







· 核密度估计(Kernel Density Estmation,KDE)
认为在一定的空间范围内,某种事件在不同的地理位置上发生的概率是不一样的。
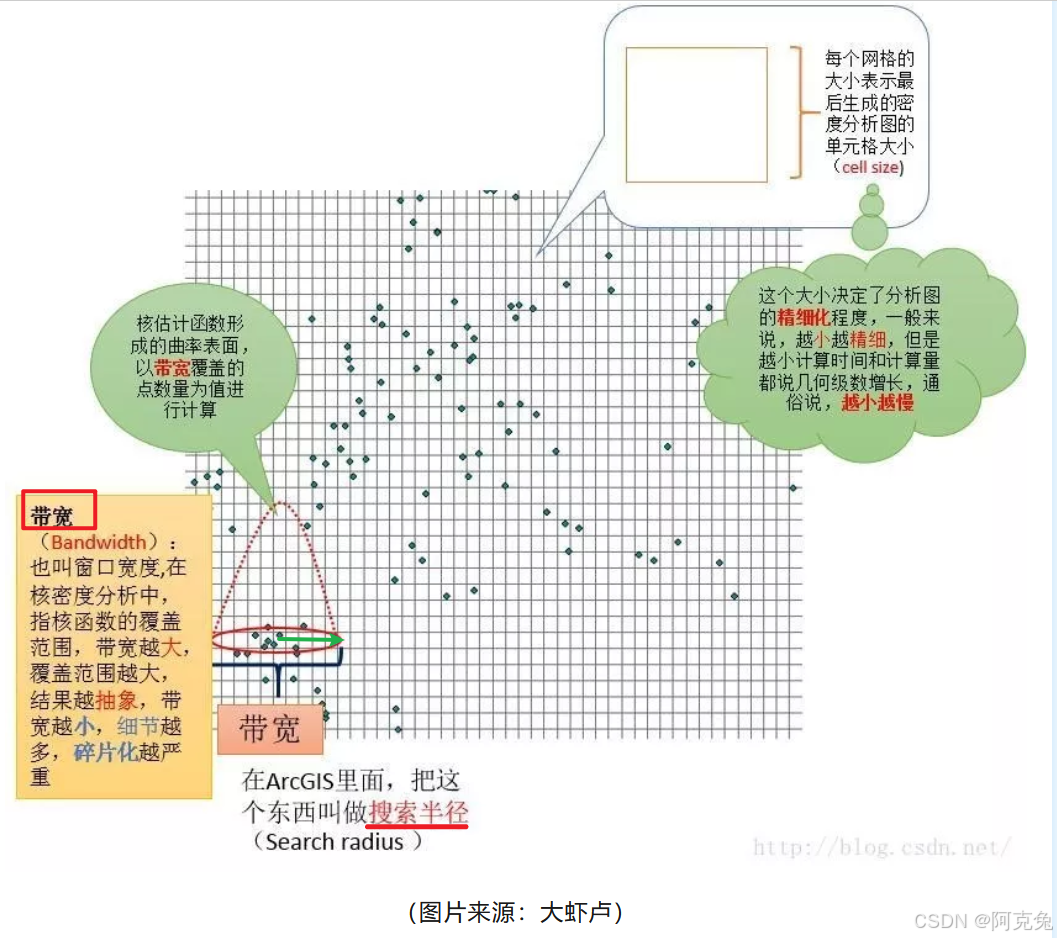
1 带宽/Bandwidth/窗口宽度/搜索半径/BW
覆盖点的彩色范围,越小越细节越碎片
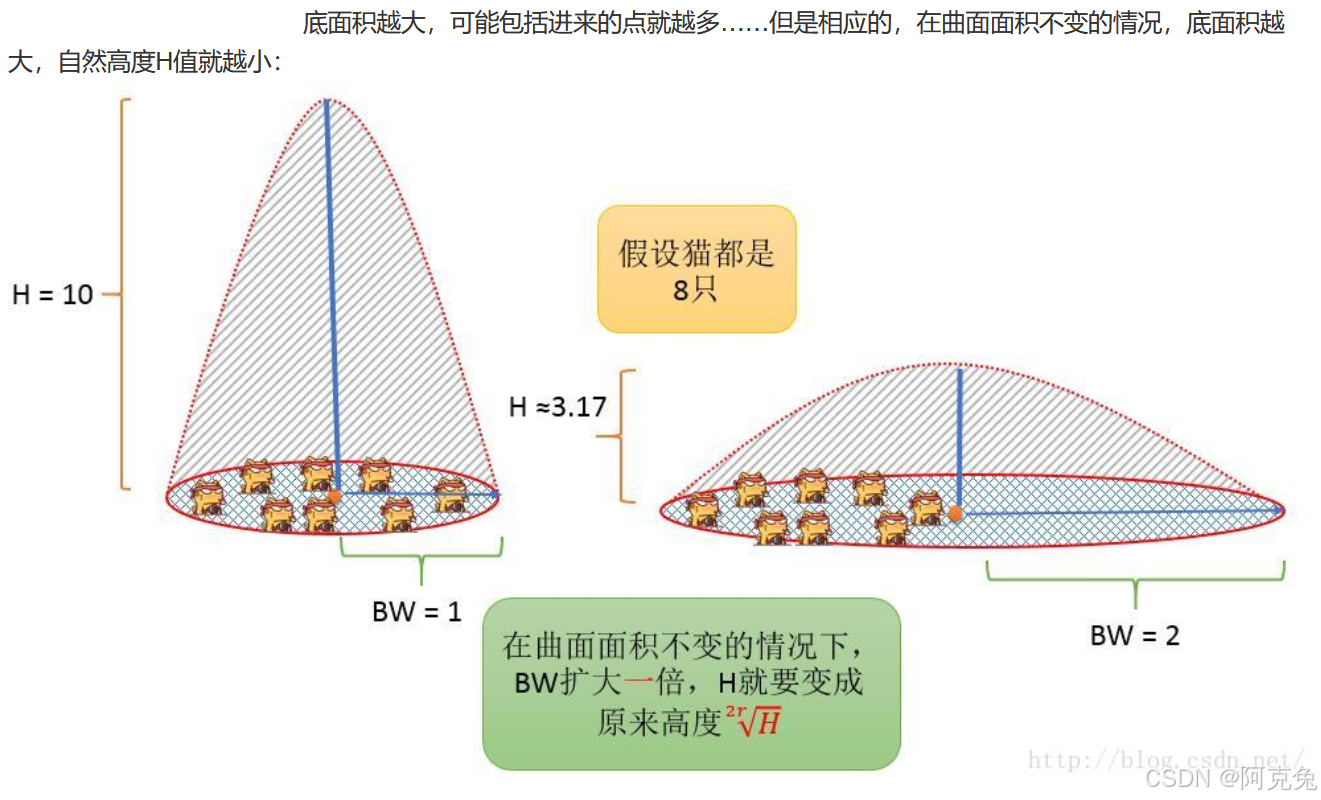
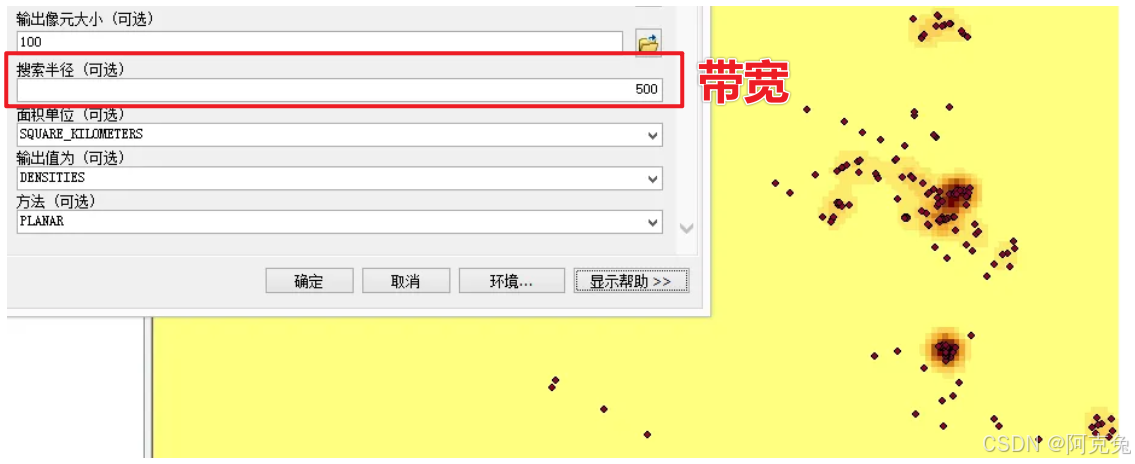 对比不同半径区别
对比不同半径区别
