







参考资料:
http://www.cnblogs.com/mengdd/archive/2012/11/30/2796845.html
http://blog.csdn.net/morewindows/article/details/6709644
1、堆的定义
常常将“二叉堆”简称作“堆”,它是完全二叉树。满足以下特性的叫做堆:
(1) 完全二叉树中所有非终端(叶子)结点的值均不大于(或不小于)其左、右孩子(child)结点的值(对于每个二叉树单元而言,孩子之间大小关系无要求);
(2) 最后一层所有的结点都连续集中在最左边(这就是完全二叉树的特性之一)
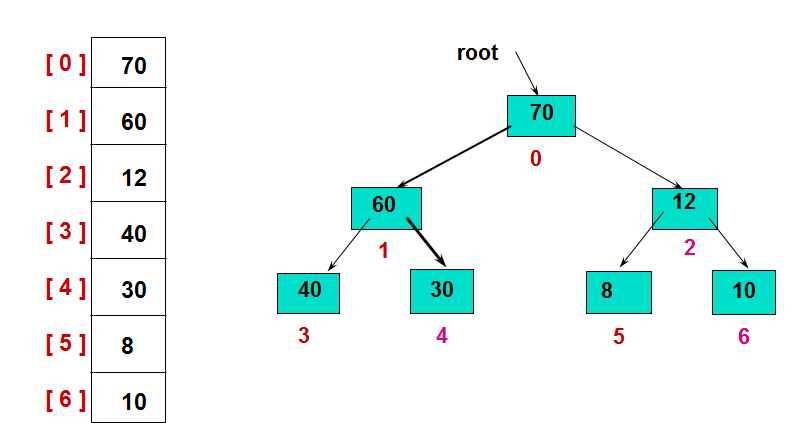
其中父节点均大于等于子节点的叫作大顶堆,反之称为小顶堆。比如下面这个大顶堆示意图,左边为对应的原始数组。
(图片摘自:堆排序 Heap Sort)
2、堆排序
由堆的定义可见,堆顶元素(即完全二叉树的根)必为序列中n个元素的最大值(或最小值)。
则可用这一特性进行堆排序了,堆排序的思想(大顶堆为例):
(1)将一个长度为n的数组,按堆的数据结构进行调整,则会在堆根部得到最大值;
(2)将最大值与第n个数交换;
(3)再将剩余的n-1个数组中的数,继续按堆的数据结构进行调整,得到次最大值,再与第n-1个数交换;
(4)以此类推,最后将次次大值,次次次大值…按顺序依次放到数组尾部,最终获得了升序排列的数组;(人类真聪明)
很像选择排序有没有?区别就在于选择排序找出最大值是线性的比,即一个一个的比,而堆排序找出最大值是按堆的结构调整着比,“跳着比”,速度那可是快多啦,选择排序的时间复杂度为O(n^2)。
而堆排序在最坏的情况下,其时间复杂度也为O(nlogn),相对于快速排序来说,这是堆排序的最大优点。(圣骑士Wind说的,嘿嘿~)
3、核心代码
核心代码中,主要是将数组顺序调整成堆的数据结构那个函数(heapAdjust)比较绕,大神博客中都有这些代码,不过或多或少都有些错误,或者不能完全运行,我好事做到底,将变量改成了易读的形式,并做上了相关注释。最后写了个测试程序放在了第4部分,最后运行成功。
int heapSort(int *data, unsigned int length)
{
if (data == NULL)
{
return -1;
}
//建立一个大顶堆
for (int start = (length-1-1) / 2; start >= 0; start--)
{
heapAdjust(data, start, length - 1);
}
//堆排序
for (int i = length - 1; i >= 1; i--)
{
swap(data[i], data[0]);
heapAdjust(data, 0, i-1);
}
return 0;
}
//将数组的start到end部分,调节成一个大顶堆
void heapAdjust(int *data, int start, int end)
{
int temp = data[start];
//pNode表示一个二叉树单元中,lchild所对应的下标
int pNode = 2 * start + 1;
while (pNode<=end)
{
//如果rchild比lchild还大,pNode则指向rchild
if (pNode+1<=end&&data[pNode + 1] > data[pNode])
pNode++;
//如果temp比“pNode指向的地方”(lchild和rchild中的最大值)还大,
//那就不用再调整了,已经符合了堆的条件
if (temp>=data[pNode])
break;
//下面这两句非常精妙,也是为什么堆排序时间复杂度低的精髓所在
//通俗讲,就是旨在只去调整移动过的节点及其子节点,其余的就“跳过了”
data[start] = data[pNode];
start = pNode;
