









Towards Cross-Modality Medical Image Segmentation with Online Mutual Knowledge Distillation论文的研读
原文出处:英文原文
本文主要翻译了摘要 引言以及结论部分,方法以及结果部分捡重点进行翻译研读,有不恰当之处,敬请指出!
摘要:深度卷积神经网络的成功部分归功于大量注释的训练数据。然而,在实践中,获取医疗数据注释通常是昂贵且耗时的。考虑到具有相同解剖结构的多模态数据在临床常规中广泛可用,在本文中,我们的目的是利用从一模态(即辅助模态)中学习到的先验知识(又名形状先验),以提高在另一模态(如目标模式)上的分割性能,以此来弥补注释的稀缺性。为了缓解因模态特定的外观差异造成的学习困难,我们首先提出了一个图像对齐模块(IAM)来缩小辅助模态数据和目标模态数据之间的外观差距。在此基础上,我们提出了一种新的互知识蒸馏(MKD)方案,以充分利用模式共享的知识来实现目标-模式的分割。具体地说,我们将我们的框架构建为两个独立分段器的集成。每个分段程序不仅显式地从相应的注释中提取一种模态知识,而且还以相互引导的方式隐式地从对应的注释中探索另一种模态知识。两个分割器的集成将进一步整合两种模式的知识,并在目标模态上产生可靠的分割结果。在公共的多类心脏分割数据(MMWHS 2017)上的实验结果表明,我们的方法利用额外的MRI数据,在CT分割上取得了很大的改进,优于其他先进的多模态学习方法。
引言
现代临床实践通常涉及多种成像技术,如磁共振成像(MRI)和计算机断层扫描(CT),以便在疾病诊断和手术规划中更全面地了解特定组织或器官(Cao et al. 2017)。例如,CT和MRI被广泛用于提供心脏结构的清晰解剖信息(Zhuang et al. 2019)。由于不同的成像方式基于不同的物理成像原理,它们通常强调有明显视觉对比的器官或组织。例如,在MRI脑扫描中,MRI- t2在水肿部位有更好的视觉效果,然而MRI- t1c则突出恶性肿瘤的区域(Woo, Stone, and Prince 2014)。因此,多模学习逐渐在医学影像领域得到发展。近年来,基于深度学习的方法在许多医学图像分析任务中凭借大量注释数据取得了很好的性能(Litjens et al. 2017)。然而,在医学领域,获取大型标注数据通常是昂贵且耗时的,因为标注需要由专业的医学专家在严格细致的检查下进行。由于不同的成像方式反映了相同的解剖结构,多模态学习已成为弥补医学图像自动分析中标注不足的一个有前途的方向。在这篇论文中,我们的目的是研究利用从一种模态(辅助模态)中学习的先验知识(例如形状先验)来提高在另一模态(目标模态)上的分割性能的有效性,在测试阶段不需要辅助模态数据。
