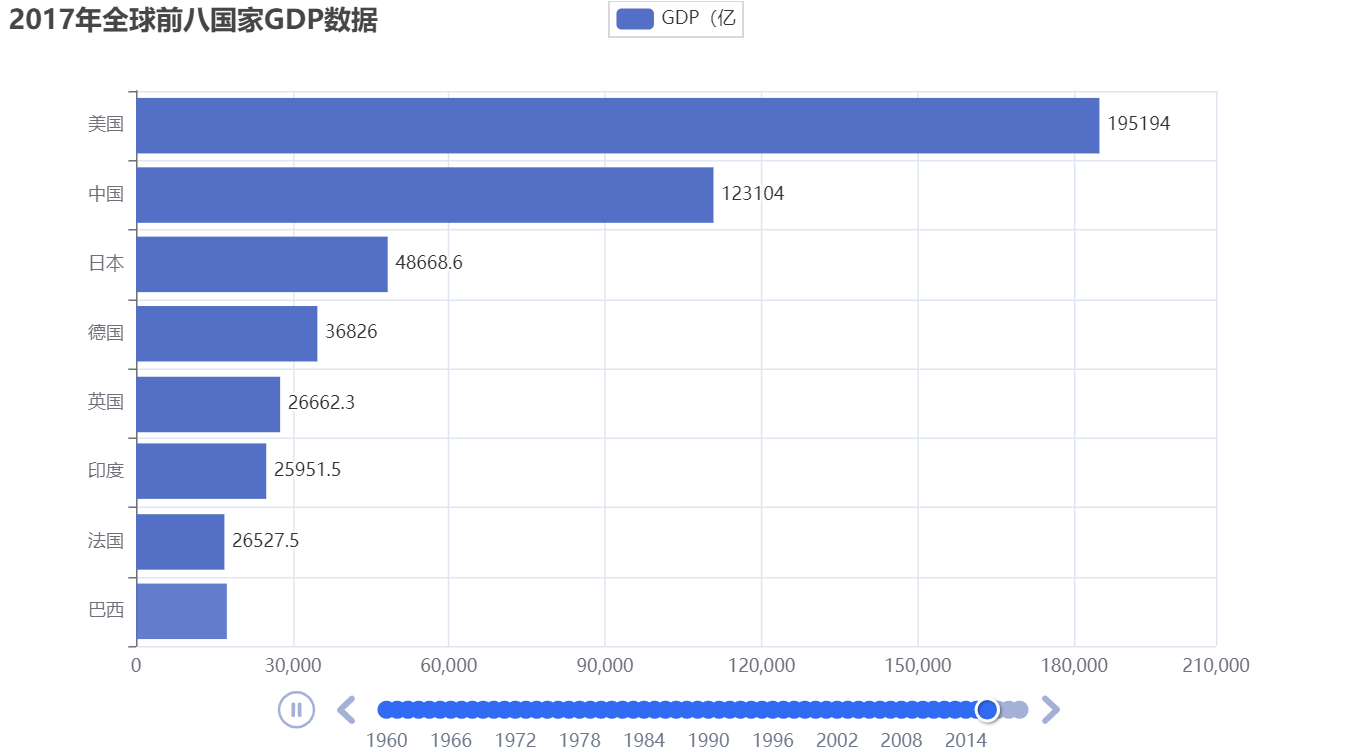
2. Bar Chart Plus
from pyecharts.charts import Bar, Timeline
from pyecharts.options import TitleOpts, LabelOpts
f = open("D:/可视化案例数据/动态柱状图数据/1960-2019全球GDP数据.csv")
data_lines = f.readlines()
f.close()
data_lines.pop(0) # 去掉第一条无用数据
data_dict = {}
for line in data_lines:
year = int(line.split(",")[0])
country = line.split(",")[1]
gdp = float(line.split(",")[2])
# 将数据转换为一个字典
try:
data_dict[year].append([country, gdp])
except KeyError:
data_dict[year] = []
data_dict[year].append([country, gdp])
# 填充字典
sorted_year_list = sorted(data_dict.keys())
# 排序年份
timeline = Timeline()
# print(data_dict)
for year in sorted_year_list:
data_dict[year].sort(key=lambda element: element[1], reverse=True)
# seq.sort(key=lambda x: f(x), reverse=True), 默认False升序排列
year_data = data_dict[year][0:8] # 取出前八名的国家
x_data = []
y_data = []
for country_gdp in year_data:
x_data.append(country_gdp[0])
y_data.append(country_gdp[1]/100000000)
bar = Bar()
x_data.reverse()
y_data.reverse()
bar.add_xaxis(x_data)
bar.add_yaxis("GDP(亿", y_data, label_opts=LabelOpts(position="right")) # 数值标签放在柱子右边
bar.reversal_axis()
bar.set_global_opts(
title_opts=TitleOpts(title=f"{year}年全球前八国家GDP数据")
)
timeline.add(bar, str(year)) # 要求年份是字符串形式
timeline.add_schema(
play_interval=300,
is_timeline_show=True,
is_auto_play=True,
)
# timeline.render("GDP前八.html")
timeline.render_notebook()
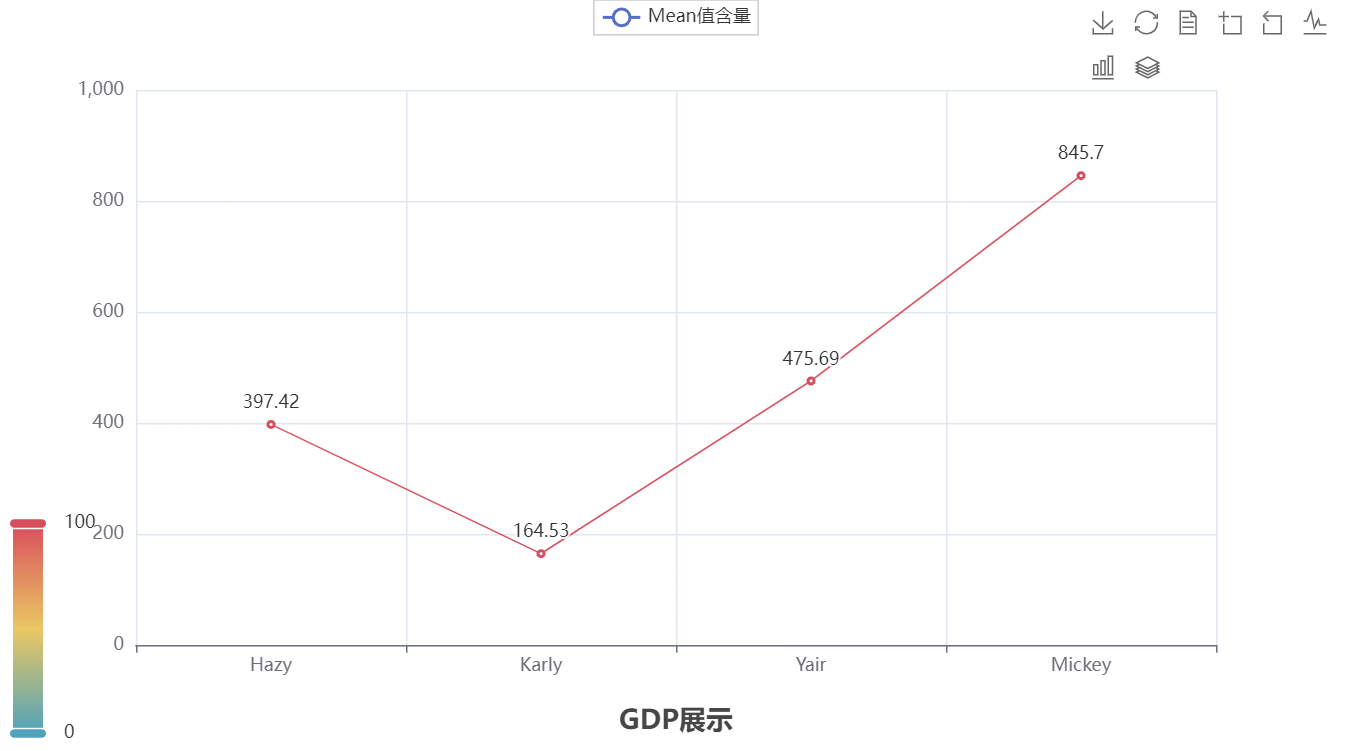
3. Line Chart
# pyecharts.org
# gallery.pyecharts.org
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts
# 导包,import后面是class对象
line = Line()
# 创建一个折线图对象
line.add_xaxis(["Hazy", "Karly", "Yair", "Mickey"])
# 给折线图对象添加x轴对象
line.add_yaxis("Mean值含量", [397.42, 164.53, 475.69, 845.70])
# 给折线图对象添加y轴对象
line.set_global_opts(
title_opts=TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"),
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True)
)
# 通过set_global_opts设置相关的全局配置项
# ctrl+p显示位置参数
# line.render()
# 通过render方法,将代码生成为图像
line.render_notebook()
十、可视化地图
1. Map
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
map = Map()
data = [
("北京市", 99),
("上海市", 199),
("湖南省", 299),
("台湾省", 199),
("安徽省", 299),
("广州省", 399),
("湖北省", 599),
]
map.add("地图", data, "china")
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{"min":1, "max":9, "label":"1-9人", "color":"#CCFFFF"},
{"min":10, "max":99, "label":"10-99人", "color":"#FFFF99"},
{"min":100, "max":499, "label":"100-499人", "color":"#FF9966"},
{"min":500, "max":999, "label":"500-999人", "color":"#FF6666"},
