引言
使用机器学习 (Machine Learning) 技术和方法来解决实际问题,已经被成功应用到多个领域,我们经常能够看到的实例有个性推荐系统,金融反欺诈,自然语言处理和机器翻译,模式识别,智能控制等。一个典型的机器学习过程通常会包含:源数据 ETL,数据预处理,指标提取,模型训练与交叉验证,新数据预测等。我们可以看到这是一个包含多个步骤的流水线式工作,也就是说数据从收集开始,要经历多个步骤,才能得到我们需要的输出。在本系列第 4 部分已经向大家介绍了 Spark MLlib 机器学习库, 虽然 MLlib 已经足够简单易用,但是如果目标数据集结构复杂需要多次处理,或者是对新数据进行预测的时候需要结合多个已经训练好的单个模型进行综合预测 (集成学习的思想),那么使用 MLlib 将会让程序结构复杂,难于理解和实现。值得庆幸的是,在 Spark 的生态系统里,一个可以用于构建复杂机器学习工作流应用的新库已经出现了,它就是 Spark 1.2 版本之后引入的 ML Pipeline,经过几个版本的发展,截止目前的 1.5.1 版本已经变得足够稳定易用了。本文将向读者详细地介绍 Spark ML Pipeline 的设计思想和基本概念,以及如何使用 ML Pipeline 提供的 API 库编写一个解决分类预测问题的 Pipeline 式应用程序。相信通过本文的学习,读者可以较为深入的理解 ML Pipeline,进而将它推广和应用到更多复杂问题的解决方案上去。
一、关于spark ml pipeline与机器学习
一个典型的机器学习构建包含若干个过程
1、源数据ETL
2、数据预处理
3、特征选取
4、模型训练与验证
以上四个步骤可以抽象为一个包括多个步骤的流水线式工作,从数据收集开始至输出我们需要的最终结果。因此,对以上多个步骤、进行抽象建模,简化为流水线式工作流程则存在着可行性,对利用spark进行机器学习的用户来说,流水线式机器学习比单个步骤独立建模更加高效、易用。
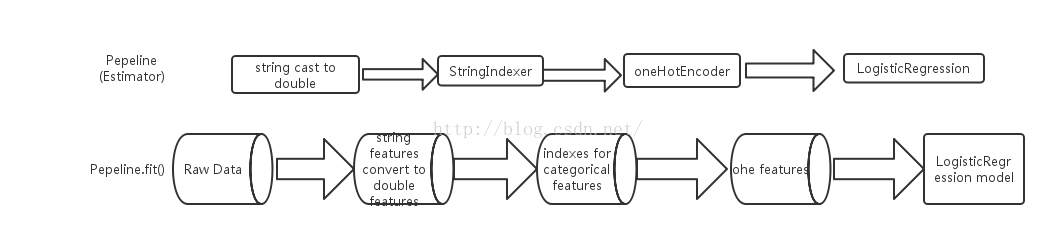
受 scikit-learn 项目的启发,并且总结了MLlib在处理复杂机器学习问题的弊端(主要为工作繁杂,流程不清晰),旨在向用户提供基于DataFrame 之上的更加高层次的 API 库,以更加方便的构建复杂的机器学习工作流式应用。一个pipeline 在结构上会包含一个或多个Stage,每一个 Stage 都会完成一个任务,如数据集处理转化,模型训练,参数设置或数据预测等,这样的Stage 在 ML 里按照处理问题类型的不同都有相应的定义和实现。两个主要的stage为Transformer和
Estimator。Transformer主要是用来操作一个DataFrame 数据并生成另外一个DataFrame 数据,比如svm模型、一个特征提取工具,都可以抽象为一个Transformer。Estimator 则主要是用来做模型拟合用的,用来生成一个Transformer。可能这样说比较难以理解,下面就以一个完整的机器学习案例来说明spark ml pipeline是怎么构建机器学习工作流的。
二、使用spark ml pipeline构建机器学习工作流
在此以Kaggle数据竞赛Display Advertising Challenge的数据集(该数据集为利用用户特征进行广告点击预测)开始,利用spark ml pipeline构建一个完整的机器学习工作流程。
首先,读入样本集,并将样本集划分为训练集与测试集:
-
- String fileReadPath = "file:\\D:\\dac_sample\\dac_sample.txt";
-
- SparkContext sc = Contexts.sparkContext;
- RDD<String> file = sc.textFile(fileReadPath,1);
- JavaRDD<String> sparkContent = file.toJavaRDD();
- JavaRDD<Row> sampleRow = sparkContent.map(new Function<String, Row>() {
- public Row call(String string) {
- String tempStr = string.replace("\t",",");
- String[] features = tempStr.split(",");
- int intLable= Integer.parseInt(features[0]);
- String intFeature1 = features[1];
- String intFeature2 = features[2]; String CatFeature1 = features[14];
- String CatFeature2 = features[15];
- return RowFactory.create(intLable, intFeature1, intFeature2, CatFeature1, CatFeature2);
- }
- });
-
-
