






如何优化提示以生成 Cypher 语句,以便从 Neo4j 中检索与你的 LLM 应用程序相关的信息

由 Midjourney 构想的知识图谱聊天机器人。
我们探讨了如何在 LangChain 库中开始使用 Cypher 搜索,以及为什么您会想要在您的 LLM 应用程序中使用知识图谱。在这篇博客文章中,我们将继续探索将知识图谱集成到 LLM 和 LangChain 应用程序的各种用例。在这个过程中,您将学习如何改进提示以产生更好、更准确的 Cypher 语句。
具体来说,我们将通过提供几个 Cypher 语句示例来探讨如何使用 LLMs 的少量样本能力,这些示例可以用来指定 LLM 应该产生哪些 Cypher 语句,结果应该是什么样子,等等。此外,您还将学习如何将 Neo4j 图数据科学库中的图算法集成到您的 LangChain 应用程序中。
GitHub.
所有代码都可以在 GitHub 上找到。
Neo4j 环境设置
I
在这篇博客文章中,我们将使用在 Neo4j Sandbox 中可用的 Twitch 数据集。
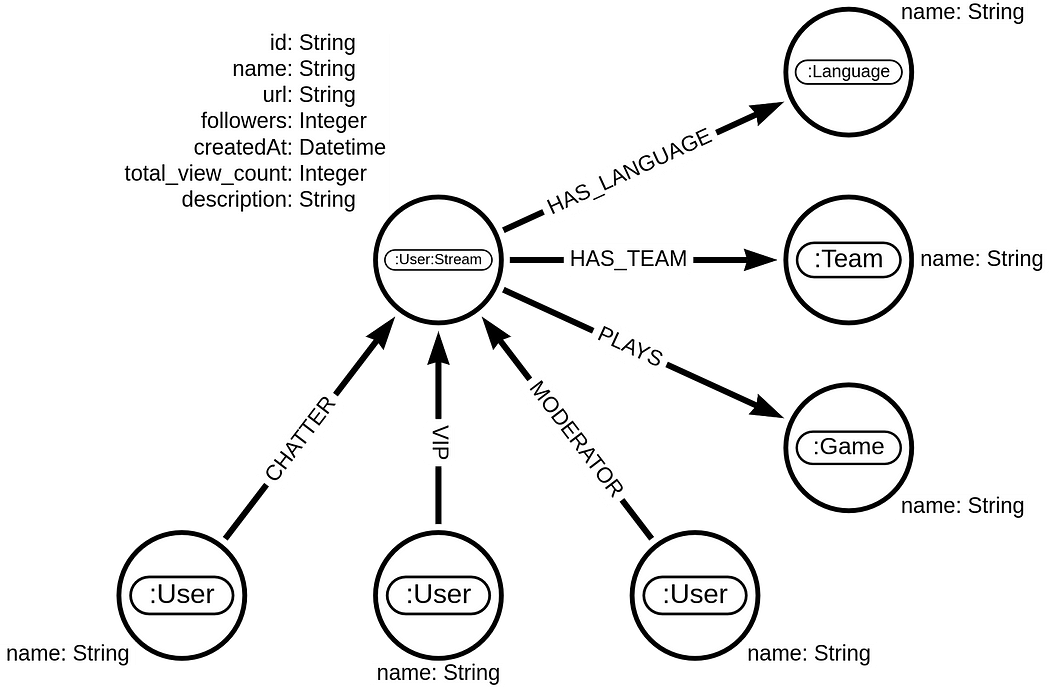
Twitch dataset graph model. Image by the author.