{"min":1000, "max":9999, "label":"1000-9999人", "color":"#CC3333"},
{"min":10000, "label":"10000人以上", "color":"#990033"}
]
)
)
# ab173.com找颜色对应编码
map.render_notebook()
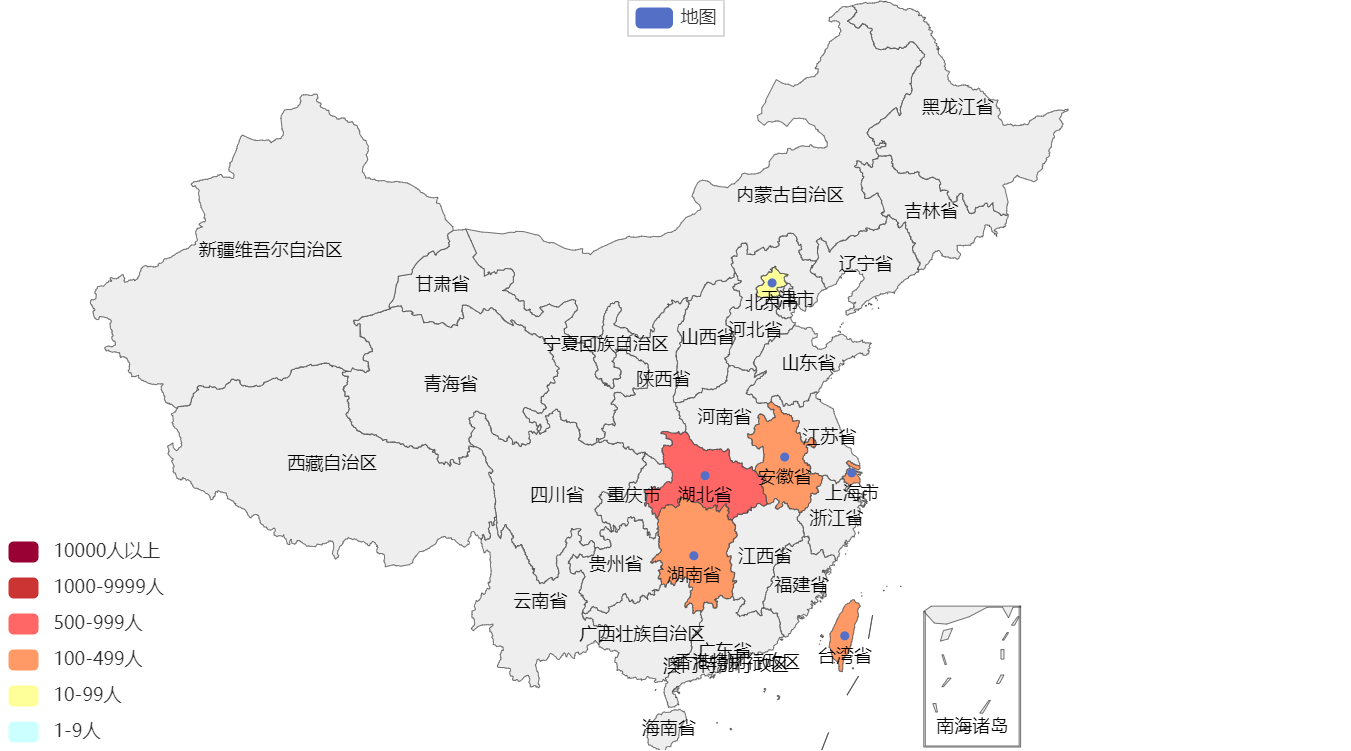
2. Map of COVID19 in China
import json
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts, TitleOpts
f = open("D:/可视化案例数据/地图数据/疫情.txt", "r", encoding="UTF-8")
data = f.read()
f.close()
data_dict = json.loads(data)
province_data_list = data_dict["areaTree"][0]["children"]
data_list = []
for province_data in province_data_list:
if province_data["name"] == "新疆":
province_name = province_data["name"] + "维吾尔自治区"
elif province_data["name"] == "广西":
province_name = province_data["name"] + "壮族自治区"
elif province_data["name"] == "宁夏":
province_name = province_data["name"] + "回族自治区"
elif province_data["name"] == "西藏" or province_data["name"] == "内蒙古":
province_name = province_data["name"] + "自治区"
elif province_data["name"] == "重庆" or province_data["name"] == "上海" or province_data["name"] == "北京" or province_data["name"] == "天津":
province_name = province_data["name"] + "市"
elif province_data["name"] == ("香港" or "澳门"):
province_name = province_data["name"] + "特别行政区"
else:
province_name = province_data["name"]+"省"
province_confirm = province_data["total"]["confirm"]
data_list.append((province_name, province_confirm)) # 元组
print(data_list)
Map = Map()
Map.add("该省确诊人数", data_list, "china")
Map.set_global_opts(
title_opts=TitleOpts(title="全国疫情地图"),
visualmap_opts=VisualMapOpts(
is_show=True, # 是否显示
is_piecewise=True, # 是否分段
pieces=[
{"min":1, "max":9, "label":"1-9人", "color":"#CCFFFF"},
{"min":10, "max":99, "label":"10-99人", "color":"#FFFF99"},
{"min":100, "max":499, "label":"100-499人", "color":"#FF9966"},
{"min":500, "max":999, "label":"500-999人", "color":"#FF6666"},
{"min":1000, "max":9999, "label":"1000-9999人", "color":"#CC3333"},
{"min":10000, "label":"10000人以上", "color":"#990033"}
]
)
)
# Map.render("全国疫情地图.html")# 指定生成文件
Map.render_notebook()
[('台湾省', 15880)]
[('台湾省', 15880), ('江苏省', 1576)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574), ('黑龙江省', 1613)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574), ('黑龙江省', 1613), ('宁夏回族自治区', 77)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574), ('黑龙江省', 1613), ('宁夏回族自治区', 77), ('青海省', 18)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574), ('黑龙江省', 1613), ('宁夏回族自治区', 77), ('青海省', 18), ('江西省', 937)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574), ('黑龙江省', 1613), ('宁夏回族自治区', 