







最近新入手了一台 arm 开发板,内置安装了 Android 13 系统。
昨天把网络问题给解决了:安卓连接 WIFI 但无法上网?盘点踩过的那些坑
今日分享,继续带大家实操:如何把大模型(LLM)部署到移动端(arm 架构)。
有小伙伴问:手头没有 arm 开发板怎么办?
准备一台 Android 手机就行。
为了得到一个丝滑的 Linux 开发环境,我们先来了解下 AidLux。
1. AidLux 简介
AidLux 是啥?
一个智能物联网(AIoT)应用开发和部署平台,它运行在 arm 架构的 CPU 上,通过 Linux 内核共享,将 Android 与 Linux 完美融合,面向物联网支持90%以上接口和外设。
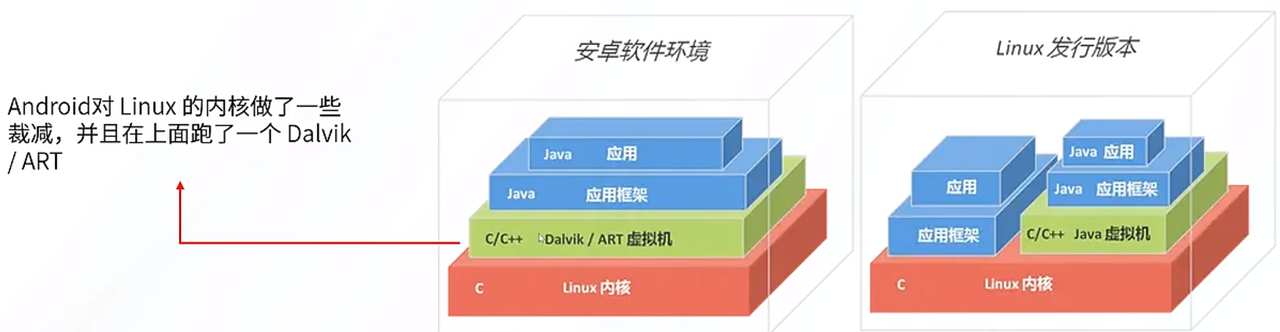
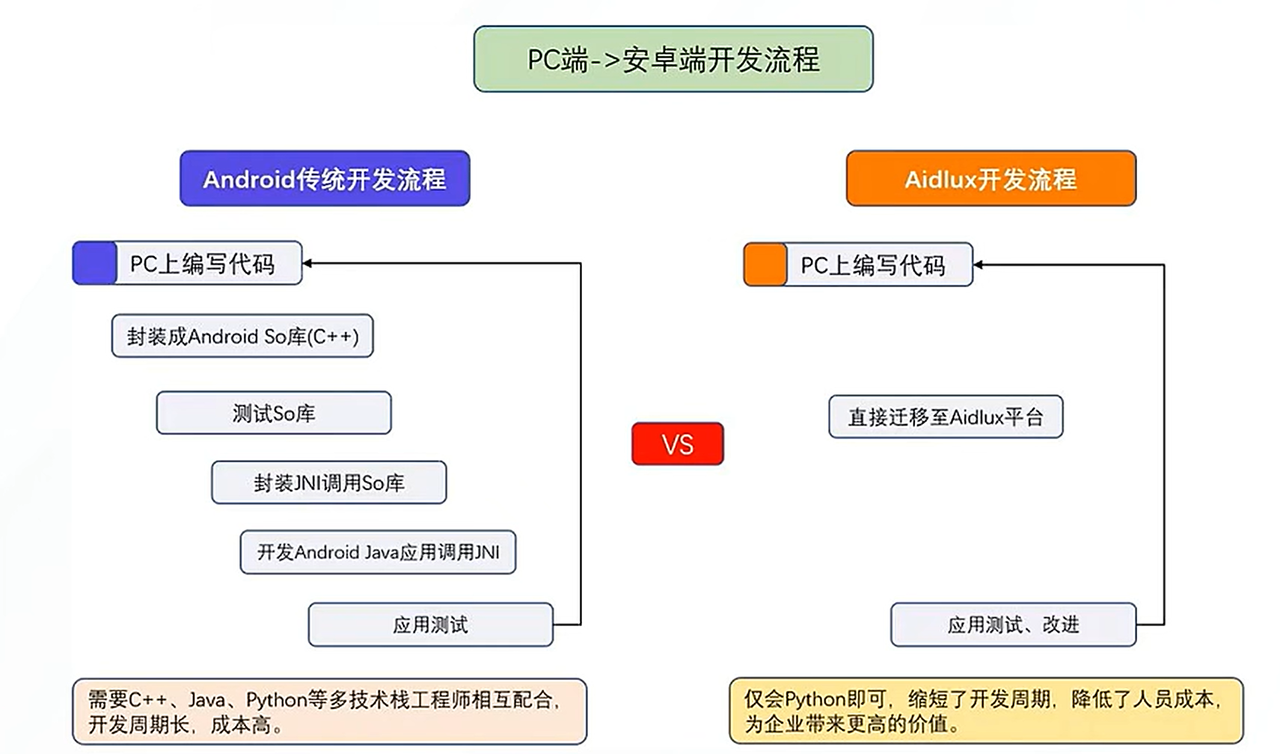
