







文章目录
本项目需要在 GPU 环境下运行,点击本页面最右边
< 进行切换
SRGAN超分辨模型
随着生成对抗网络GAN的发展,生成器和判别器的对抗学习机制在图像生成任务中展现出很强大的学习能力。Twitter的研究者们使用ResNet作为生成器结构,使用VGG作为判别器结构,提出了SRGAN模型,这是本次实践课使用的模型,其结构示意图如下:
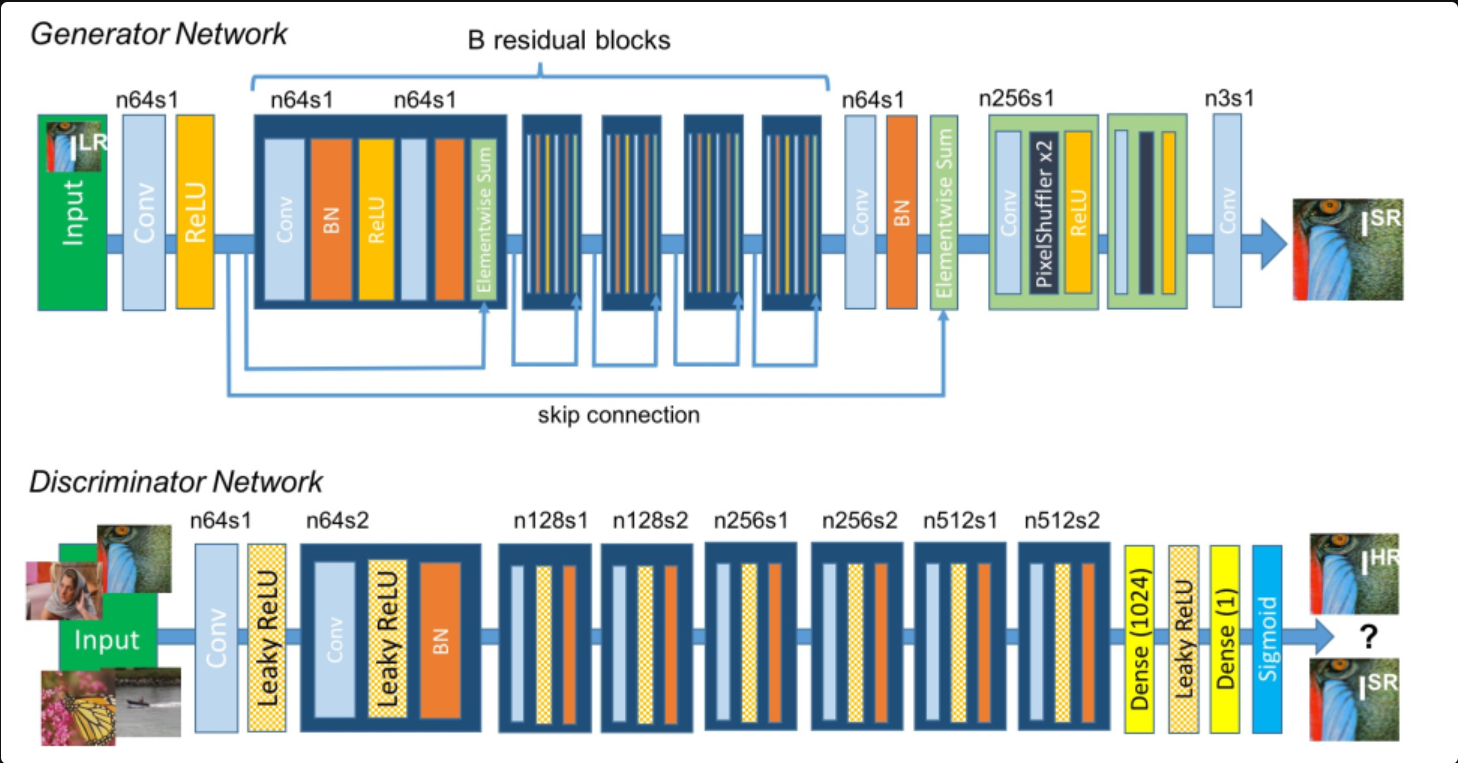
生成器结构包含了若干个不改变特征分辨率的残差模块和多个基于亚像素卷积的后上采样模块。
判别器结构则包含了若干个通道数不断增加的卷积层,每次特征通道数增加一倍时,特征分辨率降低为原来的一半。
SRGAN模型的损失函数包括两部分,内容损失与对抗损失。
l S R = l X S R ⏟ content loss + 1 0 − 3 l G e n S R ⏟ adversarial loss ⏟ perceptual loss (for VGG based content losses) l^{S R}=\underbrace{\underbrace{l_{\mathrm{X}}^{S R}}_{\text {content loss }}+\underbrace{10^{-3} l_{G e n}^{S R}}_{\text {adversarial loss }}}_{\text {perceptual loss (for VGG based content losses) }} lSR=perceptual loss (for VGG based content losses) content loss lXSR+adversarial loss 10−3lGenSR
对抗损失就是标准的GAN损失,而内容损失则是基于VGG网络特征构建,它代替了之前SRCNN使用的MSE损失函数,如下:
ℓ feat ϕ , j ( y ^ , y ) = 1 C j H j W j ∥ ϕ j ( y ^ ) − ϕ j ( y ) ∥ 2 2 \ell_{\text {feat }}^{\phi, j}(\hat{y}, y)=\frac{1}{C_{j} H_{j} W_{j}}\left\|\phi_{j}(\hat{y})-\phi_{j}(y)\right\|_{2}^{2} ℓfeat ϕ,j(y^,y)=CjHjWj1∥ϕj(y^)−ϕj(y)∥22
SRGAN通过生成器和判别器的对抗学习取得了视觉感知上更好的重建结果。不过基于GAN的模型虽然可以取得好的超分结果,但是也往往容易放大噪声。
SRGAN模型训练与测试
1. 项目解读
下面我们首先来剖析整个项目的代码。
1.1 数据集和基准模型
首先我们来介绍使用的数据集和基准模型,大多数超分重建任务的数据集都是通过从高分辨率图像进行降采样获得,这里我们也采用这样的方案。数据集既可以选择ImageNet这样包含上百万图像的大型数据集,也可以选择模式足够丰富的小数据集,这里我们选择一个垂直领域的高清人脸数据集,CelebA-HQ。CelebA-HQ数据集发布于2019年,包含30000张包括不同属性的高清人脸图,其中图像大小均为1024×1024。
数据集放置在项目根目录的 dataset 目录下,包括两个子文件夹,train 和 val。
在项目开始之前需要加载数据集和预训练模型,加载方式如下图所示: 仅第一次使用时操作!!!
由于数据集较大,加载需要较长时间,加载完毕后,会有弹窗显示
数据下载成功后,会得到两个 zip 文件,一个是数据集(Face_SuperResolution_Dataset.zip),一个是预训练模型(vgg16-397923af.zip)

运行下方代码解压数据集,第一次使用时运行即可!!,当显示 10 个 . 时,代表解压完成。
!unzip -o Face_SuperResolution_Dataset.zip | awk 'BEGIN {ORS=" "} {if(NR%3000==0)print "."}'
解压完成后会得到一个 dataset 文件夹,其文件结构如下
dataset
- train
- val
运行下方代码解压预训练模型,第一次使用时运行即可!!
!mkdir checkpoints
!unzip -o vgg16-397923af.zip -d ./checkpoints/
1.2 数据集接口
下面我们从高分辨率图进行采样得到低分辨率图,然后组成训练用的图像对,核心代码如下:
from os import listdir
from os.path import join
from PIL import Image
from torch.utils.data.dataset import Dataset
from torchvision.transforms import Compose, RandomCrop, ToTensor, ToPILImage, CenterCrop, Resize
def is_image_file(filename):
return any(
filename.endswith(extension)
for extension in ['.png', '.jpg', '.jpeg', '.PNG', '.JPG', '.JPEG'])
# 基于上采样因子对裁剪尺寸进行调整,使其为upscale_factor的整数倍
def calculate_valid_crop_size(crop_size, upscale_factor):
return crop_size - (crop_size % upscale_factor)
# 训练集高分辨率图预处理函数
def train_hr_transform(crop_size):
return Compose([
RandomCrop(crop_size),
ToTensor(),
])
# 训练集低分辨率图预处理函数
def train_lr_transform(crop_size, upscale_factor):
