






信息论
在本章中,我们讨论概率论和决策论的许多概念,他们是本书随后讨论的基础。我们通过引入一些信息论领域额外的概念来结束本章,这些概念也在模式识别和机器学习技术的发展中也是很有用的。再次,我们只关注关键的概念,并建议读者参考其他地方更详细的讨论(Viterbi和Omura,1979;Couver和Thomas,1991;MacKay,2003年)。
我们首先考虑一个离散型随机变量x并问当我们观察到此变量的特定值时接收到多少信息。信息量可以看作是学习x值的“惊喜度”(degree of surprise)。如果我们被告知非常不可能事件刚刚发生了,相对被告知一些非常有可能的事件刚刚发生会提供更多的信息量,如果我们知道该事件是一定会发生,我们将没有收到任何信息。因此,信息内容的量度将取决于p(x)上的概率分布,因此我们寻找h(x),它是概率p(x)的单调函数和表达信息内容。注意如果我们有两个事件x和y是不相关的,那么观察两者得到的信息应该是分别从两者获得信息的和,从而h(x,y)= h(x)+ h(y)。两个不相关的事件在统计上是独立,所以p(x,y)= p(x)p(y)。根据两者的关系,很容易表明h(x)必须用p(x)的对数形式给出,因此我们有

其中负号确保信息是正数或零。注意,小概率事件x对应于高信息内容。对数基准的选择是任意的,但我们采取信息论中比较流行的以对数2作为基底的公约,这种情况下,h(x)的单位是比特(“二进制数字”)。
现在,假设发送者希望发送一个随机变量的值给接收者。他们在这个过程中传输的平均信息量通过取(1.92)相对于p(x)的期望获得,由下式给出
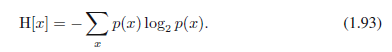
这个重要的量被称为随机变量x的熵。注意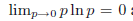
到目前为止,我们给出了信息定义(1.92)和相应熵(1.93)的启发式动机。现在我我们表明,这些定义的确具有有用性。考虑有8个可能状态的随机变量x,其中每一个是等可能的。为了将x的值通信到一个接收器,我们需要发送长度为3比特的信息。注意,这个变量的熵由下式给出:
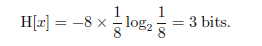
现在考虑有8个可能状态值{a,b,c,d,e,f,g,h}的例子(Cover和Thomas,1991年)其各自的概率为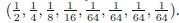
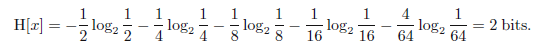
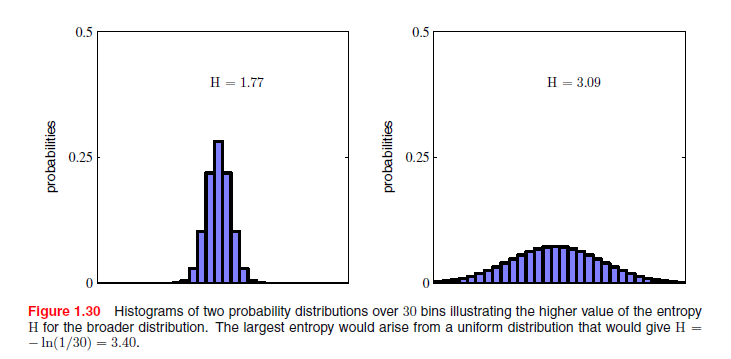
我们看到,不均匀分布比均匀分布有较少的熵,当我们讨论混乱形式的熵时会对它有更深入的理解。就目前而言,我们考虑如何传递变量的状态到接收器。我们可以用一个3位数来做到这一点。但是,我们可以利用不均匀分布这个性质,对大概率事件使用长编码,对小概率事件使用短的编码从而使平均代码长度更短。通过表示状态{a,b,c,d,e,f,g,h}来完成,例如,下面的一组代码串:0,10,110,1110,111100,111101,111110,111111。要发送编码的平均长度则是
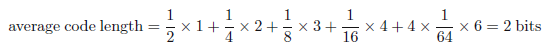
熵和最短编码长度之间的关系通常是唯一的。无噪声编码论(Shannon,1948)表明熵是一个传输随机变量状态所需位数的较小下界。
从现在开始,我们在定义熵时使用自然对数。在这种情况下,计算熵的单元就不是位,不同的这是一个因子ln2。
我们用指定随意变量状态的平均信息量这种形式介绍了熵的概念。实际上,熵的概念更早的起源是物理中的平衡热力学,后来通过统计学的发展,给出的进一步解释是混乱的一种度量。为了更好的理解,考虑一组N个相同的对象被分进一组箱子,这样的话在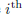