Android 也是基于 Linux 内核,从上图可以发现,Android 开发需要 C++ java python 全栈,而安装 AidLux 后,你就拥有了一个丝滑的 Linux 环境,因此只会 python 也 OK。
AidLux 怎么安装?
任意品牌手机,应用商店搜索 AidLux ,一键安装!
安装完成后,打开 APP,你会看到如下界面,找到 Cloud IP 图标,确保浏览器和手机/开发板在同一个局域网内,浏览器输入下面的 URL 打开 Web 界面,登录密码为 aidlux。
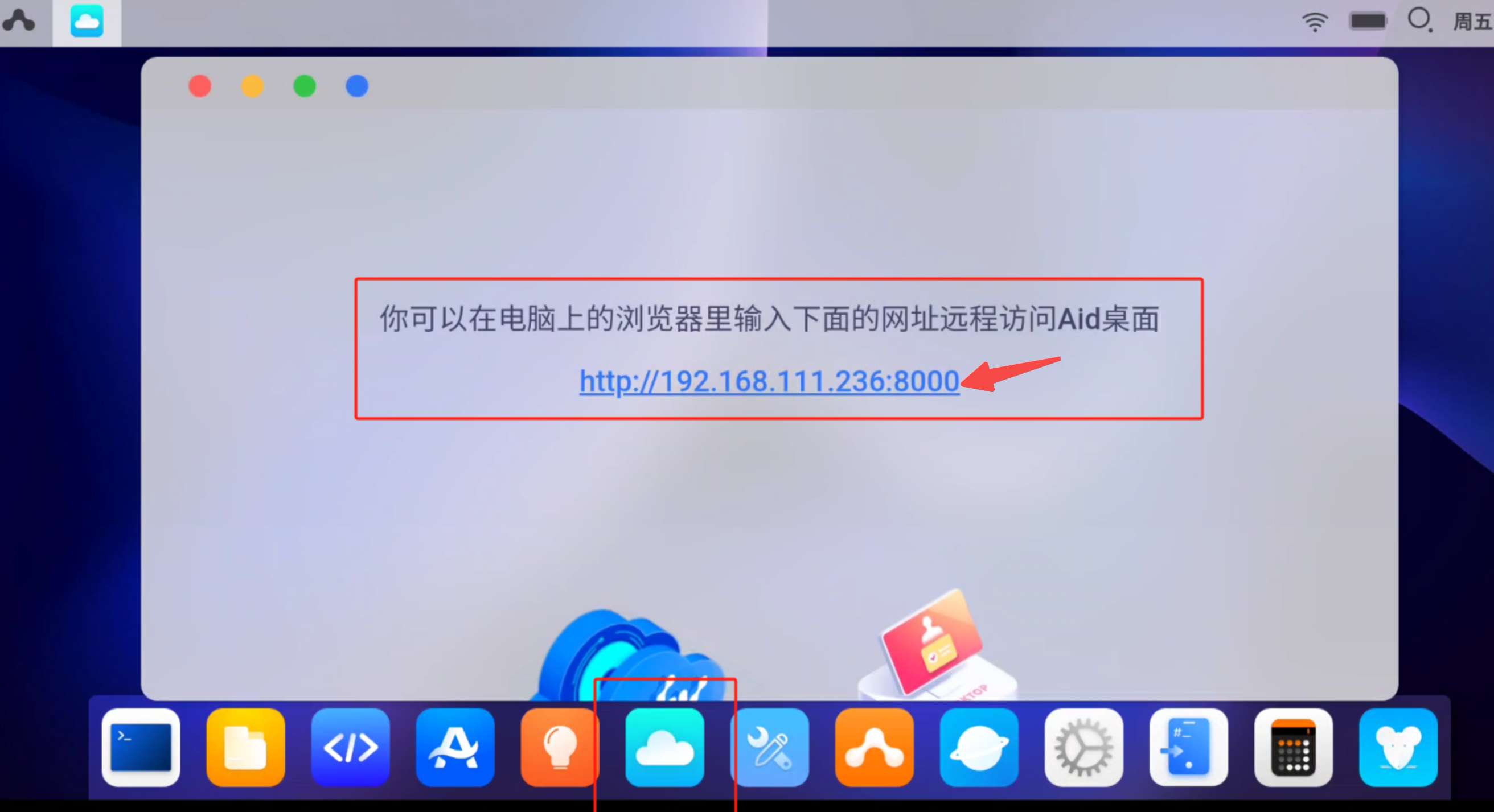
至此,你的一台 Linux 服务器已经准备就绪!
2. 开发准备
2.1 远程登录
如果要进行开发,最好能实现 VS Code 远程登录,不了解如何操作的小伙伴,可参考这篇教程:【保姆级教程】Windows 远程登陆 Linux 服务器的两种方式:SSH + VS Code
ssh config 配置示例如下,开发板直接用 22 端口,手机需要改用 9022 端口:
Host aibox
HostName 192.168.10.2
Port 22
User aidlux
登录密码默认为 aidlux,当然如果不想每次都输入密码的话,可以改用密钥认证,具体可参考上面教程。
2.2 Docker 安装
为了快速跑通各种 AI 应用,免不了要安装 Docker !
Docker 是一个开源的应用容器引擎,将应用及其依赖打包到镜像中,随时移植到容器中,无需关心操作系统的底层。不了解如何安装使用的小伙伴,可参考这篇教程:【保姆级教程】Linux系统如何玩转Docker
3. Ollama 安装
Linux 主机上如何安装 Ollama,之前出过一篇教程:本地部署大模型?Ollama 部署和实战,看这篇就够了
本文假设你已安装好 Docker,我们可以采用如下指令,一键安装好 Ollama + OpenWebUI:
sudo docker run -d -p 1001:8080 -p 1002:11434 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name ollama-webui --restart always ghcr.io/open-webui/open-webui:ollama
上述指令中,我们需要映射两个端口出来:
- 1001:8080 – webui 的前端界面端口;
- 1002:11434 – ollama 模型的后端调用端口。
注:如果容器已经在运行,你无法直接修改容器的端口映射。需要停止并删除现有容器,再重新创建。
所以,上述指令中,我们要用 -v 参数来持久化数据,这样重新创建容器就不会导致数据丢失。
浏览器中,输入 your_ip:1001,打开映射的前端界面端口,如果没什么问题,你应该看到如下界面:
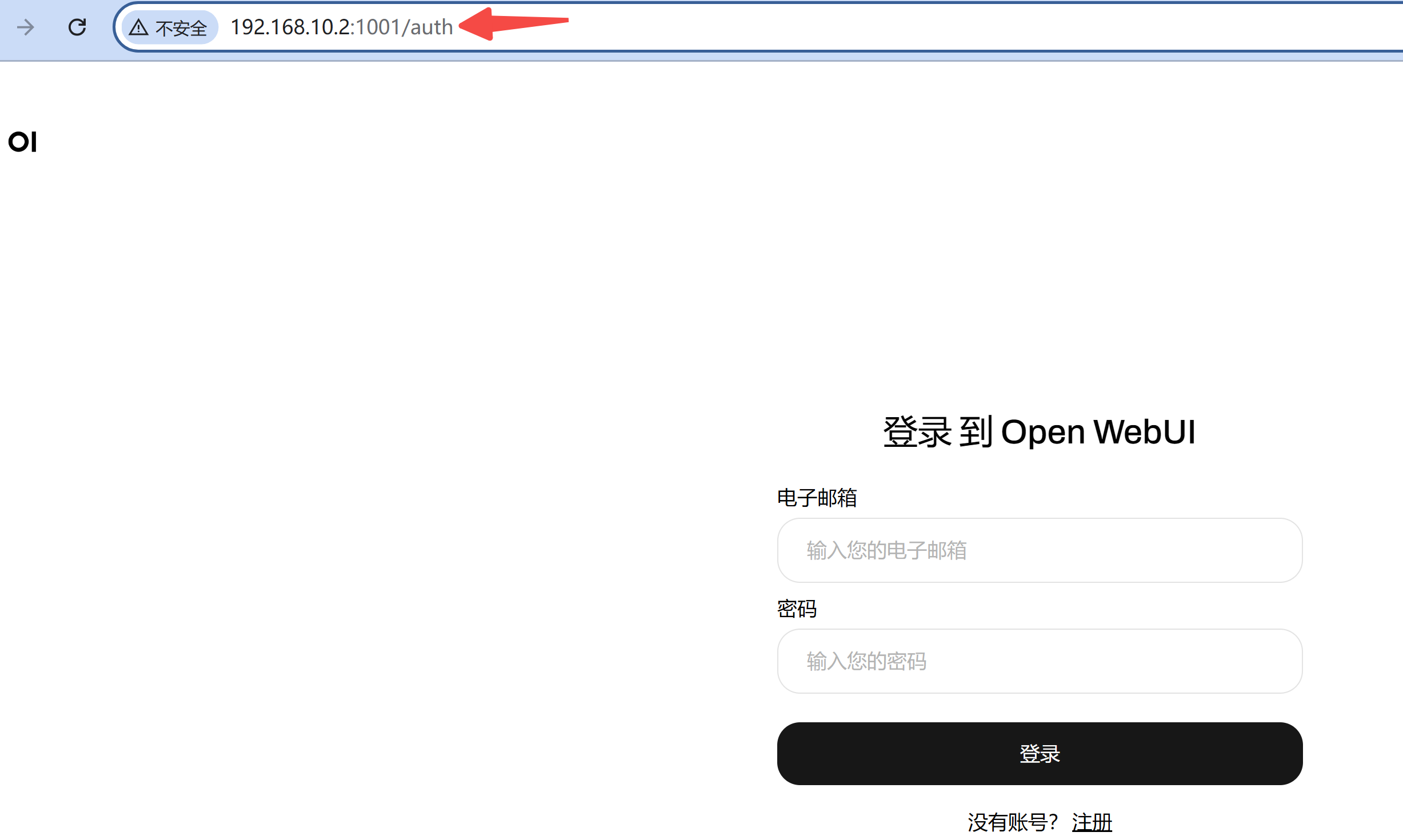
注册一个账号后,进来就可以和 LLM 愉快对话了?