return Compose([
ToPILImage(),
Resize(crop_size // upscale_factor, interpolation=Image.BICUBIC),
ToTensor()
])
def display_transform():
return Compose([ToPILImage(), Resize(400), CenterCrop(400), ToTensor()])
# 训练数据集类
class TrainDatasetFromFolder(Dataset):
def __init__(self, dataset_dir, crop_size, upscale_factor):
super(TrainDatasetFromFolder, self).__init__()
self.image_filenames = [
join(dataset_dir, x) for x in listdir(dataset_dir)
if is_image_file(x)
] # 获得所有图像
crop_size = calculate_valid_crop_size(crop_size,
upscale_factor) # 获得裁剪尺寸
self.hr_transform = train_hr_transform(crop_size) # 高分辨率图预处理函数
self.lr_transform = train_lr_transform(crop_size,
upscale_factor) # 低分辨率图预处理函数
# 数据集迭代指针
def __getitem__(self, index):
hr_image = self.hr_transform(Image.open(
self.image_filenames[index])) # 随机裁剪获得高分辨率图
lr_image = self.lr_transform(hr_image) # 获得低分辨率图
return lr_image, hr_image
def __len__(self):
return len(self.image_filenames)
# 验证数据集类
class ValDatasetFromFolder(Dataset):
def __init__(self, dataset_dir, upscale_factor):
super(ValDatasetFromFolder, self).__init__()
self.upscale_factor = upscale_factor
self.image_filenames = [
join(dataset_dir, x) for x in listdir(dataset_dir)
if is_image_file(x)
]
def __getitem__(self, index):
hr_image = Image.open(self.image_filenames[index])
# 获得图像窄边获得裁剪尺寸
w, h = hr_image.size
crop_size = calculate_valid_crop_size(min(w, h), self.upscale_factor)
lr_scale = Resize(crop_size // self.upscale_factor,
interpolation=Image.BICUBIC)
hr_scale = Resize(crop_size, interpolation=Image.BICUBIC)
hr_image = CenterCrop(crop_size)(hr_image) # 中心裁剪获得高分辨率图
lr_image = lr_scale(hr_image) # 获得低分辨率图
hr_restore_img = hr_scale(lr_image)
return ToTensor()(lr_image), ToTensor()(hr_restore_img), ToTensor()(
hr_image)
def __len__(self):
return len(self.image_filenames)
class TestDatasetFromFolder(Dataset):
def __init__(self, dataset_dir, upscale_factor):
super(TestDatasetFromFolder, self).__init__()
self.lr_path = dataset_dir + '/SRF_' + str(upscale_factor) + '/data/'
self.hr_path = dataset_dir + '/SRF_' + str(upscale_factor) + '/target/'
self.upscale_factor = upscale_factor
self.lr_filenames = [
join(self.lr_path, x) for x in listdir(self.lr_path)
if is_image_file(x)
]
self.hr_filenames = [
join(self.hr_path, x) for x in listdir(self.hr_path)
if is_image_file(x)
]
def __getitem__(self, index):
image_name = self.lr_filenames[index].split('/')[-1]
lr_image = Image.open(self.lr_filenames[index])
w, h = lr_image.size
hr_image = Image.open(self.hr_filenames[index])
hr_scale = Resize((self.upscale_factor * h, self.upscale_factor * w),
interpolation=Image.BICUBIC)