77), ('青海省', 18), ('江西省', 937), ('贵州省', 147)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574), ('黑龙江省', 1613), ('宁夏回族自治区', 77), ('青海省', 18), ('江西省', 937), ('贵州省', 147), ('西藏自治区', 1)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574), ('黑龙江省', 1613), ('宁夏回族自治区', 77), ('青海省', 18), ('江西省', 937), ('贵州省', 147), ('西藏自治区', 1), ('安徽省', 1008)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574), ('黑龙江省', 1613), ('宁夏回族自治区', 77), ('青海省', 18), ('江西省', 937), ('贵州省', 147), ('西藏自治区', 1), ('安徽省', 1008), ('河北省', 1317)]
[('台湾省', 15880), ('江苏省', 1576), ('云南省', 982), ('河南省', 1518), ('上海市', 2408), ('湖南省', 1181), ('湖北省', 68286), ('广东省', 2978), ('香港特别行政区', 12039), ('福建省', 773), ('浙江省', 1417), ('山东省', 923), ('四川省', 1179), ('天津市', 445), ('北京市', 1107), ('陕西省', 668), ('广西壮族自治区', 289), ('辽宁省', 441), ('重庆市', 603), ('澳门省', 63), ('甘肃省', 199), ('山西省', 255), ('海南省', 190), ('内蒙古自治区', 410), ('吉林省', 574), ('黑龙江省', 1613), ('宁夏回族自治区', 77), ('青海省', 18), ('江西省', 937), ('贵州省', 147), ('西藏自治区', 1), ('安徽省', 1008), ('河北省', 1317), ('新疆维吾尔自治区', 980)]
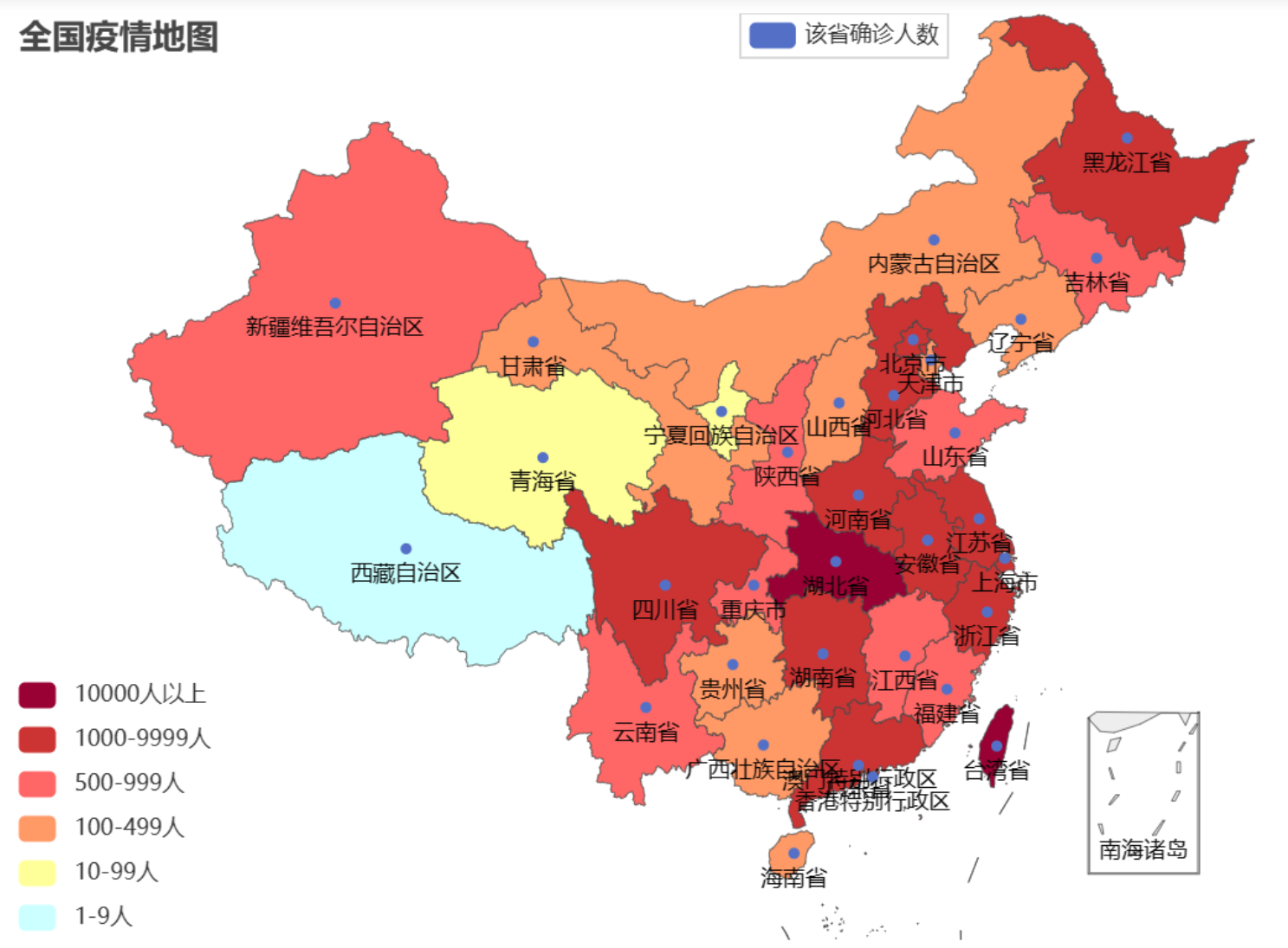
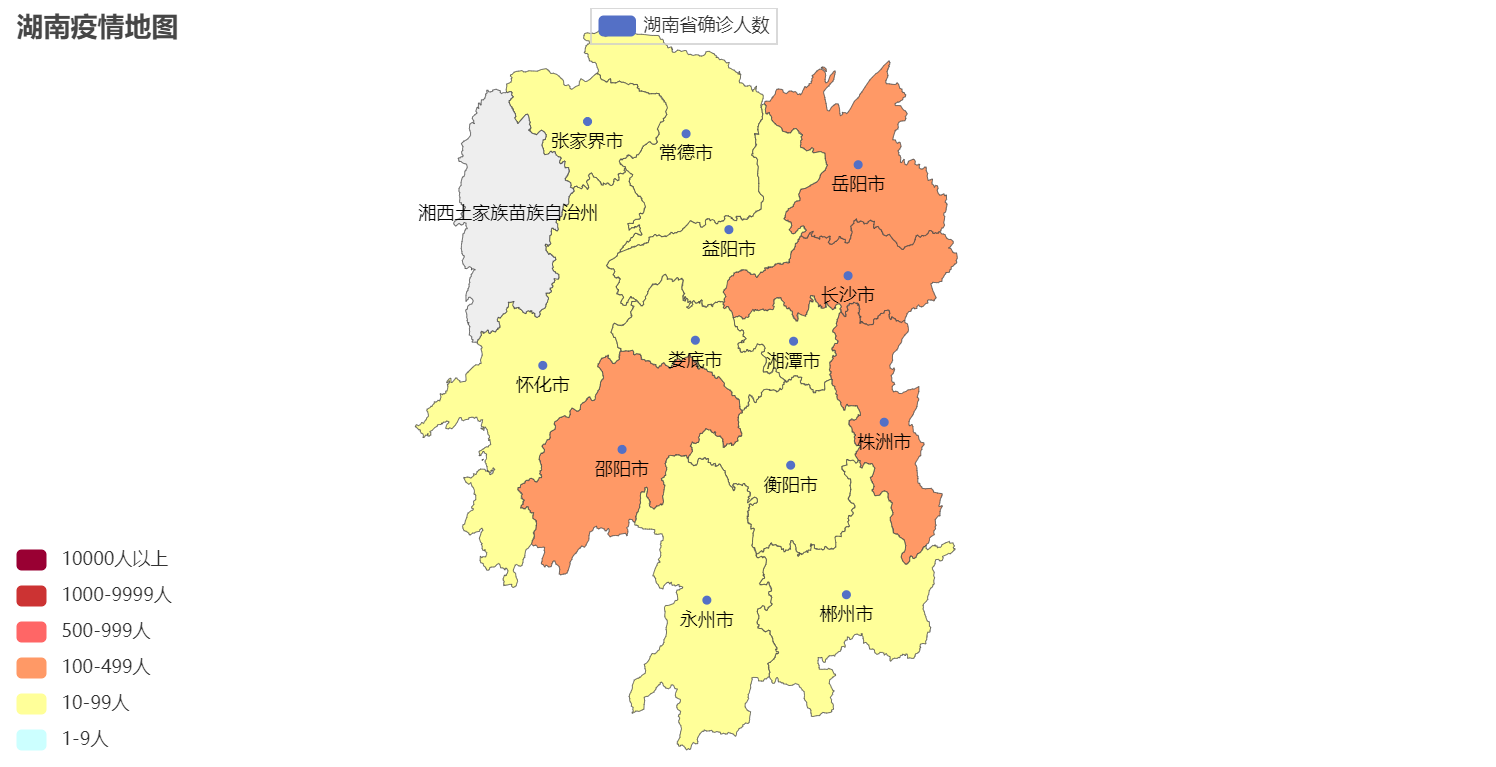
2. Map of COVID19 in Hunan
import json
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts, TitleOpts
f = open("D:/可视化案例数据/地图数据/疫情.txt", "r", encoding="UTF-8")
data = f.read()
f.close()
data_dict = json.loads(data)
city_data_list = data_dict["areaTree"][0]["children"][5]["children"]
data_list = []
for city_data in city_data_list:
city_name = city_data["name"]+"市"
city_confirm = city_data["total"]["confirm"]
data_list.append((city_name, city_confirm)) # 元组
Map = Map()
Map.add("湖南省确诊人数", data_list, "湖南")
Map.set_global_opts(
title_opts=TitleOpts(title="湖南疫情地图"),
visualmap_opts=VisualMapOpts(
is_show=True, # 是否显示
is_piecewise=True, # 是否分段
pieces=[
{"min":1, "max":9, "label":"1-9人", "color":"#CCFFFF"},
{"min":10, "max":99, "label":"10-99人", "color":"#FFFF99"},
{"min":100, "max":499, "label":"100-499人", "color":"#FF9966"},
{"min":500, "max":999, "label":"500-999人", "color":"#FF6666"},
{"min":1000, "max":9999, "label":"1000-9999人", "color":"#CC3333"},
{"min":10000, "label":"10000人以上", "color":"#990033"}
]
)
)
# Map.render("湖南省疫情地图.html") # 指定生成文件
Map.render_notebook()
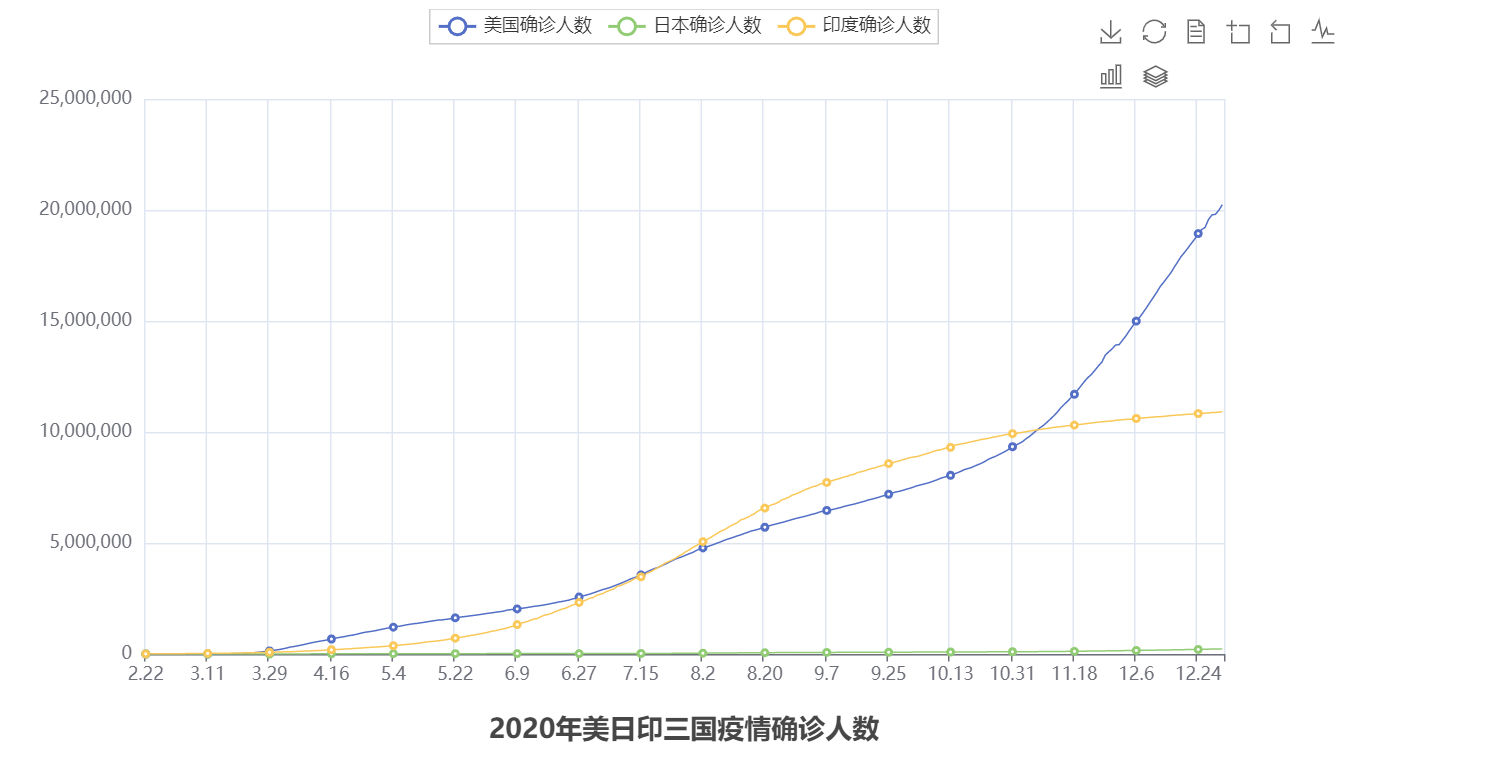
3. Line Chart of COVID19 in 3 Countries
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, LabelOpts
f_us = open("D:/可视化案例数据/折线图数据/美国.txt", "r", encoding="UTF-8")
f_jp = open("D:/可视化案例数据/折线图数据/日本.txt", "r", encoding="UTF-8")
