







上篇给大家分享了最强开源 OCR 模型 - GOT-OCR2.0:
问题来了:最强 OCR + 最强 LLM 能擦出什么火花呢?
本篇,将手把手带大家实操:本地部署最强数学大模型 Qwen2.5-Math,并结合上篇的 GOT-OCR2_0,打造一款可以给娃辅导数学作业的利器-AI数学老师。
1. Qwen2.5-Math 简介
前不久,阿里开源了 Qwen2.5系列,稳居全球最强开源大模型,猴哥前段时间有做过测评,感兴趣的小伙伴可以翻看。
Qwen2.5-Math 是同期开源的数学大模型,包括两个版本:
- 基础模型: Qwen2.5-Math-1.5B/7B/72B
- 指令微调: Qwen2.5-Math-1.5B/7B/72B-Instruct
Qwen2.5-Math 到底有多强?
据称,旧版模型在解答数学问题上,已超闭源的 GPT-4O,新版岂不更强?
👇一图胜千言,新版 7B 逼近旧版 72B 模型的性能,妥妥的性价比之王。
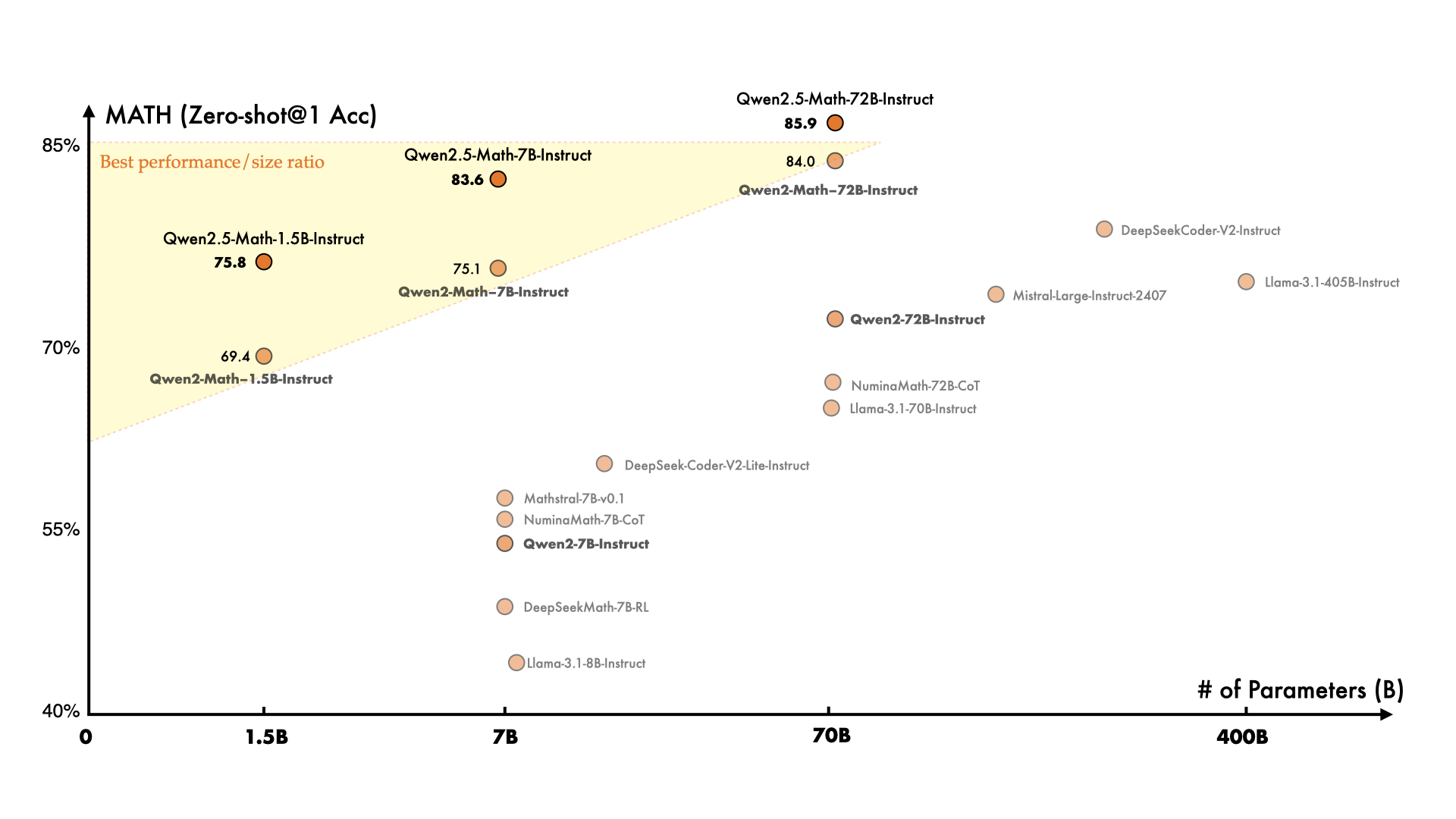
Qwen2.5-Math 到底强在哪?
