










摘要:本文主要讲述Linux环境下搭建hadoop平台过程中hadoop软件包安装配置环节,并在配置完毕的基础上运行hadoop的单机模式。
环境说明:文章延续hadoop平台搭建(2)中的步骤,搭建Apache原生态hadoop2.6.0,采用Ubuntu15.10操作系统,Ubuntu其他版本操作系统的操作类似。Linux其他系列操作系统适当做相应调整。
1安装hadoop
下载hadoop安装包hadoop-2.6.0.tar.gz以及校验文件hadoop-2.6.0.tar.gz.mds。
安装之前先检查hadoop安装包的完整性,及早发现下载或传输过程中安装包是否发生损坏。
命令:
md5sum hadoop-2.6.0.tar.gz | tr "a-z" "A-Z"
解读:计算hadoop安装文件的MD5值,其中tr “a-z” “A-Z”指将MD5值中字母小写统一转大写。命令:
cat hadoop-2.6.0.tar.gz.mds | grep 'MD5'
解读:查看hadoop校验文件里的MD5值,其中grep ‘MD5’表示对文件内容进行过滤。

如果没有错误,则两个MD5的值将一致。
将hadoop的安装包解压到安装路径下,并修改路径名,方便管理

为了在hadoop目录下执行文件更改、工程创建等操作,需要修改hadoop根目录权限
命令:
sudo chown -R hadoop ./hadoop
解读:更改hadoop目录的所有者为hadoop用户,其中-R表示对根目录下的子目录递归地执行相同的操作。

此时,可以调用hadoop跟目录下bin目录里的hadoop工具,查看hadoop版本
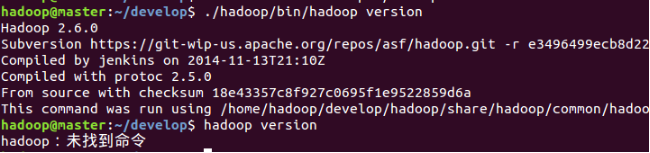
2配置环境变量
通过vi命令或gedit工具打开/home/hadoop/.bashrc文件
命令:
sudo gedit /home/hadoop/.bashrc
将hadoop的bin目录和sbin目录添加到path环境变量;”hadoop classpath”包含了运行hadoop程序所需要的全部classpath信息,为方便以后用hadoop编译java文件,在此也将“hadoop classpath”添加到CLASSPATH环境变量。
# the path and clsspath of the hadoop
export HADOOP_HOME=/home/hadoop/develop/hadoop
export PATH=$PATH:${HADOOP_HOME}/bin
#export PATH=$PATH:${HADOOP_HOME}/sbin
export CLASSPATH=$CLASSPATH:$($HADOOP_HOME/bin/hadoop classpath)注意:由于hadoop的sbin下有和spark的sbin下重名的工具(比如start-all.sh/stop-all.sh),所以当同时安装有hadoop和spark时,不要将sbin目录加入环境变量,避免出错。
保存后,执行source /home/hadoop/.bashrc命令,使设置立即生效。在bin目录以外,调用hadoop工具,查看是否配置正确。
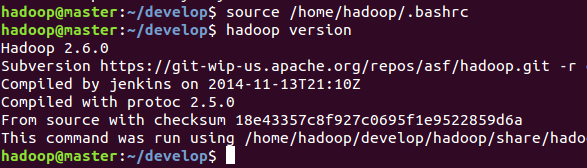
3运行单机模式
Hadoop安装、环境变量配置完毕后默认为单机模式,不需要额外配置即可运行。
(1)首先创建单机模式下的输入目录input,并将配置文件复制到输入目录下,作为输入文件。
命令:
mkdir input
解读:创建输入目录命令:
cp ./etc/hadoop/*.xml input
解读:将hadoop的部分配置文件复制到输入目录里,作为输入文件

(2)运行hadoop自带的单词统计例子(注意,如果hadoop路径配置正确,此时不必在bin目录下调用hadoop工具)
命令:
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-example-2.6.0.jar grep input output 'dfs[a-z.]+'
解读:用hadoop工具的jar命令,运行自带的单词统计例子。其中,grep后依次为输入目录、输出目录、过滤单词的正则表达式。
运行无误后会有如下输出提示

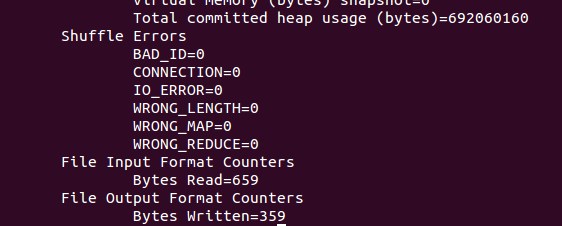
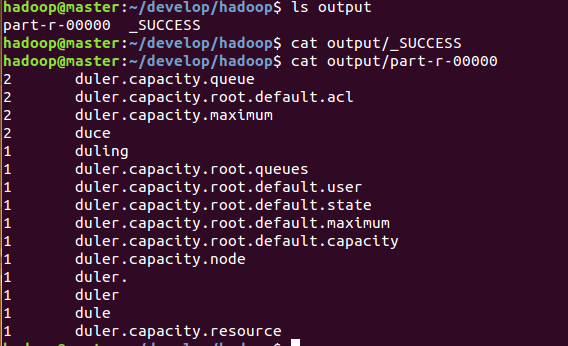
(3)查看输出结果。输出目录output里包含两个可见文件:一个是_SUCCESS,内容为空,表示执行成功;另一个是part-r-00000,记录了输出结果。
命令:
cat output/part-r-00000
解读:查看输出目录里的输出结果文件
注意:hadoop为了避免运行结果覆盖,运行之前输出目录不能存在。所以运行之前需要删除输出路径output才能再次执行
命令:mv -R output
解读:删除目录。其中,-R表示递归删除目录里面的子目录
至此,hadoop的单机配置完毕,单击运行操作结束。















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









