










我们知道数据是一个公司的命脉,随着业务越做越大,数据量也会越来越大,计算也会越来越复杂,性能,可靠性,可扩展性的需求就会越来越强烈,这个时候一个集中式的数据库显然已经满足不了需求了。对于技术决策者来说有两条路可以走,第一:按照现有的大型数据库的解决方案,比如SQL SERVER Cluster
或者Oracle RAC
等,
但是这也就等于走上了一条烧钱的道路,小则几十万,大则上百万乃至更多;第二:使用真正能够扩展的分布式数据库,利用中小型服务器甚至是PC
机的累加来替代大型的服务器,这也是很多公司希望的,却苦于没有合适产品,现在有了ClusterKiller
,用它真正能给您带来:
高性能,高可用性,高扩展性,高性价比。
http://www.mediafire.com/?bd0bdjm2gxh 介绍的录像版本
http://www.mediafire.com/?0tygenydtdg demo的录像版本
http://www.mediafire.com/?czceymw5dxz 试用版
http://www.mediafire.com/?0tygenydtdg demo的录像版本
http://www.mediafire.com/?czceymw5dxz 试用版
交流方式:msn:web668@hotmail.com;QQ:
39868224;手机:13810901198
2.1 SQL SERVER的集群模式
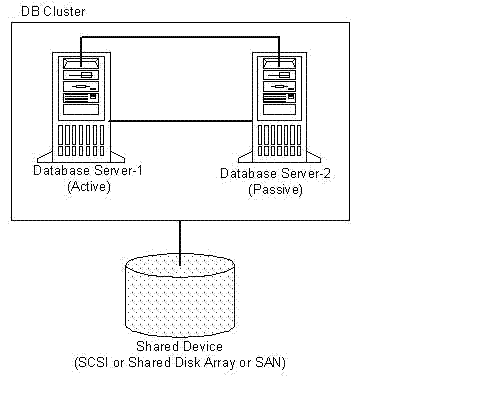
这种结构只能说是一种故障转移的机制,当有一个节点出现问题后把负载转移到另一个节点上。在负载能力上和扩展性上没有任何办法,而且还浪费了硬件资源
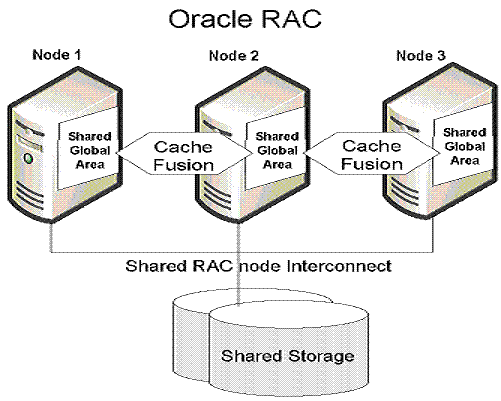
Oracle Rac最多可支持64个节点,基本上算是解决了性能,扩展性的问题了,但是它在存储上还是一个单点,且不说出现故障怎么办,IO也可能会成为性能瓶颈。 我们都知道一个数据库大到一定程度的时候,在物理上分区才能从根本上解决问题,对几十万数据进行查找和几百万上千万的数据进行查找在系统的消耗上以及响应时间上有着几何级的降低。
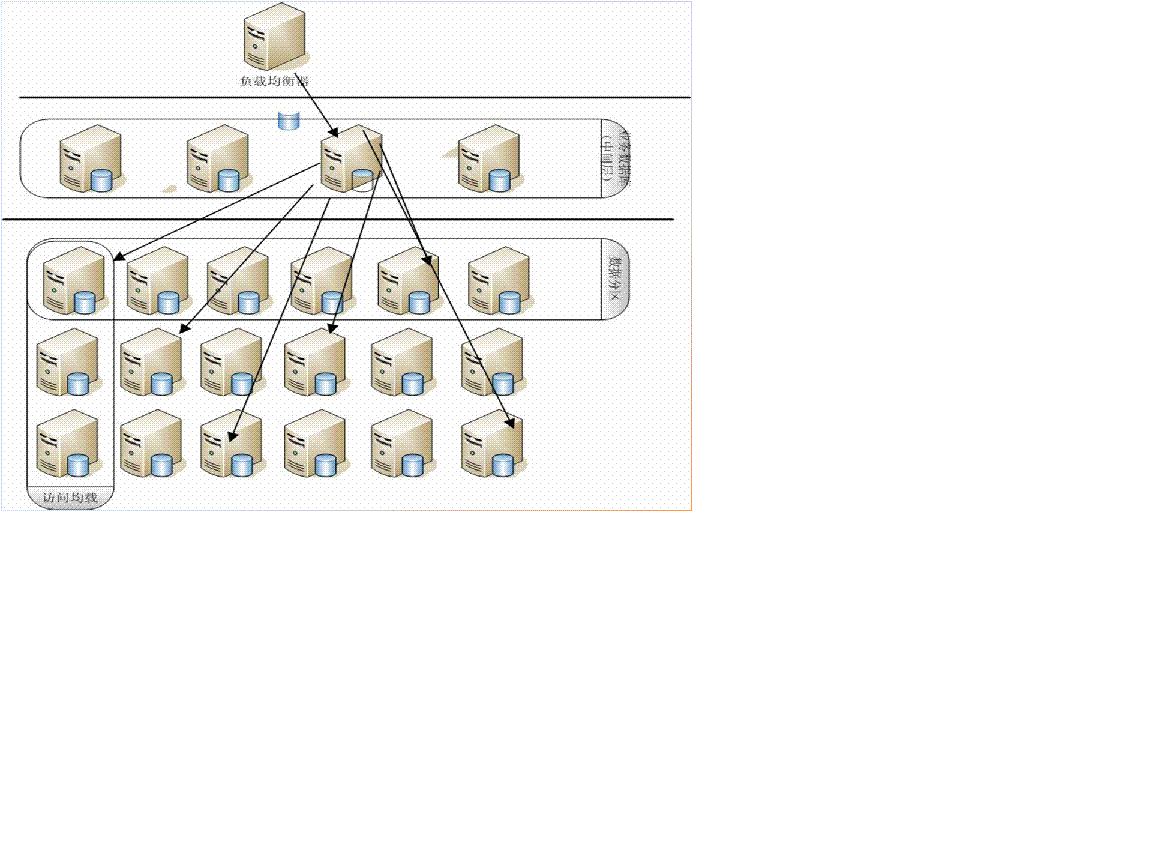
从图例中可以看出,下面的像网格一样的机器叫数据层,每个机器上存储着数据全集的一个分区,每一行组成一个数据全集,每一列是某个分区的多份相同的数据从而达到查询时负载均衡的效果,同时也是高可用性的保障:某个列的机器出现问题后其他的机器会负载访问。为了不让这样一个复杂的结构暴露给应用程序,在数据层上面又放了一层机器叫中间层,中间层
