









1. Brute force.
该方法又称暴力搜索,也是最容易想到的方法。
预处理时间 O(0)
匹配时间复杂度O(N*M)
主要过程:从原字符串开始搜索,若出现不能匹配,则从原搜索位置+1继续。
- /*
- * === FUNCTION ======================================================================
- * Name: bf
- * Description: brute-force method for string match problem.
- * =====================================================================================
- */
- int bf(const char *text, const char *find)
- {
- if (text == '/0' || find == '/0')
- return -1;
- int find_len = strlen(find);
- int text_len = strlen(text);
- if (text_len < find_len)
- return -1;
- char *s = text;
- char *p = s;
- char *q = find;
- while (*p != '/0')
- {
- if (*p == *q)
- {
- p++;
- q++;
- }
- else
- {
- s++;
- p = s;
- q = find;
- }
- if (*q == '/0')
- {
- return (p - text) - (q - find);
- }
- }
- return -1;
- }
2,KMP.
KMP是经典的字符串匹配算法。
预处理时间:O(M)
匹配时间复杂度:O(N)
主要过程:通过对字串进行预处理,当发现不能匹配时,可以不进行回溯。
- /*
- * === FUNCTION ======================================================================
- * Name: kmp
- * Description: kmp method for string match.
- * =====================================================================================
- */
- /*
- * examples of prepocessing for pattern
- * pattern_1:
- * a b c a b c a
- * 0 0 0 0 1 2 3
- * pattern_2:
- * a a a a b a a
- * 0 0 0 0 0 0 1
- */
- int kmp(const char *text, const char *find)
- {
- if (text == '/0' || find == '/0')
- return -1;
- int find_len = strlen(find);
- int text_len = strlen(text);
- if (text_len < find_len)
- return -1;
- int map[find_len];
- memset(map, 0, find_len*sizeof(int));
- //initial the kmp base array: map
- map[0] = 0;
- map[1] = 0;
- int i = 2;
- int j = 0;
- for (i=2; i<find_len; i++)
- {
- while (1)
- {
- if (find[i-1] == find[j])
- {
- j++;
- if (find[i] == find[j])
- {
- map[i] = map[j];
- }
- else
- {
- map[i] = j;
- }
- break;
- }
- else
- {
- if (j == 0)
- {
- map[i] = 0;
- break;
- }
- j = map[j];
- }
- }
- }
- i = 0;
- j = 0;
- for (i=0; i<text_len;)
- {
- if (text[i] == find[j])
- {
- i++;
- j++;
- }
- else
- {
- j = map[j];
- if (j == 0)
- i++;
- }
- if (j == (find_len))
- return i-j;
- }
- return -1;
- }
注意:在预处理中,表面看起来时间复杂度为O(N^2),但是为什么是线性的,在时间复杂度分析中中,通过观察变量的变化来统计零碎的、执行次数不规则的情况,这种方法叫做摊还分析。我们从上述程序的j 值入手。每一次执行上述循环预处理语句中的第二个else时都会使j减小(但不能减成负的),而另外的改变j值的地方只有一处。每次执行了这一处,j都只能加1;因此,整个过程中j最多加了M-1个1。于是,j最多只有M-1次减小的机会(j值减小的次数当然不能超过M-1,因为j永远是非负整数)。这告诉我们,while循环总共最多执行了M-1次。按照摊还分析的说法,平摊到每次for循环中后,一次for循环的复杂度为O(1)。整个过程显然是O(M)的。另外关于KMP的详细分析,可以参考Matrix67KMP算法详解。
3,Boyer Moore
Boyer Moore是字符串匹配算法中的经典,可以参考论文a faster string searching algorithm。
预处理时间O(N + M^2)
匹配时间复杂度O(N)
主要过程:通过预处理原字符串以及待匹配字串,从而在匹配失败时可以跳过更多的字符。
- /*
- * === FUNCTION ======================================================================
- * Name: bm
- * Descritexttion: Boyer–Moore method for string match.
