








iouring 思路补充 由于是飞机上写的,可能有一些错误和拼写问题,手头也没有参考资料了,凭空想象的回忆了属于是。(已订正了一部分)
专栏内的所有笔记本身是和他们自洽的(也许漏了一篇讲如何理解协程和函数式编程中的 call/cc 的笔记,博客中也上传了,当然实际这系列笔记不是一个能够快速上手的,而是一个系列的学习,主要目的是供我自己复习或者有对 C++ 协程与 Proactor 网络框架编写感兴趣的读者。
 https://blog.csdn.net/u010180372/article/details/123267951
https://blog.csdn.net/u010180372/article/details/123267951主要讨论一下一些异步的投递的实现,第二部分是 CPU bound 的 task 的线程池,因为 proactor 对线程池的要求和 reactor 的不一样。
首先从缓冲区的支持,缓冲区本身不需要支持async,但是他有一个 readfd 的支持。根据muduo的tcpconnection写法,感觉不需要这个也可以,这个函数应该是利用on stack buffer 和iovec来进行 socket 的读入,一次系统调用就可以把 bytes 读进来(大概率,不然就需要反复调用 read,重新扩容 buffer 等),之后再把 temp buf append 到本身的buffer里进行扩容。由于只是考虑了给 socket 提供了支持,所以实际 64kb 的栈上空间大概率是支持的了。(不考虑长肥)。
我现在来讲解一下这个是怎么改写成async的。首先我们需要对他进行一个iouring fd 的绑定。这个就要求他必须在uiocontext(指有iouring fd 管理的一个类下而不能是独立的了,所以实际将它实现为 buffer 的 member function/coroutine 没有意义。我们应该把他写到 iocontexy里面。这样主要就是说内部的readv不直接调用readv了,而是需要传一个buffer进来,我们调用iouring的readv函数,iovec这个操作还是同样可用的。
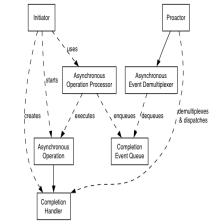
iocontext(service)的编写。首先是一个iocontext实际等于一个reactor的poller,poller即绑定了一个epollfd。在reactor的模型里面我们还有eventloop来继续封装poller,当然我们也可以直接把eventloop给写完poller的那一部分。
在多线程模型中,say有多个eventloop实际是线程池的话,请问epoll也是要create多个吗?实际我们可以发现,worker的eventloop实现线程池使用的方案其实是通过一个eventfd然后平时睡觉,醒来了就执行callback(实际有一个queue,然后发送任务给他的时候无非就是通过enqueue之后wakeup他来运行的),那么,是否还需要poller呢?是的,需要的。现在的问题是,由于 short read (short count)的存在,实际线程池的 eventloop 必须转而给 poller 注册要监控这个 fd(which 是 accept/accept4 返回来的,并不在你的主线程的 poller 监控的 channels 里面)。所以这个类似 spawn 的过程,就要注册好到 subreactor 的 poller 里面去。
那么这样现在对我们async可以想到一个方案就是说协程handle的resume就通过发给线程池去运行,但是其实这个并不需要吧,因为对于reactor来说他说ready之后callback的,read和write都要花时间所以才要用到这种模型的线程池吗?
这个问题很奇怪,考虑如果有compute bound 的任务的话,实际你在main thread(或者说master thread)上进行的话,会不会影响到我们的async accept呢?我讨厌考虑这种公平性问题,因为你必须要量化才知道是不是符合先入为主的看法。
首先是投递一个accept的sqe,然后coawait从而睡觉了(通过iocontext的循环里面在waitcqe函数上睡觉)。如果一个request进来,此时唤醒我们的线程,于是就恢复了acceptor协程的运行,然后acceptor直接在同一个线程上cospawn一个connectionhandler的协程,实际发生的事情是cospawn会做什么呢?