hr_restore_img = hr_scale(lr_image)
return image_name, ToTensor()(lr_image), ToTensor()(
hr_restore_img), ToTensor()(hr_image)
def __len__(self):
return len(self.lr_filenames)
从上述代码可以看出,包含了两个预处理函数接口,分别是train_hr_transform,train_lr_transform。train_hr_transform包含的操作主要是随机裁剪,而train_lr_transform包含的操作主要是缩放。
另外还有一个函数calculate_valid_crop_size,对于训练集来说,它用于当配置的图像尺寸crop_size不能整除上采样因子upscale_factor时对crop_size进行调整,我们在使用的时候应该避免这一点,即配置crop_size让它等于upscale_factor的整数倍。对于验证集,图像的窄边min(w, h)会被用于crop_size的初始化,所以该函数的作用是当图像的窄边不能整除上采样因子upscale_factor时对crop_size进行调整。
训练集类TrainDatasetFromFolder包含了若干操作,它使用train_hr_transform从原图像中随机裁剪大小为裁剪尺寸的正方形的图像,使用train_lr_transform获得对应的低分辨率图。而验证集类ValDatasetFromFolder则将图像按照调整后的crop_size进行中心裁剪,然后使用train_lr_transform获得对应的低分辨率图。
在这里我们只使用了随机裁剪作为训练时的数据增强操作,实际训练工程项目时,应该根据需要添加多种数据增强操作才能获得泛化能力更好的模型。
1.3 生成器
生成器是一个基于残差模块的上采样模型,它的定义包括残差模块,上采样模块以及主干模型,如下:
import math
import torch
from torch import nn
# 生成模型
class Generator(nn.Module):
def __init__(self, scale_factor):
upsample_block_num = int(math.log(scale_factor, 2))
super(Generator, self).__init__()
# 第一个卷积层,卷积核大小为9×9,输入通道数为3,输出通道数为64
self.block1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=9, padding=4),
nn.PReLU())
# 6个残差模块
self.block2 = ResidualBlock(64)
self.block3 = ResidualBlock(64)
self.block4 = ResidualBlock(64)
self.block5 = ResidualBlock(64)
self.block6 = ResidualBlock(64)
self.block7 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.BatchNorm2d(64))
# upsample_block_num个上采样模块,每一个上采样模块恢复2倍的上采样倍率
block8 = [UpsampleBLock(64, 2) for _ in range(upsample_block_num)]
# 最后一个卷积层,卷积核大小为9×9,输入通道数为64,输出通道数为3
block8.append(nn.Conv2d(64, 3, kernel_size=9, padding=4))
self.block8 = nn.Sequential(*block8)
def forward(self, x):
block1 = self.block1(x)
block2 = self.block2(block1)
block3 = self.block3(block2)
block4 = self.block4(block3)
block5 = self.block5(block4)
block6 = self.block6(block5)
block7 = self.block7(block6)
block8 = self.block8(block1 + block7)
return (torch.tanh(block8) + 1) / 2
# 残差模块
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
# 两个卷积层,卷积核大小为3×3,通道数不变
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(channels)
self.prelu = nn.PReLU()
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(channels)
def forward(self, x):
residual = self.conv1(x)
residual = self.bn1(residual)
residual = self.prelu(residual)
residual = self.conv2(residual)
residual = self.bn2(residual)
return x + residual
# 上采样模块,每一个恢复分辨率为2
class UpsampleBLock(nn.Module):
def __init__(self, in_channels, up_scale):
super(UpsampleBLock, self).__init__()
# 卷积层,输入通道数为in_channels,输出通道数为in_channels * up_scale ** 2
self.conv = nn.Conv2d(in_channels,