相比上一代,Qwen2.5-Math在中英文的数学解题上均实现了显著提升。具体而言:
- Qwen2-Math 只支持使用思维链(CoT),只支持英文数学题;
- Qwen2.5-Math 增加了工具集成推理(TIR),比如python解释器,支持中英双语的数学题。
2. Qwen2.5-Math 本地部署
之前我们本地部署 Qwen2.5 采用的是 Ollama:
最强开源Qwen2.5:本地部署 Ollma/vLLM 实测对比,邀你围观体验
2.1 Ollama 部署
不过,Ollama Library 没上线 Qwen2.5-Math,如果要用 Ollama 部署原生模型,可参考教程:本地部署大模型?Ollama 部署和实战,看这篇就够了。
Huggingface 社区已有 GGUF 格式的模型,推荐大家直接下载食用。
如何下载单个模型权重?参考下图,找到你想要的模型,右键-复制链接地址:
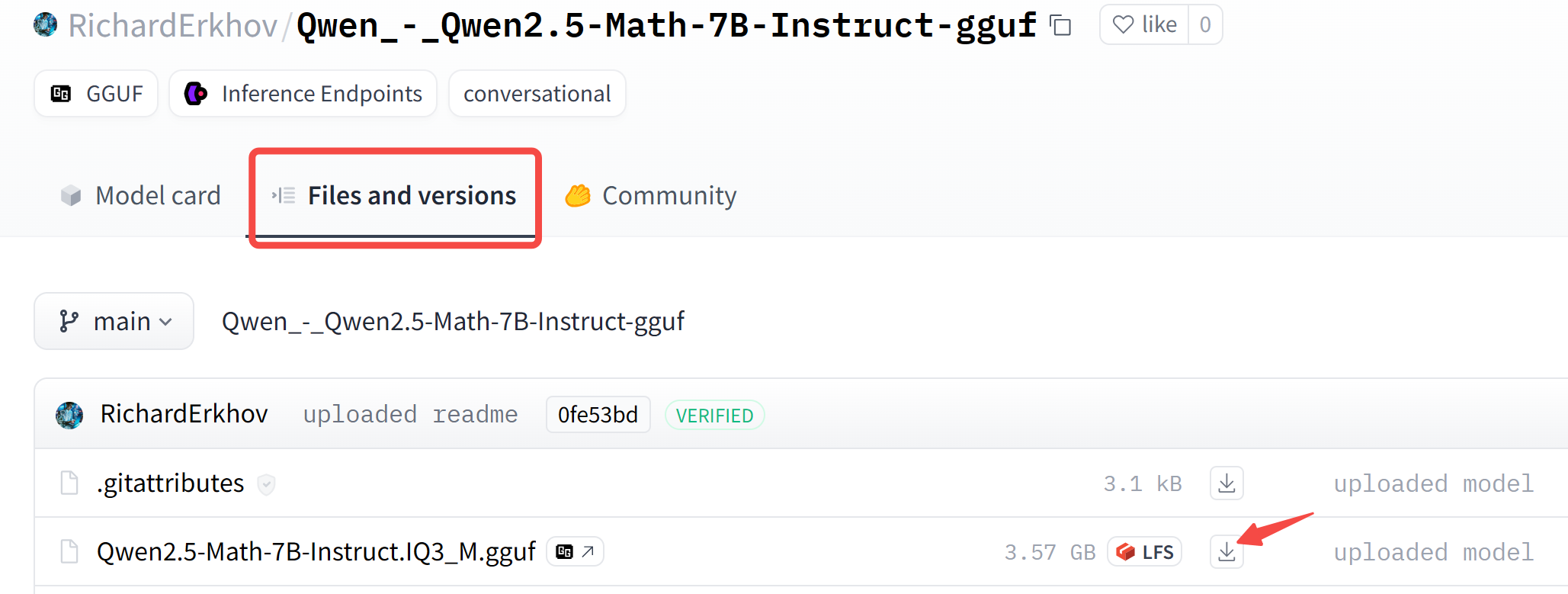
然后命令行下载:
wget https://hf-mirror.com/RichardErkhov/Qwen_-_Qwen2.5-Math-7B-Instruct-gguf/resolve/main/Qwen2.5-Math-7B-Instruct.Q4_K_M.gguf
下载成功后,参考上面文章的-2.3 自定义模型,完成模型创建和运行。
2.2 原生部署
考虑到 Ollama 部署本地模型,对小白并非友好,因此本文带大家手动下载模型,进行原生部署,方便快速体验。
原生模型下载:
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download Qwen/Qwen2.5-Math-7B-Instruct --local-dir ckpts/Qwen2.5-Math-7B-Instruct
**模型初始化:**量化模型以加速推理
import torch
from transformers import AutoTokenizer, BitsAndBytesConfig, Qwen2ForCausalLM
bnb_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True, #QLoRA 设计的 Double Quantization
bnb_4bit_quant_type="nf4", #QLoRA 设计的 Normal Float 4 量化数据类型
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
model_name = "ckpts/Qwen2.5-Math-7B-Instruct"
model = Qwen2ForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