有两种方案,直接coawait这个task然后进入task中的第一个coawait其他awaitable 然后一路到第一个真异步然后返回再投递我们的accept请求(当然inbound req是不会丢失的因为已经listen了);
第二种方案是让cospawn把这个task存在某一个地方(say a queue)然后再被本线程或者其他线程调度运行。如果现在有一个compute bound 的业务,比如要进行一个场景的战斗计算或者一个ai寻路的查找并且say场景很复杂可能要1s的时间,那故事就到此终结了,对于高并发服务来说,这种情况应该要上线程的公平的有timer interrupt (preemption) 的调度,但是对于游戏服务器来说这现实吗?考虑我们有一个24核的机器,那只能开线程模型了,这个时候我好像明白了,一个process大概只能开几百个线程(指 linux 32bit),这就不能走nginx那种多进程模型(fork)了。怪不得百人同屏已经很极限了?游戏服务器的确实是单机上运行的,考虑一台服务器能同时进行多少盘游戏的模拟呢?我们怎么实现这种?无非是线程池里面没有公平调度所有长时间的运行的时候我们可能需要扩容一下线程数了。当然实际情况是不可能一盘游戏同时100个线程都在寻路吧。你看守望先锋也就6v6,这么说我们最多一盘模拟也就最多需要6个线程。我决定不要再讲这个公平问题了,因为我确实还没研究明白,实际我的实践就是通过这个线程池定时检测一下long running 的线程这样就扩容一下。
其实上面这个讨论主要就是针对通过线程池来运行一些task从而达到假async的效果,现在就来讲一下这个东西怎么实现。
首先线程池都很容易实现的了,暂时不考虑long running 的问题,首先是我们需要支持队列的功能,当然这些在美团那篇讲线程池的技术文章基本都讲了。muduo里面有个写法是run in loop 函数。
这种要计算很久的task的内部他可能会没有coawait,即充当一个真的cppcoro的task原本意义的延迟运行。因为我们要真的运行他,所以主线程不能直接coawait了,我们还可以提供一个好看的语法去让他运行到其他线程上(实际对于有executor 的抽象的时候,可以用executor的接口)比如coawait as long running task 之类的语法包装。对于这种没有注册io来做completion callback 的东西的话,我们的线程池就要支持(或者说不是线程池,是支持这种task 的executor)投递信息给我们的 wait cqe,that is to say 利用 iouring 上面的 eventfd 来实现的。
一种实现思路是直接在运行task 的地方做一个针对task 的 decorator,至少添加一个运行结束后写eventfd从而唤醒callback分发线程的操作,这就是另一个问题了,因为这里又要做mux和demux了!之前说过普通的io我们token直接存了handle,你resume就行了,现在你不能这样做了,因为eventfd醒来的时候,completion token 里面不能是单单一个 handle 然后就 co_await 就行的了,这种应该想办法标记为是 eventfd,然后我们采取别的逻辑。仿照 muduo 的思路就是实现一个大家(eventloop,线程池也都在运行 poller ?看你考虑了,如果我们是纯真的异步模型,根本不需要那种 subreactor 的模型,这样线程就是纯纯用来运行 compute bound /CPU bound 的,可以直接用信号机制、或者 blocking read on eventfd,毕竟 poller 本身就是个 MUX,现在直接专线了)都有的 queue,然后类似 doPendingFunctors 的逻辑,我们写一个 doPendingTasks 的函数。然后又有一个问题了,用户不一定就会按逻辑跟你提交一个纯真的 CPU bound 的 task,what if task 里面也有 co_await 一个应该绑定到 io_context(即 wait_cqes 上睡觉) 的 awaitable (前面说了,这种也可能以 task 的形式,因为 task 本身就是中介)怎么办呢?
线程池本身还可以利用 eventfd 的功能(注意是 io_uring complete 了之后写入 eventfd,而不是io_uring 异步 read or write eventfd),这个可以参考这里的指示:
Register an eventfd — Lord of the io_uring documentation (unixism.net)
尾声:
至此,整个系列已经开始走向灭亡了。因为我已经把整个项目的所有思路回忆了一遍,实际有用的没用的占大部分,系列的第二阶段会是针对完整项目代码的分析。但是我感觉已经没有意义了,因为写的方法都讲明白了,已经足够复习了。同时没有辜负我的期待,整个笔记的组织条理已经完全崩溃了。完全是野蛮的写法。

















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









