







一直想写个关于语音识别系统原理的博文。前段时间我和@零落一起做了很多实验,比如htk,kaldi等。从周五开始就已经放寒假了,明天就做火车回家了。今晚加点劲写点吧,回家由于没网。大家有问题只能留言或者找我qq,我尽量过段时间来回答吧。现在我就把语音识别的原理说下去。
具体的框架图还是来一个把。这个图我也是我从网上找的。
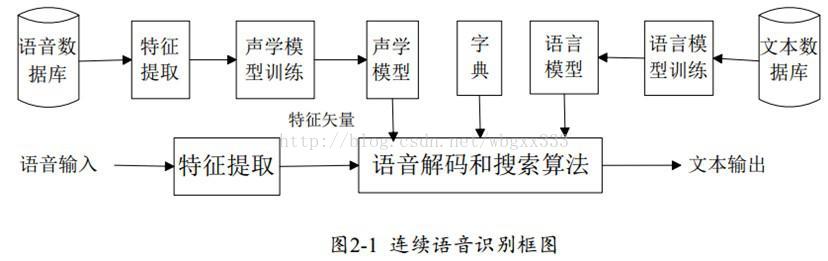
按照上图的说法,语音识别是由语言模型和声学模型构成的。下面我就根据图上的流程说下。
一 特征提取
现在主流的特征是mfcc。具体mfcc的步骤,在我前面转的博客里也有。地址:语音信号处理之(四)梅尔频率倒谱系数(MFCC)。这里我引有知乎里的一个人的说法:
首先说一下作为输入的时域波形。我们知道声音实际上是一种波。常见的mp3、wmv等格式都是压缩格式,必须转成非压缩的纯波形文件,比如Windows PCM文件,即wav文件来处理。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。采样率越大,每毫秒语音中包含的点的个数就越多。另外声音有单通道双通道之分,还有四通道的等等。对语音识别任务来说,单通道就足够了,多了浪费,因此一般要把声音
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









