







简介
- 定义:
- NebulaGraph 是一款开源的分布式图数据库,旨在处理大规模的图数据,为高并发、低延迟的图数据存储和查询提供强大的支持。它适用于各种复杂的关系分析场景,如社交网络分析、推荐系统、知识图谱构建、金融风控等。
- 核心特点:
- 高可用性:通过分布式架构和数据副本机制,确保系统在部分节点故障时仍能正常运行,保障服务的可用性。
- 高性能:采用存储计算分离的架构,利用高效的图算法和索引技术,能够快速执行复杂的图查询操作。
- 可扩展性:支持水平扩展,可以根据数据量和负载需求,轻松添加新的存储节点和计算节点,以满足业务增长。
数据模型
- 图空间(Space):
- 类似于关系数据库中的数据库,是存储图数据的逻辑单元,不同的图空间可以存储不同的图数据,相互隔离。例如,你可以创建一个图空间存储社交网络数据,另一个存储物流网络数据。
- 示例:CREATE SPACE my_space(partition_num=10, replica_factor=1);
- 顶点(Vertex)和标签(Tag):
- 顶点表示图中的实体,而标签是对顶点的分类。一个顶点可以有多个标签。例如,在社交网络中,用户可以是一个顶点,“用户” 就是一个标签,可能还有 “VIP 用户” 这样的标签,用来区分不同类型的用户。
- 边(Edge)和边类型(Edge Type):
- 边表示顶点之间的关系,边类型则定义了边的类别。例如,在社交网络中,“关注” 可以是一个边类型,连接不同用户顶点。
-- 查看用户
SHOW users;
-- 创建图空间
CREATE SPACE IF NOT EXISTS my_space (vid_type=FIXED_STRING(30));
USE my_space;
-- 创建标签 (Tag)
CREATE TAG IF NOT EXISTS player(name string, age int);
-- 创建边类型 (Edge Type)
CREATE EDGE friend(likeness double);
-- 插入顶点 (Vertex)
INSERT VERTEX person(name, age) VALUES "person1":("Alice", 25), "person2":("Bob", 30);
-- 插入边 (Edge)
INSERT EDGE friend(likeness) VALUES "person1"->"person2":(0.8);
-- nebula-console导入测试语句
【免费】basketballplayer-2.X.ngql,nebula-console测试语句资源-CSDN文库
nebula-console -addr 192.168.1.215 -port 9669 -u root -p 123456 -f /opt/basketballplayer-2.X.ngql

-- 查询语法
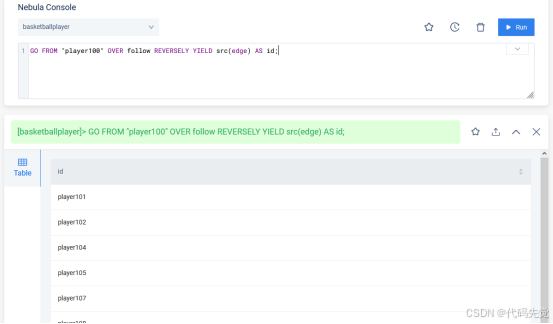
GO FROM "player100" OVER follow REVERSELY YIELD src(edge) AS id;
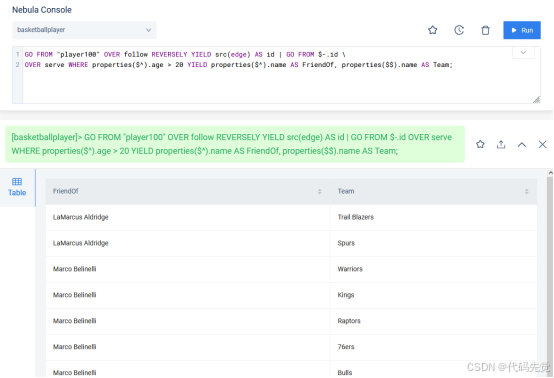
GO FROM "player100" OVER follow REVERSELY YIELD src(edge) AS id | GO FROM $-.id \ OVER serve WHERE properties($^).age > 20 YIELD properties($^).name AS FriendOf, properties($$).name AS Team;
