







上篇介绍了TTS的一个简单例子http://blog.csdn.net/u010176014/article/details/47326413
本篇咱们进一步聊聊 语音如何读模板。比如
公交车上的模板:**到了,开门请当心,下车请走好。
新生入学系统的模板:丹桂飘香共祝美好明天,金秋送爽喜迎八方学子。**同学你好,欢迎来到**大学。
本文介绍的很适用于这种情况,模板比较固定,只有个别处不一样。而且还可根据需要更换配置,轻松换模板。
我做了一个天气预报的Demo。
第一步 添加一个resx文件
属于资源文件由 XML 组成,可以加入任何资源,包括二进制。像字典一样 有Key 和Value。
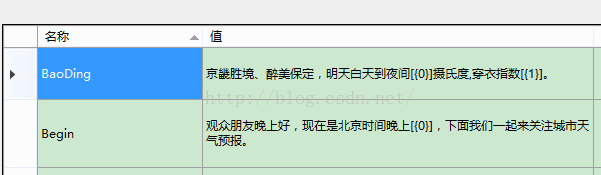
然后填充内容。名称就是Key值 ,值写的包含参数。例如“观众朋友晚上好,现在是北京时间晚上[{0}],下面我们一起来关注城市天气预报。” 这里面的时间可以根据具体情况赋值。把变的东西拿出来。
第二步 写一个类能够取出资源里的这些文字。
新建一个Resource类 。里面的代码如下。
using System.Text;
using System.Reflection;
using System.Resources;
namespace TTSSpeakDemo
{
public sealed class Resource
{
#region Static part
private const string ResourceFileName = ".SpeakTemplt";
static Resource InternalResource = new Resource();
/// <summary>
/// 获取文件资源管理
/// </summary>
public static Resource Manager
{
get { return InternalResource; }
}
#endregion
#region Instance part
ResourceManager rm = null;
/// <summary>
/// Constructor
/// 取得资源文件
/// </summary>
public Resource()
{
rm = new ResourceManager(this.GetType().Namespace + ResourceFileName, Assembly.GetExecutingAssembly());
}
/// <summary>
/// 从程序集资源文件中获取指定键的消息
/// </summary>
public string this[string key]
{
get
{
return rm.GetString(key, System.Globalization.CultureInfo.CurrentUICulture);
}
}
#endregion
}
}
第三步 画个界面
我做的比较简单。欢饮大家继续丰富。。
第四步 添加事件
<span style="font-family:KaiTi_GB2312;font-size:18px;">using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Media;
using SpeechLib;
namespace TTSSpeakDemo
{
#region 语音读文本Demo-2015-8-9-MDM
/// <summary>
/// 语音读文本Demo-2015-8-7-MDM
/// </summary>
public partial class SpeakDemo : Form
{
public SpeakDemo()
{
InitializeComponent();//自动生成,不动
}
/// <summary>
/// 发音对象
/// </summary>
public SpVoice voice = new SpVoice();//该类是支持语音合成(TTS)的核心类。通过SpVoice对象调用TTS引擎,从而实现朗读功能。
public SpeechVoiceSpeakFlags spFlags = SpeechVoiceSpeakFlags.SVSFDefault;//
/// <summary>
/// 通过关键字获取语音文字资源内容
/// </summary>
/// <param name="key"></param>
/// <returns></returns>
private static string GetTextResourceByKey(string key)
{
return Resource.Manager[key].ToString().Trim();
}
private void btnSpeak_Click(object sender, EventArgs e)
{
string beginWord = GetTextResourceByKey("Begin");//根据key值获取到相应的文本
string baoDing=GetTextResourceByKey("BaoDing");//同上
string nowTime = DateTime.Now.ToString("r");//获取时间
string speakWord = string.Format(beginWord, nowTime); //问候语和时间
string weather=txtWeather.Text;
string air=txtAir.Text;
string speakWeather = string.Format(baoDing,weather, air);//将参数放入模板中
voice.Speak(speakWord, spFlags);
voice.Speak(speakWeather, spFlags);
}
}
#endregion
}
</span>这样我们就能听到啦~虽然简单 但是很实用哦~
将Demo传至网盘,供大家直接看看效果。http://yunpan.cn/cdBHfJzuqZHaC 访问密码 96c9














 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