f_in = open("D:/可视化案例数据/折线图数据/印度.txt", "r", encoding="UTF-8")
us_data = f_us.read()
jp_data = f_jp.read()
in_data = f_in.read()
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
in_data = in_data.replace("jsonp_1629350745930_63180(", "")
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]
# 去掉不合规范的json数据
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# json转python字典
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']
# 获取trend key
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]
# 获取日期数据,用于x轴
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]
# 获取确诊数据,用于y轴
line = Line()
line.add_xaxis(us_x_data)
# 公用x轴,使用一个国家的数据即可
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False))
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False))
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False))
# 添加各国确诊人数为y轴数据
line.set_global_opts(
title_opts=TitleOpts(title="2020年美日印三国疫情确诊人数", pos_left="center", pos_bottom="1%"),
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
)
# 全局设置
line.render_notebook()
# # 用render方法生成图表
# f_us.close()
# f_jp.close()
# f_in.close()
十一、月销售额数据分析
1. data_analysis.py
import json
from 月销售额数据分析.data_analysis_Record import Record
class FileReader:
def read_data(self):
pass
class TextFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
def read_data(self): # 复写父类方法
f = open(self.path, "r", encoding = "UTF-8")
record_list = []
for line in f.readlines():
line = line.strip()
data_list = line.split(",")
record = Record(data_list[0], data_list[1], int(data_list[2]), data_list[3])
record_list.append(record)
f.close()
return record_list
class JsonFileReader(FileReader):
def __init__(self, path):
self.path = path
def read_data(self):
f = open(self.path, "r", encoding = "UTF-8")
record_list = []
for line in f.readlines():
data_dict = json.loads(line)
record = Record(data_dict["date"], data_dict["order_id"], int(data_dict["money"]), data_dict["province"])
record_list.append(record)
f.close()
return record_list
2. data_analysis_Record.py
class Record:
def __init__(self, date, order_id, money, province):
self.date = date
self.order_id = order_id
self.money = money
self.province = province
# 在方法中使用变量要用self,表示成员变量
def __str__(self):
return f"{self.date}, {self.order_id}, {self.money}, {self.province}"
# 在此决定在list[]里面存放的Record元素是什么
3. data_analysis_main.py
from pyecharts.charts import Bar
from pyecharts.options import TitleOpts, LabelOpts, ToolboxOpts, VisualMapOpts
from 月销售额数据分析.data_analysis import TextFileReader, JsonFileReader