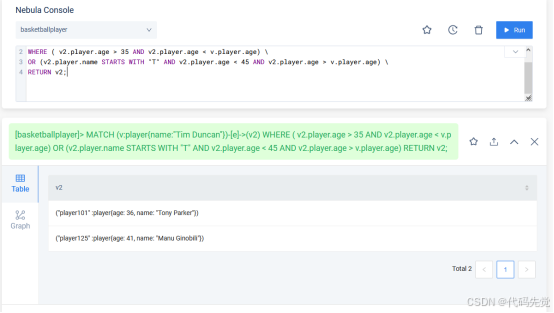
MATCH (v:player{name:"Tim Duncan"})-[e]->(v2) \
WHERE ( v2.player.age > 35 AND v2.player.age < v.player.age) \
OR (v2.player.name STARTS WITH "T" AND v2.player.age < 45 AND v2.player.age > v.player.age) \
RETURN v2;
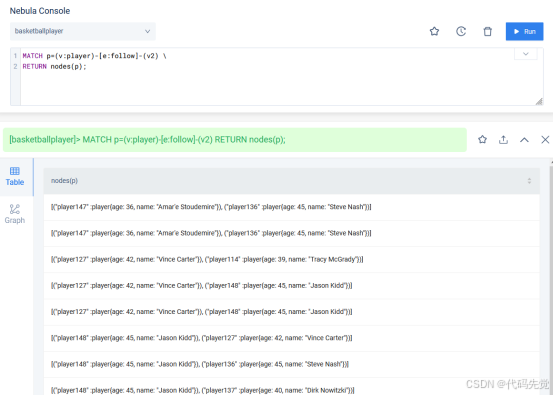
MATCH p=(v:player)-[e:follow]-(v2) \
RETURN nodes(p);
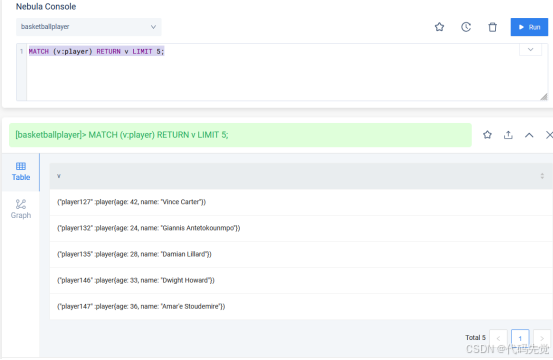
MATCH (v:player) RETURN v LIMIT 5;
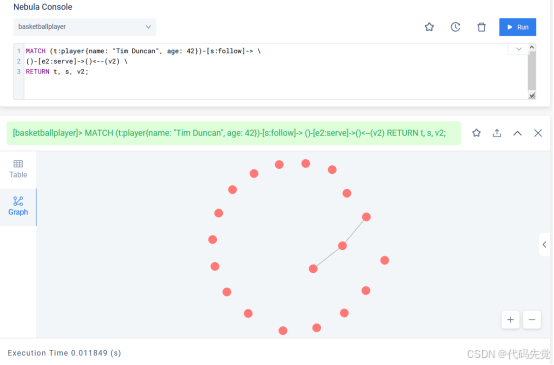
分行写 Pattern 时,在表示边的箭头右侧换行,而不是左侧。
MATCH (v:player{name: "Tim Duncan", age: 42})-[e:follow]-> \
()-[e2:serve]->()<--(v2) \
RETURN v, e, v2;
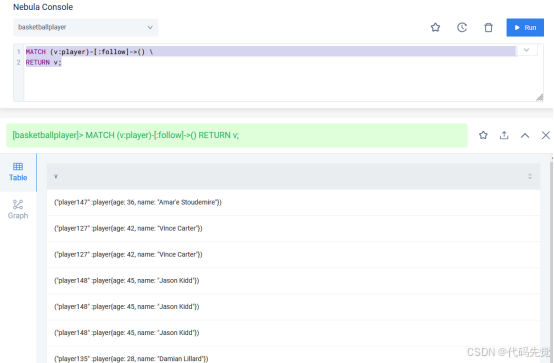
将无需查询的点和边匿名化。
MATCH (v:player)-[:follow]->() \
RETURN v;
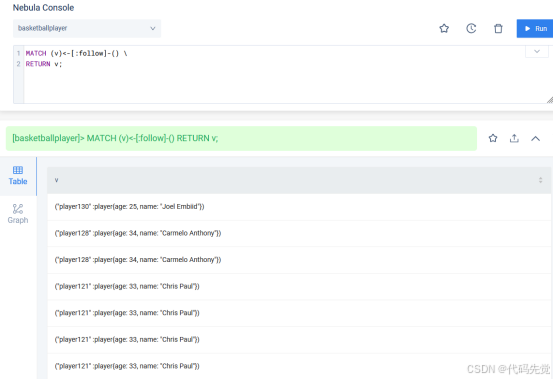
将非匿名点放在匿名点的前面。
MATCH (v)<-[:follow]-() \ RETURN v;
MATCH
MATCH语句提供基于模式(Pattern)匹配的搜索功能,其通过定义一个或多个模式,允许在 NebulaGraph 中查找与模式匹配的数据。在检索到匹配的数据后,用户可以使用 RETURN 子句将其作为结果返回。
MATCH <pattern> [<clause_1>] RETURN <output> [<clause_2>];
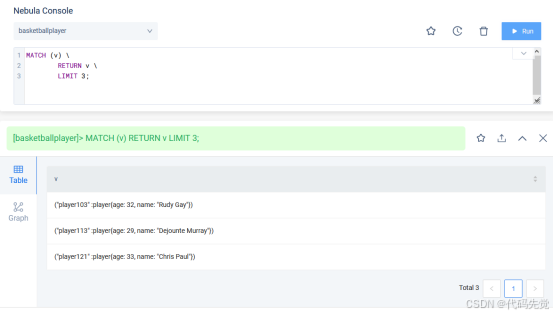
MATCH (v) \
RETURN v \
LIMIT 3;
OPTIONAL MATCH
OPTIONAL MATCH通常与MATCH语句一起使用,作为MATCH语句的可选项去匹配命中的模式,如果没有命中对应的模式,对应的列返回NULL。
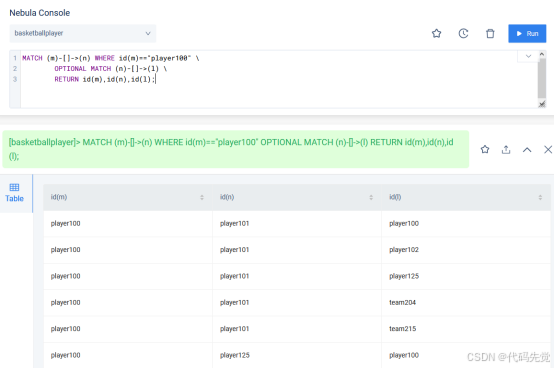
找出特定节点 m(ID为 "player100" 的节点)直接连接的节点,以及这些节点 n 直连的下一层节点 l (OPTIONAL MATCH (n)-[]->(l)), 如果没有找到这样的节点 l,查询也会继续, l 的返回值是 null。
MATCH (m)-[]->(n) WHERE id(m)=="player100" \
OPTIONAL MATCH (n)-[]->(l) \
RETURN id(m),id(n),id(l);
LOOKUP
LOOKUP根据索引遍历数据。用户可以使用LOOKUP实现如下功能:
根据WHERE子句搜索特定数据。