pNode = start * 2 + 1;
}
//到这一步说明后面要么没有子节点了,要么后面的顺序满足条件了
//所以最后算总账,把temp放回来
data[start] = temp;
/*NOTICE:自己在纸上画个堆,按照代码跑<=三遍即可意会*/
}4、Test程序
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
int heapSort(int *data, unsigned int length);
void heapAdjust(int *data, int start, int end);
void main(void)
{
int array[20] = {6,1,2,8,10,4,3,9,5,7,15,12,13,16,14,17,19,11,20,18};
int num = 20;
//step1: 遍历数组,输出初始排列
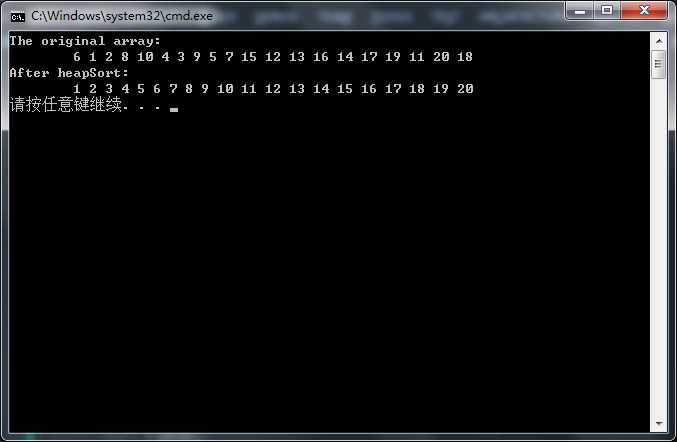
cout << "The original array: \n\t";
for (int arN = 0; arN < num; arN++)
{
cout << array[arN]<<' ';
}
cout << endl;
//step2: 堆排序
heapSort(array, num);
//step3: 遍历数组,输出排序后结果
cout << "After heapSort: \n\t";
for (int arN = 0; arN < num; arN++)
{
cout << array[arN]<<' ';
}
cout << endl;
}
int heapSort(int *data, unsigned int length)
{
if (data == NULL)
{
return -1;
}
//建立一个大顶堆
for (int start = (length-1-1) / 2; start >= 0; start--)
{
heapAdjust(data, start, length - 1);
}
//堆排序
for (int i = length - 1; i >= 1; i--)
{
swap(data[i], data[0]);
heapAdjust(data, 0, i-1);
}
return 0;
}
//将数组的start到end部分,调节成一个大顶堆
void heapAdjust(int *data, int start, int end)
{
int temp = data[start];
//pNode表示一个二叉树单元中,lchild所对应的下标
int pNode = 2 * start + 1;
while (pNode<=end)
{
//如果rchild比lchild还大,pNode则指向rchild
if (pNode+1<=end&&data[pNode + 1] > data[pNode])
pNode++;
//如果temp比“pNode指向的地方”(lchild和rchild中的最大值)还大,
//那就不用再调整了,已经符合了堆的条件
if (temp>=data[pNode])
break;
//下面这两句非常精妙,也是为什么堆排序时间复杂度低的精髓所在
//通俗讲,就是旨在只去调整移动过的节点及其子节点,其余的就“跳过了”
data[start] = data[pNode];
start = pNode;
pNode = start * 2 + 1;
}
//到这一步说明后面要么没有子节点了,要么后面的顺序满足条件了
//所以最后算总账,把temp放回来
data[start] = temp;
/*NOTICE:自己在纸上画个堆,按照代码跑<=三遍即可意会*/
}运行结果















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









