







最近新入手了一台 arm 开发板,希望打造一款有温度、有情怀的陪伴式 AI 对话机器人。

大体实现思路如下图:
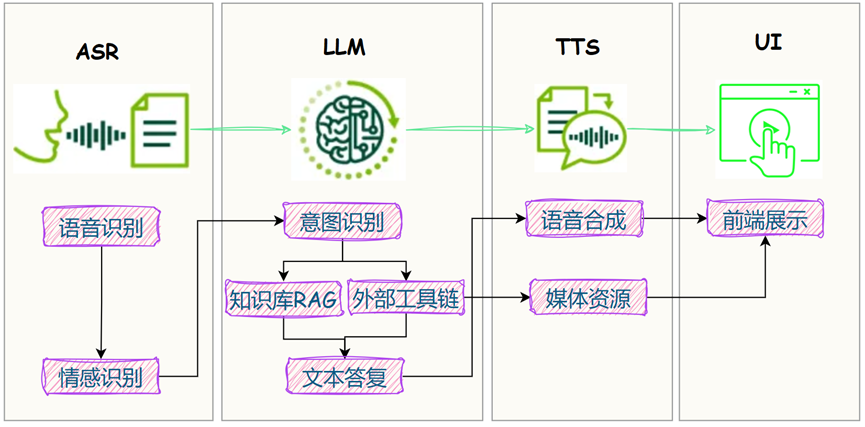
前两天在板子上,把本地 LLM 大脑装上了:
接下来,继续给它装上 眼睛、耳朵和嘴巴,一个机器人 JAVIS 的雏形不就出来了?
对应到设备上:
眼睛== 摄像头;耳朵== 麦克风;嘴巴== 扬声器;
对于 眼睛 和 耳朵,市面上的 USB 摄像头一般都自带有麦克风。
今日分享,带大家实操:如何在开发板上接入 USB 摄像头,并正确读取音频。
有小伙伴问:没有 arm 开发板怎么办?准备一台 Android 手机就行。
友情提醒:本文实操,请确保已在手机端准备好 Linux 环境,具体参考教程:如何在手机端部署大模型?
1. 接入 USB 摄像头

插入后,使用如下命令查看所有设备:
ls /dev/video*
多出来的 video2 即为刚插入的USB摄像头:

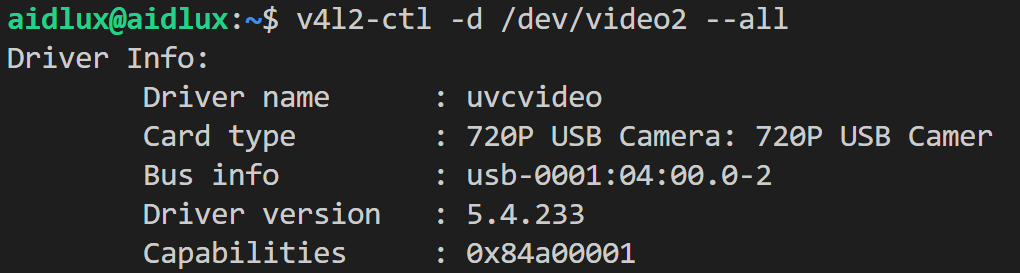
通过 v4l2-ctl 命令查看设备信息:
v4l2-ctl -d /dev/video2 --all
如果只想查看分辨率/帧率:
v4l2-ctl -d /dev/video2 --list-formats-ext
如果没什么问题,我们用 opencv 调用摄像头试试看:
import cv2
cap = cv2.VideoCapture("/dev/video2")
while True:
ret, frame = cap.read()
if not ret:
continue
# cv2.imshow('Camera', frame)
cv2.imwrite('frame.jpg',frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
有了摄像头,能做的事情就多了,下篇我们来分享:如何基于摄像头接入AI视觉能力。
本篇重点:如何获取摄像头自带的麦克风数据,接下来开整!
2. 获取音频设备
首先需要安装一些驱动音频的包:
sudo apt-get install alsa-utils pulseaudio
如果系统有 /proc/asound/cards 路径,说明 ALSA 驱动已经使用上,下面指令可以查看音频设备:
cat /proc/asound/cards
比如我的输出如下:
0 [Camera ]: USB-Audio - 720P USB Camera SN0002 720P USB Camera at usb-0001:04:00.0-4, high speed
1 [lahainayupikidp]: lahaina-yupikid - lahaina-yupikidp-snd-card lahaina-yupikidp-snd-card
下面两个指令分别用来查看:音频输入设备(麦克风)和音频输出设备(扬声器):
sudo arecord -l
sudo aplay -l
注意要加 sudo,非root用户无权限查看。
当然,也可以选择将当前账户加入 sudo 用户组:
sudo usermod -aG sudo aidlux
# 确认下
groups aidlux
# 最后重新登陆 or 重启系统
再来试试吧,可以看到已识别音频输入设备:
aidlux@aidlux:~$ arecord -l
**** List of CAPTURE Hardware Devices ****
card 0: Camera [720P USB Camera], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
上述指令,获取到设备号:card 0, device 0。
最后,我们采用如下指令,指定设备号hw:0,0,录制一段音频试试:
sudo arecord -D hw:0,0 -f S16_LE -r 16000 -c 1 -d 10 output.wav
注:上述指令仍然需要 sudo 权限,如何才能避免?
运行以下命令检查音频设备的权限:
ls -l /dev/snd
# 输出如下
total 0
drwxr-xr-x. 2 root root 60 Sep 15 17:43 by-id
drwxr-xr-x. 2 root root 60 Sep 15 17:43 by-path
crw-rw----. 1 system 1005 116, 61 Jan 1 1970 comprC1D11
crw-rw----. 1 system 1005 116, 62 Jan 1 1970 comprC1D24
crw-rw----. 1 system 1005 116, 63 Jan 1 1970 comprC1D25
可以看到,用户组 1005 才有音频设备的权限,为此可以将音频设备的组更改为audio,使其对所有audio组的用户可访问:
sudo chgrp audio /dev/snd/*
sudo chmod 660 /dev/snd/*
再次查看:
ls -l /dev/snd
# 输出如下
total 0
drw-rw----. 2 root audio 60 Sep 15 17:43 by-id
drw-rw----. 2 root audio 60 Sep 15 17:43 by-path
crw-rw----. 1 system audio 116, 61 Jan 1 1970 comprC1D11
crw-rw----. 1 system audio 116, 62 Jan 1 1970 comprC1D24
然后,把当前账户加入 audio 用户组:
sudo usermod -aG audio aidlux
至此,你就拥有了操纵音频设备的权限了。
3. 获取音频数据
我们希望实现一个基本的实时语音识别系统,该系统能够实时监听用户的语音。
本文将采用 PyAudio 库来实现这一目标。
首先,安装如下两个包:
sudo apt-get install portaudio19-dev
pip install pyaudio
然后查看设备支持的音频格式和通道数:
sudo arecord -D hw:0,0 --dump-hw-params | grep '^CHANNELS'
在 PyAudio 中找到摄像头麦克风的设备号:
def list_audio_devices():
p = pyaudio.PyAudio()
# 列出所有设备
for i in range(p.get_device_count()):
info = p.get_device_info_by_index(i)
print(f"设备 {i}: {info['name']}")
p.terminate()
输出如下:
设备 0: 720P USB Camera: Audio (hw:0,0)
设备 1: lahaina-yupikidp-snd-card: - (hw:1,0)
...
可以发现,摄像头对应的麦克风设备序号为 0。
要实现实时音频检测,怎么搞?
以下是我的实现逻辑,大家有更好的想法,欢迎交流:
- 检测到环境音量大于一定阈值,开始录音;
- 判断是否超过最大录音时间;
- 为了避免截断,设置静默时间;
- 结束录音,保存音频文件到本地,以时间戳命名。
实现代码如下,供参考:
def test_audio(amp_threshold=5000, max_record_time=5, slience_dura=1, chunk=1024, format=pyaudio.paInt16, channels=1, rate=16000, out_path='data/audios'):
os.makedirs(out_path, exist_ok=True)
p = pyaudio.PyAudio()
stream = p.open(format=format, channels=channels, rate=rate, input=True, input_device_index=0, frames_per_buffer=chunk)
print("程序正在运行,按 Ctrl+C 停止...")
try:
while True:
frames = []
recording = False
start_time = None
silence_start_time = None
while True:
amplitude_values = []
for _ in range(5):
data = stream.read(chunk)
amplitude_values.append(data)
amplitude_mean = np.mean([np.abs(np.frombuffer(d, dtype=np.int16)).mean() for d in amplitude_values])
print(f"{datetime.now().strftime('%H:%M:%S')}:{amplitude_mean:.1f}")
if amplitude_mean > amp_threshold:
if not recording:
recording = True
start_time = time.time()
print("开始录音...")
frames.extend(amplitude_values)
silence_start_time = None
else:
if recording:
frames.extend(amplitude_values)
if silence_start_time is None:
silence_start_time = time.time()
elif time.time() - silence_start_time >= slience_dura:
print("低音量持续,停止录音。")
break
# 检查是否超过最大录音时间
if start_time and time.time() - start_time >= max_record_time:
print("达到最大录音时间,停止录音。")
break
if recording:
# 保存录音到文件
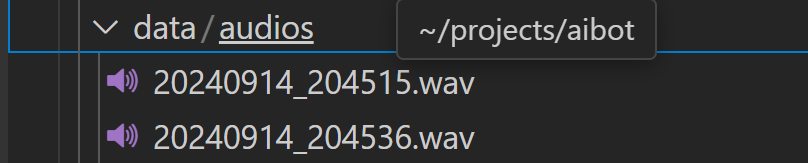
filename = f'{out_path}/{ datetime.now().strftime("%Y%m%d_%H%M%S")}.wav'
with wave.open(filename, 'wb') as wf:
wf.setnchannels(channels)
wf.setsampwidth(p.get_sample_size(format))
wf.setframerate(rate)
wf.writeframes(b''.join(frames))
print(f"录音已保存为 {filename}")
except KeyboardInterrupt:
print("手动停止程序。")
finally:
stream.stop_stream()
stream.close()
p.terminate()
有了音频文件,接下来就可以调用 ASR 实现音频检测,进而交给 LLM 进行互动啦~我们下篇来聊。
附:Pyaudio 基本用法
听:输入设备的音频保存到本地:
p = pyaudio.PyAudio()
stream = p.open(format=format, channels=channels, rate=rate, input=True, input_device_index=0, frames_per_buffer=chunk)
data = stream.read(chunk)
说:播放本地音频文件到输出设备:
wf = wave.open(file_path, 'rb')
p = pyaudio.PyAudio()
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(), ate=wf.getframerate(), output=True, output_device_index=0)
# 读取数据并播放
data = wf.readframes(1024)
while data:
stream.write(data)
data = wf.readframes(1024)
写在最后
本文通过一个 USB 摄像头,给开发板安排上了"眼睛"和"耳朵",并通过 PyAudio 实现实时音频检测。
如果对你有帮助,欢迎点赞和收藏备用。
为方便大家交流,新建了一个 AI 交流群,欢迎对嵌入式、AIoT、AI工具感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,公众号后台「联系我」,拉你进群。















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









