










Programming Exercise 7: K-means Clustering and Principal Component Analysis
这周总结一下Week8的作业,第一部分需要实现K-means聚类并应用算法来压缩图片,第二部分需要利用PCA构造保留人脸图片主要信息的低维向量来重新表示图片。
首先看一下作业要求。


文件略多,不过难度都不大。
一.ex7
kMeansInitCentroids中心初始化,直接在X个元素中取K个随机数,将选中的元素作为初始中心。函数输入X和K值,返回centroids。
rd=randi(size(X,1),1,K);
centroids=centroids+X(rd,:);
findClosestCentroids初始化完自然是找X中每个元素距离最近的中心,centroids由K个中心所对应的特征向量组成,idx用来记录离每个点最近的中心。函数输入X和centroids,返回idx。
for i=1:size(X,1)
adj=sqrt((X(i,:)-centroids(1,:))*(X(i,:)-centroids(1,:))');
idx(i)=1;
for j=2:K
temp=sqrt((X(i,:)-centroids(j,:))*(X(i,:)-centroids(j,:))');
if(temp<adj)
idx(i)=j;
adj=temp;
end
end
end
computeCentroids在找到每个X元素距离最近的中心后需要重新更新中心的特征向量,具体方法就是求所有该中心内部点的均值。输入X和idx,返回centorids。
for i=1:K
if(size(find(idx==i),2)~=0)
centroids(i,:)=mean(X(find(idx==i),:));
else
centroids(i,:)=zeros(1,n);
end
end
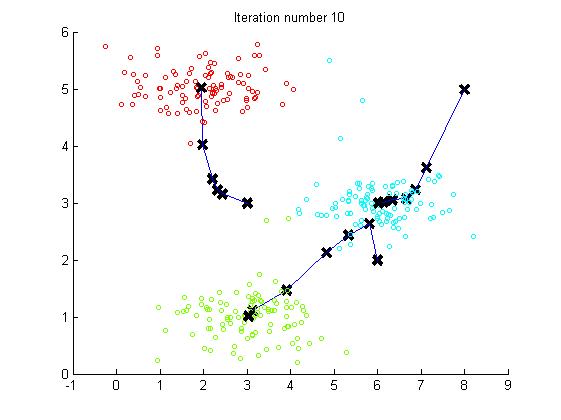
每一步迭代,中心变化的过程展示的很清楚,结果的可视化可以帮助更好的理解算法运行的整个过程,下面是最后一步的结果。
使用16种颜色作为中心,用K-means对图片进行压缩,效果如下。

二.ex7_pca
主成分分析的本质就是先对原数据的维数,用特征向量做为变换矩阵做线性变换再根据对应的特征值,选择尽量少的维数向量来表示原来大部分的信息(低秩近似),从而达到降维的目的。
实现方法是利用MATLAB中的svd函数,[U, S, V] = svd(Sigma),其中Sigma是A的协方差矩阵,U和V是正交阵也是A的奇异矩阵,S是A的奇异值构成的对角阵。我们要用的是U和S,S的对角线元素按递减顺序排列。Pca中使用的特征向量已经做过预处理(正规化,减均值再除方差,目的是使元素在同一范围内),先算协方差矩阵,再进行奇异值分解。函数返回U和S。
sigma=X'*X/m;
[U,S,V]=svd(sigma);projectData是将矩阵降到K维,输入为X,U,K,输出为Z。
Z=X*U(:,1:K);recoverData是将降维后的矩阵再升维成与原矩阵相同维数,目的是用来计算变换前后造成的误差。
X_rec=Z*U(:,1:K)';结果如下:变换前
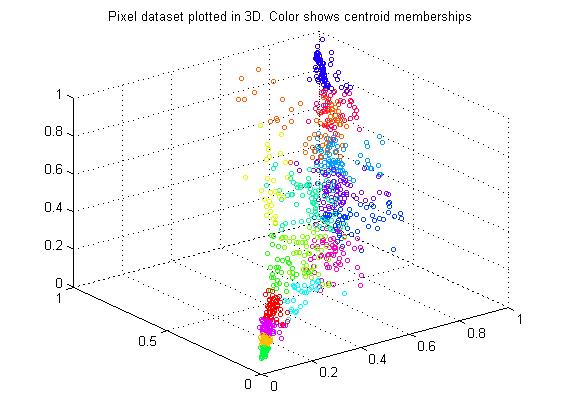
变换后:

总结一下:SVD的原理就是线性变换,但是其中蕴含的思想值得深思。














 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









