







一、决策树
在1986年,机器学习研究者J.Ross Quinlan 开发了决策树算法,称为ID3(Iterative Dichotomiser,迭代的二分器)。这项工作扩展了E.B.Hunt,J.Marin 和P.T.Stone 的概念学习系统。Quinlan 后来提出了C4.5、C5.0算法。与ID3发明几乎同时,1984年统计学家L.Breiman,J.Friedman,R.Olshen 和C.Stone 出版了分类与回归树(CART),介绍了二叉决策树的产生。这两个基础算法激发了决策树归纳研究的旋风。
1.1 决策树概念
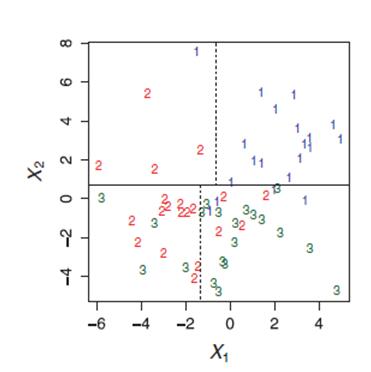
决策树模型是一种对实例进行分类或者回归的树型结构。决策树由结点和有向边组成,结点有两种类型:内部结点和叶结点,内部结点表示一个特征,叶结点表示一种类别或者目标值。

决策树包括分类决策树和回归决策树,分类决策树叶结点对应于一个类别,回归决策树叶结点对应一个连续值。决策树的思想是空间划分:用递归的方式把关于自变量的m维特征空间划分成不重叠的空间。
1.2 决策树学习目的
决策树学习的目的是根据给定的训练数据集,学习到一个决策树模型,使它能够对决策树进行正确的分类。决策树学习的本质上是从训练数据集中归纳出一组分类规则。与训练数据集不相矛盾的树可能有多颗,也可能一颗都没有。我们需要的是一颗与训练数据集矛盾较小的树,同时有很好的泛化能力。即:不仅对训练数据有很好的拟合,同时能对未知类型数据很好的预测。
二、ID3 算法
ID3 算法是较早提出的一种算法。之后在它基础上进行改进提出了C4.5,C5.0。它们都属于多分支决策树,与此同时还有一种二分支决策树CART,在生成决策树的其他细节上也有所不同。本文先介绍ID3,之后再介绍CART,最后比较它们的异同。
决策树的学习算法是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。以上的方法构造的决策树可能对训练数据有较好的分类能力,但对未知的测试数据却未必有很好的分类能力,即有可能发生过拟合。我们需要对已生成的树自下而上的进行剪枝,使它具备很好的泛化能力。
由以上可以看到,ID3 决策树学习算法包括几个关键的元素:特征选择、决策树的构造、决策树的剪枝。
2.1 特征选择
特征选择在于选取对训练数据具有分类能力的特征,这样可以提高决策树的学习效率。ID3进行特征选择使用的规则是信息增益。
2.1.1 信息增益
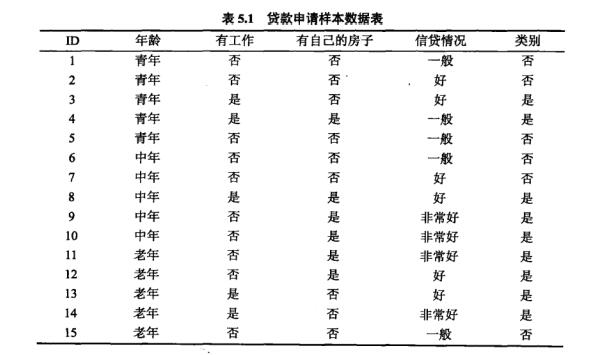
对于这个训练数据,我们选择哪个特征来划分特征空间呢?
如果一个特征将训练数据划分为各个子集,使得各个子集在当前有一个最好的分类,那么就应该选择这个特征。信息增益能够很好表示这样一个规则。
信息增益:对于训练数据集D和特征A,经验熵H(D)表示对数据集D进行分类的不确定性;经验条件熵表示H(D|A)表示在特征A给定的条件下对数据集D进行分类的不确定性。那么H(D)与H(D|A)的差即是信息增益g(D,A)。它表示由于特征A使得对数据集D的分类不确定性减少的程度。
这里熵的定义是:随机变量不确定性的度量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3475
3475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