Twitch 数据集图形模型。图片由作者提供。
Twitch 社交网络由用户组成。这些用户中只有一小部分通过直播流广播他们的游戏或活动。在图形模型中,进行直播的用户被标记为次要标签“Stream”。有关他们所属的团队、他们在直播中玩的游戏以及他们呈现内容的语言的额外信息是存在的。我们也知道在抓取时他们有多少关注者,历史总浏览量,以及他们何时创建了他们的账户。对于网络分析来说,最相关的信息是知道哪些用户参与了主播的聊天。你可以区分在直播中聊天的用户是普通用户(CHATTER 关系)、直播的版主(MODERATOR 关系)还是直播的 VIP。
提高 LangChain Cypher 搜索
首先,我们必须设置 LangChain Cypher 搜索。
import os
from langchain.chat_models import ChatOpenAI
from langchain.chains import GraphCypherQAChain
from langchain.graphs import Neo4jGraph
os.environ['OPENAI_API_KEY'] = "OPENAI_API_KEY"
graph = Neo4jGraph(
url="bolt://ip:7687",
username="nXX",
password="XX"
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True,
)
我很喜欢在 LangChain 库中设置 Cypher 搜索是多么容易。你只需要定义 Neo4j 和 OpenAI 的凭证,然后就可以开始了。在幕后, graph 对象检查图模式模型并将其传递给 GraphCypherQAChain 以构建准确的 Cypher 语句。
Let’s begin with a simple question.
让我们从一个简单的问题开始。
chain.run("""
Which fortnite streamer has the most followers?
""")
Results 结果

Generated answer. Image by the author.
生成的答案。图片由作者提供。
Cypher 链构建了一个相关的 Cypher 语句,用它从 Neo4j 检索信息,并以自然语言形式提供了答案。
现在让我们再问一个问题。
chain.run("""
Which italian streamer has the most followers?
""")
Results 结果
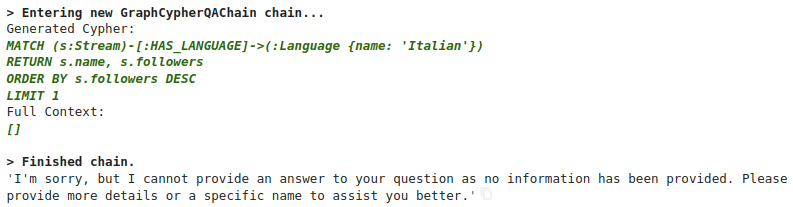
Generated answer. Image by the author.
生成的答案。图片由作者提供。
生成的 Cypher 语句看起来是有效的,但不幸的是,我们没有得到任何结果。问题在于语言值存储为两个字符的国家代码,而 LLM 并不知道这一点。我们有几种选择来克服这个问题。首先,我们可以通过提供 Cypher 语句的示例来利用 LLMs 的少量样本能力,这样模型在生成 Cypher 语句时就会模仿这些示例。要在提示中添加示例 Cypher 语句,我们必须更新生成 Cypher 的提示。你可以查看用于生成 Cypher 语句的默认提示,以更好地理解我们将要进行的更新。
from langchain.prompts.prompt import PromptTemplate
CYPHER_GENERATION_TEMPLATE = """
Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Cypher examples:
# How many streamers are from Norway?
MATCH (s:Stream)-[:HAS_LANGUAGE]->(:Language {{name: 'no'}})
RETURN count(s) AS streamers
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
The question is:
{question}"""
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"], template=CYPHER_GENERATION_TEMPLATE
)
如果你将新的 Cypher 生成提示与默认提示进行比较,你可以观察到我们只添加了 Cypher 示例部分。我们添加了一个示例,在这个示例中,模型可以观察到语言值是以两个字符的国家代码给出的。现在我们可以测试改进后的 Cypher 链来回答关于最受关注的意大利主播的问题。
chain_language_example = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True,
cypher_prompt=CYPHER_GENERATION_PROMPT
)
chain_language_example.run("""
Which italian streamer has the most followers?
""")
Results 结果

Generated answer. Image by the author.
生成的答案。图片由作者提供。
该模型现在知道语言以两个字符的国家代码给出,并且现在可以准确地回答使用语言信息的问题。
_
我们解决这个问题的另一种方法是在定义图形模式信息时给出每个属性的一些示例值。_
使用图形算法回答问题
在之前的博客文章中,我们探讨了如何将图形数据库集成到LLM应用程序中,可以通过找到它们之间的最短或其他路径来回答实体是如何连接的问题。今天,我们将看看图形数据库在LLM应用程序中的其他用例,其他数据库难以处理,特别是我们如何使用像 PageRank 这样的图形算法来提供相关答案。例如,我们可以使用个性化的 PageRank 在查询时为用户提供推荐。
看看下面的例子:
chain_language_example.run("""
Which streamers should also I watch if I like pokimane?
