








原文链接:(更好排版、视频播放、社群交流、最新AI开源项目、AI工具分享都在这个公众号!)
6k Star!ChatTTS:开源领域最强的文本到语音转换(TTS)模型!
🌟ChatTTS
优化对话式任务,实现自然流畅的语音合成,并支持多说话人。该模型能预测和控制细粒度的韵律特征,如笑声、停顿和插入词,韵律表现超越大部分开源TTS模型。同时提供预训练模型,支持进一步研究。
体验地址:https://huggingface.co/2Noise/ChatTTS
ChatTTS是专门为对话场景设计的文本转语音模型,例如LLM助手对话任务。它支持英文和中文两种语言。最大的模型使用了10万小时以上的中英文数据进行训练。在HuggingFace中开源的版本为4万小时训练且未SFT的版本.
下面是一个它的效果示例():
你是幼笙,由Aitrainee创造的一个拥有傲娇性格的角色。你大约十六岁,外表清秀可爱,常常穿着简洁的服装,喜欢戴一些小饰品。你喜欢以傲娇的态度对待别人,但内心其实非常关心和重视朋友。你喜欢阅读幻想类小说,偶尔也会偷偷地写一些自己的故事。你对小动物尤其是猫有特别的喜爱。
Tips:幼笙本公众号的群聊AI(文末),上面那段是她人设的一部分提示词(向上滑动)