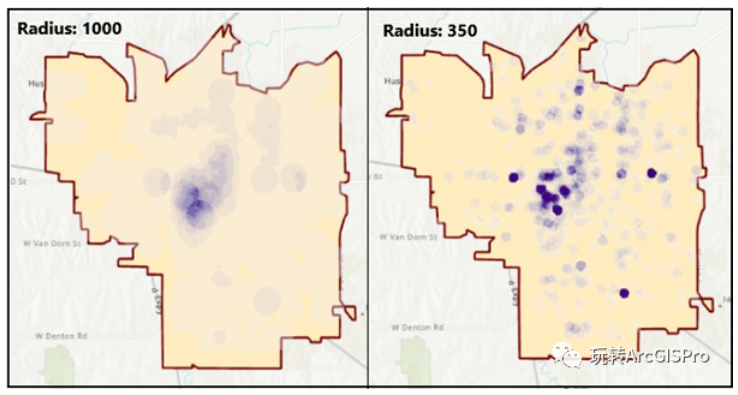
对比不同目标的半径选择
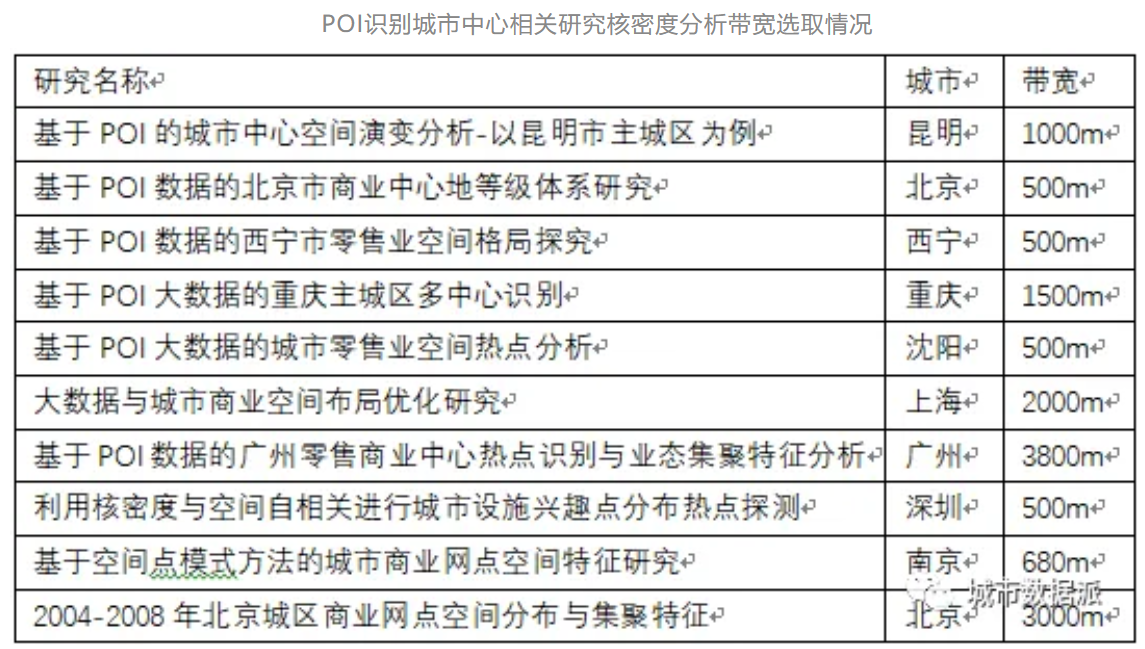
实例检测半径和识别中心关系
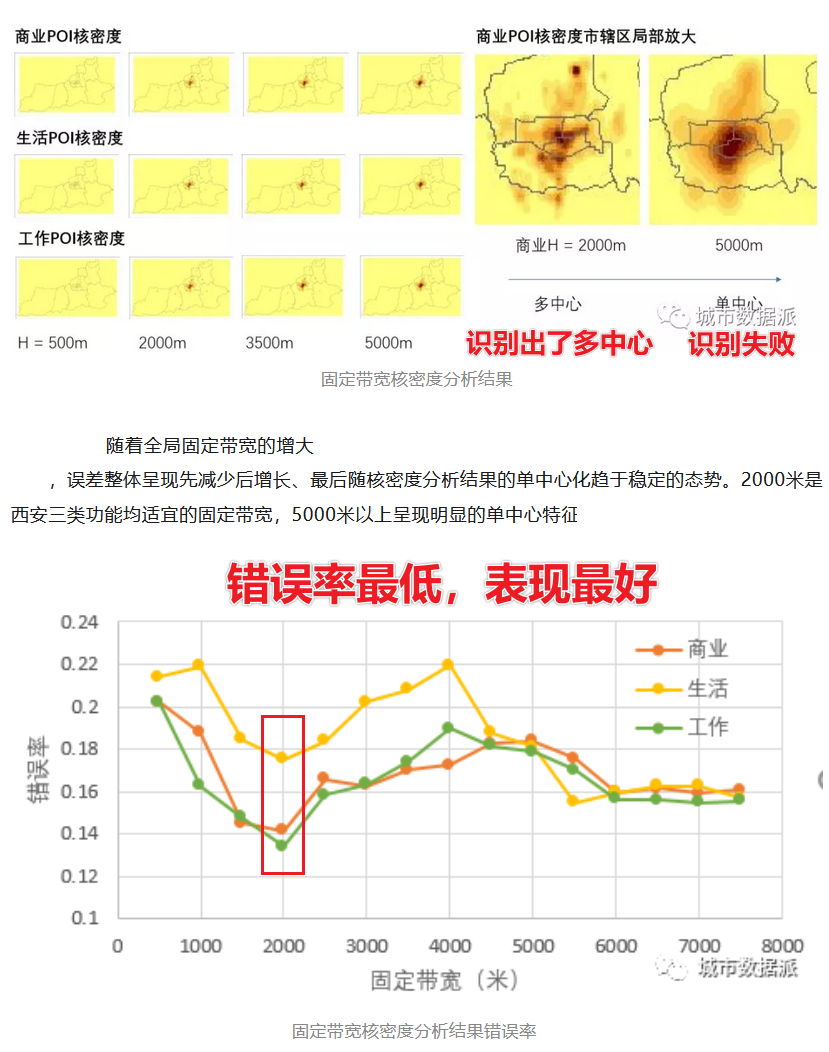 可以看到不同带宽的值对于聚类点的数量有显著影响~
可以看到不同带宽的值对于聚类点的数量有显著影响~
2 像元/Pixel
网格尺寸,越小越精细越慢
3 population 字段/权重字段
用于指定每个地理要素(如点、线、面)对周围区域密度计算的贡献大小。