in_channels * up_scale**2,
kernel_size=3,
padding=1)
# PixelShuffle上采样层,来自于后上采样结构
self.pixel_shuffle = nn.PixelShuffle(up_scale)
self.prelu = nn.PReLU()
def forward(self, x):
x = self.conv(x)
x = self.pixel_shuffle(x)
x = self.prelu(x)
return x
在上述的生成器定义中,调用了nn.PixelShuffle模块来实现上采样,它的具体原理在上节基于亚像素卷积的后上采样ESPCN模型中有详细介绍。
1.4 判别器
判别器是一个普通的类似于VGG的CNN模型,完整定义如下:
# 残差模块
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
# 第1个卷积层,卷积核大小为3×3,输入通道数为3,输出通道数为64
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.LeakyReLU(0.2),
# 第2个卷积层,卷积核大小为3×3,输入通道数为64,输出通道数为64
nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
# 第3个卷积层,卷积核大小为3×3,输入通道数为64,输出通道数为128
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
# 第4个卷积层,卷积核大小为3×3,输入通道数为128,输出通道数为128
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
# 第5个卷积层,卷积核大小为3×3,输入通道数为128,输出通道数为256
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
# 第6个卷积层,卷积核大小为3×3,输入通道数为256,输出通道数为256
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
# 第7个卷积层,卷积核大小为3×3,输入通道数为256,输出通道数为512
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
# 第8个卷积层,卷积核大小为3×3,输入通道数为512,输出通道数为512
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
# 全局池化层
nn.AdaptiveAvgPool2d(1),
# 两个全连接层,使用卷积实现
nn.Conv2d(512, 1024, kernel_size=1),
nn.LeakyReLU(0.2),
nn.Conv2d(1024, 1, kernel_size=1))
def forward(self, x):
batch_size = x.size(0)
return torch.sigmoid(self.net(x).view(batch_size))
1.5 损失定义
import torch
from torch import nn
from torchvision.models.vgg import vgg16
import os
os.environ['TORCH_HOME'] = './'
# 生成器损失定义
class GeneratorLoss(nn.Module):
def __init__(self):
super(GeneratorLoss, self).__init__()
vgg = vgg16(pretrained=True)
loss_network = nn.Sequential(*list(vgg.features)[:31]).eval()
for param in loss_network.parameters():
param.requires_grad = False
self.loss_network = loss_network
self.mse_loss = nn.MSELoss() # MSE损失
self.tv_loss = TVLoss() # TV平滑损失
def forward(self, out_labels, out_images, target_images):
# 对抗损失
adversarial_loss = torch.mean(1 - out_labels)
# 感知损失
perception_loss = self.mse_loss(self.loss_network(out_images),
self.loss_network(target_images))
# 图像MSE损失
image_loss = self.mse_loss(out_images, target_images)
# TV平滑损失
tv_loss = self.tv_loss(out_images)
return image_loss + 0.001 * adversarial_loss + 0.006 * perception_loss + 2e-8 * tv_loss
# TV平滑损失
class TVLoss(nn.Module):
def __init__(self, tv_loss_weight=1):
super(TVLoss, self).__init__()
self.tv_loss_weight = tv_loss_weight
def forward(self, x):
batch_size = x.size()[0]
h_x = x.size()[2]
w_x = x.size()[3]
count_h = self.tensor_size(x[:, :, 1:, :])
count_w = self.tensor_size(x[:, :, :, 1:])