- *======================================================================================
- */
- int bm(const char *text, const char *find)
- {
- if (text == '/0' || find == '/0')
- return -1;
- int i, j, k;
- int text_len = strlen(text);
- int find_len = strlen(find);
- if (text_len < find_len)
- return -1;
- int delta_1[CHAR_MAX];
- for (i=0; i<CHAR_MAX; i++)
- delta_1[i] = find_len;
- for (i=0; i<find_len; i++)
- delta_1[find[i]] = find_len - i - 1;
- int rpr[find_len];
- rpr[find_len-1] = find_len - 1;
- for (i=find_len-2; i>=0; i--)
- {
- int len = (find_len - 1) - i;
- //find the reoccurence of the right most (len) chars
- for (j=find_len-2; j>=(len-1); j--)
- {
- if (strncmp(find+i+1, find+j-len+1, len) == 0)
- {
- if ((j-len) == -1 || find[i] != find[j-len])
- {
- rpr[i] = j - len + 1;
- break;
- }
- }
- }
- //if the right most (len) chars not completely occur, we find the right
- //substring of (len). every step, we try to find the right most (len-k)
- //chars.
- for (k=1; j<(len-1) && k<len; k++)
- {
- if (strncmp(find+i+k, find, len-k) == 0)
- {
- rpr[i] = 0 - k;
- break;
- }
- }
- if (j<(len-1) && k == len)
- {
- rpr[i] = 0 - len;
- }
- }
- int delta_2[find_len];
- for (i=0; i<find_len; i++)
- delta_2[i] = find_len - rpr[i];
- i = find_len - 1;
- j = find_len - 1;
- while (i < text_len)
- {
- if (text[i] == find[j])
- {
- i--;
- j--;
- }
- else
- {
- if (delta_1[text[i]] > delta_2[j])
- {
- i += delta_1[text[i]];
- }
- else
- {
- i += delta_2[j];
- }
- j = find_len - 1;
- }
- if (j == -1)
- return i+1;
- }
- return -1;
- }
提示:该算法主要利用坏字符规则和好后缀规则进行转换。所谓坏字符规则,是指不能匹配时的字符在待匹配字串中从右边数的位置;而好后缀规则则是指子串中从该不匹配位置后面所有字符(都是已匹配字符)再次在字串中出现的位置(k),其中s[k,k+1,---,k+len-j-1] = s[j+1, j+1,---,len-1], 并且s[k-1] != [j] || s[k-1] = $, 其中$表示增补的字符,可以与任何字符相等。
举例来说,对于字串ABCXXXABC
-4 -3 -2 -10 1 23 4 56 7 89
A BC X XX A BC
j=9 9//NULL->其值为当前位置。
j=8 $0 //C->虽然出现在3,但[2] = [j],所以不满足
j=7 $$ -1 //BC出现在开始[2],但[1]=[j]
j=6 1 //ABC
j=5 $0 //XABC
j=4 $$ -1 //XXABC
j=3 $$ $ -2 //XXXABC
j=2 $ $ $$ -3 //CXXXABC
j=1 $ $ $$ $ -4 //BCXXXABC
4, Sunday
Sunday算法比较简单,其实就是利用Boyer Moore中的坏字符规则,实现起来简单,效果也还不错。
预处理时间O(M)
匹配时间复杂度O(N*M)
- /*
- * === FUNCTION ======================================================================
- * Name: sunday
- * Description: sunday method for string match.
- * =====================================================================================
- */
- int sunday(const char *text, const char *find)
- {
- if (text == '/0' || find == '/0')
- return -1;
- char map[CHAR_MAX];
- int i;
- int text_len = strlen(text);
- int find_len = strlen(find);
- if (text_len < find_len)
- return -1;
- //preprocess
- for (i=0; i<CHAR_MAX; i++)
- map[i] = find_len + 1;
- for (i=0; i<find_len; i++)
- map[find[i]] = find_len - i;
- //match process
- i = 0;
- while (i <= (text_len - find_len))
- {
- if (strncmp(find, text + i, find_len) == 0)
- return i;
- else
- i += map[text[i + find_len]];
- }
- return -1;
- }
5, Robin-Karp
Robin-Karp主要利用HASH函数来处理字串,从而完成匹配。
预处理时间O(0)
最坏匹配时间复杂度O(N*M)
- /*
- * === FUNCTION ======================================================================
- * Name: robin_karp
- * Description: robin_karp method for string match problem.