通过 Tag 列出点:检索指定 Tag 的所有点 ID。
通过 Edge type 列出边:检索指定 Edge type 的所有边的起始点、目的点和 rank。
统计包含指定 Tag 的点或属于指定 Edge type 的边的数量。
LOOKUP ON {<vertex_tag> | <edge_type>}
[WHERE <expression> [AND <expression> ...]]
YIELD [DISTINCT] <return_list> [AS <alias>]
[<clause>];
<return_list>
<prop_name> [AS <col_alias>] [, <prop_name> [AS <prop_alias>] ...];
检索点
# 创建 Tag 为 player 的复合属性索引 index_player。
nebula> CREATE TAG INDEX IF NOT EXISTS index_player ON player(name(30), age);
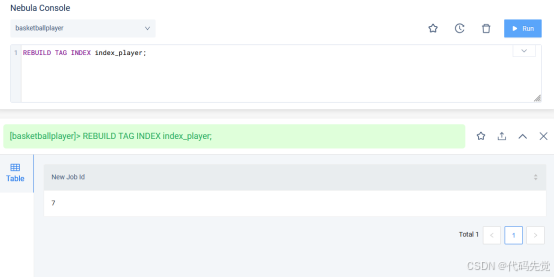
# 重建复合属性索引 index_player,返回任务 id。
nebula> REBUILD TAG INDEX index_player;
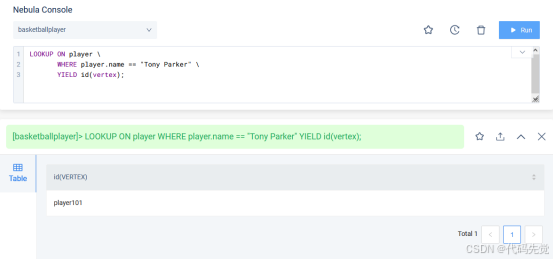
# 返回所有 name 等于 Tony Parker 的点数据的 ID。
nebula> LOOKUP ON player \
WHERE player.name == "Tony Parker" \
YIELD id(vertex);
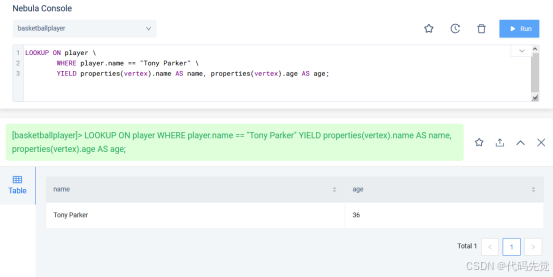
# 查询所有 name 等于 Tony Parker 的点数据,返回 name 和 age 属性值。
nebula> LOOKUP ON player \
WHERE player.name == "Tony Parker" \
YIELD properties(vertex).name AS name, properties(vertex).age AS age;
# 查询所有 age 大于 45 的点数据,并返回点数据的 ID。
nebula> LOOKUP ON player \
WHERE player.age > 45 \
YIELD id(vertex);
# 查询所有 name 以 B 开头,且 age 是 22 或 30 的点数据,并返回 name 和 age 属性值。
nebula> LOOKUP ON player \
WHERE player.name STARTS WITH "B" \
AND player.age IN [22,30] \
YIELD properties(vertex).name, properties(vertex).age;
# 查询所有 name 等于 Kobe Bryant 的点数据,返回点的 ID 和 name 属性值,并以此为起始点进行遍历,返回遍历结果。
nebula> LOOKUP ON player \
WHERE player.name == "Kobe Bryant"\
YIELD id(vertex) AS VertexID, properties(vertex).name AS name |\
GO FROM $-.VertexID OVER serve \
YIELD $-.name, properties(edge).start_year, properties(edge).end_year, properties($$).name;
