










Programming Exercise 6:Support Vector Machines
这周总结一下Week7的作业,利用SVM实现垃圾邮件分类,作业中并未要求实现SVM的训练过程,所以总体上来说难度不大。
首先看一下作业要求(打星号的需要提交):


别看文件多,但是要求提交的只有四个。
一. ex6
gaussianKernel.m要求实现高斯型核函数。
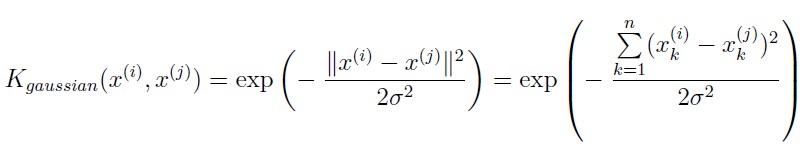
编程无难度。
sim=sim+exp(-(x1-x2)'*(x1-x2)/2/sigma^2);dataset3Params.m选择使测试误差达到最小时的参数C, sigma。
err=10000;
temp=[0.01,0.03,0.1,0.3,1,3,10,30];
for i=1:length(temp)
for j=1:length(temp)
model= svmTrain(X, y, temp(i), @(x1, x2) gaussianKernel(x1, x2,temp(j)));
predictions = svmPredict(model, Xval);
if(err>mean(double(predictions ~= yval)))
err=mean(double(predictions ~= yval));
C=temp(i);
sigma=temp(j);
end
end
end
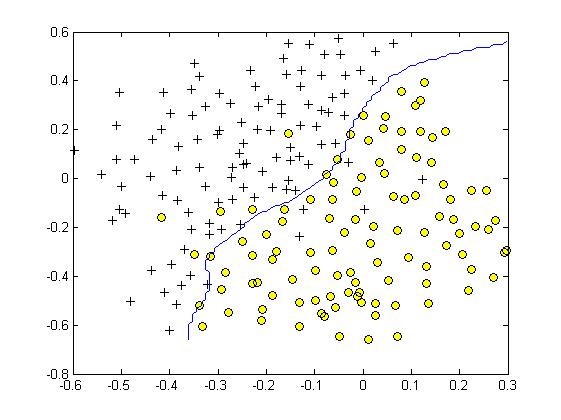
其中svmTrain中使用了SMO算法,结果如下。
二. ex6_spam
processEmail.m 在一个单词序列中查找每一个邮件单词,如果含有 则将其在单词序列中的位置加 入 word_indices 。for i=1:length(vocabList)
if(strcmp(vocabList(i),str))
word_indices=[word_indices;i];
end
end
emailFeatures.m将word_indices中对应位置的单词进行标记。
for i=1:length(word_indices)
x(word_indices(i))=1;
end
训练误差为99.85,测试误差为98.80。
总结一下,这次作业基本无难度,但是要把整个邮件检测系统搞明白,例如邮件中字符处理,SVM的训练过程等真的需要一段时间。















 4388
4388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