from 月销售额数据分析.data_analysis_Record import Record
textFileReader = TextFileReader("D:/数据分析案例/2011年1月销售数据.txt")
jsonFileReader = JsonFileReader("D:/数据分析案例/2011年2月销售数据JSON.txt")
jan_data = textFileReader.read_data()
feb_data = jsonFileReader.read_data()
all_data = jan_data + feb_data # 将两组list列表整合到一起
data_dict = {} # 使用字典的key不重复的特性
for record in all_data:
if record.date in data_dict.keys():
data_dict[record.date] += record.money # 同一天销售额相加
else:
data_dict[record.date] = record.money # 新建日期
bar = Bar()
bar.add_xaxis(list(data_dict.keys()))
bar.add_yaxis("销售额", list(data_dict.values()), label_opts=LabelOpts(is_show=False))
bar.set_global_opts(
title_opts=TitleOpts(title="每日销售额"),
)
bar.render("每日销售额主张图.html")
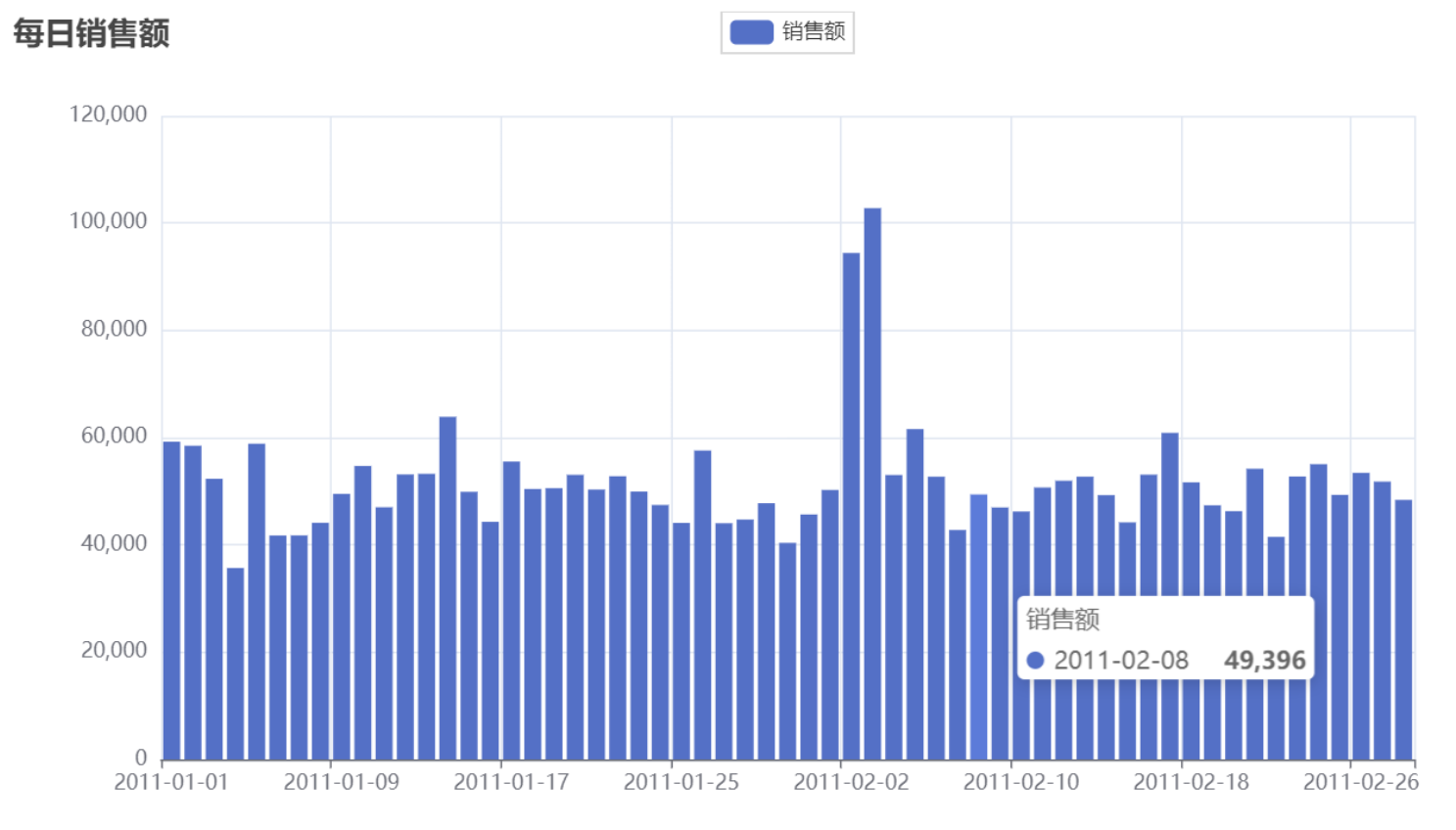
十二、类与对象
1. Class
# 设计一个闹钟类(设计表格)
# 类可以包含属性和行为,所以使用类描述现实世界事物是非常合适的
# 面向对象编程就是,使用对象进行编程
# 即,设计类,基于类创建对象,并使用对象来完成具体的工作
class Clock:
id = None # 序列化
price = None # 零售价
def ring(self): # self表示本函数对象,必须存在,传参的上海当他不存在就行
import winsound
print(f"闹钟ID:{self.id},价格:{self.price}")
winsound.Beep(2000, 3000) # 频率和持续时间
# 构建2个闹钟对象(打印表格)
clock1 = Clock()
clock2 = Clock()
# 让这2个闹钟工作(填写表格)
clock1.id = "20195908"
clock1.price = 19.9
clock1.ring()
clock2.id = "20195608"
clock2.price = 29.9
clock2.ring()
闹钟ID:20195908,价格:19.9
闹钟ID:20195608,价格:29.9
2. Init Method
class Student:
name = None
age = None
tel = None
# 可以省略
def __init__(self, name, age, tel):
self.name = name
self.age = age
self.tel = tel
# 赋值定义二合一
print("Student类创建了一个类对象")
stu = Student("Mickey", 21, 500603095) # 传入参数
print(stu.name)
print(stu.age)
print(stu.tel)
# python类中使用:__init__(),称之为构造方法。可以实现:
# 在创建类对象的时候,会自动执行。将传入参数自动传递给__init__方法使用。
Student类创建了一个类对象
Mickey
21
500603095
3. Magic Method
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"Student类对象,name: {self.name}, age:{self.age}"
# 可以自己决定stu输出什么
# 如果没有这一串代码,返回的只是stu的内存地址
def __lt__(self, other):
return self.age < other.age
# 该魔术方法可以使两个类对象之间进行比较(小于和大于)
def __le__(self, other):
return self.age <= other.age
# 判断大于等于(小于等于)
def __eq__(self, other):
return self.age == other.age
# 判断是否等于
stu1 = Student("Mickey", 31)
stu2 = Student("Alan", 25)
print(stu1)
print(str(stu1))
print(stu1 < stu2) # __lt__
print(stu1 > stu2) # __lt__
print(stu1 >= stu2) # __le__
print(stu1 >= stu2) # __le__
print(stu1 == stu2) # __eq__
Student类对象,name: Mickey, age:31
Student类对象,name: Mickey, age:31
False
True
True
True
False
4. Private Member
# 封装即把现实世界的事物在类中描述为属性和行为
class Phone:
import random
