







一、前言
在这个博客中,我们正在对数据集是否进行假设检验,并试图证明该假设是否正确。 我们也在做一些数据清理技术、数据可视化和假设检验。在之前的博客中我们已经介绍了气象数据的基本处理。
二、相关库的引入
Numpy
Pandas
Matplotlib
Seaborn三、代码实现
假设是在监督机器学习中最能描述目标的函数。 用简单的语言来说,我们创建一个函数并尝试我们的输入和目标,如果匹配则我们的假设被接受,否则它被拒绝。
该项目的假设:零假设 H0 是“表观温度和湿度在 10 年的数据中每月比较表明由于全球变暖而增加”
表观温度:表观温度是由气温、相对湿度和风速的综合影响引起的人类感知的等效温度。 该措施最常用于感知室外温度。
湿度:湿度是空气中水蒸气的量。 如果空气中有很多水蒸气,湿度就会很高
3.1 数据介绍
该数据集记录了从 2006–04–01 00:00:00.000 +0200 到 2016–09–09 23:00:00.000 +0200 的过去 10 年的每小时温度。 对应北欧国家芬兰。 您可以从此下载数据集
数据样式如下:

如您所见,我们共有 10 个字段,例如摘要、降水类型、温度等。
我们只使用表观温度和湿度场,因为我们需要证明我们的假设。
检查空值:
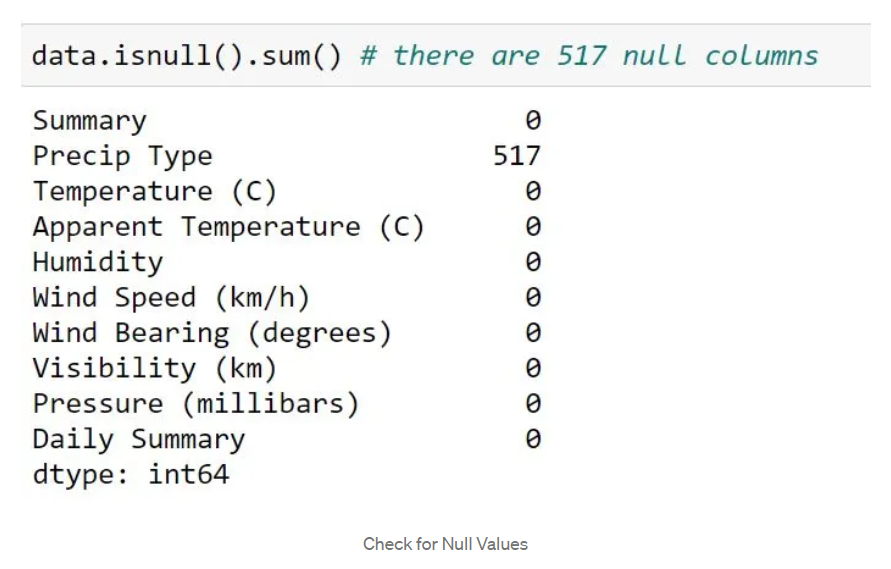
在这里我们可以看到总共有 517 个空值。
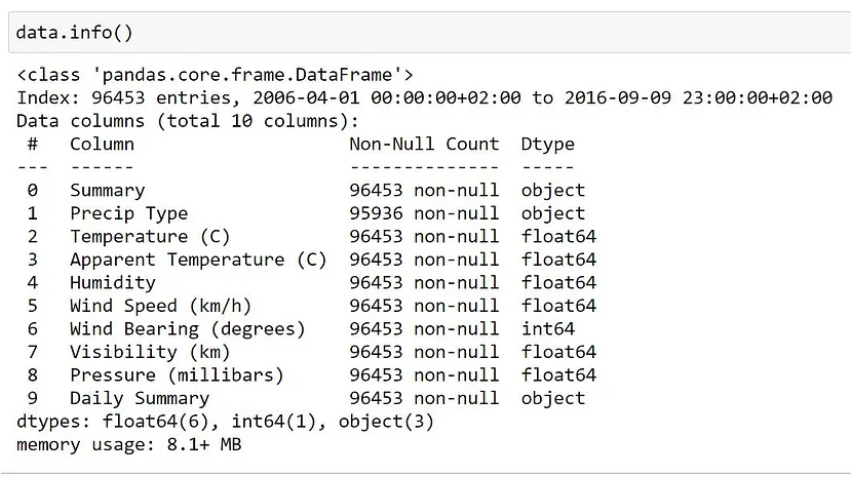
数据集中共有 96453 行。 其中只有 514 行包含空值,因此我们可以简单地删除那些包含空值的行。
new_data = data.dropna() # remove rows which contained null value3.2 数据重采样
在这个例子中,我们可以通过两种方法对数据进行重采样。
使用 Pandas 的 Resample 函数
手动创建函数
这两种方法最终都会使我们得到相同的结果。 我刚刚发布了使用该函数手动重新采样的代码。
在这个函数中,new_data 还有两个额外的列 year 和 month,我们也将为第一种方法创建它们。
def find_average_monthly_AT_or_Humidity(what_for):
avg_data_tempreature_monthly = {}
for year in range(2006,2017):
for month in range(1,13):
result = list(new_data.loc[(new_data['month'] == month)&(new_data['year']==year) , :][what_for].values)
if month not in avg_data_tempreature_monthly:
avg_data_tempreature_monthly[month] = [np.mean(result)]
else:
avg_data_tempreature_monthly[month].append(np.mean(result))
return avg_data_tempreature_monthly所以上面的这个函数返回一个字典,其中键作为月份,值作为特定月份过去 10 年平均值的列表。
pandas重采样功能:
resampled_data = new_data.resample('M').mean()
# resample accroading to Month end ('M')上述函数通过对其上的值进行平均将每小时数据转换为每月数据。“M”称为 DateOffset。 这意味着月底。