h_tv = torch.pow((x[:, :, 1:, :] - x[:, :, :h_x - 1, :]), 2).sum()
w_tv = torch.pow((x[:, :, :, 1:] - x[:, :, :, :w_x - 1]), 2).sum()
return self.tv_loss_weight * 2 * (h_tv / count_h +
w_tv / count_w) / batch_size
@staticmethod
def tensor_size(t):
return t.size()[1] * t.size()[2] * t.size()[3]
if __name__ == "__main__":
g_loss = GeneratorLoss()
print(g_loss)
生成器损失总共包含4部分,分别是对抗网络损失,逐像素的图像MSE损失,基于VGG模型的感知损失,用于约束图像平滑的TV平滑损失。
2. 模型训练
接下来我们来解读模型的核心训练代码,查看模型训练的结果。训练代码除了模型和损失定义,还需要完成优化器定义,训练和验证指标变量的存储,核心代码如下:
from math import exp
import torch
import torch.nn.functional as F
from torch.autograd import Variable
def gaussian(window_size, sigma):
gauss = torch.Tensor([exp(-(x - window_size // 2) ** 2 / float(2 * sigma ** 2)) for x in range(window_size)])
return gauss / gauss.sum()
def create_window(window_size, channel):
_1D_window = gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
return window
def _ssim(img1, img2, window, window_size, channel, size_average=True):
mu1 = F.conv2d(img1, window, padding=window_size // 2, groups=channel)
mu2 = F.conv2d(img2, window, padding=window_size // 2, groups=channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1 * mu2
sigma1_sq = F.conv2d(img1 * img1, window, padding=window_size // 2, groups=channel) - mu1_sq
sigma2_sq = F.conv2d(img2 * img2, window, padding=window_size // 2, groups=channel) - mu2_sq
sigma12 = F.conv2d(img1 * img2, window, padding=window_size // 2, groups=channel) - mu1_mu2
C1 = 0.01 ** 2
C2 = 0.03 ** 2
ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2))
if size_average:
return ssim_map.mean()
else:
return ssim_map.mean(1).mean(1).mean(1)
class SSIM(torch.nn.Module):
def __init__(self, window_size=11, size_average=True):
super(SSIM, self).__init__()
self.window_size = window_size
self.size_average = size_average
self.channel = 1
self.window = create_window(window_size, self.channel)
def forward(self, img1, img2):
(_, channel, _, _) = img1.size()
if channel == self.channel and self.window.data.type() == img1.data.type():
window = self.window
else:
window = create_window(self.window_size, channel)
if img1.is_cuda:
window = window.cuda(img1.get_device())
window = window.type_as(img1)
self.window = window
self.channel = channel
return _ssim(img1, img2, window, self.window_size, channel, self.size_average)
def ssim(img1, img2, window_size=11, size_average=True):
(_, channel, _, _) = img1.size()
window = create_window(window_size, channel)
if img1.is_cuda:
window = window.cuda(img1.get_device())
window = window.type_as(img1)
return _ssim(img1, img2, window, window_size, channel, size_average)
创建一些文件夹,首次使用时运行!!!