__current_voltage = random.randint(0, 2)
# 私有成员无法被类对象使用,但是可以被其他的成员使用
def __keep_single_core(self): # 成员变量和方法以__开头即为私有成员
print("让CPU以单核模式运行")
def call_by_5G(self):
if self.__current_voltage >=1:
print("5G通话已开启")
else:
self.__keep_single_core()
print("电量不足,无法使用5G通话,并已设置为单核运行进行省电")
phone = Phone()
phone.call_by_5G()
让CPU以单核模式运行
电量不足,无法使用5G通话,并已设置为单核运行进行省电
5. Phone in Practice
class Phone:
import random
s = None
i = random.randint(1, 10)
if i > 5:
s = True
else:
s = False
__is_5g_enable = s
def __check_5g(self):
if self.__is_5g_enable:
print("5G开启")
else:
print("5G关闭,使用4G网络")
def call_by_5G(self):
self.__check_5g()
print("正在通话中")
phone = Phone()
phone.call_by_5G()
5G开启
正在通话中
6. Student in Practice
class Student:
def __init__(self, name, age, addr):
self.name = name
self.age = age
self.addr = addr
for i in range(4):
print(f"当前录入第{i+1}位学生信息,总共需要录入4位学生信息")
a = input("请输入学生姓名:")
b = input("请输入学生年龄:")
c = input("请输入学生地址:")
stu = Student(a, b, c)
print(f"学生{i+1}信息录入完成,信息为【学生姓名:{stu.name},年龄:{stu.age},地址:{stu.addr}】")
当前录入第1位学生信息,总共需要录入4位学生信息
请输入学生姓名:Mickey
请输入学生年龄:21
请输入学生地址:湖南
学生1信息录入完成,信息为【学生姓名:Mickey,年龄:21,地址:湖南】
当前录入第2位学生信息,总共需要录入4位学生信息
请输入学生姓名:Bob
请输入学生年龄:23
请输入学生地址:四川
学生2信息录入完成,信息为【学生姓名:Bob,年龄:23,地址:四川】
当前录入第3位学生信息,总共需要录入4位学生信息
请输入学生姓名:Alan
请输入学生年龄:22
请输入学生地址:河北
学生3信息录入完成,信息为【学生姓名:Alan,年龄:22,地址:河北】
当前录入第4位学生信息,总共需要录入4位学生信息
请输入学生姓名:Jennie
请输入学生年龄:20
请输入学生地址:山东
学生4信息录入完成,信息为【学生姓名:Jennie,年龄:20,地址:山东】
7. Inheritance
class Phone_5G:
import random
s = None
i = random.randint(1, 10)
if i > 5:
s = True
else:
s = False
__is_5g_enable = s
def __check_5g(self):
if self.__is_5g_enable:
print("5G话费套餐已订阅,5G网络开启!")
else:
print("5G网络关闭,使用4G网络")
def use_5G(self):
self.__check_5g()
class Phone_function:
import random
__current_voltage = random.randint(0, 2)
# 私有成员无法被类对象使用,但是可以被其他的成员使用
def __keep_single_core(self): # 成员变量和方法以__开头即为私有成员
print("CPU单核模式运行中")
def call_by_5G(self):
if self.__current_voltage >=1:
print("电量充足,5G通话权限已开启,请检查是否处于5G网络")
else:
print("电量不足,无法使用5G通话,并已设置为单核运行进行省电")
self.__keep_single_core()
class Phone_pro(Phone_5G):
# 继承了其他类的所有属性和行为
# 多继承中,如果父类有同名方法或属性,先继承的优先级高于后继承(左边优先于右边)
producer = "HUAWEI"
def print_process(self):
print("手机出现5G新功能啦!")
class Phone_final(Phone_pro, Phone_function):
def print_process(self):
super().print_process() # 通过调用来保留父类的方法
print(f"旧版的厂商是:{Phone_pro.producer}")
print("更换厂商完毕,已经更新到最新版本!") # 复写父类的方法
phone = Phone_final()
phone.print_process()
phone.use_5G()
phone.call_by_5G()
# pass表示无内容,可以在类定义后避免没有功能语句造成的语法错误
手机出现5G新功能啦!
旧版的厂商是:HUAWEI
更换厂商完毕,已经更新到最新版本!
5G话费套餐已订阅,5G网络开启!
