







领导安排了一个任务,下载竞争对手公司申请的专利信息,主要对手包括以下几个:Vestas Wind System A/S 集团,歌美飒技术集团股份有限公司,GE,西门子。
google专利被墙了,不好弄,发现美国专利及商标局这个网站还健在,打开https://www.uspto.gov/,发现美帝还是比较良心的,网站简约,搜索人性,检索迅速,比较一下国内的这个网站http://cpquery.sipo.gov.cn/真是高下立判。
检索界面如下:
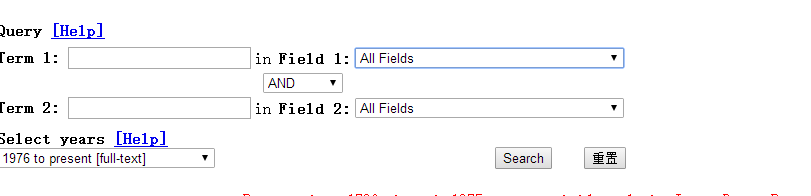
检索结果如下:
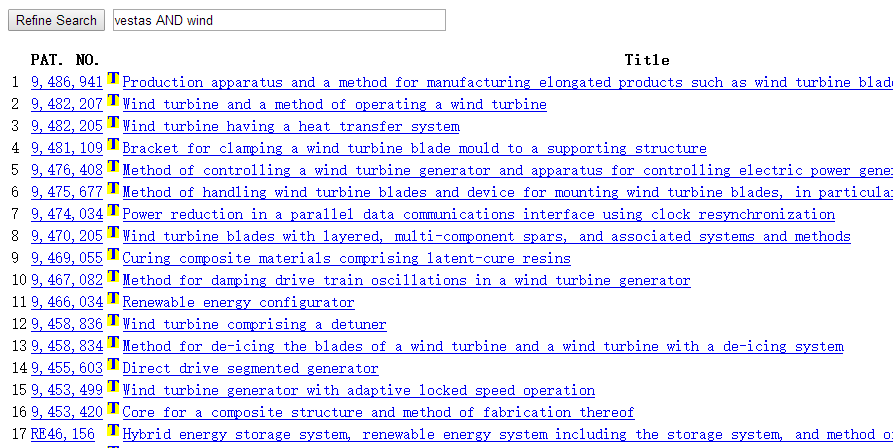
任务就是把这些都批量下载下来,形成一个记录信息的txt文档,同时下载全文pdf,两个文件放进一个文件夹。
talk is cheap,show the code
#爬取美国专利网指定公司的专利
#by---jzx
#2016-11-8
import re
from bs4 import BeautifulSoup
import requests
import os
#存储数据
def store_data(dictionary, search_string):
dictionary['patent_name'] = dictionary['patent_name'].replace('\n', ' ').replace('"', ' ')[:100]
folder_name = './' + search_string + '/' + dictionary['patent_name'] + '(' + dictionary['patent_code'] + ')'
if not os.path.exists(folder_name):
os.makedirs(folder_name)
filename = folder_name + '/data.txt'
pdfname = folder_name + '/full_pdf.pdf'
data_list = ['patent_code', 'patent_name', 'year', 'inventor_and_country_data', 'description', 'full_pdf_file_link']
with open(filename, 'w') as f:
for data in data_list:
f.write(data + ': \n' + dictionary[data] + '\n')
f.close()
try:
r = requests.get(dictionary['full_pdf_file_link'], stream=True)
with open(pdfname, 'wb') as fd:
for chunk in r.iter_content(chunk_size=1024):
fd.write(chunk)
fd.close()
except:
print('there is something wrong with this patent')
#获取数据
def get_patent_data(url, search_string):
tmp_s = requests.session()
try:
r2 = tmp_s.get(url)
except:
print('There is something wrong with this patent')
return
text2 = r2.text
tmp_soup = BeautifulSoup(text2, "html.parser")
patent_data = dict()
# print(text2)
patent_data['patent_code'] = tmp_soup.find('title').next[22:]
patent_data['patent_name'] = tmp_soup.find('font', size="+1").text[:-1]
tmp1 = text2[re.search('BUF7=', text2).span()[1]:]
patent_data['year'] = tmp1[:re.search('\n', tmp1).span()[0]]
patent_data['inventor_and_country_data'] = tmp_soup.find_all('table', width="100%")[2].contents[1].text
tmp1 = text2[re.search('Description', text2).span()[1]:]
tmp2 = tmp1[re.search('<HR>', tmp1).span()[1]:]
patent_data['description'] = tmp2[re.search('<BR>', tmp2).span()[0]:(re.search('<CENTER>', tmp2).span()[0] - 9)]. \
replace('<BR><BR> ', '')
tmp3 = tmp2[:re.search('<TABLE>', tmp2).span()[0]]
tmp_soup = BeautifulSoup(tmp3, "html.parser")
pdf_link = tmp_soup.find('a').get('href')
r3 = tmp_s.get(pdf_link)