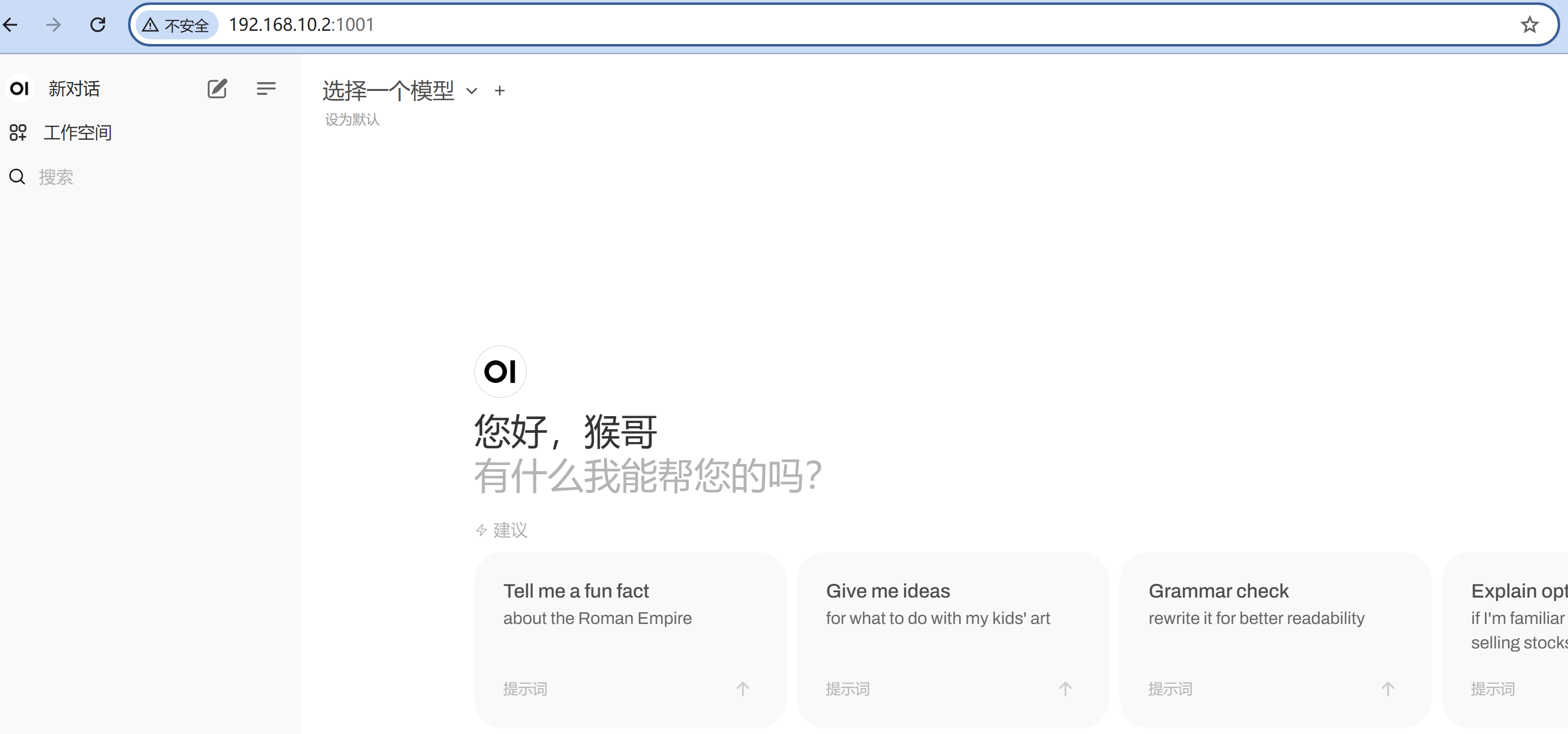
NO!Ollana 中还没有部署任何模型~
3.1 大语言模型部署
要安装模型,首先需要进入容器:
sudo docker exec -it ollama-webui /bin/bash
在本地部署大模型?Ollama 部署和实战,看这篇就够了中,为了快速跑通流程,我们采用的 qwen2:0.5B,速度倒是快,不过由于参数量较小,稍微复杂一点的指令,就尴尬了。。。
这次,我们部署 qwen2:7B 来试试(确保至少 8GB 的 RAM):
root@9345c935de06:/app/backend# ollama run qwen2
pulling manifest
pulling 43f7a214e532... 2% ▕ ▏ 73 MB/4.4 GB 3.2 MB/s 22m43s
稍等片刻,模型下载成功,再去 your_ip:1001 看看吧!终于,大模型已经在你的手机上跑起来了。
除了前端,当然我们还希望能在后端调用大模型。
No Problem,容器中 Ollama 已自动启动后端 API。
我们来写下接口调用示例代码:
def test_ollama():
url = 'http://localhost:1002/api/chat'
data = {
"model": "qwen2",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
],
"stream": False
}
response = requests.post(url, json=data)
print(response.text)
请求被拒绝了?已经把主机的 1002 映射到容器的 11434 了啊?