!mkdir training_results
!mkdir epochs
!mkdir statistics
mkdir: cannot create directory ‘training_results’: File exists
mkdir: cannot create directory ‘epochs’: File exists
mkdir: cannot create directory ‘statistics’: File exists
注意:由于阿里云平台 GPU 资源受限,本项目仅使用少量数据集进行训练
import os
from math import log10
import pandas as pd
import torch.optim as optim
import torch.utils.data
import torchvision.utils as utils
from torch.autograd import Variable
from torch.utils.data import DataLoader
from tqdm import tqdm
if __name__ == '__main__':
CROP_SIZE = 240 #opt.crop_size ## 裁剪尺寸,即训练尺度
UPSCALE_FACTOR = 4#opt.upscale_factor ## 超分上采样倍率
NUM_EPOCHS = 20 #opt.num_epochs ## 迭代epoch次数
## 获取训练集/验证集
train_set = TrainDatasetFromFolder('dataset/train', crop_size=CROP_SIZE, upscale_factor=UPSCALE_FACTOR)
val_set = ValDatasetFromFolder('dataset/val', upscale_factor=UPSCALE_FACTOR)
train_loader = DataLoader(dataset=train_set, num_workers=4, batch_size=16, shuffle=True)
val_loader = DataLoader(dataset=val_set, num_workers=4, batch_size=1, shuffle=False)
netG = Generator(UPSCALE_FACTOR) ##生成器定义
netD = Discriminator() ##判别器定义
generator_criterion = GeneratorLoss() ##生成器优化目标
## 是否使用GPU
if torch.cuda.is_available():
netG.cuda()
netD.cuda()
generator_criterion.cuda()
##生成器和判别器优化器
optimizerG = optim.Adam(netG.parameters())
optimizerD = optim.Adam(netD.parameters())
results = {'d_loss': [], 'g_loss': [], 'd_score': [], 'g_score': [], 'psnr': [], 'ssim': []}
## epoch迭代
for epoch in range(1, NUM_EPOCHS + 1):
train_bar = tqdm(train_loader)
running_results = {'batch_sizes': 0, 'd_loss': 0, 'g_loss': 0, 'd_score': 0, 'g_score': 0} ##结果变量
netG.train() ##生成器训练
netD.train() ##判别器训练
## 每一个epoch的数据迭代
for data, target in train_bar:
g_update_first = True
batch_size = data.size(0)
running_results['batch_sizes'] += batch_size
## 优化判别器,最大化D(x)-1-D(G(z))
real_img = Variable(target)
if torch.cuda.is_available():
real_img = real_img.cuda()
z = Variable(data)
if torch.cuda.is_available():
z = z.cuda()
fake_img = netG(z) ##获取生成结果
netD.zero_grad()
real_out = netD(real_img).mean()
fake_out = netD(fake_img).mean()
d_loss = 1 - real_out + fake_out
d_loss.backward(retain_graph=True)
optimizerD.step() ##优化判别器