text3 = r3.text
tmp_soup = BeautifulSoup(text3, "html.parser")
pdf_file_link = tmp_soup.find('embed').get('src')
patent_data['pdf_file_link'] = pdf_file_link
patent_data['full_pdf_file_link'] = pdf_file_link.replace('pdfpiw.uspto.gov/', 'pimg-fpiw.uspto.gov/fdd/'). \
replace('1.pdf', '0.pdf')
store_data(patent_data, search_string)
#主函数
def main():
s = requests.session()
keywords = list()
while True:
print('what do you want to do?(a: add a key word for searching, q:quit adding words and start)')
command = input('command:')
if command == 'a':
word = input('keyword: ')
if word not in keywords:
keywords.append(word)
elif command == 'q':
break
else:
print('please input a valid command')
if len(keywords) == 0:
return
search_string = ''
for keyword in keywords:
search_string += keyword
search_string += '+'
search_string = search_string[:-1]
main_folder_name = './' + search_string
if not os.path.exists(main_folder_name):
os.makedirs(main_folder_name)
# search_url = 'http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&p=1&u=%2Fnetahtml%2FPTO%2Fsearch-' \
# 'bool.html&r=0&f=S&l=50&TERM1=' + search_string + '&FIELD1=&co1=AND&TERM2=&FIELD2=&d=PTXT'
search_url ='http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&p=1&u=%2Fnetahtml%2FPTO%2Fsearch-bool.html&r=0&f=S&l=50&TERM1=vestas&FIELD1=&co1=AND&TERM2=wind&FIELD2=&d=PTXT'
r = s.get(search_url)
text = r.text
print('finish collecting html...')
soup = BeautifulSoup(text, "html.parser")
number_of_patents = int(soup.find('b').nextSibling[2:-10])
print('The total of patents under your key words is: ' + str(number_of_patents))
for number in range(156, number_of_patents + 1):
print('collecting patent data' + '(' + str(number) + '/' + str(number_of_patents) + ')')
# patent_url = 'http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&p=1&u=%2Fnetahtml%2FPTO%2F' \
# 'search-bool.html&r=' + str(number) + '&f=G&l=50&co1=AND&d=PTXT&s1=%22led+lamp%22&OS=%22led+' \
# 'lamp%22&RS=%22led+lamp%22'
patent_url = 'http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&p=1&u=%2Fnetahtml%2FPTO%2Fsearch-bool.html&r=' + str(number) + '&f=G&l=50&co1=AND&d=PTXT&s1=vestas&OS=vestas&RS=vestas'
get_patent_data(patent_url, search_string)
if __name__ == '__main__':
main()主要研究的就是几个跳转链接的格式,自己改一下就能实现不同的自定义搜索方式。
最后结果:

enjoy it!















 1250
1250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