- double[] weights = {0.8, 0.2};
- Long seed = 42L;
- JavaRDD<Row>[] sampleRows = sampleRow.randomSplit(weights,seed);
得到样本集后,构建出
DataFrame格式的数据供spark ml pipeline使用:
- List<StructField> fields = new ArrayList<StructField>();
- fields.add(DataTypes.createStructField("lable", DataTypes.IntegerType, false));
- fields.add(DataTypes.createStructField("intFeature1", DataTypes.StringType, true));
- fields.add(DataTypes.createStructField("intFeature2", DataTypes.StringType, true));
- fields.add(DataTypes.createStructField("CatFeature1", DataTypes.StringType, true));
- fields.add(DataTypes.createStructField("CatFeature2", DataTypes.StringType, true));
-
-
-
- StructType schema = DataTypes.createStructType(fields);
- DataFrame dfTrain = Contexts.hiveContext.createDataFrame(sampleRows[0], schema);
- dfTrain.registerTempTable("tmpTable1");
- DataFrame dfTest = Contexts.hiveContext.createDataFrame(sampleRows[1], schema);
- dfTest.registerTempTable("tmpTable2");
由于在dfTrain、dfTest中所有的特征目前都为string类型,而机器学习则要求其特征为numerical类型,在此需要对特征做转换,包括类型转换和缺失值的处理。
首先,将intFeature由string转为double,cast()方法将表中指定列string类型转换为double类型,并生成新列并命名为intFeature1Temp,
之后,需要
删除原来的数据列 并将新列重命名为
intFeature1
,这样,就将
string
类型的特征转换得到
double
类型的特征了。
-
- dfTest = dfTest.withColumn("intFeature1Temp",dfTest.col("intFeature1").cast("double"));
- dfTest = dfTest.drop("intFeature1").withColumnRenamed("intFeature1Temp","intFeature1");
如果intFeature特征是年龄或者特征等类型,则需要进行分箱操作,将一个特征按照指定范围进行划分:
-
- double[] splitV = {0.0,16.0,Double.MAX_VALUE};
- Bucketizer bucketizer = new Bucketizer().setInputCol("").setOutputCol("").setSplits(splitV);
再次,需要将categorical 类型的特征转换为numerical类型。主要包括两个步骤,缺失值处理和编码转换。
缺失值处理方面,可以使用全局的NA来统一标记缺失值:
-
- String[] strCols = {"CatFeature1","CatFeature2"};
- dfTrain = dfTrain.na().fill("NA",strCols);
- dfTest = dfTest.na().fill("NA",strCols);
缺失值处理完成之后,就可以正式的对categorical类型的特征进行numerical转换了。在spark ml中,可以借助StringIndexer和oneHotEncoder完成
这一任务:
-
-
- StringIndexer cat1Index = new StringIndexer().setInputCol("CatFeature1").setOutputCol("indexedCat1").setHandleInvalid("skip");
- OneHotEncoder cat1Encoder = new OneHotEncoder().setInputCol(cat1Index.getOutputCol()).setOutputCol("CatVector1");
- StringIndexer cat2Index = new StringIndexer().setInputCol("CatFeature2").setOutputCol("indexedCat2");