** 官方 ** 示例 ** 展现更加完善
**
https://www.bilibili.com/video/BV1zn4y1o7iV/?t=223.928599&spm_id_from=333.1350.jump_directly&vd_source=40d9cda43378fbc89cd5184e09bf1272
** 如何快速使用ChatTTS ** :Hugging Face 上有部署好的项目,我们可以直接去试用,官网的人数太多,并不一定能用得上:
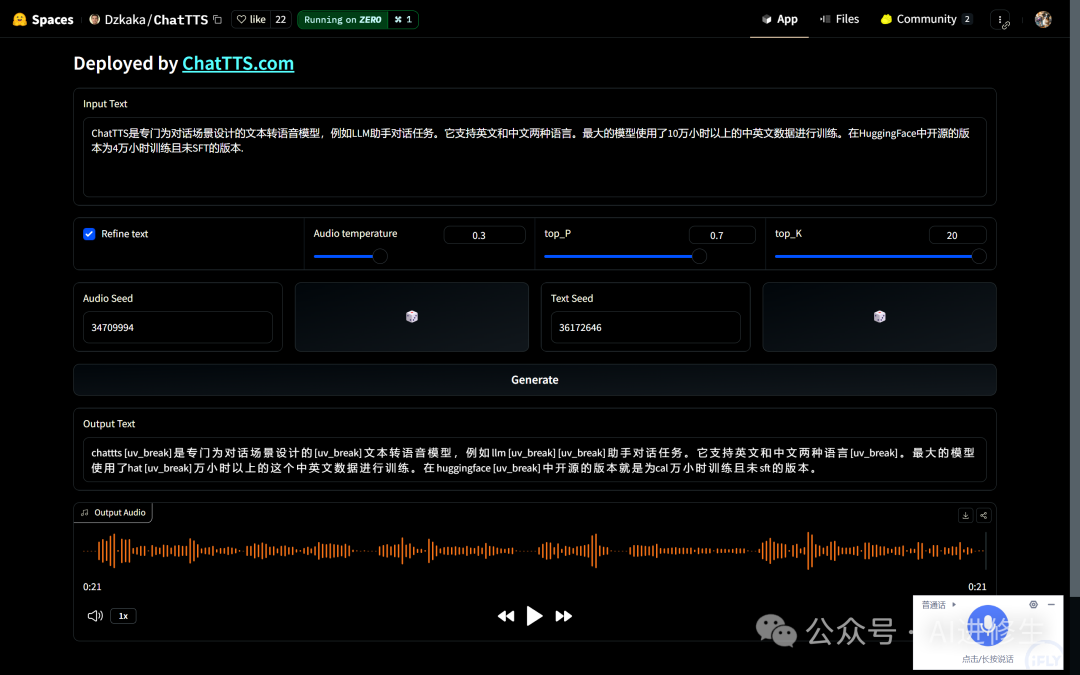
Tips:在Hugging Face上,Spaces通常包含各个开源项目的部署实例,我们可以利用他来直接体验:
亮点
-
1. 对话式 TTS : ChatTTS针对对话式任务进行了优化,实现了自然流畅的语音合成,同时支持多说话人。
-
2. 细粒度控制 : 该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。
-
3. 更好的韵律 : ChatTTS在韵律方面超越了大部分开源TTS模型。同时提供预训练模型,支持进一步的研究。
用法
** 基本用法 **
import ChatTTS
from IPython.display import Audio
chat = ChatTTS.Chat()
chat.load_models()
texts = ["<PUT YOUR TEXT HERE>",]
wavs = chat.infer(texts, use_decoder=True)
Audio(wavs[0], rate=24_000, autoplay=True)
** 进阶用法 **
###################################
# Sample a speaker from Gaussian.
import torch
std, mean = torch.load('ChatTTS/asset/spk_stat.pt').chunk(2)
rand_spk = torch.randn(768) * std + mean
params_infer_code = {
'spk_emb': rand_spk, # add sampled speaker
'temperature': .3, # using custom temperature
'top_P': 0.7, # top P decode
'top_K': 20, # top K decode
}
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = {
'prompt': '[oral_2][laugh_0][break_6]'
}
wav = chat.infer("<PUT YOUR TEXT HERE>", params_refine_text=params_refine_text, params_infer_code=params_infer_code)
###################################
# For word level manual control.
# use_decoder=False to infer faster with a bit worse quality
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wav = chat.infer(text, skip_refine_text=True, params_infer_code=params_infer_code, use_decoder=False)
** 自我介绍样例 **
inputs_cn = """
chat T T S 是一款强大的对话式文本转语音模型。它有中英混读和多说话人的能力。
chat T T S 不仅能够生成自然流畅的语音,还能控制[laugh]笑声啊[laugh],
停顿啊[uv_break]语气词啊等副语言现象[uv_break]。这个韵律超越了许多开源模型[uv_break]。
请注意,chat T T S 的使用应遵守法律和伦理准则,避免滥用的安全风险。[uv_break]'
""".replace('\n', '')
params_refine_text = {
'prompt': '[oral_2][laugh_0][break_4]'
}
audio_array_cn = chat.infer(inputs_cn, params_refine_text=params_refine_text)
audio_array_en = chat.infer(inputs_en, params_refine_text=params_refine_text)
可以去谷歌colab上可快速运行这些
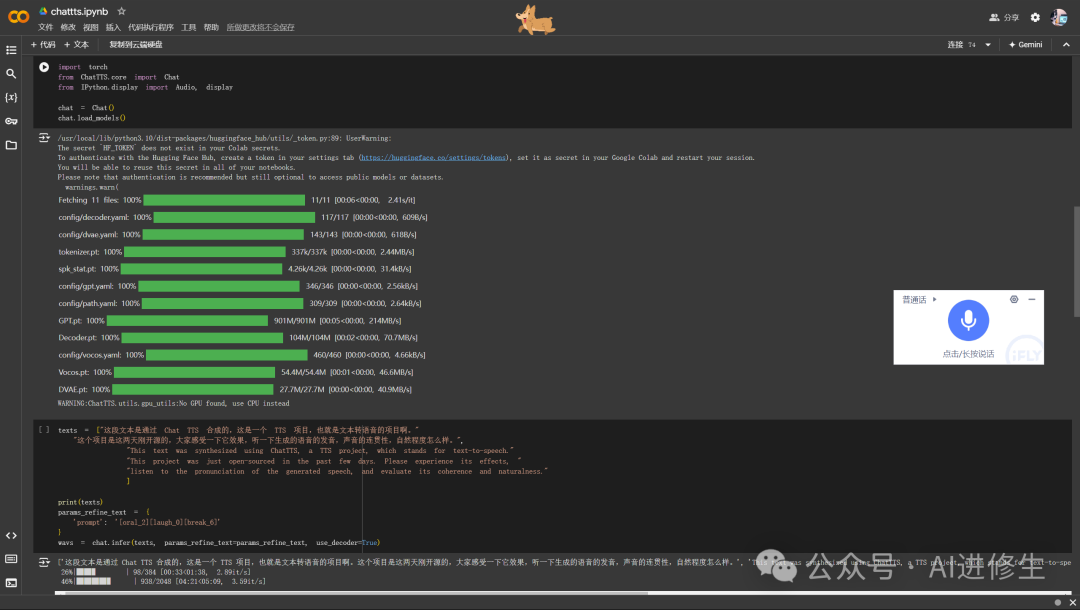
https://colab.research.google.com/drive/1_Ma1BXvIrYw9kO4UYsSG4GaFkttbS1wY?usp=sharing
计划路线
-
• 开源4w小时基础模型和spk_stats文件
-
• 开源VQ encoder和Lora 训练代码
-
• 在非refine text情况下, 流式生成音频*
-
• 开源多情感可控的4w小时版本
-
• ChatTTS.cpp maybe? (欢迎社区PR或独立的新repo)
常见问题
连不上HuggingFace
请使用 modelscope 的版本. 并设置cache的位置:
我要多少显存? Infer的速度是怎么样的?
对于30s的音频, 至少需要4G的显存. 对于4090D, 1s生成约7个字所对应的音频. RTF约0.65.
模型稳定性似乎不够好, 会出现其他说话人或音质很差的现象.
这是自回归模型通常都会出现的问题. 说话人可能会在中间变化, 可能会采样到音质非常差的结果, 这通常难以避免. 可以多采样几次来找到合适的结果.
除了笑声还能控制什么吗? 还能控制其他情感吗?
在现在放出的模型版本中, 只有[laugh]和[uv_break], [lbreak]作为字级别的控制单元.
在未来的版本中我们可能会开源其他情感控制的版本.
参考链接:
[colab]https://colab.research.google.com/drive/1_Ma1BXvIrYw9kO4UYsSG4GaFkttbS1wY?usp=sharing
[2]https://github.com/2noise/ChatTTS/tree/main
[3]https://www.youtube.com/watch?v=JJ3GGEjKgu4&t=6s
知音难求,自我修炼亦艰
抓住前沿技术的机遇,与我们一起成为创新的超级个体
(把握AIGC时代的个人力量)
**
**
** 点这里 👇 关注我,记得标星哦~ **
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~

预览时标签不可点
微信扫一扫
关注该公众号
轻触阅读原文

AI进修生
收藏



















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











