









转自:
http://blog.csdn.net/dudubird90/article/details/49759431
k-means算法对于数据点和clusters之间的关系,是all-or-nothing的关系,这是一个hard decision,往往会导致的局部最小值,这不是理想的求解。一种常见的做法,是学习这个协方差矩阵,而不是固定它们为单位矩阵。
GMM模型及算法流程
GMM的全称是Gaussian Mixture Model,即高斯混合模型。
假设我们有一个训练集
{x1,...,xm}
,在非监督学习中,这些数据都是没有标签的。我们希望可以对数据进行建模,通过定义一个联合分布
p(x(i),z(i))=p(x(i)|z(i))p(z(i))
,这里
z(i)∼Multinomial(ϕ)
,其中
ϕj≥0,∑kj=1ϕj=1
, 这个参数
ϕj
代表着
p(z(i)=j)
的概率。
而
xi|zi=j∼(μj,Σj)
,k代表着标签
z(i)
可以有的取值的数目。所以我们的模型实际上是当
z(i)
从
{1,...,k}
随机取值时,从k个高斯分量中选一个,再根据相应的
z(i)
生成对应的
x(i)
。
z(i)
是一个隐变量,就是说它是隐藏的,不可见的。
我们的似然函数可以这样写:
如果直接通过令偏导数为0,对其进行求解是无法得到closed form的。
这个隐变量告诉了我们,数据
x(i)
是从k个高斯分量中的哪一个来的。如果我们一开始就知道是哪个,那么最大似然问题是很简单的。具体而言,我们就可以将似然函数展开:
随后分别对 ϕ , μ , Σ 求导,可以得到:
当我们知道类别信息,事实上这就是一个高斯判别分析的参数估计问题。但是我们知道,所以我们可以分两个步骤:
一个步骤猜测这个 zi 的值,也就是E-step;
一个步骤利用已知的类别信息来估计高斯的参数 μ,Σ ,以及各个高斯分量的权重 ϕj 。
那么这个标签值要如何猜测呢? 我们可以在固定参数 ϕ,μ,Σ 的情况下,在给定数据 x(i) 时 z(i) 后验概率的来判定,再结合贝叶斯定律:
EM算法在k-means 聚类中也有用到,但是用的是hard decision, 而利用GMM,我们使用的其实是soft的 assignments w(i)j . 同样它也可能会收敛到局部极小值,所以需要尝试不同的初始参数。
用GMM来进行聚类,K个高斯component实际上就对应着K个cluster,我们根据数据来推算概率密度density estimation。
利用Mixtures of Gaussians模型来实现聚类算法的流程总结如下:
输入:
{x(i)}mi=1
(数据), k(聚类的数目)
初始化:
∀μi←1k
Σi←var({x(i)})
Repeat until convergence :
E-step:
M-step:
输出:
算法代码demo及关键步骤注解
大费苦心写了编辑了这么多公式,还没有进入正题。本文一大重点是要研读scikit包中gaussian mixture 部分的代码,已进一步熟悉算法和这个工具包。
官网给出的密度估计的源码可见:
http://scikit-learn.org/stable/auto_examples/mixture/plot_gmm_pdf.html#example-mixture-plot-gmm-pdf-py
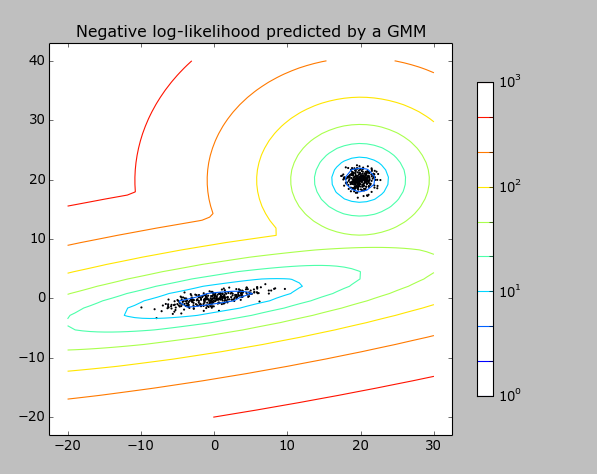
算法就是随机产生两个不同中心的高斯分布的数据点,再用mixture.GMM进行拟合。
关键部分代码拆分如下。
1. 准备数据
产生以20,20 为中心的满足标准正态分布的300个样本点。
- 1
- 1
产生原点处的stretch后高斯分布的300个样本点。通过乘以一个矩阵来完成。
- 1
- 2
- 1
- 2
叠加两部分数据:
- 1
- 1
训练数据是一个600*2的矩阵。
2. 初始化高斯混合模型
clf = mixture.GMM(n_components=2, covariance_type=’full’)
第二个参数这样设置,实际得到的协方差的参数 covars_是
(n_components, n_features, n_features)
这样允许了不同的高斯分量有不同的协方差矩阵。
初始化就做了这些事情:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
默认迭代的次数为100次
- 1
- 1
每个分量一开始赋值的权重是相同的,这里的例子中有两个分量,所以得到的是一个行向量[0.5,0.5].
密度估计
随后要做的事情,是生成模型。
调用方式为:
- 1
- 1
里面的关键步骤,就看Expection Step和Maximization Step。
Expection Step:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
第一个函数就是计算后验概率的函数,
其中作者对
表示成exp(log(.))的形式,于是把除法就转换成了减法。
下面这一步是计算分子。相当于计算 log(p(x(i)|z(i)=j;μ,Σ))+log(p(z(i)=j;ϕ))
- 1
- 2
- 3
- 1
- 2
- 3
上面得到的矩阵为600*2,一列对应着一个高斯分量。下面这一步是计算分母,先用exp得到原值,再求和,随后再取log相当于计算
log∑kl=1p(x(i)|z(i)=j;μ,Σ)p(z(i)=j;ϕ)
万分精简的只用了一个函数就完成了:
- 1
- 1
计算结果减法完成:
- 1
- 1
函数的返回值中,
responsibilities : array_like, shape (n_samples, n_components)
Posterior probabilities of each mixture component for each
observation
而curr_log_likelihood则是分母的值,作者通过记录这个值所有600个样本的和在每一次迭代中的变化来与阈值self.thresh比较来判断是否达到了收敛。
Maximization step
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
前面已经说了:
ϕj
代表着
p(z(i)=j)
的概率,之类对应着weights_, 每个分量的权重。
计算的方法是
也等于600个样本的分量1的后验概率和/(600个样本的分量1的后验概率和+600个样本的分量2的后验概率和)。
- 1
- 2
- 3
- 1
- 2
- 3
注意每一行两个分量的权重求和为1,600个全部加起来为600,正好等于左右两列归总值的和。所以这么计算也是对的。
更新均值:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
更新协方差矩阵:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
这里实际调用的函数为:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
具体可见参考文献2的公式12. 其实我看参考文献2脱离上下文不怎么容易懂,基本上应该说这是协方差矩阵的另一种写法。https://en.wikipedia.org/wiki/Covariance_matrix
Σ=E[(X−EX)(X−EX)T]=E(XXT)−μμT
所以上面的公式就进一步写成:
下一次再来梳理关键步骤的推导吧,最后的结果是好看的。
参考文献:
1. andrew ng cs229 handouts
http://cs229.stanford.edu/notes/cs229-notes7b.pdf
2. K. Murphy, “Fitting a Conditional Linear Gaussian Distribution”
http://www.cs.ubc.ca/~murphyk/Papers/learncg.pdf















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









