







HuggingFace数据集介绍
地址:https://huggingface.co/datasets
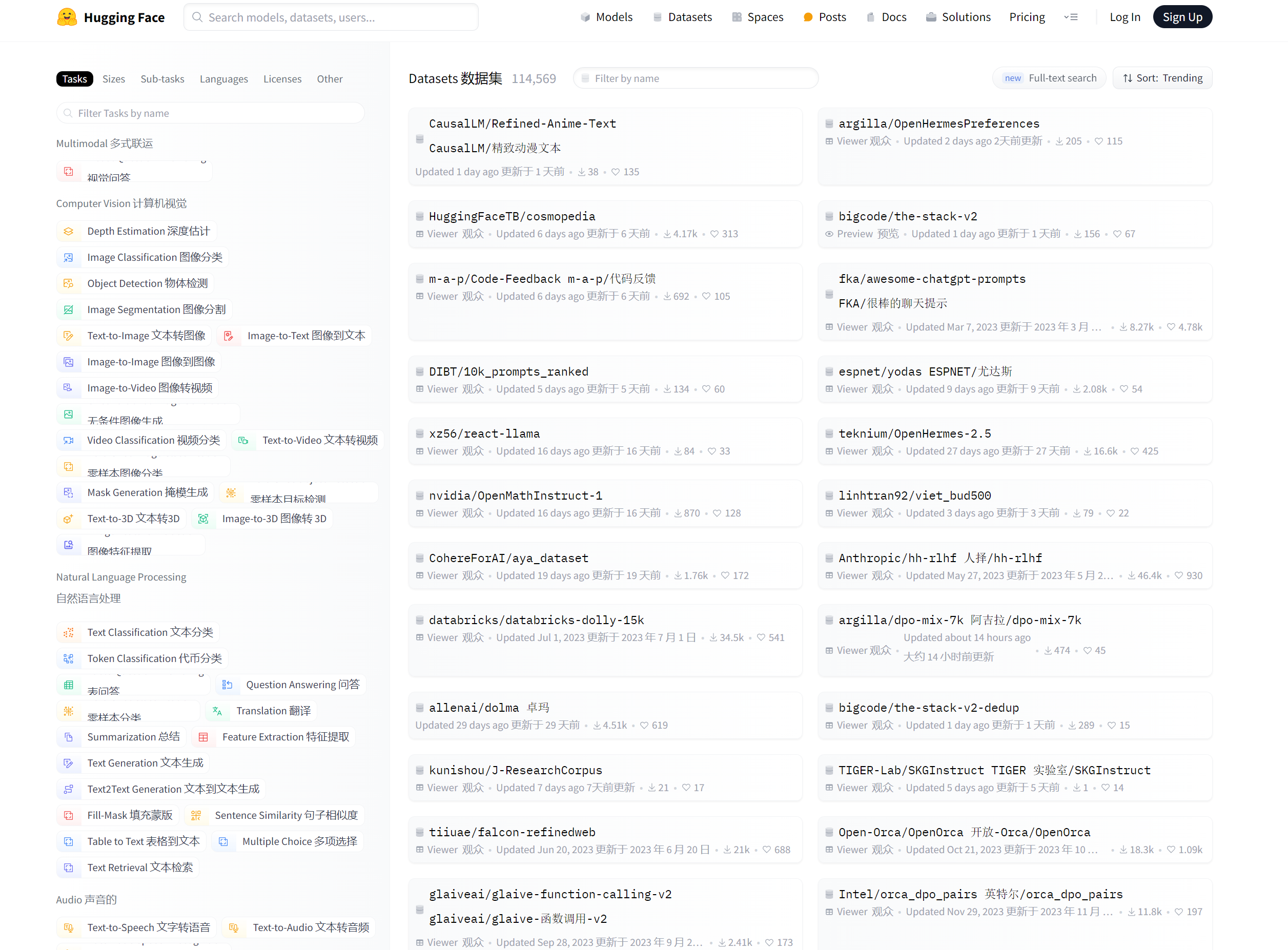
点击某个数据集可以看到详细介绍 ,数据集多以英语为主

数据集的使用
加载数据集
#加载数据集
from datasets import load_dataset
#HuggingFace数据集工具加载数据往往只需一行代码'seamew/ChnSentiCorp'为数据集名称
dataset = load_dataset(path='seamew/ChnSentiCorp')
dataset
注意:由于HuggingFace把数据集存储在谷歌云盘上,在国内加载时可能会遇到网络问题,推荐国内镜像站
地址:https://hf-mirror.com/
使用国内镜像下载数据集:
1、需要使用huggingface-cli进行下载,
🔰 Hugging Face CLI(命令行界面)是一个工具,用于与Hugging Face模型和数据集的Hub进行交互。它提供了一种简单的方式来搜索、下载、上传、共享和管理模型、数据集以及其他相关资源。用户可以通过命令行轻松地访问Hugging Face生态系统中的各种模型和数据集,从而加快机器学习实验的速度并促进模型和数据的共享与合作。huggingface-cli 的优点包括:
- 支持断点续传,避免因网络中断而导致的文件损坏。
- 支持指定镜像 endpoint,可直接使用本站镜像服务。
- 默认使用多文件并行下载,速度更快。(如需更极致的下载速度,可对文件链接用其他多线程下载工具下载,默认不推荐)
- 支持 Gated model 下载 如 llama。–token参数,详见文档。
- 支持排除特定文件或指定特定文件下载,便于用户自定义下载内容。
- 安装 Hugging Face CLI:
pip install --upgrade pip
pip install huggingface-cli
pip install -U huggingface_hub
- 设置环境变量数据源更改为镜像站
#Linux设置
export HF_ENDPOINT=https://hf-mirror.com
#Windows Powershell
$env:HF_ENDPOINT = "https://hf-mirror.com"
- 下载模型
huggingface-cli download --resume-download gpt2 --local-dir gpt2
- 下载数据集
以下载弱智笑话数据集为例
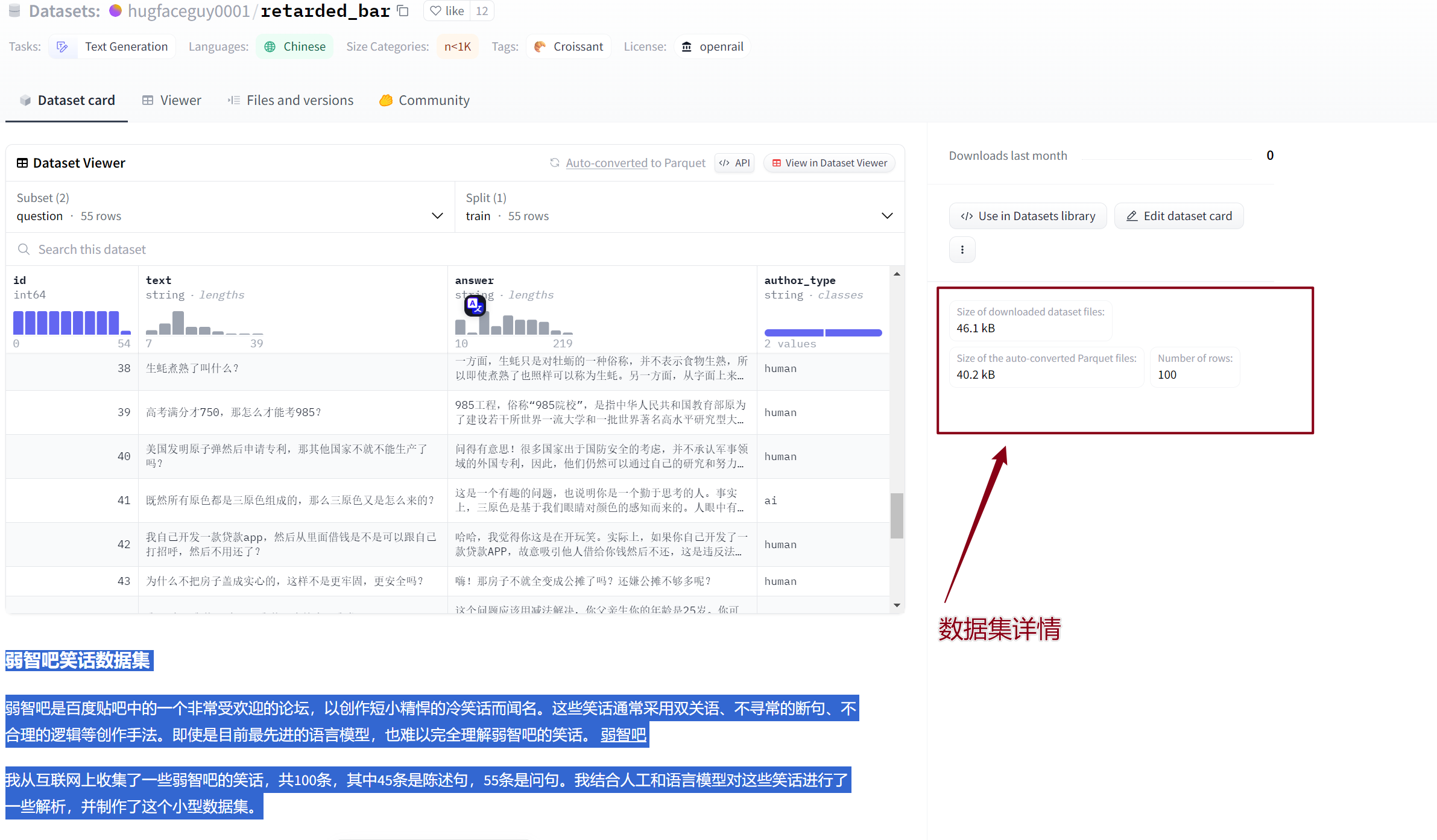
huggingface-cli download --repo-type dataset --resume-download hugfaceguy0001/retarded_bar --local-dir retarded_bar
🔰参数解释:
download:指示 huggingface-cli 执行下载操作的命令。--repo-type dataset:指定了要下载的资源类型是数据集。--resume-download:启用了恢复下载功能,这意味着如果下载中断,您可以在之后的下载中从中断处继续下载,而不必重新开始。wikitext:指定要下载的数据集名称或标识符。在这里,它是一个名为 “wikitext” 的数据集。--local-dir wikitext:指定将数据集下载到本地的目录。在这里,它指定了一个名为 “wikitext” 的目录,数据集将被下载到该目录中。
加载数据集使用
dataset = load_dataset('acronym_identification')
print(dataset)
输出
DatasetDict({
train: Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 14006
})
validation: Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 1717
})
test: Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 1750
})
})
数据集保存至硬盘
#第3章/将数据集保存到磁盘
dataset.save_to_disk(dataset_dict_path='./data/acronym_identification')
从本地加载数据集
from datasets import load_from_disk