检索边
# 创建 Edge type 为 follow,属性 degree 的索引 index_follow。
nebula> CREATE EDGE INDEX IF NOT EXISTS index_follow ON follow(degree);
# 重建属性索引 index_follow,返回任务 id。
nebula> REBUILD EDGE INDEX index_follow;
# 查询并返回所有 degree 等于 90 的边。
nebula> LOOKUP ON follow \
WHERE follow.degree == 90 YIELD edge AS e;
...
# 查询所有 degree 等于 90 的边,并返回 degree 属性值。
nebula> LOOKUP ON follow \
WHERE follow.degree == 90 \
YIELD properties(edge).degree;
# 根据 degree 属性值升序排列,并返回前 10 条 degree 属性值。
nebula> LOOKUP ON follow \
YIELD properties(edge).degree as degree \
| ORDER BY $-.degree \
| LIMIT 10;
# 查询所有 degree 等于 60 的边,返回边的目的点 ID 和边的 degree 属性值,并为此起始点进行遍历,返回遍历结果。
nebula> LOOKUP ON follow \
WHERE follow.degree == 60 \
YIELD dst(edge) AS DstVID, properties(edge).degree AS Degree |\
GO FROM $-.DstVID OVER serve \
YIELD $-.DstVID, properties(edge).start_year, properties(edge).end_year, properties($$).name;
GO
GO语句是 NebulaGraph 图数据库中用于从给定起始点开始遍历图的语句。GO语句采用的路径类型是walk,即遍历时点和边都可以重复。
语法
GO [[<M> TO] <N> {STEP|STEPS} ] FROM <vertex_list>
OVER <edge_type_list> [{REVERSELY | BIDIRECT}]
[ WHERE <conditions> ]
YIELD [DISTINCT] <return_list>
[{ SAMPLE <sample_list> | <limit_by_list_clause> }]
[| GROUP BY {<col_name> | <expression> | <position>} YIELD <col_name>]
[| ORDER BY <expression> [{ASC | DESC}]]
[| LIMIT [<offset>,] <number_rows>];
<vertex_list> ::=
<vid> [, <vid> ...]
<edge_type_list> ::=
<edge_type> [, <edge_type> ...]
| *
<return_list> ::=
<col_name> [AS <col_alias>] [, <col_name> [AS <col_alias>] ...]
