







序列化(serialization):将对象的状态信息(如Python的简单的数据类型list ,string,dict,tuple,int,float, unicode)转换成可存储或者可传输的内容(如 json、xml格式)的过程
反序列化:从存储文件或存储区域(json、xml)中读取需要反序列化的对象的状态,并重建该对象
Json(javascript object notation):一种轻量级数据交换格式,相对于xml更简单、易阅读、编写、解析和生成,json是javascript中的一个子集
Python中集成了json模块
序列化:enconding——把一个Python对象编码转换成json字符串
反序列化:decoding——把一个json字符串解码转换成Python对象
json 包中有JSONEncode 和JSONDecoder 两个类实现Json字符串和dict类型数据的转换
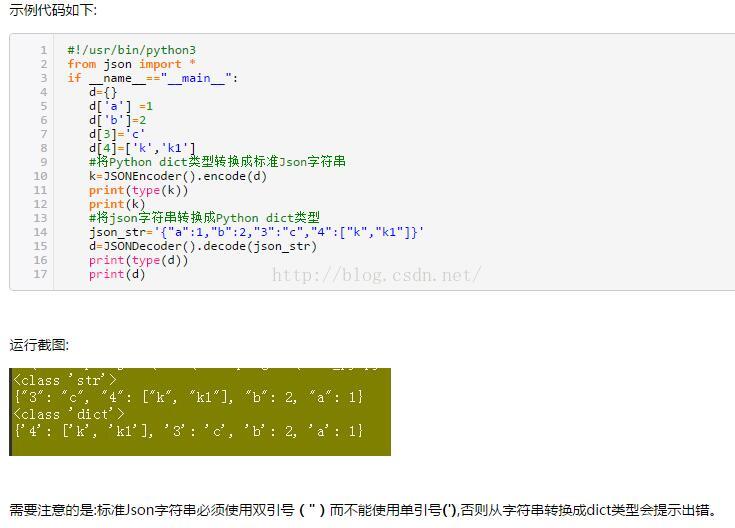
例:序列化方式:(Python对象转换成json的对照图)
import json
data={'a':1,'b':2,'c':3}#或者data=['a','b','c',1,3]或data=(3,3,4,5)等Python对象都可以
f=open("./test.txt","w")
data_string=json.dumps(data)#方式1
f.write(data_string)
f.write('\n')#write不会在自动行末加换行符,需要手动加上
sort_data_string=json.dumps(data,sort_keys=True)#方式1,字典按keys顺序编码
f.write(sort_data_string)
f.write('\n')
json.dump(data,f)#方式2,注意dump没有s
f.write('\n')
f.close()
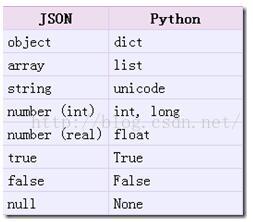
反序列化:(json 对象转换成Python对象的对照图)
f=open("./test.txt","r")
for line in f:
decodes=json.loads(line)
print type(decodes)
print decodes #输出key前会带一个u,类似[{u'a': u'A', u'c': 3.0, u'b': [2, 4]}]
f.close()
附加:dumps(data, indent=2)indent参数根据数据格式缩进显示,读起来更加清晰:
dumps(data, separators):separators参数的作用是去掉,,:后面的空格,从上面的输出结果都能看到", :"后面都有个空格,这都是为了美化输出结果的作用,但是在我们传输数据的过程中,越精简越好,冗余的东西全部去掉,因此就可以加上例:
import json
data = [{'a':"A",'b':(2,4),'c':3.0}] #list对象
data_string = json.dumps(data)
print "ENCODED:",data_string
decoded = json.loads(data_string)
print "DECODED:",decoded
print "ORIGINAL:",type(data[0]['b'])
print "DECODED:",type(decoded[0]['b'])
输出:
ENCODED: [{"a": "A", "c": 3.0, "b": [2, 4]}]
DECODED: [{u'a': u'A', u'c': 3.0, u'b': [2, 4]}]
ORIGINAL: <type 'tuple'>
DECODED: <type 'list'>
解码过程中,json的数组最终转换成了python的list,而不是最初的tuple类型
在encoding过程中,dict对象的key只可以是string对象,如果是其他类型,那么在编码过程中就会抛出ValueError的异常。skipkeys可以跳过那些非string对象当作key的处理.
import json
data= [ { 'a':'A', 'b':(2, 4), 'c':3.0, ('d',):'D tuple' } ]
try:
print json.dumps(data)
except (TypeError, ValueError) as err:
print 'ERROR:', err
print
print json.dumps(data, skipkeys=True)
输出:
ERROR: keys must be a string
[{"a": "A", "c": 3.0, "b": [2, 4]}]














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