现在我们已经根据月份对数据进行了重新采样。 正如您在格式化日期索引中看到的那样。 第一个值是 2005 年 12 月 31 日,之后是 2006 年 1 月 1 日,依此类推。
出于分析目的,我们还创建了两个额外的列。 年和月。
resampled_data['month'] = resampled_data.index.month
resampled_data['year'] = resampled_data.index.year我们分析所有 12 个月的表观温度的月度数据。
在这里,我只展示四月和六月。
3.3 数据可视化
(1)对于四月
我们创建了两个 DataFrame AT(表观温度)和 H(湿度),它们的值仅基于 2006-2016 年。
两个数据框都有一个额外的列。 年
湿度条形图(仅适用于四月):
sns.barplot(H['year'] , H[4])
plt.title('Humidity For April Month')
plt.show()
我们可以看到 2006-2016 年的平均湿度相同。 我们有 2006 年的最大湿度和 2007 年的最小湿度。
表观温度条形图(仅适用于四月):
sns.barplot(AT['year'] , AT[4])
plt.title('Apparent Temperature For April Month')
plt.show()
我们可以看到 2015 年的一些不确定性,我们的 AT 最低且几乎等于最低湿度。 之后我们可以看到 2009 年的不确定性,我们有最大 AT 但没有最小湿度。
湿度和表观温度是相反的建议。
四月份的最终图表
AT_monthly_average 和 Humidity_monthly_average 是两个字典,其中包含 2006-2016 年的月度数据。 两个词典都有作为月份索引的键(比如四月索引是 4)。
plt.plot(range(2006,2017),AT_monthly_average[4] , label = 'Apparent Temperature(C)' , color = 'red')
plt.plot(range(2006,2017),Humidity_monthly_average[4] , label = 'Humidity')
plt.legend()
plt.title('Apparent Temperature vs Humidity for April Month')
plt.show()
由此可见,2009年的表观温度最高,然后又出现波动。 在 2015 年,它变得最低,然后再次增加。 所以我们可以明确地说,在过去的 10 年里,由于全球变暖的加剧,表观温度是不确定的。
(2)对于六月
大约每个月,我们都会看到过去 10 年温度数据的一些不确定性。
作为另一个例子,我们现在可以看到 6 月份的数据和图表。(所有代码与上面解释的相同。)
湿度条形图(仅适用于六月):

六月的平均湿度也相同。 我们可以看到 2010 年的最大湿度和 2014 年的最小湿度。
表观温度条形图(仅适用于 6 月):

正如我们上面提到的,我们在图中看到了不确定性。 例如,对于 2010 年,我们有最高的 AT 但不是最低的湿度。 根据图表,我们可以看到 2006 年和 2009 年的最低 AT,但不是那几年的最高湿度。
六月份的最终图表:

2008 年的表观温度较低,此后逐渐上升,2012 年达到最大值,之后再次下降。 因此,由于全球变暖,我们可以清楚地看到 6 月份的不确定性。
四、结论
在这 10 年的数据集中,我们可以看到每年增加表观温度和湿度是不相关的。 全年月平均湿度相同,但表观温度不同。 全球变暖正在影响地球的温度,因此我们在这些数据中看到了一些不确定性。
















 1970
1970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