""")
Results 结果
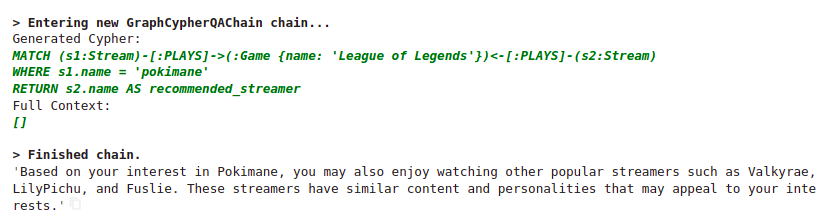
有趣的是,每次我们重新运行这个问题时,模型都会生成一个不同的 Cypher 语句。然而,有一件事是一致的。
重复指令三次可以帮助 gpt-3.5-turbo 解决这个问题。然而,通过重复指令,您正在增加令牌计数,因此,Cypher 生成的成本也会相应增加。因此,需要一些提示工程来使用最少的令牌计数获得最佳结果。
另一方面,GPT-4 在遵循指令方面要出色得多。
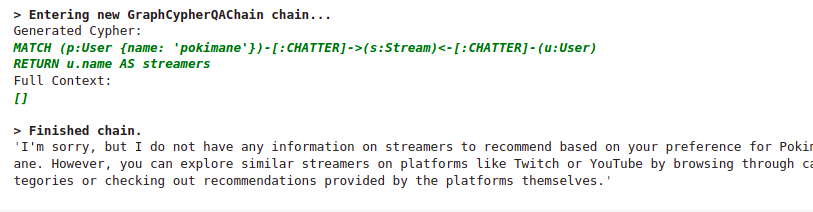
GPT-4 没有从其内部知识中添加任何信息。然而,它生成的 Cypher 语句仍然相对糟糕。同样,我们可以通过在 LLM 提示中提供 Cypher 示例来解决这个问题。
如前所述,我们将使用个性化 PageRank 来提供流媒体推荐。但首先,我们需要投影内存中的图形并运行节点相似性算法,以准备图形以便能够提供推荐。查看我之前的博客文章,了解更多关于如何使用图形算法分析 Twitch 网络的信息。
# Project in-memory graph
graph.query("""
CALL gds.graph.project('shared-audience',
['User', 'Stream'],
{CHATTER: {orientation:'REVERSE'}})
""")
# Run node similarity algorithm
graph.query("""
CALL gds.nodeSimilarity.mutate('shared-audience',
{similarityMetric: 'Jaccard',similarityCutoff:0.05, topK:10, sudo:true,
mutateProperty:'score', mutateRelationshipType:'SHARED_AUDIENCE'})
""")
节点相似性算法将需要大约 30 秒才能完成,因为数据库中几乎有五百万用户。使用个性化 PageRank 提供推荐的 Cypher 语句如下:
MATCH (s:Stream)
WHERE s.name = "kimdoe"
WITH collect(s) AS sourceNodes
CALL gds.pageRank.stream("shared-audience",
{sourceNodes:sourceNodes, relationshipTypes:['SHARED_AUDIENCE'],
nodeLabels:['Stream']})
YIELD nodeId, score
WITH gds.util.asNode(nodeId) AS node, score
WHERE NOT node in sourceNodes
RETURN node.name AS streamer, score
ORDER BY score DESC LIMIT 3
T
开放人工智能 LLMs 在使用图数据科学库方面可以做得更好,因为他们的知识截止日期是 2021 年 9 月,而图数据科学库的第 2 版是在 2022 年 4 月发布的。因此,我们需要在提示中提供另一个示例来展示 LLM 如何使用个性化 PageRank 来给出推荐。
CYPHER_RECOMMENDATION_TEMPLATE = """Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Cypher examples:
# How many streamers are from Norway?
MATCH (s:Stream)-[:HAS_LANGUAGE]->(:Language {{name: 'no'}})
RETURN count(s) AS streamers
# Which streamers do you recommend if I like kimdoe?
MATCH (s:Stream)
WHERE s.name = "kimdoe"
WITH collect(s) AS sourceNodes
CALL gds.pageRank.stream("shared-audience",
{sourceNodes:sourceNodes, relationshipTypes:['SHARED_AUDIENCE'],
nodeLabels:['Stream']})
YIELD nodeId, score
WITH gds.util.asNode(nodeId) AS node, score
WHERE NOT node in sourceNodes
RETURN node.name AS streamer, score
ORDER BY score DESC LIMIT 3
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
The question is:
{question}"""
CYPHER_RECOMMENDATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"], template=CYPHER_RECOMMENDATION_TEMPLATE
)
我们现在可以测试个性化 PageRank 推荐。
chain_recommendation_example = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0, model_name='gpt-4'), graph=graph, verbose=True,
cypher_prompt=CYPHER_RECOMMENDATION_PROMPT,
)
chain_recommendation_example.run("""
Which streamers do you recommend if I like pokimane?
""")
Results 结果
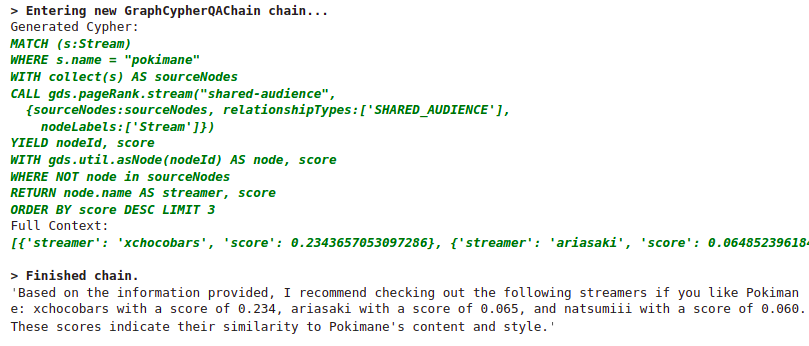
Generated answer. Image by the author.
生成答案。图片由作者提供。
不幸的是,在这里,我们必须使用 GPT-4 模型,因为 gpt-3.5-turbo 很固执,不愿意模仿复杂的个性化 PageRank 示例。
我们还可以测试 GPT-4 模型是否会决定将个性化 PageRank 推荐推广到其他用例中。
chain_recommendation_example.run("""
Which streamers do you recommend to watch if I like Chess games?
""")
Results 结果

Generated answer. Image by the author.
生成的答案。图片由作者提供。
然而,LLMs 非常擅长倾听暗示:
chain_recommendation_example.run("""
Which streamers do you recommend to watch if I like Chess games?
Use Personalized PageRank to provide recommendations.
Do not exclude sourceNodes in the answer
""")
Results 结果
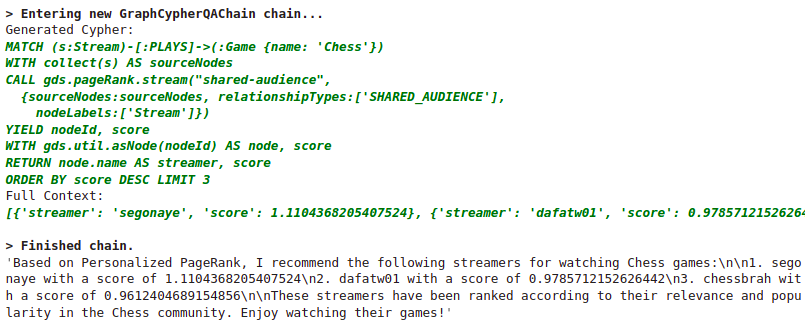
Generated answer. Image by the author.
生成的答案。图片由作者提供。















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









