







Logistic Regression
在分类问题中,你要预测的变量 y 是离散的值,我们将学习一种叫做逻辑回归 (Logistic
Regression) 的算法,这是目前最流行使用最广泛的一种学习算法。

spam 垃圾邮件。transaction 交易;fraudulent 欺骗的:tumor 肿瘤;
肿瘤诊断问题的目的是告诉病人是否为恶性肿瘤,是一个二元分类问题(binary class problems)。其中 0 表示负向类(negative class),代表恶性肿瘤("-"),1 为正向类(positive class),代表良性肿瘤("+")。
如果我们要用线性回归算法来解决一个分类问题,对于分类, y 取值为 0 或者 1,但
如果你使用的是线性回归,那么假设函数的输出值可能远大于 1,或者远小于 0。所以我们在接下来的要研究的算法就叫做逻辑回归算法,这个算法的性质是:它的输出值永远在 0 到 1 之间。
逻辑回归算法是分类算法,我们将它作为分类算法使用。有时候可能因为这个算法的名字中出现了“回归”使你感到困惑,但逻辑回归算法实际上是一种分类算法,它适用于标签 y 取值离散的情况,如: 1 0 0 1。
Hypothesis Representation
我们引入一个新的模型,逻辑回归,该模型的输出变量范围始终在 0 和 1 之间。 逻辑
回归模型的假设是: hθ(x)=g(θTX)。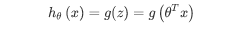
X 代表特征向量
g 代表逻辑函数(logistic function)是一个常用的逻辑函数为 S 形函数(Sigmoid function),公式为:
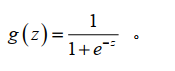
该函数的图像为:

合起来,我们得到逻辑回归模型的假设:

Decision Boundary

并且参数 θ 是向量[-3 1 1]。 则当-3+x1+x2 大于等于 0,即 x1+x2 大于等于 3 时,模型将预测 y=1。 我们可以绘制直线 x1+x2=3,这条线便是我们模型的分界线,将预测为 1 的区域和预测为 0 的区域分隔开。

决策边界就是分类的分界线,本质上就是当取了最合适的θ后,对应的Z这个函数的图像。(如上图,就是 x1和x2这两个变量)
当然,通过一些更为复杂的多项式即Z**(直线 1次,曲线2次,等等画图规律决定多项式次数)**,还能拟合那些图像显得非常怪异的数据,使得决策边界形似碗状、爱心状等等。
Cost Function
为了得到最优的多项式,先要定义用来拟合逻辑回归模型的优化目标也就是代价函数。
线性回归的代价函数为所有模型误差的平方和:
理论上来说,我们也可以对逻辑回归模型沿用这个定义,也就是

但是问题在于,当我们将
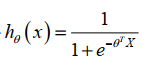
带入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数(non-convex function)。

这类讨论凸函数最优值的问题,被称为凸优化问题(Convex optimization)。为了成为凸函数,这里需要选择适当的代价函数。
代价函数也就是误差模型不止平方损失函数一种。对于逻辑回归,更换平方损失函数为对数损失函数,可由统计学中的最大似然估计方法推出代价函数的原型 :

hθ(x)与 Cost(hθ(x),y)之间的关系如下图所示:

这样构建的 Cost(hθ(x),y)函数的特点是:当实际的结果y=1(规定为正样本), 随着预测值趋于1,那么代价函数的值会趋于0,即表示真实值和预测值的差趋于0,那么拟合也就非常好。如果预测值趋于0,则代价函数趋于无穷,即差别很远,拟合程度差。
数学知识:如果a的x次方等于N(a>0,且a不等于1),那么数x叫做以a为底N的对数(logarithm),记作x=logaN。其中,a叫做对数的底数,N叫做真数。 指数是幂运算aⁿ(a≠0)中的一个参数,a为底数,n为指数,指数位于底数的右上角,幂运算表示指数个底数相乘。把幂看作乘方的结果。
巧妙的利用分类,代入分类数让多余项消失掉。将构建的 Cost(hθ(x),y)简化如下:
基于这种形式的代价函数就是一种凸函数了,就可以用梯度下降算法来优化求得使代价函数最小的参数。
除了梯度下降算法以外, 还有一些常被用来令代价函数最小的算法,这些算法更加复杂和优越,而且通常不需要人工选择学习率,通常比梯度下降算法要更加快速。这些算法有:共轭梯度(Conjugate Gradient), 局部优化法(四个作者名字,BFGS)和有限内存局部优化法(LBFGS)。
这三种算法优点:
不需要手动选择学习率 α, 所以对于这些算法的一种思路是, 给出计算导数项和代价函数的方法, 他们有一个智能的内部循环, 称为线性搜索(line search)算法, 它可以自
动尝试不同的学习速率 α, 并自动选择一个好的学习速率 α, 因此它甚至可以为每次迭代选择不同的学习速率, 那么你就不需要自己选择。 这些算法实际上在做更复杂的事情, 而不仅仅是选择一个好的学习率, 所以它们往往最终收敛得远远快于梯度下降。
我们成功使用这些算法, 并应用于许多不同的学习问题, 不需要真正理解这些算法的内环间在做什么, 如果说这些算法有缺点的话, 那么我想说主要缺点是它们比梯度下降法复杂多了, 特别是你最好不要使用 L-BGFS、 BFGS 这些算法, 除非你是数值计算方面的专家。
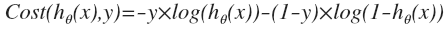
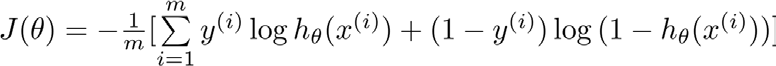


fminunc 是 matlab 中带的一个最小值优化函数,使用时我们需要提供代价函数和每个参数的求导,下面是使用 fminunc 函数的代码示例:
function [jVal, gradient] = costFunction(theta)
jVal=(theta(1)-5)^2+(theta(2)-5)^2; %jVal = [...code to compute J(theta)...]; 代价函数 jval
gradient=zeros(2,1); %gradient = [...code to compute derivative of J(theta)...];
gradient(1)=2*(theta(1)-5);
gradient(2)=2*(theta(2)-5);
end
options = optimset('GradObj', 'on', 'MaxIter', '100'); %解释见下面
initialTheta = zeros(2,1); %给出一个 θ 的猜测初始值, 它是一个 2× 1 的零向量
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options); %解释见下面
1.你要设置几个 options, 这个 options 变量作为一个数据结构可以存储你想要的options,所以 GradObj 和 On, 这里设置梯度目标参数为打开(on), 这意味着你现在确实要给这个算法提供一个梯度, 然后设置最大迭代次数, 比方说 100。
2. 调用 fminunc, 这个@符号表示指向我们刚刚定义的costFunction 函数的指针。 如果你调用它, 它就会使用众多高级优化算法中的一个, 当然你也可以把它当成梯度下降, 只不过它能自动选择学习速率 α, 你不需要自己来做。 然后它会尝试使用这些高级的优化算法, 就像加强版的梯度下降法, 为你找到最佳的 θ 值。
3. θ就是梯度值gradient,costFunction 函数就是代价函数。















 1302
1302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









