








sample=cutstring(u"据悉,这辆汽车绰号野兽,野兽很可能于2017年1月份美国第45任总统就职时使用。目前,野兽的详细规格都属于绝密信息,但谍照显示野兽采用了凯迪拉克的最新护栅和前灯设计。")
tokenstr=nltk.word_tokenize(sample)
fdist3=nltk.FreqDist(tokenstr)
print "---美国出现的次数---"
print fdist3[u"美国"]
print "---样本总数---"
print fdist3.N()
print "---数值最大的样本---"
print fdist3.max()
#频率分布表
fdist3.tabulate()
#频率分布图
fdist3.plot()
#累积频率分布图
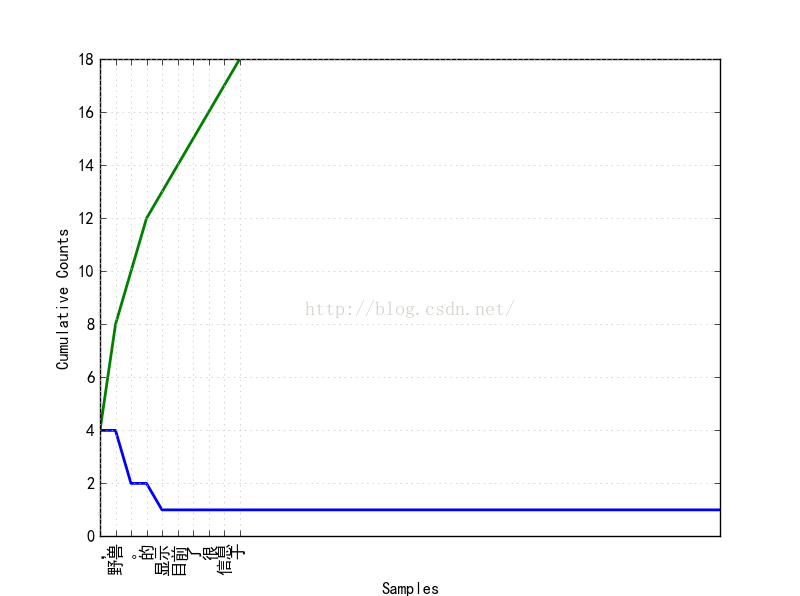
fdist3.plot(10,cumulative=True)
本博客所有内容是原创,如果转载请注明来源
http://blog.csdn.net/myhaspl/















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