机器的数据库中驻留着的中间件来处理SQL
语句,根据SQL
语句的类型和条件来决定由哪些机器来提供服务。在中间层的外面加一个负载均衡设备,
这样应用程序或者开发/
维护的人员通过负载均衡设备连接到中间层的任意一台机器上操作,感觉就像还在使用原来的一个数据库那样,易用性非常好。以下从各个角度具体的说明一下:
l
开发:中间件是宿主在数据库中的,所以面对数据库写SQL
语句的方式没有改变,只需要把SQL
语句从语法的角度上封装一下即可。还是利用原有的数据库的管理工具,不需要使用的新的管理工具,不需要改变原有的使用习惯,不需要学习新的知识。
l
数据库维护:对于维护表,存储过程,安全等数据库对象还是像使用一个数据库那样在中间层的任意一台机器上执行,中间件会抓取到更改并分发到其他的机器上。不会增加额外的工作量。
l
机器维护:因为这个结构比集中式的结构在机器的数量上要增加了很多,所以在机器层面上的维护成本比以前要有所增加。不过对于机器的维护不会影响整个结构的可用性,只需要在中间层的任意一台机器上更改一下配置就可以把某台机器添加到结构中或从结构中移出。
l
诊断:当出现异常后会明确的指定出错原因以及出错的机器,另外还有执行日志详细的记录每个执行步骤的细节。
l
分区:支持多种数据类型的分区,分区方式有静态分区和线形增长两种方式。静态分区不言而喻就是一开始就要规划好分区的个数;线形增长方式就是一开始只有一个或少数几个分区列,随着数据量和访问的增长的时候再添加新的分区从而达到了线性扩展的效果
l 总结:中间件的定位和作用是只是把很多的数据库服务器联合起来最终实现高扩展性,高可用性以及高性能。许多关键的数据库技术比如事务,连接池,锁,安全等还是依靠数据库来完成,无论从研发成本还是实施的风险都降到最低。
l
故障转移/
可靠性
n SQL SERVER Cluster
:能做到前面的计算节点的故障转移,后面的存储设备还是单点
n Oracle RAC
:能做到前面的计算节点的故障转移,后面的存储设备还是单点
n Cluster Killer
:从每个维度上都是可扩展的,所以无论从哪个维度上的机器损坏以后都能找到替代者从而实现故障转移。
l
负载均衡
n SQL SERVER Cluster
:从它的工作机制上可以看出它的两个节点只能有一个处于工作状态,所以没有负载均衡能力
n Oracle RAC