电量不足,无法使用5G通话,并已设置为单核运行进行省电
CPU单核模式运行中
十三、多态
1. Introduction
# 多态:指的是多种状态,即完成某个行为时,使用不同的对象会得到不同的状态
# 以父类做定义声明,以子类做实际工作,用以获得同一行为,不同状态
class Animal:
def speak(self):
pass # 抽象方法:方法体是空实现
# 抽象类:父类确定有哪些方法,具体的方法实现由子类自行决定
# 顶层设计:好比一个标准,包含了一些抽象方法,要求子类必须一一实现
class Dog(Animal):
def speak(self):
print("汪汪汪")
class Cat(Animal):
def speak(self):
print("喵喵喵")
def make_noise(animal:Animal):
animal.speak()
dog = Dog()
cat = Cat()
make_noise(dog)
make_noise(cat)
汪汪汪
喵喵喵
2. Air Conditioner in Practice
class AC:
def make_cool(self):
pass
def make_warm(self):
pass
def make_move(self):
pass
class Media:
def make_cool(self):
print("美的空调制冷技术")
def make_warm(self):
print("美的空调制热技术")
def make_move(self):
print("美的空调上下摆风技术")
class Gree:
def make_cool(self):
print("格力空调制冷技术")
def make_warm(self):
print("格力空调制热技术")
def make_move(self):
print("格力空调上下摆风技术")
def open_air_conditioner(ac:AC):
ac.make_move()
ac.make_warm()
ac.make_cool()
midea = Media()
gree = Gree()
open_air_conditioner(midea)
print("=============================")
open_air_conditioner(gree)
美的空调上下摆风技术
美的空调制热技术
美的空调制冷技术
=============================
格力空调上下摆风技术
格力空调制热技术
格力空调制冷技术
十四、高阶技巧
1. Closure
# 在函数嵌套的前提下,内部函数使用了外部函数的变量,并且外部函数返回了内部函数
# 我们把这个使用外部函数变量的内部函数称为闭包
def account_create(account_amount=0):
def atm(num, deposit=True): # 缺省参数(默认值)只能是最后一个参数
nonlocal account_amount # 需要用nonlocal关键字,才能在内部函数中修改外部函数的变量
if deposit:
account_amount += num
print(f"存款{num}元,账户余额还剩{account_amount}元")
else:
account_amount -= num
print(f"取款{num}元,账户余额还剩{account_amount}元")
return atm
fn = account_create(10000) # 只有这一次可以更改账户余额初始值,并且获得atm函数
fn(2000)
fn(200, False)
for i in range(4):
deposit = bool(int((input("请输入存款(1)还是取款(0):")))) # int数据类型才能转bool
num = int(input("请输入操作余额:"))
fn(num, deposit)
存款2000元,账户余额还剩12000元
取款200元,账户余额还剩11800元
请输入存款(1)还是取款(0):1
请输入操作余额:200
存款200元,账户余额还剩12000元
请输入存款(1)还是取款(0):0
请输入操作余额:2000
取款2000元,账户余额还剩10000元
请输入存款(1)还是取款(0):1
请输入操作余额:5000
存款5000元,账户余额还剩15000元
请输入存款(1)还是取款(0):0
请输入操作余额:5000
取款5000元,账户余额还剩10000元
2. Decorator
# 装饰器就是创建一个闭包函数,在闭包函数内调用目标i函数
# 可以达到不改动目标函数的同时,增加额外的功能
def outer(func):
def inner():
print("我要睡觉了")
func()
print("我要起床了")
return inner
@outer
# 给sleep增加功能
def sleep():
import random
import time
print("睡眠中......Zzzz")
time.sleep(random.randint(1, 5))
sleep()
# 实际调用的是嵌套了sleep的outer
# fn = outer(sleep)
# fn()
我要睡觉了
睡眠中......Zzzz
我要起床了
3. Single Pattern
# 单例模式(single pattern)
# 是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在
class StrTools:
pass
s1 = StrTools()
s2 = StrTools()
print(s1)
print(s2)
# 发现不是同一个地址
str_tool = StrTools()
s3 = str_tool
s4 = str_tool
print(s3)
print(s4)
# 单例模式,只获取其唯一的类实例对象,并重复使用
# 节省内存,节省创建对象的开销
<__main__.StrTools object at 0x000001DA15F26E10>
<__main__.StrTools object at 0x000001DA17699510>
<__main__.StrTools object at 0x000001DA1711EB50>
<__main__.StrTools object at 0x000001DA1711EB50>
4. Factory Pattern
# 使用工厂类的get_person()方法去创建具体的类对象
# 大批量创建对象的时候有统一的入口,易于代码的维护
# 当发生修改,仅修改工厂类的创建方法即可
# 符合现实世界的模式,即有工厂来制作产品(对象)
class Person:
pass
class Worker(Person):
print("工人模式")
class Student(Person):
print("学生模式")
class Teacher(Person):
print("教师模式")
class Factory:
def get_person(self, p_type):
if p_type == 'w':
return Worker()
elif p_type == 's':
return Student()
else:
return Teacher()
factory = Factory()
worker = factory.get_person('w')
student = factory.get_person('s')
teacher = factory.get_person('t')
工人模式
学生模式
教师模式
5. Socket Service Port
"""
socket(简称套接字)是进程之间通信的一个工具,好比现实生活中的插座,所有的家用电器要想工作都是基于插座进行
进程之间想要进行网络通信需要socket,它负责进程之间的网络传输,好比数据的搬运工。
"""
import socket
socket_server = socket.socket()
# 创建socket对象
socket_server.bind(("localhost", 888))
# 绑定ip地址和端口(绑定的端口不能被占用)
socket_server.listen(1)
# 监听端口(listen方法内接收一个整数传参数,表示接受的链接数量)
result = socket_server.accept()
# 等待客户端连接
conn = result[0] # 客户端和服务端的链接对象
address = result[1] # 客户端的地址信息
# conn, address = socket_server.accept()
# accept方法返回的是二元元组(链接对象,客户端地址信息)
# accept方法是阻塞的方法,等待客户端的链接,如果没有链接,就卡在这一行不向下执行了
print(f"接收到了客户端链接,客户端的信息是:{address}")
while True:
data = conn.recv(1024).decode("UTF-8")
# recv接受的参数是缓冲区大小,一般给1024即可
# recv方法的返回值是一个字节数组 也就是bytes对象,不是字符串
# 可以通过decode方法用UTF-8解码,将字节数组转换为字符串对象
print(f"客户端发来的消息:{data}")
msg = input("请输入你要和客户端回复的消息:")
# encode可以将字符串对象转换为字节数组
if msg == 'exit':
break
conn.send(msg.encode("UTF-8"))
conn.close()
socket_server.close()
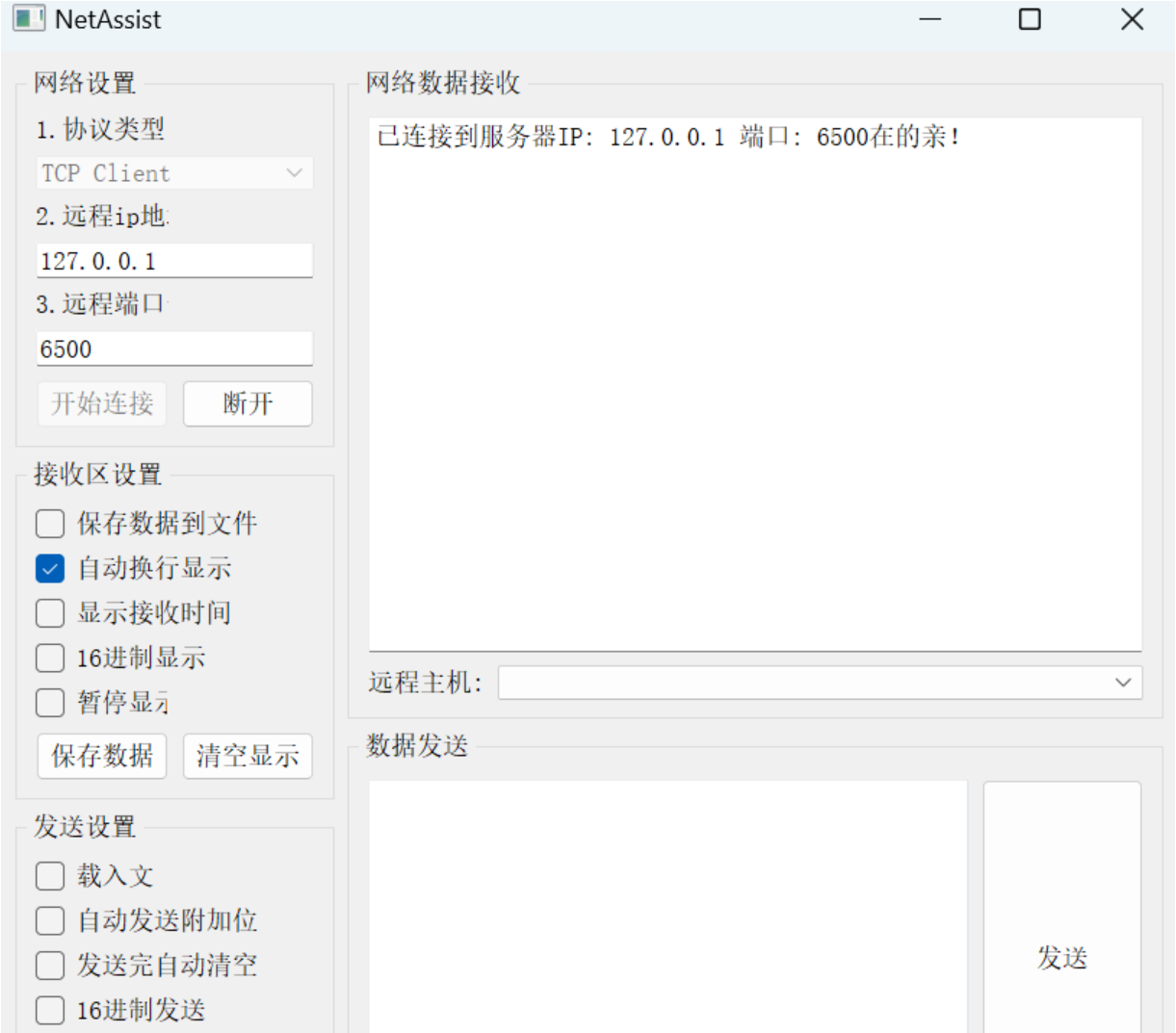
接收到了客户端链接,客户端的信息是:('127.0.0.1', 53482)
客户端发来的消息:在吗?
