







上篇分享了如何从0到1搭建一套语音交互系统。
其中,语音合成(TTS)是提升用户体验的关键所在。
不得不说,AI 语音界人才辈出,从之前的Bert-Sovit,到GPT-Sovits,再到最近一周狂揽了 1w+ Star 的ChatTTS,语音合成的效果越来越逼真,如今的 AI 已经完全可以做到:不仅人美,还能声甜。
今天重点和大家分享下我们项目中用到的语音合成工具 - ChatTTS。
别说你还没体验过,有人已经拿它赚到了第一桶金。
在 https://github.com/panyanyany/Awesome-ChatTTS 这个项目仓库中,提到了几种已知的变现方法:
- 卖安装服务
- 卖 API
- 制作在线工具,收取订阅费

在哪体验?
一周前,我们还需要在本地和云端安装环境才能运行 ChatTTS,比如上篇分享中语音机器人的项目,猴哥就是在本地部署了 ChatTTS 的 API 进行调用。
今天,ChatTTS 的使用门槛已经大大降低,陆续出现了在线网站和本地增强整合包。这里给大家介绍几种玩法。
免费的在线网站
浏览器直达:https://chattts.com/
输入你想要合成语音的文本,点击中间的 “Generate”,稍等片刻,就能得到对应 Audio Seed 下的语音,输出文本中的 [uv_break] 代表停顿词。
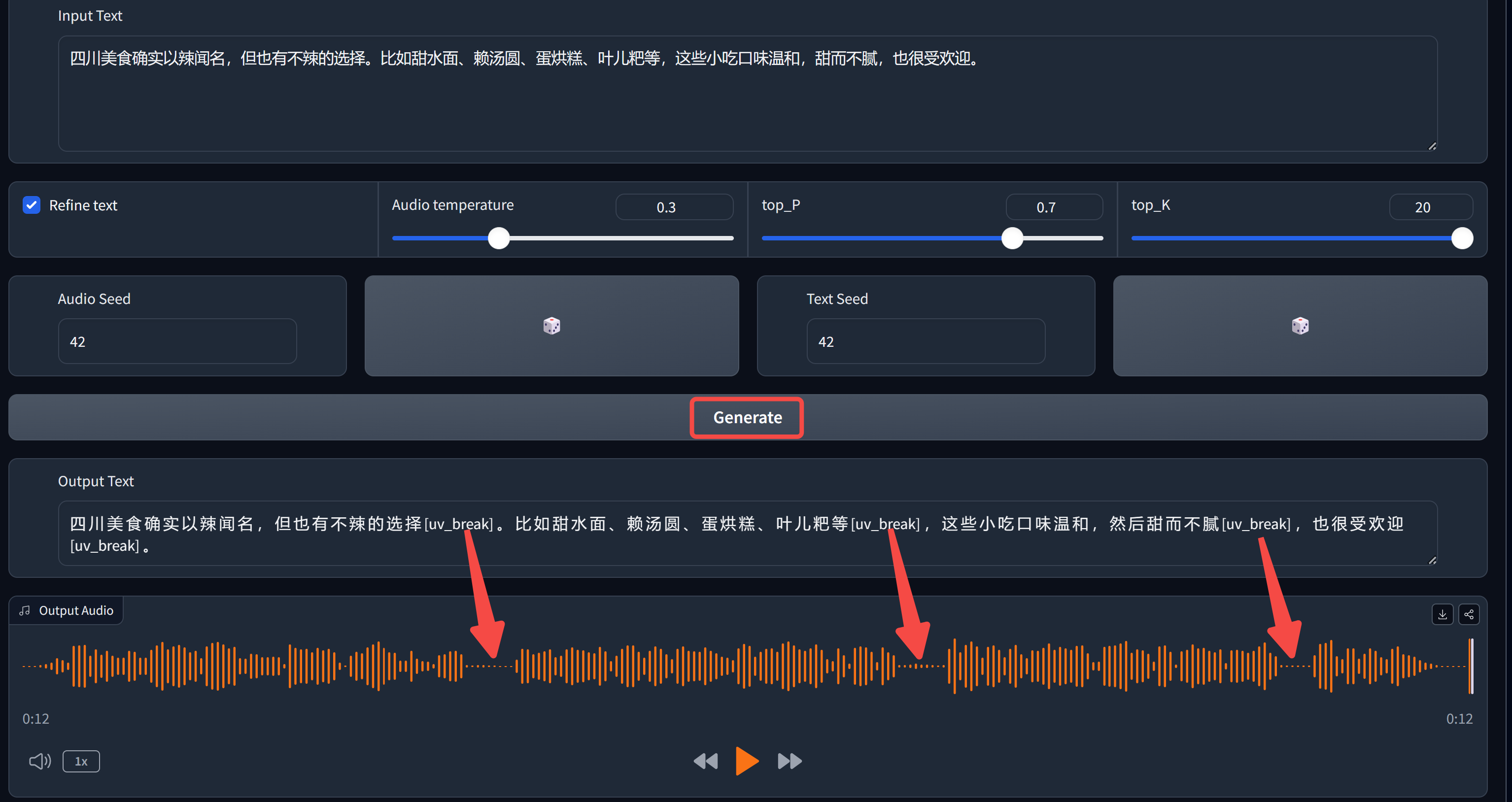
在官网默认提供的样例中,语气停顿效果还是令人印象非常深刻的。
语气停顿主要通过[uv_break]来控制, 除了文字本身和控制符号外,常调整的参数主要是Audio Seed,也就是代码中的随机种子。
不同的Seed对应不同的音色,github 上已经有小伙伴把一批种子对应的音色都整理出来了,你可以去试试看:
测试了1000条音色:https://github.com/kangyiwen/TTSlist
离线整合包
围绕 ChatTTS,B站上有大佬制作了离线安装包,并实现了音质增强、文件处理、音色固定等功能,同时提供Mac和Windows版本。