:它前面的几个计算节点是可以同时提供服务的,但是后面的存储设备只有一个。所以说是计算能够均载,存储不能均载
n Cluster Killer
:即能够计算均载也能存储均载
l
扩展性
n SQL SERVER Cluster
:只能够两个计算节点带一个存储组成
n Oracle RAC
:最多64
个节点带一个存储组成
n Cluster Killer
:每个维度上都能扩展,而且能够根据数据的增加线形扩展,最小用两台机器就可以搭建起来,另外每个机器之间的关系是松散耦合的,扩展起来不需要复杂的安装,配置。
l
硬件要求
n SQL SERVER Cluster
:因为要使用能够连接存储设备的服务器,而这类服务器的配置都很高,都是中高档服务器,价格不菲。而且还有一个节点在正常情况下是闲置的,所以性价比低
n Oracle RAC
:它的硬件配置要求同上,但是起码没有闲置的资源,性价比中
n Cluster Killer
:不需要每个机器的紧密耦合,对机器的配置没有要求,用买一个集群的钱可以买几十台小型服务器或者上百台的PC
机,Google
的分布式结构已经验证了它的高性价比。
3.1 某大型求职/招聘网站
l
项目背景:给企业方使用的一个搜索个人简历的系统,特点是数据量大,查询条件复杂,更新频繁。具体数据为:简历主表700
万,子表从1600
万到2000
万不等;每天查询12
万次,40%
的查询条件中带有关键词;个人用户每天新增/
更新简历的事务数为120
万次。
l
解决方案:使用30
台DELL 2950小
型PC
服务器搭建起分布式数据库结构。
l
性能测试数据:
n
测试模型:查询
n
查询条件:大于等于线上用户的实际条件
n
测试工具:LoadRunner8.0
n
测试时间:20
小时
n
并发数:50
n
响应时间:平均1.5
秒,90%
的响应时间在1.9
秒以下,方差:1.1
n
查询次数:成功487325
,超时:98
,没有其它类型错误
l
收益:
n
因为组件不会影响业务逻辑,所以业务程序不用重构,只用2
天就升级到新的架构上
n
查询时间从原来的10
秒缩减到不到1
秒,92%
的查询在秒以下,大大提高客户体验
n
真正的7*24
的持续提供服务
n
系统的扩展能力大大增强,使得客户有能力上原来不能上的更复杂的业务逻辑,建立更好的搜索模型,从而提升了客户在行业内的竞争实力。















 3308
3308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