- OneHotEncoder cat2Encoder = new OneHotEncoder().setInputCol(cat2Index.getOutputCol()).setOutputCol("CatVector2");
至此,特征预处理步骤基本完成了。由于上述特征都是处于单独的列并且列名独立,为方便后续模型进行特征输入,需要将其转换为特征向量,并统一命名,
可以使用VectorAssembler类完成这一任务:
-
- String[] vectorAsCols = {"intFeature1","intFeature2","CatVector1","CatVector2"};
- VectorAssembler vectorAssembler = new VectorAssembler().setInputCols(vectorAsCols).setOutputCol("vectorFeature");
通常,预处理之后获得的特征有成千上万维,出于去除冗余特征、消除维数灾难、提高模型质量的考虑,需要进行选择。在此,使用卡方检验方法,
利用特征与类标签之间的相关性,进行特征选取:
-
- ChiSqSelector chiSqSelector = new ChiSqSelector().setFeaturesCol("vectorFeature").setLabelCol("label").setNumTopFeatures(10)
- .setOutputCol("selectedFeature");
在特征预处理和特征选取完成之后,就可以定义模型及其参数了。简单期间,在此使用LogisticRegression模型,并设定最大迭代次数、正则化项:
-
-
- LogisticRegression logModel = new LogisticRegression().setMaxIter(100).setRegParam(0.1).setElasticNetParam(0.0)
- .setFeaturesCol("selectedFeature").setLabelCol("lable");
在上述准备步骤完成之后,就可以开始定义pipeline并进行模型的学习了:
-
- PipelineStage[] pipelineStage = {cat1Index,cat2Index,cat1Encoder,cat2Encoder,vectorAssembler,logModel};
- Pipeline pipline = new Pipeline().setStages(pipelineStage);
- PipelineModel pModle = pipline.fit(dfTrain);
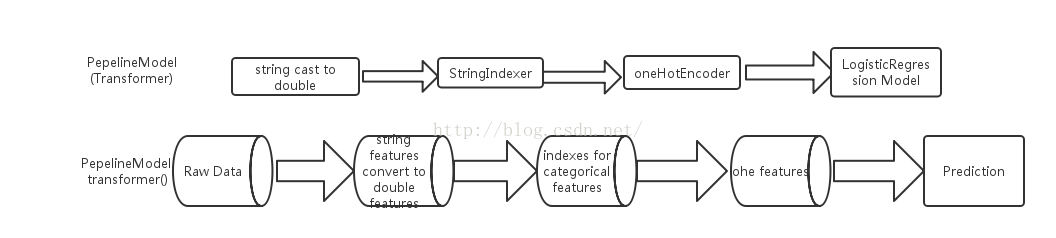
上面pipeline的fit方法得到的是一个Transformer,我们可以使它作用于训练集得到模型在训练集上的预测结果:
-
- DataFrame output = pModle.transform(dfTest).select("selectedFeature", "label", "prediction", "rawPrediction", "probability");
- DataFrame prediction = output.select("label", "prediction");
- prediction.show();
分析计算,得到模型在训练集上的准确率,看看模型的效果怎么样:
-
- long correct = prediction.filter(prediction.col("label").equalTo(prediction.col("'prediction"))).count();
- long total = prediction.count();
- double accuracy = correct / (double)total;
-
- System.out.println(accuracy);
最后,可以将模型保存下来,下次直接使用就可以了:
- String pModlePath = ""file:\\D:\\dac_sample\\";
- pModle.save(pModlePath);
三,梳理和总结:
上述,借助代码实现了基于spark ml pipeline的机器学习,包括数据转换、特征生成、特征选取、模型定义及模型学习等多个stage,得到的pipeline
模型后,就可以在新的数据集上进行预测,总结为两部分并用流程图表示如下:
训练阶段:
预测阶段:
借助于Pepeline,在spark上进行机器学习的数据流向更加清晰,同时每一stage的任务也更加明了,因此,无论是在模型的预测使用上、还是
模型后续的改进优化上,都变得更加容易。

























 2279
2279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