请输入你要和客户端回复你的消息:在的亲!
6. Socket Client Port
import socket
socket_client = socket.socket()
# 此程序可替代一个NetAssist作为client port
socket_client.connect(("localhost", 888))
while 1:
msg = input("请输入要给服务端发送的消息:")
socket_client.send(msg.encode("UTF-8"))
recv_data = socket_client.recv(1024)
print(f"服务端回复的消息是:{recv_data.decode('UTF-8')}")
if msg == 'exit':
break
socket_client.close()
7. Multiple Thread
"""
现代操作系统比如Mac OS X, UNIX, Linux, Windows等,都是只是”多任务的操作系统。
进程:就是一个程序,运行在系统之上,那么便称这个程序为一个运行进程,并分配进程ID方便系统管理。
线程:线程是归属于进程的,一个进程可以开启多个线程,执行不同的工作,是进程的实际工作最小单位。
"""
import threading
import time
def sing(behaviour):
while 1:
print(behaviour)
time.sleep(1)
def dance(behaviour):
while 1:
print(behaviour)
time.sleep(1)
sing_thread = threading.Thread(target=sing, args=("DIDADIDIDADI",)) # args以元组形式给执行任务传参
dance_thread = threading.Thread(target=dance, kwargs={"behaviour": "HHHHHHH"}) # kwargs以字典形式给执行任务传参
sing_thread.start()
dance_thread.start()
DIDADIDIDADI
HHHHHHH
HHHHHHH
DIDADIDIDADI
HHHHHHHDIDADIDIDADI
HHHHHHHDIDADIDIDADI
HHHHHHHDIDADIDIDADI
DIDADIDIDADIHHHHHHH
DIDADIDIDADI
HHHHHHH
HHHHHHHDIDADIDIDADI
DIDADIDIDADI
HHHHHHH
DIDADIDIDADIHHHHHHH
DIDADIDIDADI
HHHHHHH
HHHHHHH
DIDADIDIDADI
DIDADIDIDADIHHHHHHH
HHHHHHH
DIDADIDIDADI
8. Regularization
import re
# python正则表达式,使用re模块,并基于re模块中三个基础方法来做正则匹配
s1 = "python itheima"
s2 = "1python itheima"
s3 = "pythonghjgghjghjpythonhghgjhpythongugg"
s4 = "itheima"
result1 = re.match("python", s1)
# 从被匹配的字符串开头进行匹配,匹配成功返回匹配对象(包含匹配的信息)
result2 = re.match("python", s2)
# 匹配不成功则返回None
result3 = re.search("python", s2)
# 搜索整个字符串,找出匹配的第一个就停止
result4 = re.search("python", s4)
# 整个字符串找不到,则返回None
result5 = re.findall("python", s3)
# 匹配整个字符串,找出全部匹配项
result6 = re.findall("python", s4)
# 整个字符串找不到,返回空list:[]
print(result1)
print(result1.span())
print(result1.group())
print(result2)
print(result3)
print(result4)
print(result5)
print(result6)
<re.Match object; span=(0, 6), match='python'>
(0, 6)
python
None
<re.Match object; span=(1, 7), match='python'>
None
['python', 'python', 'python']
[]
9. Metacharacter Match
import re
s = 'itheima @@Python2 !!66'
result1 = re.findall(r'\w', s) # r会让字符串内转义字符无效
result2 = re.findall(f'[A-Z 0-9]', s)
result3 = re.findall(f'[ipth!]', s)
print(result1)
print(result2)
print(result3)
# 匹配账号,只能由字母和数字组成,长度限制到6到10位
r = '^[0-9 a-z A-Z]{6,10}$' # ^匹配开头,$匹配结尾
s1 = '704625068'
s2 = '50913523_'
print(re.findall(r, s1))
print(re.findall(r, s2))
# 匹配QQ号,要求纯数字,长度5-11,第一位不为0
r = '^[1-9][0-9]{4,10}$'
s3 = '020195908'
s4 = '20195908'
print(re.findall(r, s3))
print(re.findall(r, s4))
# 匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址
s5 = '704625068@qq.com'
r = '^([\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)$)' # .表示任何字符,但是表示本身要\.
print(re.findall(r, s5))
print(re.match(r, s5))
['i', 't', 'h', 'e', 'i', 'm', 'a', 'P', 'y', 't', 'h', 'o', 'n', '2', '6', '6']
[' ', 'P', '2', ' ', '6', '6']
['i', 't', 'h', 'i', 't', 'h', '!', '!']
['704625068']
[]
[]
['20195908']
[('704625068@qq.com', '', 'qq', '.com')]
<re.Match object; span=(0, 16), match='704625068@qq.com'>
10. Recurssion
import os
def test_os():
print(os.listdir("C:/Users/lenovo/Desktop/code")) # 列出路径下的内容
print(os.path.exists("C:/Users/lenovo/Desktop/code")) # 判断指定路径是不是文件夹
print(os.path.isdir("C:/Users/lenovo/Desktop/code")) # 判断指定路径是否存在
test_os()
def get_files_recurssion_from_dir(path):
"""
从指定文件夹中使用递归文件,获取全部文件夹列表
:param path: 被判断的文件夹
:return: 包含全部的文件,如果目录不存在则返回一个空list[]
"""
file_list = []
print(f"当前文件夹是{path}")
if os.path.exists(path):
for f in os.listdir(path):
new_path = path + "/" + f
if os.path.isdir((new_path)):
file_list +=get_files_recurssion_from_dir(new_path)
else:
file_list.append((new_path))
else:
print(f"指定的目录{path},不存在")
return []
return file_list
print(get_files_recurssion_from_dir("D:\福建农林大学-1-《点燃民族团结之火,绽放璀璨时代之光》"))
['.ipynb_checkpoints', 'C++', 'd2l-zh.zip', 'data', 'Devcpp', 'high.jpg', 'jupyter', 'jupyterpics', 'low.bmp', 'Matlab', 'pythonProject', 'Python_test', 'stone.cpp', 'ultralytics-main', 'YOLOv1', 'YOLOV1-pytorch-main.zip', 'YOLOv3', '单词翻译pyqt5']
True
True
当前文件夹是D:\福建农林大学-1-《点燃民族团结之火,绽放璀璨时代之光》
['D:\\福建农林大学-1-《点燃民族团结之火,绽放璀璨时代之光》/1_1_8.docx', 'D:\\福建农林大学-1-《点燃民族团结之火,绽放璀璨时代之光》/e86339661b236716fbf5efb24aea8914.mp4', 'D:\\福建农林大学-1-《点燃民族团结之火,绽放璀璨时代之光》/福籽同心爱中华(1).docx']


















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