## 优化生成器 最小化1-D(G(z)) + Perception Loss + Image Loss + TV Loss
netG.zero_grad()
g_loss = generator_criterion(fake_out, fake_img, real_img)
g_loss.backward()
fake_img = netG(z)
fake_out = netD(fake_img).mean()
optimizerG.step()
# 记录当前损失
running_results['g_loss'] += g_loss.item() * batch_size
running_results['d_loss'] += d_loss.item() * batch_size
running_results['d_score'] += real_out.item() * batch_size
running_results['g_score'] += fake_out.item() * batch_size
train_bar.set_description(desc='[%d/%d] Loss_D: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f' % (
epoch, NUM_EPOCHS, running_results['d_loss'] / running_results['batch_sizes'],
running_results['g_loss'] / running_results['batch_sizes'],
running_results['d_score'] / running_results['batch_sizes'],
running_results['g_score'] / running_results['batch_sizes']))
## 对验证集进行验证
netG.eval() ## 设置验证模式
out_path = 'training_results/SRF_' + str(UPSCALE_FACTOR) + '/'
if not os.path.exists(out_path):
os.makedirs(out_path)
## 计算验证集相关指标
with torch.no_grad():
val_bar = tqdm(val_loader)
valing_results = {'mse': 0, 'ssims': 0, 'psnr': 0, 'ssim': 0, 'batch_sizes': 0}
val_images = []
for val_lr, val_hr_restore, val_hr in val_bar:
batch_size = val_lr.size(0)
valing_results['batch_sizes'] += batch_size
lr = val_lr ##低分辨率真值图
hr = val_hr ##高分辨率真值图
if torch.cuda.is_available():
lr = lr.cuda()
hr = hr.cuda()
sr = netG(lr) ##超分重建结果
batch_mse = ((sr - hr) ** 2).data.mean() ##计算MSE指标
valing_results['mse'] += batch_mse * batch_size
valing_results['psnr'] = 10 * log10(1 / (valing_results['mse'] / valing_results['batch_sizes'])) ##计算PSNR指标
batch_ssim = ssim(sr, hr).item() ##计算SSIM指标
valing_results['ssims'] += batch_ssim * batch_size
valing_results['ssim'] = valing_results['ssims'] / valing_results['batch_sizes']
## 存储模型参数
torch.save(netG.state_dict(), 'epochs/netG_epoch_%d_%d.pth' % (UPSCALE_FACTOR, epoch))
torch.save(netD.state_dict(), 'epochs/netD_epoch_%d_%d.pth' % (UPSCALE_FACTOR, epoch))
## 记录训练集损失以及验证集的psnr,ssim等指标 \scores\psnr\ssim
results['d_loss'].append(running_results['d_loss'] / running_results['batch_sizes'])
results['g_loss'].append(running_results['g_loss'] / running_results['batch_sizes'])
results['d_score'].append(running_results['d_score'] / running_results['batch_sizes'])