- * =====================================================================================
- */
- // karp_robin need a hash function
- int hash(const char *s, unsigned int len)
- {
- int result = 0;
- int base = 3;
- int i;
- for (i=0; i<len; i++)
- {
- result += s[i];
- result *= base;
- }
- result /= base;
- return result;
- }
- int robin_karp(const char *text, const char *find)
- {
- if (text == '/0' || find == '/0')
- return -1;
- int i, j;
- int text_len = strlen(text);
- int find_len = strlen(find);
- if (text_len < find_len)
- return -1;
- int h_find = hash(find, find_len);
- int h_tmp = 0;
- for (i=0; i<=(text_len-find_len); i++)
- {
- h_tmp = hash(text+i, find_len);
- if (h_tmp == h_find)
- {
- for (j=0; j<find_len; j++)
- {
- if (find[j] != text[i+j])
- {
- break;
- }
- }
- if (j == find_len)
- return i;
- }
- }
- return -1;
- }
注意:主要依赖于hash函数的设计。
6, Bitap
Bitap算法主要利用位运算进行字符串的匹配,其匹配过程可以看作是有穷自动机中状态的转换,按照字串(pattern)的连续分解状态进行转换,从而到达终点,此时匹配过程完成。
预处理时间O(M)
最坏匹配时间复杂度O(N*M)
- /*
- * === FUNCTION ======================================================================
- * Name: bitap
- * Description: bitap method.
- *=======================================================================================
- */
- int bitap(const char *text, const char *find)
- {
- if (text == '/0' || find == '/0')
- return -1;
- int text_len = strlen(text);
- int find_len = strlen(find);
- if (text_len < find_len)
- return -1;
- int i = 0;
- int j = find_len - 1;
- char map[find_len + 1];
- map[0] = 1;
- for (i=1; i<=find_len; i++)
- {
- map[i] = 0;
- }
- for (i=0; i< text_len; i++)
- {
- for (j=find_len-1; j>=0; j--)
- {
- map[j+1] = map[j] & (text[i] == find[j]);
- }
- if (map[find_len] == 1)
- {
- return i - find_len + 1;
- }
- }
- return -1;
- }
注意:Bitap匹配算法中可以改用位移操作实现,从而将匹配复杂度从O(N*M)降低到O(N)。
总结,以上算法中,性能较好的为KMP,BM, 实现简单的为BF,Sunday,Bitap。两者折中来看,KMP表现较好。
预处理时间 匹配时间复杂度
BF O(0) O(N*M)
KMP O(M) O(N)
BM O(N+M^2)O(N)
Sunday O(M)O(N*M)
Robin-Karp O(0)O(N*M)
Bitap O(M) O(N*M)->O(N)
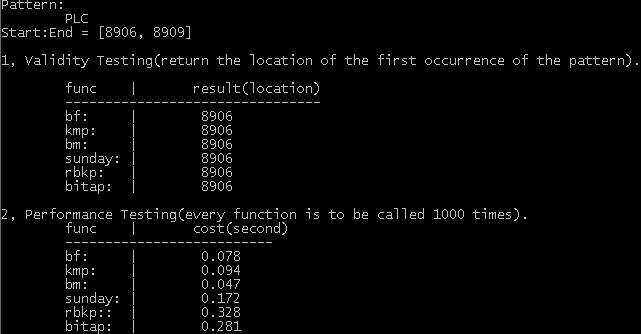
以上六种算法比较实现的代码如下所示(其中string长度10000)。















 2324
2324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