这叫做多重性,然后熵被定义为多重性的对数(并用一个合适的常数进进行缩放)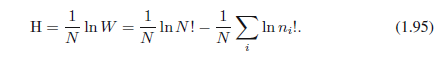
我们考虑N →∞,分数ni/N趋向一个定值,应用斯特灵近似:

得到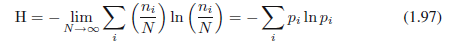
其中,我们使用了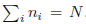
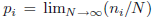
我们可以解释箱子为一个离散型随机变量X的状态xi,其中p(X = xi)=pi。随机变量X的熵
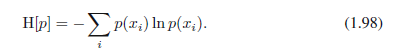
分布p(xi)是被几个值包围的峰值,那么它有一个相对低的熵,而那些分布更均匀地具有较高的熵,如图1.30。因为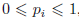

从中我们发现所有的p(xi)都是相等的,由p(xi)=1/ M给出其中M是状态xi的总数。熵的值随后是H = lnM。这个结果也可以根据詹森不等式(稍后讨论)得到。为了验证驻点的确是最大的,我们可以评价熵的二阶导数
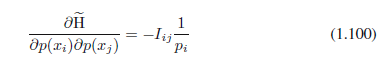
其中Iij是单位矩阵的元素。
我们可以扩展熵的定义来包括连续变量x上的分布p(x)。首先将x分成宽为Δ的箱子。然后,假设p(x)是连续的,中值定理(Weisstein,1999)告诉我们每个这样的箱子,一定存在一个值xi使得:
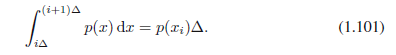
现在,我们通过指派任何值x到xi来量化连续变量x。观察值xi的概率则是p(xi)Δ。这给出了一个离散分布,熵的形式为:
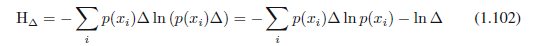
其中我们有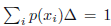
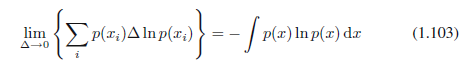
其中,右手侧的量称为微分熵。我们看到熵的离散和连续形式相差一个lnΔ,在极限Δ→0时发散。这反映了为了非常精确地指定连续变量,需要大量的比特。对定义在多个连续变量上的密度(矢量x表示),微分熵由下式给出:
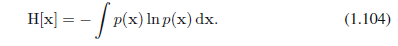
在离散分布的情况下,我们看到最大熵配置对应于一个相等的穿过变量可能状态的概率分布。现在让我们考虑连续变量的最大熵配置。为了最大限度地得到好的定义,约束ρ(x)的第一和第二项而且保留规范化约束是很有必要的。因此,我们最大化带有三个约束的微分熵:
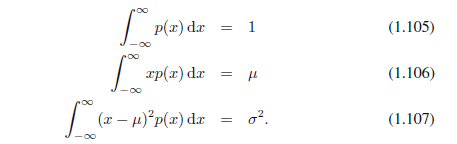
受约束的最大化可以用拉格朗日乘子来执行,这样我们、最大化相对于p(x)的函数:
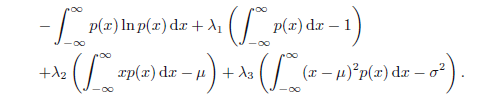
采用变分法,我们设置这个函数的导数为零:
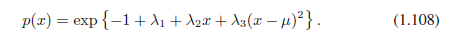
通过代回这个结果到三个约束方程可以找到拉格朗日乘子,最终产生结果:
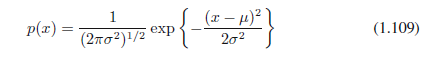
因此,最大化微分熵的分布是高斯分布。注意,当在最大化熵时我们没有约束分布为非负的。然而,因为所得分布确实是非负的,我们事后看到,这种约束是没有必要的。
如果我们评估的高斯的微分熵,我们得到:
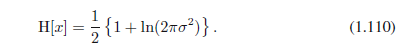
因此,我们再次看到随着分布变得更为平坦(即σ2增加)熵函数也随之增加。此结果也表明,微分熵跟离散熵不一样,它可以是负的,因为(1.110)中σ2<1 /(2πe)时H(x)<0。
假设我们有一个联合分布p(x,y),从中我们得出x和y的一对值。如果x值是已知的,则需要指定y对应值的附加信息由-ln p(y |x)给出。因此,需要指定y的平均附加信息可以写成
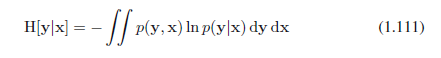
这被称为给定x后y的条件熵。很容易看到,使用乘积规则条件熵满足关系
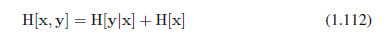
其中H[x,y]为p(x,y)的微分熵,H[x]是边缘分布p(x)的微分熵。从而描述x和y的信息由单独描述x的信息加上给定x指定y的条件信息给出。















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