dataset = load_from_disk('./data/acronym_identification')
print(dataset)
数据集基本操作
数据集对象的查询的在语法上与使用 Pandas DataFrame 的操作非常相似
dataset = load_from_disk('./data/acronym_identification')
# 使用train数据子集做后续的实验
dataset = dataset['train']
print(dataset)
# 查看数据样例
for i in [12, 17, 20, 26, 56]:
print(dataset[i])
输出
Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 14006
})
#查看数据样例
{'id': 'TR-12', 'tokens': ['Inspired', 'by', 'recent', 'advances', 'in', 'Generative', 'Adversarial', 'Networks', '(', 'GANs', ')', ',', 'we', 'developed', 'an', 'algorithm', 'for', 'domain', 'adaptation', 'for', 'aerial', 'imagery', 'based', 'on', 'GANs', '.'], 'labels': [4, 4, 4, 4, 4, 0, 2, 2, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4]}
{'id': 'TR-17', 'tokens': ['Given', 'an', 'FSP', 'model', ',', 'the', 'LTSA', 'tool', 'generates', 'an', 'executable', 'Labeled', 'Transition', 'System', '(', 'LTS', ')', 'suitable', 'for', 'automated', 'analysis', 'and', 'animation', '.'], 'labels': [4, 4, 1, 4, 4, 4, 1, 4, 4, 4, 4, 0, 2, 2, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4]}
{'id': 'TR-20', 'tokens': ['If', 'the', 'entity', 'pairs', 'of', 'two', 'triplets', 'are', 'identical', 'but', 'the', 'relations', 'are', 'different', ',', 'the', 'sentence', 'will', 'be', 'added', 'to', 'the', 'EPO', 'set', '.'], 'labels': [4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 1, 4, 4]}
{'id': 'TR-26', 'tokens': ['Model', '2', ',', 'similar', 'to', 'model', '1', ',', 'has', 'a', 'multiple', 'input', 'single', 'output', '(', 'A', '-', 'MISO', ')', 'structure', '.'], 'labels': [4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 2, 2, 2, 4, 4, 4, 1, 4, 4, 4]}
{'id': 'TR-56', 'tokens': ['Finally', ',', 'in', 'Case', 'III', ',', 'while', 'the', 'same', 'CSI', 'assumption', 'as', 'in', 'Case', 'II', 'are', 'made', ',', 'an', 'optimal', 'relay', 'selection', 'scheme', 'is', 'implemented', ',', 'whereby', 'the', 'relay', 'that', 'achieves', 'the', 'maximum', 'secrecy', 'rate', 'is', 'chosen', 'for', 'retransmission', '.'], 'labels': [4, 4, 4, 4, 4, 4, 4, 4, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4]}