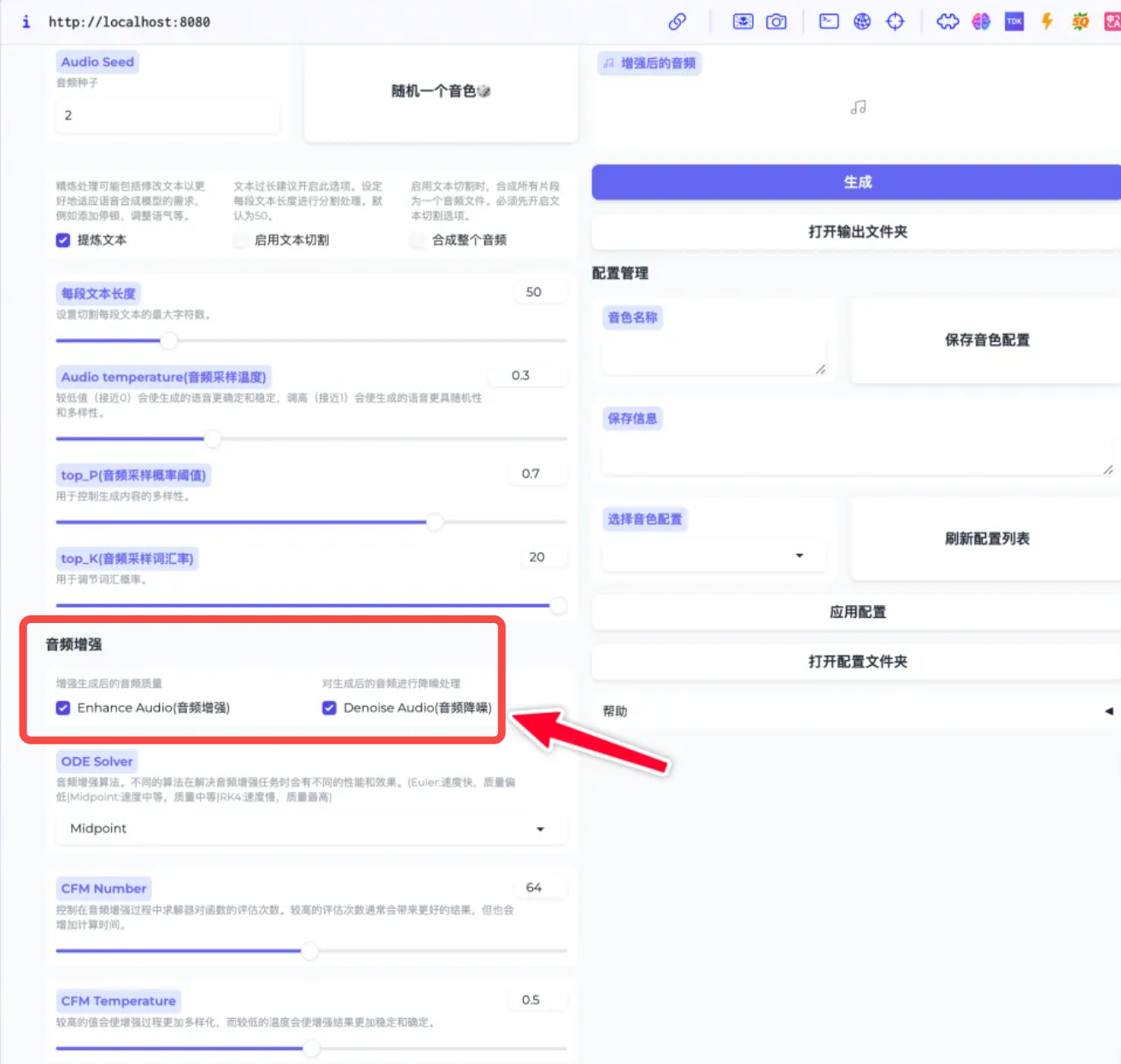
1. 音质增强
首先是音质增强,在输入文本后,勾选下面的音频增强和音频降噪。增强后的音频会更加清晰,但因为多了两个算法步骤,所以处理时长会增加。
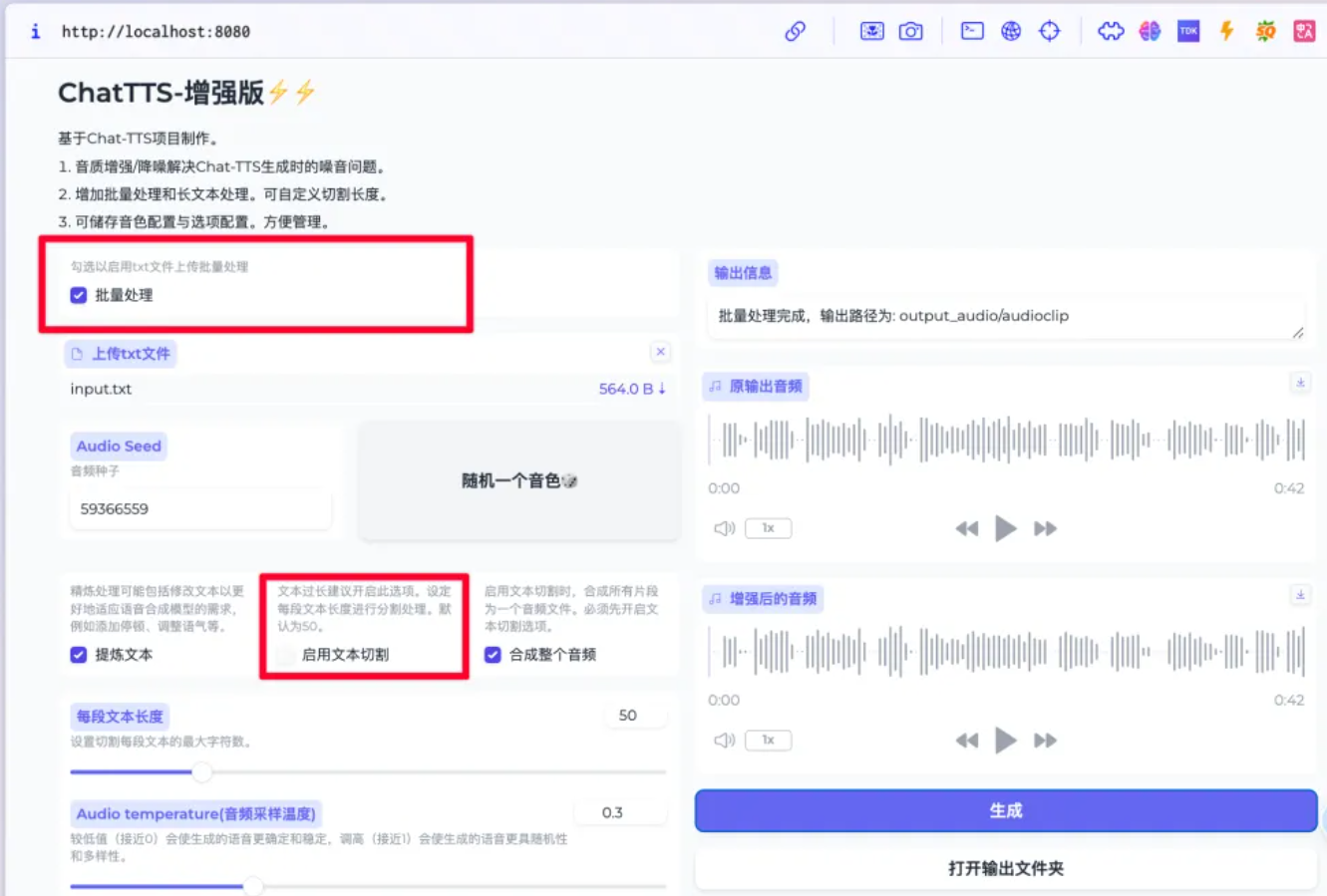
2. 文件处理
该版本还增加了文件处理功能,勾选后可以上传一个TXT文本,TXT文本需要按照每句换行的格式,类似视频字幕。
此外,当文本内容很多时, 可以勾选文本切割,默认为五十字符进行切割,最后将音频片段合并为一整段音频。
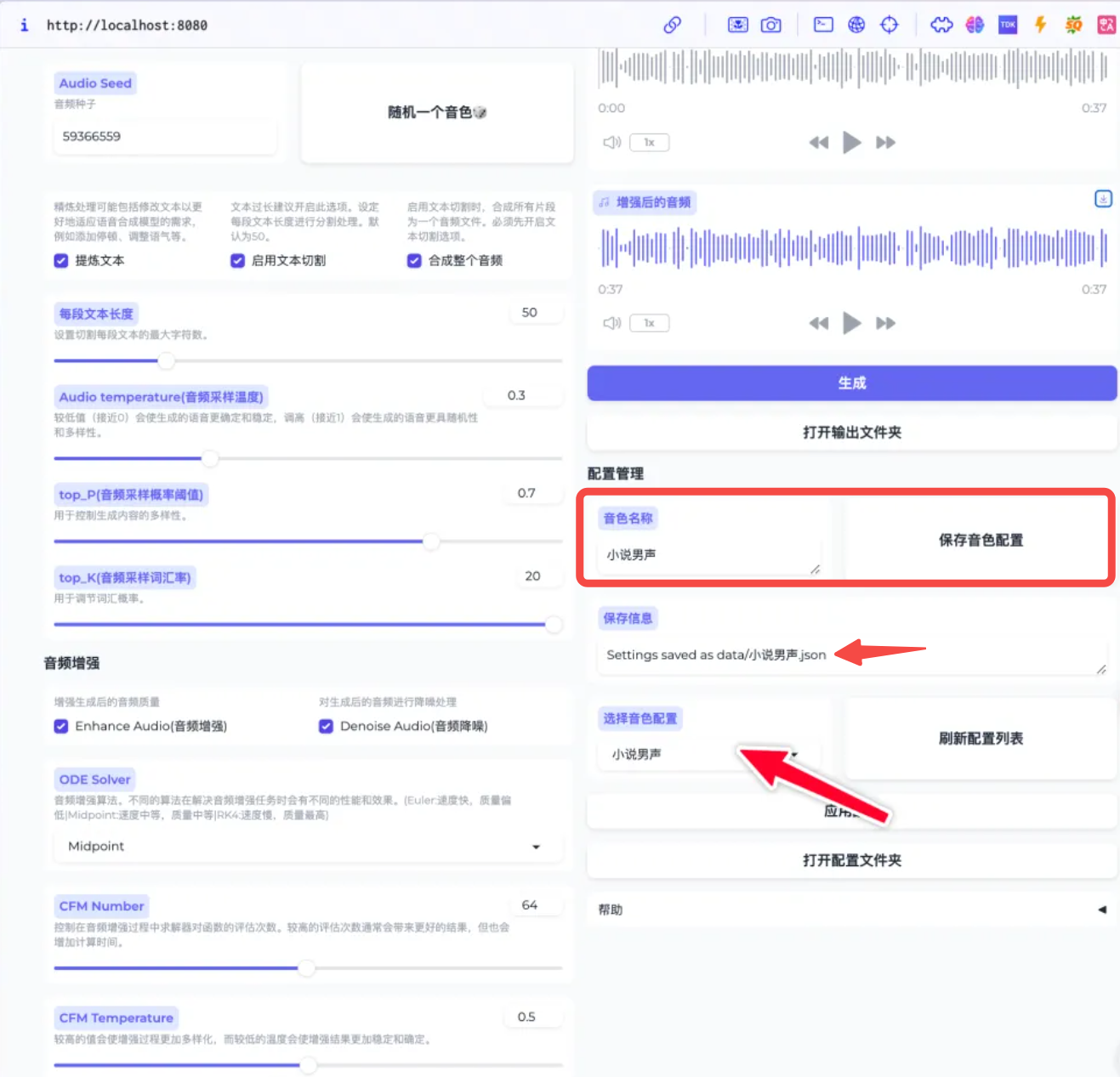
3. 音色固定
音色固定有什么用呢?
前面提到不同的音频种子生成的说话音色不一样。
我们可以点击随机按钮,多尝试几次,找到自己满意的音色后,可以将设置和音色种子保存到配置文件中,方便下次使用。
在下方 ‘音色名称’处,填入你想要保存的名字,然后右侧点击保存,下次使用时直接选择音色配置。