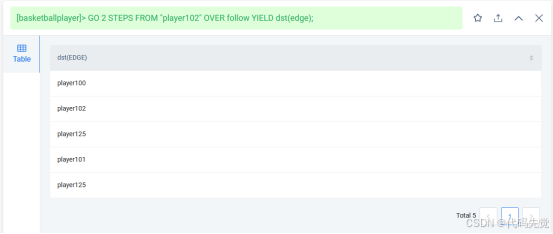
GO 2 STEPS FROM "player102" OVER follow YIELD dst(edge);
FETCH
FETCH可以获取指定点或边的属性值。
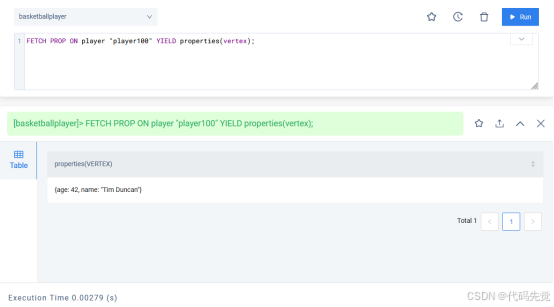
FETCH PROP ON {<tag_name>[, tag_name ...] | *} <vid> [, vid ...] YIELD [DISTINCT] <return_list> [AS <alias>];
FETCH PROP ON player "player100" YIELD properties(vertex);
FIND PATH
FIND PATH语句查找指定起始点和目的点之间的路径。
FIND { SHORTEST | ALL | NOLOOP } PATH [WITH PROP] FROM <vertex_id_list> TO <vertex_id_list> OVER <edge_type_list> [REVERSELY | BIDIRECT] [<WHERE clause>] [UPTO <N> {STEP|STEPS}] YIELD path as <alias> [| ORDER BY $-.path] [| LIMIT <M>]; <vertex_id_list> ::= [vertex_id [, vertex_id] ...]
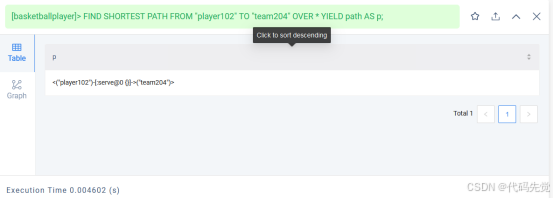
# 查找并返回 player102 到 team204 的最短路径。
nebula> FIND SHORTEST PATH FROM "player102" TO "team204" OVER * YIELD path AS p;
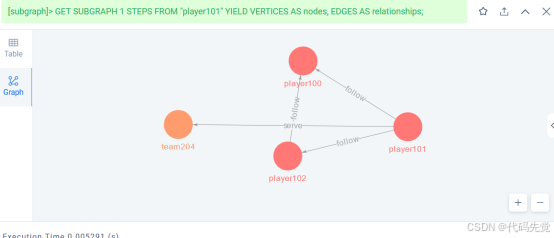
GET SUBGRAPH
GET SUBGRAPH语句查询并返回一个通过从指定点出发对图进行游走而生成的子图。在GET SUBGRAPH语句中,用户可以指定游走的步数以及游走所经过的边的类型或方向。
GET SUBGRAPH [WITH PROP] [<step_count> {STEP|STEPS}] FROM {<vid>, <vid>...} [{IN | OUT | BOTH} <edge_type>, <edge_type>...] [WHERE <expression> [AND <expression> ...]] YIELD [VERTICES AS <vertex_alias>] [, EDGES AS <edge_alias>];
nebula> CREATE SPACE IF NOT EXISTS subgraph(partition_num=15, replica_factor=1, vid_type=fixed_string(30));
nebula> USE subgraph;
nebula> CREATE TAG IF NOT EXISTS player(name string, age int);
nebula> CREATE TAG IF NOT EXISTS team(name string);
nebula> CREATE EDGE IF NOT EXISTS follow(degree int);
nebula> CREATE EDGE IF NOT EXISTS serve(start_year int, end_year int);
nebula> INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42);
nebula> INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36);
nebula> INSERT VERTEX player(name, age) VALUES "player102":("LaMarcus Aldridge", 33);
nebula> INSERT VERTEX team(name) VALUES "team203":("Trail Blazers"), "team204":("Spurs");
nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95);
nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player102":(90);
nebula> INSERT EDGE follow(degree) VALUES "player102" -> "player100":(75);
nebula> INSERT EDGE serve(start_year, end_year) VALUES "player101" -> "team204":(1999, 2018),"player102" -> "team203":(2006, 2015);
查询从点player101开始、0~1 跳、所有 Edge type 的子图。
nebula> GET SUBGRAPH 1 STEPS FROM "player101" YIELD VERTICES AS nodes, EDGES AS relationships;


















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