数据过滤
def f(data):
return data['tokens'][0].startswith('In')
new_dataset=dataset.filter(f)
for i in [12, 17, 20, 26, 56]:
print(new_dataset[i])
print(dataset)
print(new_dataset)
输出
{'id': 'TR-159', 'tokens': ['In', 'a', 'complementary', 'vein', ',', 'eyetracking', 'signal', 'has', 'been', 'used', 'for', 'linguistic', 'annotation', 'tasks', 'such', 'as', 'POS', 'tagging', 'and', 'prediction', 'of', 'syntactic', 'functions', '.'], 'labels': [4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 1, 4, 4, 4, 4, 4, 4, 4]}
{'id': 'TR-265', 'tokens': ['In', ',', 'three', 'frequently', 'used', 'clustering', 'techniques', ',', 'namely', ',', 'k', '-', 'means', ',', 'hierarchical', 'algorithms', ',', 'and', 'the', 'Dirichlet', 'process', 'mixture', 'model', '(', 'DPMM', ')', 'algorithm', ',', 'were', 'performed', 'on', 'the', 'smart', 'meter', 'data', 'with', 'different', 'frequencies', 'varying', 'from', 'every', '1', 'minute', 'to', '2', 'hours', 'to', 'investigate', 'how', 'the', 'resolution', 'of', 'smart', 'meter', 'data', 'influences', 'the', 'clustering', 'results', '.'], 'labels': [4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 2, 2, 2, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4]}
{'id': 'TR-288', 'tokens': ['In', 'order', 'to', 'avoid', 'hidden', 'terminals', 'in', 'multi', '-', 'hop', 'and', 'overlapping', 'basic', 'service', 'set', '(', 'OBSS', ')', 'scenarios', ',', 'a', 'receiver', 'should', 'also', 'include', 'this', 'field', 'in', 'the', 'ACK', 'control', 'frame', 'to', 'also', 'play', 'the', 'role', 'of', 'CTS', 'control', 'frame', '.'], 'labels': [4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 2, 2, 2, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 1, 4, 4, 4]}