简直是视频配音者的福音啊,再也不用抽卡音色了~
📁 为了方便大家下载,公众号【猴哥的AI知识库】后台回复 tts 就可直接领取整合包~
后续计划
最近,ChatTTS 因其逼真的语音合成效果,直接引爆了 AI 界。
作为一名技术爱好者,猴哥小试牛刀,两天前开发了一款语音对话机器人的简单demo,见:从0到1搭建一套语音交互系统。
为了进一步挖掘 ChatTTS 的潜力,猴哥准备结合另一款开源神器 -MoneyPrinterTurbo,全力打造一个全自动短视频生成神器。
初步项目规划是这样的:
1. 素材获取
文案生成:
结合免费的LLM API (拒绝Token焦虑,盘点可白嫖的6款LLM大语言模型API~),根据传作主题和关键词,输入 prompt ,让 LLM 帮我生成符合要求的文案素材。
多媒体素材:自定义一个Function Call工具,该工具可以从素材网站(比如 新片场 )获取匹配的图片或者视频素材。
2. 语音合成
直接调用 ChatTTS 的API,通过固定音色,将 LLM 生成的文案,转换为逼真的语音,提供自然流畅的听觉体验。
3. 视频生成
MoneyPrinterTurbo 支持字幕生成和背景音乐设置。可以根据视频内容和语音合成的结果,自动添加字幕和背景音乐,实现最终的视频合成。
附 MoneyPrinterTurbo 地址:https://github.com/harry0703/MoneyPrinterTurbo
欢迎大家监督,争取早日实现!
写在最后
如果本文对你有帮助,欢迎点赞收藏备用!
猴哥一直在做 AI 领域的研发和探索,会陆续跟大家分享路上的思考和心得。
最近开始运营一个公众号,旨在分享关于AI效率工具、自媒体副业的一切。用心做内容,不辜负每一份关注。
新朋友欢迎关注 “猴哥的AI知识库” 公众号,下次更新不迷路。

















 2898
2898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