一般来说,一种直观的方式是联合训练,即利用辅助模态和目标模态数据对网络进行训练。另一种直接的方法是利用目标模态数据对从辅助模态数据中学习到的深度卷积神经网络(DCNN)进行优化,这样它就可以将从辅助模态学习到的先验知识转移到目标模态任务中。然而,无论是联合训练还是微调,都不能很好地利用共享的跨模性信息,因为具有代表性的模态共享特征很难从外观差异较大的多模态数据中直接学习。Valindria等人(2018)提出为每种模态数据分配其特定的特征提取器,以减轻不同的多模态现象带来的负面影响。他们提出了四种具有精心设计的参数共享策略的双流架构来探索交叉模态信息,并证明X-Shape更适合多模态图像分割。然而,这些双流结构在确定参数共享时加入了人工干预,并且需要进行特殊的调整以推广到其他医学分析任务中。在我们的问题设置中,网络学习涉及两种模态信息,其中有价值的模态共享知识应该被充分挖掘,以增强网络的泛化,而冗余模态特有的出现应该被对齐,以简化网络学习。
在本文中,我们提出了一种新的基于知识蒸馏的交叉模态图像分割框架,利用辅助模态(如MRI)先验来提高目标模态数据(如CT)的分割性能。本文的主要内容如下:
- 提出了一个有效的多模学习框架,利用一个模态的先验知识来提高另一个模态的分割性能。
- 提出了一种新的互知识精馏方案,以更好地利用分段输出的互引导下的模式共享知识。
- 提出了一种减少跨模态外观差异的图像对齐模块,以促进模态共享知识的学习。
- 在公开的多级心脏分段挑战数据上对我们的方法进行了广泛的评估(Zhuang et al. 2019)。我们的方法优于其他先进的多模态学习方法。
相关工作
Multi-modality Learning in Medical Imaging 医学影像的多模式学习:不同于以往通过联合训练直接融合多模态知识的方法,我们的框架分别采用合成数据和真实数据两个分支,以相互引导的方式整合跨模态知识。
Knowledge Distillation 知识蒸馏:具体知识蒸馏(knowledge distillation)的知识,可以参考这篇博文:知识蒸馏
方法
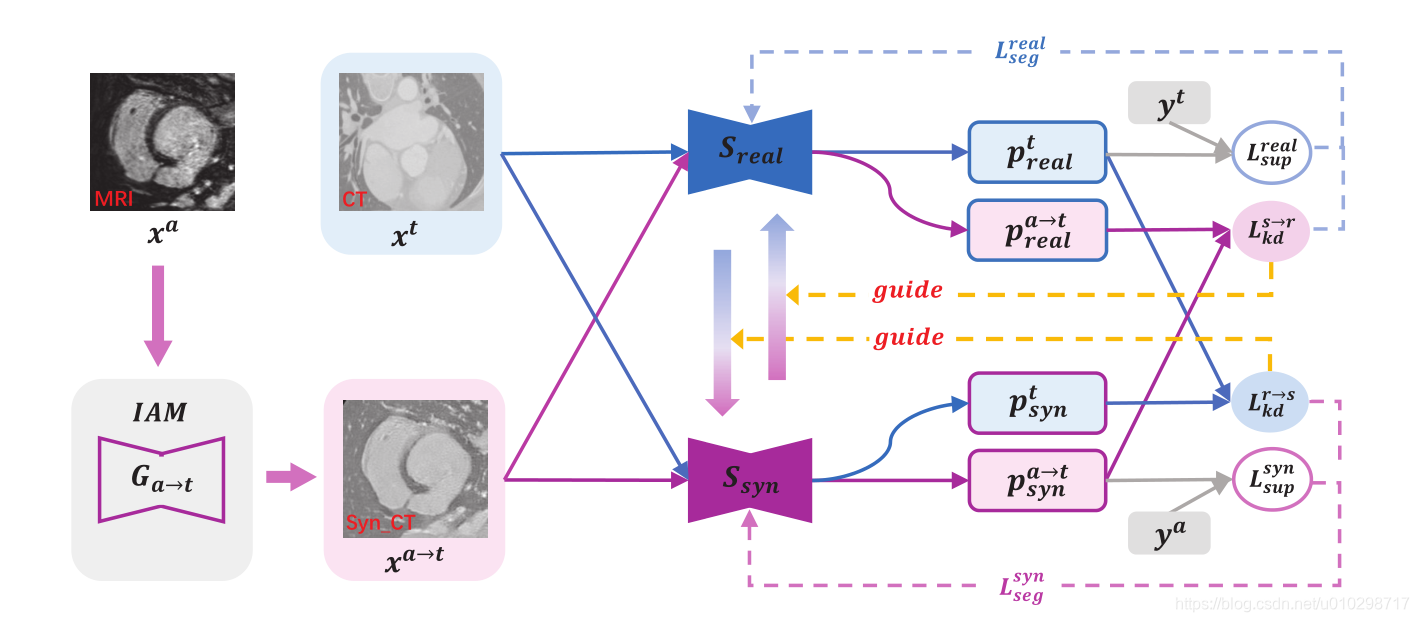
如图所示是论文的架构,其中洋红色和蓝色分别代表辅助模态(如MRI)和目标模态(如CT)的数据流。发生器进行辅助到目标的转化,输出合成的CT数据。红到蓝过渡箭头表示
引导下
到
的知识转移,蓝到洋红色过渡箭头表示
引导下
到
的知识转移。通过这种方式,两个分段器是相互引导的。
本文架构中主要包含两大块:IAM以及Mutual Knowledge Distillation共同知识蒸馏
IAM:利用cycle-consistencyGAN方法,不仅能够通过辅助数据(MRI)转化成为目标数据(CT),还能够实现反向生成。主要目的还是为了实现两种模式图像的转换。具体方法实现参考这篇文章:https://blog.csdn.net/luojun2007/article/details/81157378
Mutual Knowledge Distillation共同知识蒸馏:通过上图的架构可以知道,知识蒸馏阶段包括两种训练,一种是显式训练,一种是隐式训练。
显式训练:具体而言,合成分段器主要通过辅助模态注释
从合成目标模态图像
中学习辅助模态特征,同时真实分段器
主要利用真实目标模态图像
和目标模态ground truth
来探索目标模态信息。下面是显式训练的损失函数的公式:

隐式训练:为了让真实分割器利用合成分割器的指导,我们给真实分割器输入合成的目标模态图像用来获取概率分布图
,并使用知识蒸馏损失函数
鼓励它与合成分段器输出
类似。由于
是被合成目标模式注释直接监管,因此
是可信赖的。此外,因为
本身具备了辅助模式先验信息,从合成到真实的知识蒸馏方案可以将知识从
传递到
,并且促使
有效地整合交叉模式信息。类似的方式,本文也可以将知识从
传递到
。本文将知识蒸馏损失表示为两个概率映射之间的交叉熵,如下所示:

训练与
的目标函数可以定义为:

实验结果:
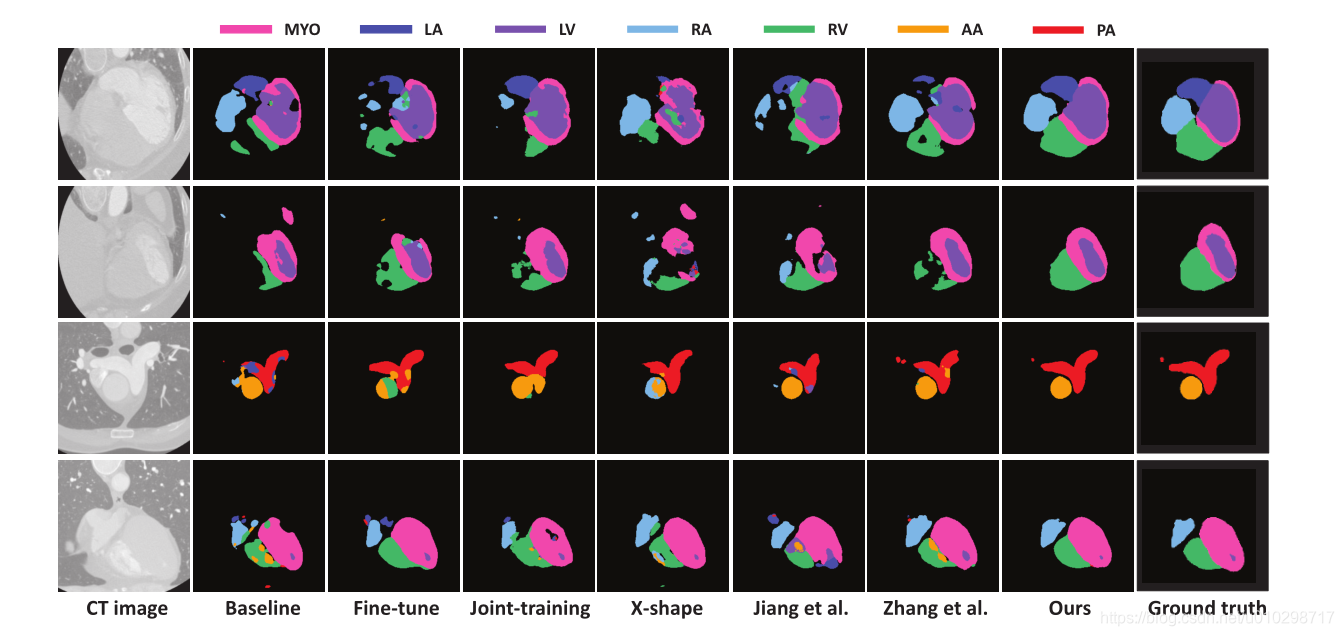
如下图所示:不同方法分割结果的可视化比较,心脏下层结构的图示在顶部。正如我们所看到的,我们的结果(第二列最后一列)比其他人更接近地面真相(最后一列)。
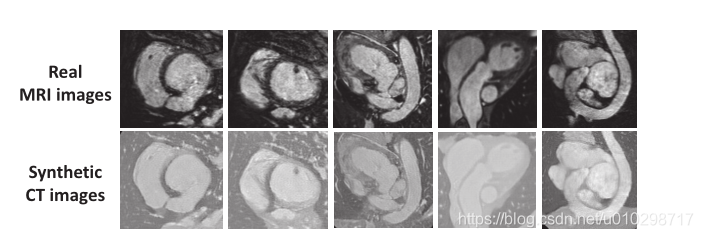
如下图所示:图像对齐模块生成的结果,其中MRI结构在合成CT图像中保存良好,边缘清晰。
如下图所示,分别是,
与集成分割器分割结果的可视化比较,从图中可以看出,集成分割器可以突出统一的预测,同时纠正误导的预测。
结论:
本文提出了一种新的多模图像分割框架,以证明利用辅助模先验知识提高目标模图像分割性能的有效性。具体来说,本文首先设计了一个图像对齐模块,通过对抗性学习生成合成的目标模态图像来减少外观差异(例如,实现MRI到CT的转换)。更重要的是,我们提出了互知识精馏方案,通过显式学习一种模态知识的分割注释和隐式探索另一种模态知识,以全面开发模态共享知识。在公共多模心脏分割数据集上的实验结果验证了我们的方法的有效性,并证明了与其他先进方法的优越性能。














 2011
2011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