{'id': 'TR-362', 'tokens': ['In', 'the', 'considered', 'model', ',', 'each', 'user', 'transmits', 'a', 'superposition', 'of', 'two', 'messages', 'to', 'a', 'base', 'station', '(', 'BS', ')', 'with', 'separate', 'transmit', 'power', 'and', 'the', 'BS', 'uses', 'a', 'successive', 'decoding', 'technique', 'to', 'decode', 'the', 'received', 'messages', '.'], 'labels': [4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 2, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4]}
{'id': 'TR-598', 'tokens': ['In', 'DeepR', ',', 'the', 'standard', 'Stochastic', 'Gradient', 'Descent', '(', 'SGD', ')', 'optimizer', 'is', 'augmented', 'with', 'a', 'random', 'walk', 'in', 'parameter', 'space', '.'], 'labels': [4, 4, 4, 4, 4, 0, 2, 2, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4]}
Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 14006
})
Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 1534
})
训练测试集拆分
#切分训练集和测试集
train_test=dataset.train_test_split(test_size=0.1) #test_size=0.1 代表拆分10%的数据
print("原数据集:")
print(dataset)
print("拆分后:")
print(train_test)
输出
原数据集:
Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 14006
})
拆分后:
DatasetDict({
train: Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 12605
})
test: Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 1401
})
})
数据分桶
🔰当我们处理一些数值型数据时,有时候我们希望将这些数据按照一定的规则分成几个小组,每个小组里面的数据在某些方面是类似的。这个过程就像是把水桶里的水分成几个小桶一样,每个小桶里的水性质是相似的。
举个例子,假设我们有一些人的年龄数据,从1岁到100岁不等。我们希望把这些年龄数据分成几个年龄段,比如婴儿、幼儿、青少年、成年人等。这样做的好处是,我们可以更好地理解和描述这些数据,比如统计某个年龄段的人口数量,或者分析不同年龄段的人的特点。
在机器学习中,数据分桶也有类似的作用。我们可以根据数据的特点,将连续的数值型特征分成几个范围或区间,从而简化模型、处理异常值、改善模型性能等。这样做可以让我们更好地利用数据来训练模型,提高模型的准确性和可解释性。
from datasets import load_from_disk
dataset = load_from_disk('./data/acronym_identification')
# 使用train数据子集做后续的实验
dataset = dataset['train']
#第数据分桶
bucket_dataset=dataset.shard(num_shards=10, index=0) #num_shards 数据分多少份 ,index返回第多少份数据,索引0开始
print("原数据集:")
print(dataset)
print("分桶后:")
print(bucket_dataset)
输出
原数据集:
Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 14006
})
分桶后:
Dataset({
features: ['id', 'tokens', 'labels'],
num_rows: 1401
})
字段操作
#字段重命名
dataset.rename_column('text', 'text_rename')
#删除字段
new_rename_column=new_rename_column.remove_columns(['key'])
print(new_rename_column)
#map()函数遍历修改
