







支持向量机在1992年被正式发表,最开始时研究线性可分支持向量机,与它相似的算法是感知机,感知机学习的策略是误分类点最少;而线性支持向量机的学习策略是间隔最大化。之后相继引入了惩罚因子和核函数的概念,能够处理线性支持向量机和非线性支持向量机。
所以整体的逻辑是分别理清三类支持向量机的关系,能够明白最终都是转化为求解凸二次规划问题;那么我们通过序列最小最优化算法SMO求解这个问题即可。那么具体逐一介绍以下内容:
支持向量机三类模型
- 线性可分支持向量机 : 当训练数据线性可分时,可通过硬间隔最大化学习一个线性分类器
- 线性支持向量机 : 当训练数据近似线性可分时,可通过软间隔最大化学习一个线性的分类器
- 非线性支持向量机: 当训练数据线性不可分时,可通过软间隔最大化与核技巧来学习一个非线性分类器
- 序列最小最优化算法SMO:求解凸二次规划的最优化算法
- 核技巧[扩展]
- 惩罚因子[扩展]
- 支持向量机的代码实现
1、线性可分支持向量机
对于给定特征空间上的训练数据集
T={(x1,y1),(x2,y2),⋯,(xn,yn)}
,其中
xi∈Rn,yi∈{+1,−1},i=1,2,⋯,N,
学习的目的是在特征空间上找到一个分离超平面,能够将实例分到不同的类。分离超平面对应于方程
w⋅x+b=0
;学习的策略是间隔最大化,即得到将两类数据正确划分且间隔最大的直线。
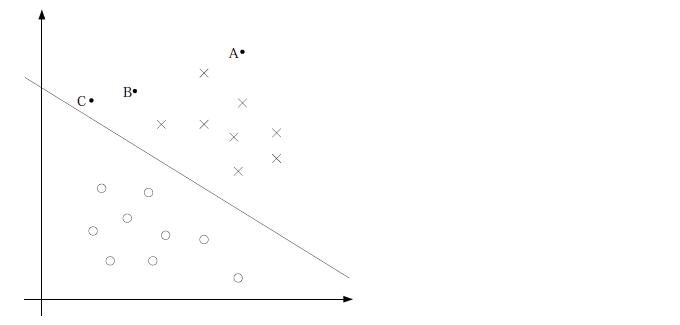
1.1 函数间隔
从图中我们可以确定A是×类别的,B还算能够确定,然而C是不太确定的。可见一个点距离分离超平面的远近可以表示分类预测的确信程度,一个点距离分类超平面越远,那么它被预测正确地概率越大;在超平面 w⋅x+b=0 确定的情况下, |w⋅x+b| 能够表示点x距离超平面的远近;而 w⋅x+b 的符号与类标记y的符号是否一致能够表示分类是否正确,所以可以用 y(w⋅x+b) 表示分类的正确性与确信度。所以我们定义函数间隔如下:
- 关于训练数据集T中样本点 (xi,yi) 的函数间隔是 r^i=yi(w⋅xi+b)
- 关于训练数据集T的函数间隔是 r^=min r^i
函数间隔虽然可以表示分类的正确性和确信度,但对于一个确定的超平面 w⋅x+b=0 ,同时同比例增大 w,b ,超平面没有改变,但函数间隔却变大了。所以我们若希望间隔不发生改变,通常是对w加以约束。
几何间隔
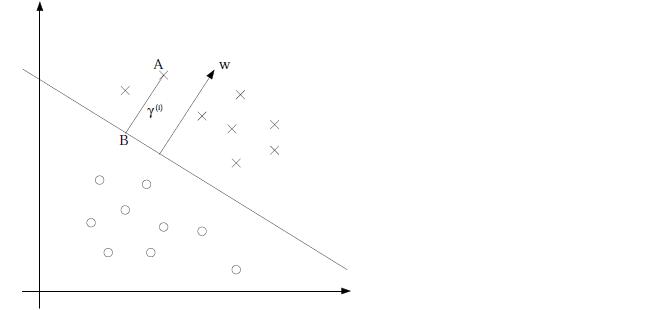
假设我们已知分离超平面
w⋅x+b=0
,
A(xi,yi)
到该面的距离
ri
,B为A在分离超平面的投影,且BA的方向为
w
(法向量),单位向量为
我们发现函数间隔约束之后恰好是几何间隔,之所以一样,是因为函数间隔是人为定义的,里面已经潜藏了几何间隔的元素。此时,若同时扩大w和b,w扩大几倍,||w||就扩大几倍,几何间隔无影响。于是有:
- 关于训练数据集T中样本点 (xi,yi) 的几何间隔是 ri=yi(w⋅xi+b)||w||
- 关于训练数据集T的几何间隔是 r=min ri
间隔最大化
我们已经知道了几何间隔,间隔最大化即是对训练集找到几何间隔最大的超平面。它意味着不仅将正负实例分开,而且对最难分的实例点(距离超平面最近的实例点)也能以足够大的确信度将它们分开。这样的超平面应该对未知实例有很好的预测能力。
则最大化几何间隔可以表示成这样的最优化问题:
由函数间隔 r 与
因为对于一个可分数据集,一定能有无穷多各超平面去实现它的分割,也就是对应不同的w,b。但无论是哪一组w,b,同比例扩大或缩小都可以使函数间隔 r^=min yi(w⋅xi+b) 变为一个常数。也即是说函数间隔 r^ 不影响最优问题的解。于是我们便于计算,可以取 r^=1 。且最大化 1||w|| 等价于 最小化 12||w||2 (系数 12 只是为了求导方便)。于是有:
这是一个凸二次规划问题。如果求解了该问题的解 w,b ,则可以得到最大间隔分离超平面 w⋅x+b=0 ,也即得到了分类决策函数 f(x)=sign(w⋅x+b) 。这就是线性可分支持向量机模型。
凸二次规划问题可以通过优化软件来进行求解,但往往效率低下,下一节内容我们介绍一种手工求解的方法。















 2837
2837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