results['g_score'].append(running_results['g_score'] / running_results['batch_sizes'])
results['psnr'].append(valing_results['psnr'])
results['ssim'].append(valing_results['ssim'])
## 存储结果到本地文件
if epoch % 10 == 0 and epoch != 0:
out_path = 'statistics/'
data_frame = pd.DataFrame(
data={'Loss_D': results['d_loss'], 'Loss_G': results['g_loss'], 'Score_D': results['d_score'],
'Score_G': results['g_score'], 'PSNR': results['psnr'], 'SSIM': results['ssim']},
index=range(1, epoch + 1))
data_frame.to_csv(out_path + 'srf_' + str(UPSCALE_FACTOR) + '_train_results.csv', index_label='Epoch')
从上述代码可以看出,训练时采用的crop_size为240×240,批处理大小为16,使用的优化器为Adam,Adam采用了默认的优化参数。
损失等相关数据将生成在 statistics 文件夹下。
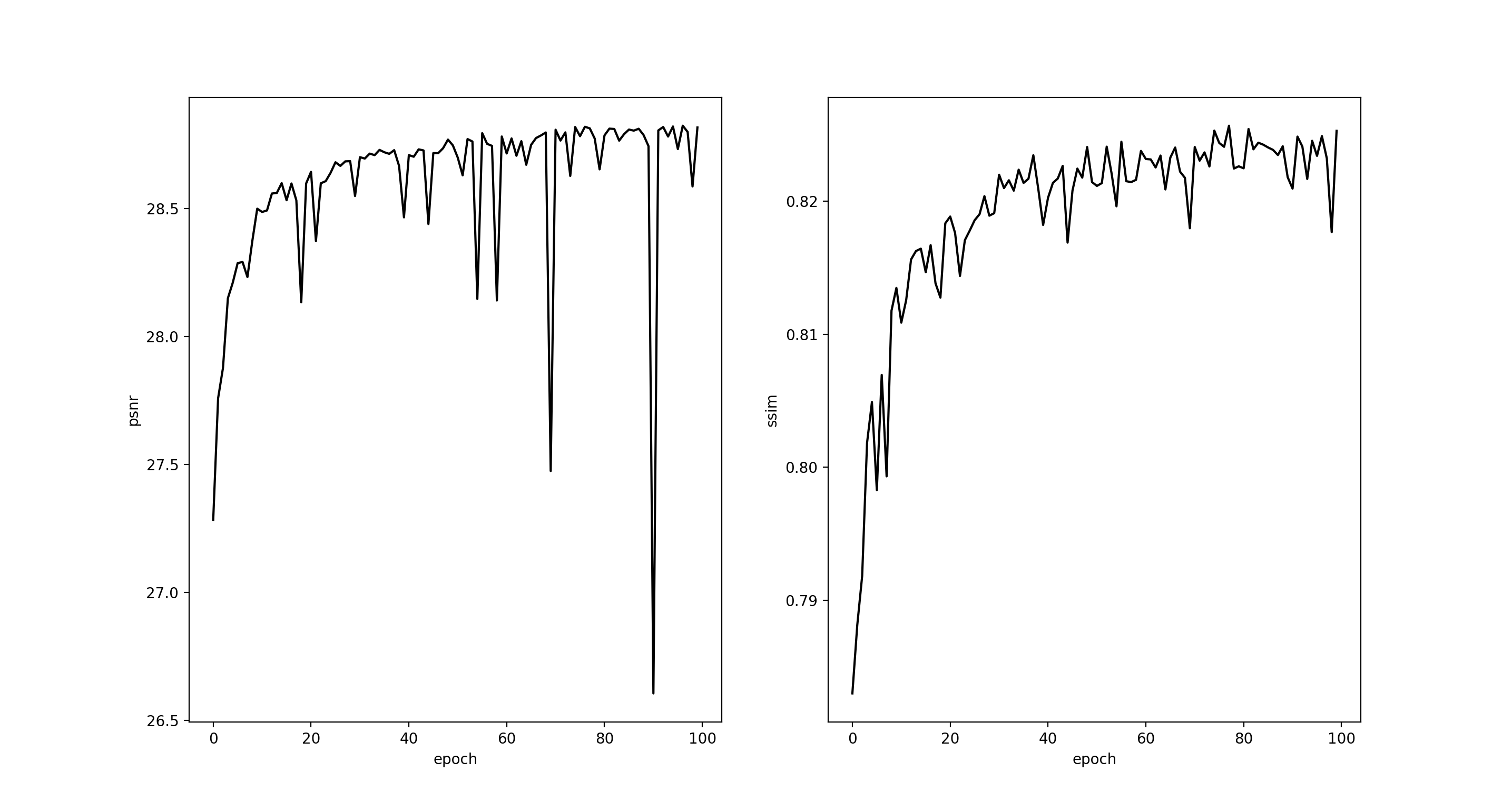
上采样倍率为4的模型训练结果如下:
3. 模型测试
接下来我们进行模型的测试。
3.1 测试代码
首先解读测试代码,需要完成模型的载入,图像预处理和结果存储,完整代码如下:
import torch
from PIL import Image
from torch.autograd import Variable
from torchvision.transforms import ToTensor, ToPILImage
UPSCALE_FACTOR = 4 ##上采样倍率
TEST_MODE = True ## 使用GPU进行测试
IMAGE_NAME = "./dataset/val/10879.jpg" # 测试图片路径
MODEL_NAME = './epochs/netG_epoch_4_20.pth' ##模型路径
model = Generator(UPSCALE_FACTOR).eval() ##设置验证模式
if TEST_MODE:
model.cuda()
model.load_state_dict(torch.load(MODEL_NAME))
else:
model.load_state_dict(torch.load(MODEL_NAME, map_location=lambda storage, loc: storage))
image = Image.open(IMAGE_NAME) ##读取图片
image = Variable(ToTensor()(image), volatile=True).unsqueeze(0) ##图像预处理
if TEST_MODE:
image = image.cuda()
with torch.no_grad():
RESULT_NAME = "out_srf_" + str(UPSCALE_FACTOR) + "_" + IMAGE_NAME.split("/")[-1]
out = model(image)
out_img = ToPILImage()(out[0].data.cpu())
out_img.save(RESULT_NAME)
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:21: UserWarning: volatile was removed and now has no effect. Use `with torch.no_grad():` instead.
预测结果将在本级目录生成,以 out_srf_ 开头
3.2 重建结果
下图展示了若干图片的超分辨结果。
第一行为使用双线性插值进行上采样的结果, 第二行为4倍超分结果,第三行为原始大图。

本次我们对SRGAN模型进行了实践,使用高清人脸数据集进行训练,对低分辨率的人脸图像进行了超分重建,验证了SRGAN模型的有效性,不过该模型仍然有较大的改进空间,它需要使用成对数据集进行训练,而训练时低分辨率图片的模式产生过于简单,无法对复杂的退化类型完成重建。
当要对退化类型更加复杂的图像进行超分辨重建时,模型训练时也应该采取多种对应的数据增强方法,包括但不限于对比度增强,各类噪声污染,JPEG压缩失真等操作,这些就留给读者去做更多的实验。















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