dataset = dataset['train']
print('修改前')
print(dataset[0])
# map修改每条数据
def f(data):
data['id'] = 'My id: ' + data['id']
return data
dataset = dataset.map(f)
print(dataset[0])
#使用批处理加速修改处理速度
#function 计算的函数,batched批量处理,batch_size每批处理的数据条数 num_proc线程数一般设置为CPU核心数量
dataset = dataset.map(function=f, batched=True, batch_size=1000, num_proc=4)
输出
#字段重命名
Dataset({
features: ['key', 'tokens', 'labels'],
num_rows: 14006
})
#删除字段
Dataset({
features: ['tokens', 'labels'],
num_rows: 14006
})
# map修改每条数据
修改前
{'id': 'TR-0', 'tokens': ['What', 'is', 'here', 'called', 'controlled', 'natural', 'language', '(', 'CNL', ')', 'has', 'traditionally', 'been', 'given', 'many', 'different', 'names', '.'], 'labels': [4, 4, 4, 4, 0, 2, 2, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4]}
修改后
{'id': 'My id: TR-0', 'tokens': ['What', 'is', 'here', 'called', 'controlled', 'natural', 'language', '(', 'CNL', ')', 'has', 'traditionally', 'been', 'given', 'many', 'different', 'names', '.'], 'labels': [4, 4, 4, 4, 0, 2, 2, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4]}
#使用批处理加速修改处理速度
设置数据格式
dataset = dataset['train']
print('修改前')
print(dataset[0])
dataset.set_format(type='torch', columns=['labels'], output_all_columns=True)
print('修改后')
print(dataset[0])
- 参数type表明要修改为的数据类型,常用的取值有numpy、torch、tensorflow、pandas等。
- 参数columns表明要修改格式的字段。
- 参数output_all_columns表明是否要保留其他字段,设置为True表明要保留
输出 labels列 数据类型变为 tensor
修改前
{'id': 'TR-0', 'tokens': ['What', 'is', 'here', 'called', 'controlled', 'natural', 'language', '(', 'CNL', ')', 'has', 'traditionally', 'been', 'given', 'many', 'different', 'names', '.'], 'labels': [4, 4, 4, 4, 0, 2, 2, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4]}
修改后
{'labels': tensor([4, 4, 4, 4, 0, 2, 2, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4]), 'id': 'TR-0', 'tokens': ['What', 'is', 'here', 'called', 'controlled', 'natural', 'language', '(', 'CNL', ')', 'has', 'traditionally', 'been', 'given', 'many', 'different', 'names', '.']}

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