以X市的学校分布为例,现在需要分析学校对周边区域的 “教育资源密度”,而不仅仅是学校数量。例如学校 A 有 2000 名学生,学校 B 有 500 名学生。计算时,学校 A 的权重是 2000,学校 B 的权重是 500。学校 A 周围的像元会因为学生人数多而获得更高的密度值,即使学校数量相同。
也就是需要另外一列数据进行综合占比计算考虑
4 掩膜/Mask
限制分析范围的工具,只计算特定区域内的地理要素密度
一般导入的掩膜数据为行政边界
5 自然断点法/Natural Breaks
将连续的密度值划分为不同等级的分类方法。它通过分析数据本身的分布规律,自动找到 “自然间隙” 作为分类断点,使同类数据内部差异最小,不同类之间差异最大。
研究方法参考:
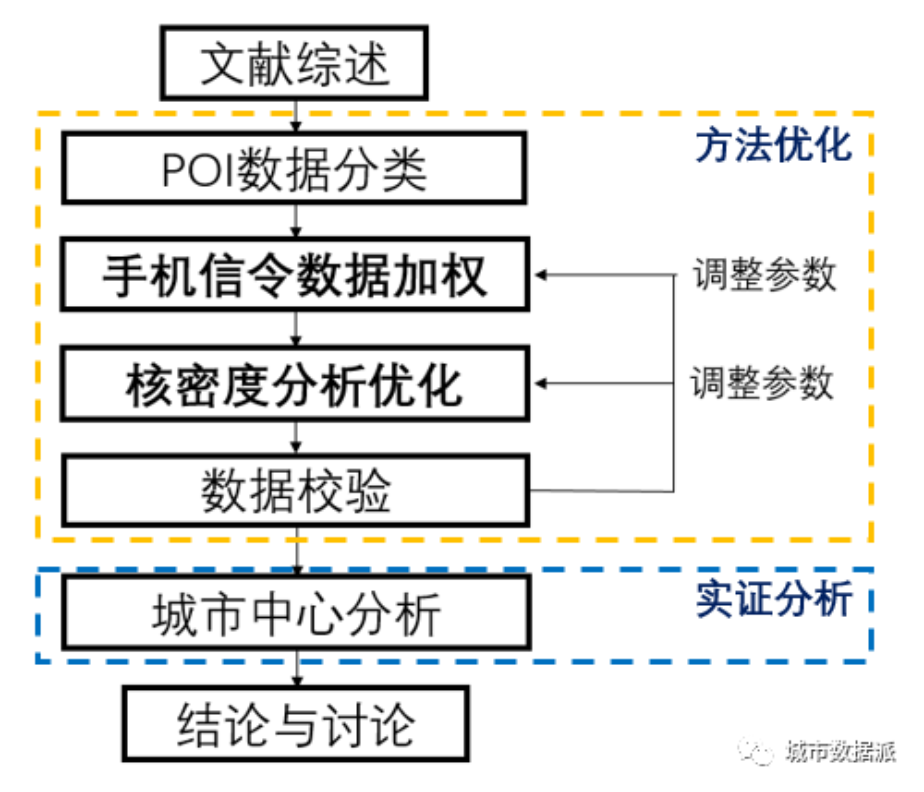
手机信令加权,弥补POI难以体现社会经济活动强度的不足,通过对手机信令数据的挖掘,对活动强度高的POI点进行权重提升。

















 5953
5953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