Yes,不过这里有个坑,我们一起来排查下,在容器中执行:
sudo apt update
sudo apt install net-tools
netstat -ntlp
可以看到有两个端口正在被监听:
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 10/ollama
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 1/python3
但是,有没有发现:容器内的 11434 端口在 127.0.0.1 上监听,这意味着它只接受来自容器内部的请求。因此,你在宿主机上尝试通过映射的 1002 端口访问,无法成功!
怎么解决?
先把 ollama 的进程杀了,然后指定环境变量 OLLAMA_HOST=0.0.0.0,再重新启动!
kill 10
export OLLAMA_HOST=0.0.0.0
nohup ollama serve > log.txt 2>&1 &
再来打开 your_ip:1002 看看吧!

搞定!这时再用上面的示例代码,就可以请求成功了。
如果还希望接入兼容 OpenAI 格式的应用,可以考虑将 Ollama 的模型接入 OneAPI。
不了解 OneAPI 的小伙伴可参考这篇教程:OneAPI-接口管理和分发神器:所有大模型一键封装成OpenAI协议。
我们先用下面指令部署 OneAPI:
sudo docker run --name oneapi -d --restart always -p 1003:3000 -e TZ=Asia/Shanghai -v oneapi:/data justsong/one-api
浏览器中输入 your_ip:1003,进入 OneAPI 管理界面,然后新建一个渠道,名称就叫 ollama,输入你在 ollama 容器中已经安装好的模型:
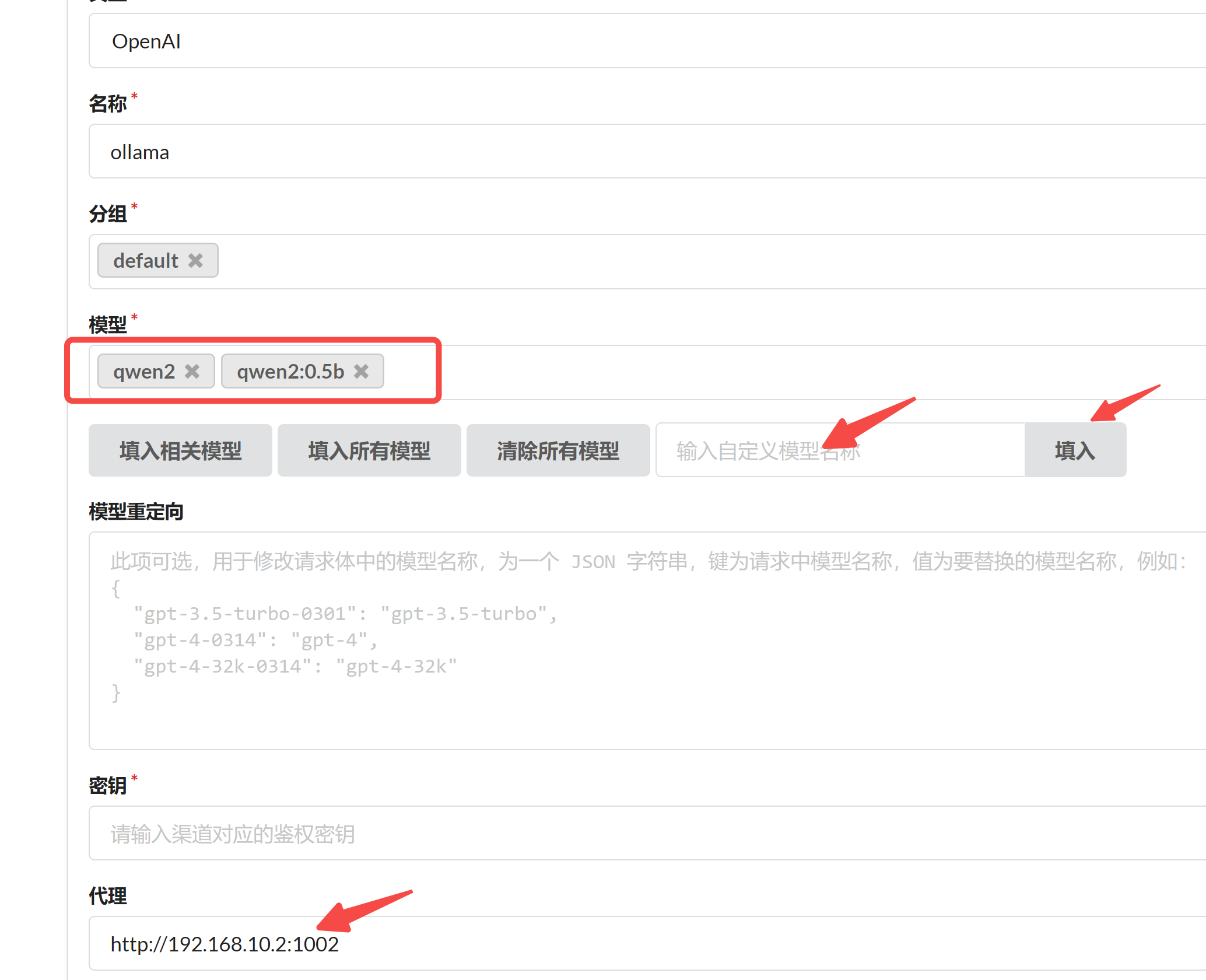
最后的代理,注意要填主机的 IP 地址,localhost 是不行的。
至此,你的本地大模型,已经无缝兼容 OpenAI 格式的 LLM 应用啦。
3.2 多模态大模型部署
除了众多大模型之外,Ollma 中还集成了视觉多模态模型。
而提到多模态模型,就不得不致敬下 LLaVA,它结合了视觉编码器和大语言模型 Vicuna,可用于通用视觉和语言理解,已更新至 1.6 版本。
Ollma 中一键安装:
ollama run llava
安装成功后,我们来到 WebUI 试试吧:
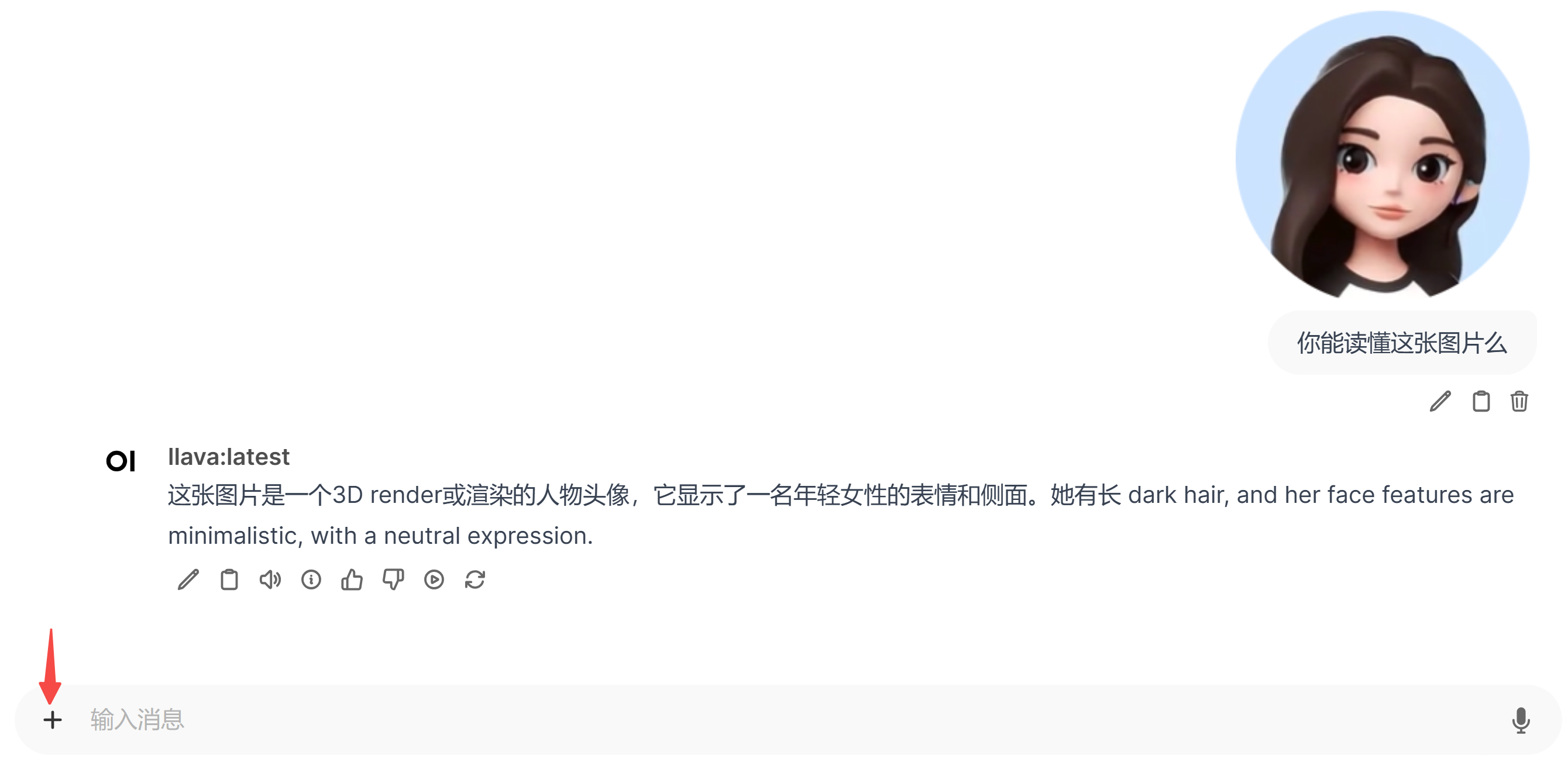
上面这个简单的任务,足足运行了近 4 分钟!
看来,在端侧跑多模态大模型,还任重道远啊~
接下来,我们来写下后端接口调用示例代码:
def test_llava():
url = 'http://localhost:1002/api/generate'
data = {
"model": "llava",
"prompt": "What is in this picture?",
"images": [encode_image('test.png')],
"stream": False
}
response = requests.post(url, json=data)
print(response.json())
注意:传入的图像,需要使用 base64 编码。
返回结果如下:
{"model":"llava","created_at":"2024-09-10T12:52:53.284208538Z","response":" The image shows a stylized illustration of a pink deer or antelope standing on two legs. It appears to be a cartoon representation, with the animal's body simplified and rendered in shades of pink against a black background. The deer has large eyes, a small nose, and what looks like a tufted tail. ","done":true,"done_reason":"stop","context":[733,],"total_duration":227969591111,"load_duration":32525521,"prompt_eval_count":1,"prompt_eval_duration":197885547000,"eval_count":73,"eval_duration":30043357000}
除了速度不能忍之外,效果还是可以滴~
写在最后
本文通过 AidLux + Ollama 带大家快速跑通端侧部署大模型的流程,为实现端侧 LLM 应用提供了一种可能性。
下一篇,我们将继续探索更多的 LLM 工具链,为端侧 LLM 应用构建好基础设施。
如果本文对你有帮助,不妨点个免费的赞和收藏备用。
为方便大家交流,新建了一个 AI 交流群,欢迎感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,想进群体验的朋友,公众号后台「联系我」即可,拉你进群。

















 4444
4444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