torch_dtype=torch.float16,
low_cpu_mem_usage=True).eval()
tokenizer = AutoTokenizer.from_pretrained(model_name)
构建提示词:
# CoT
ocr_res = '1、x²+6x-5=0 2、x²-4x+3=0 3、2x²-10x=3 4、 (x+5)²=16'
prompt = f'{ocr_res}, 请问第2道题怎么解'
messages = [
{"role": "system", "content": "你是一位数学老师,请逐步推理,并在最终答案中使用 \boxed{} 来表示。"},
{"role": "user", "content": prompt}
]
开始推理:
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to("cuda")
generated_ids = model.generate(**model_inputs, max_new_tokens=4096)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
response = response.replace("\\(","$(").replace("\\)",")$").replace("\\[","$[").replace("\\]","]$")
print(response)
推理结果:
要解二次方程 $(x^2 - 4x + 3 = 0)$,我们可以使用因式分解的方法。以下是步骤:
1. **识别二次方程**:给定的方程是 $(x^2 - 4x + 3 = 0)$。
2. **因式分解**:我们需要找到两个数,它们相乘等于常数项(3),并且相加等于线性项的系数(-4)。这两个数是 -1 和 -3,因为 $((-1) \times (-3) = 3)$ 和 $((-1) + (-3) = -4)$。
3. **重写二次方程**:使用这些数,我们可以将二次方程因式分解为 $((x - 1)(x - 3) = 0)$。
4. **解每个因子**:将每个因子等于零并解出 $(x)$。
$[x - 1 = 0 \quad \text{或} \quad x - 3 = 0]$
$[x = 1 \quad \text{或} \quad x = 3]$
5. **写出解**:方程 $(x^2 - 4x + 3 = 0)$ 的解是 $(x = 1)$ 和 $(x = 3)$。
因此,最终答案是 $(\boxed{1 \text{ 和 } 3})$
最后,我们把文字放到 Markdown 渲染工具中,效果如下:

怎么样?
3. AI 数学老师搭建
上篇我们已经把通用 OCR搭建好了,现在只需把 Qwen2.5-Math接进来:
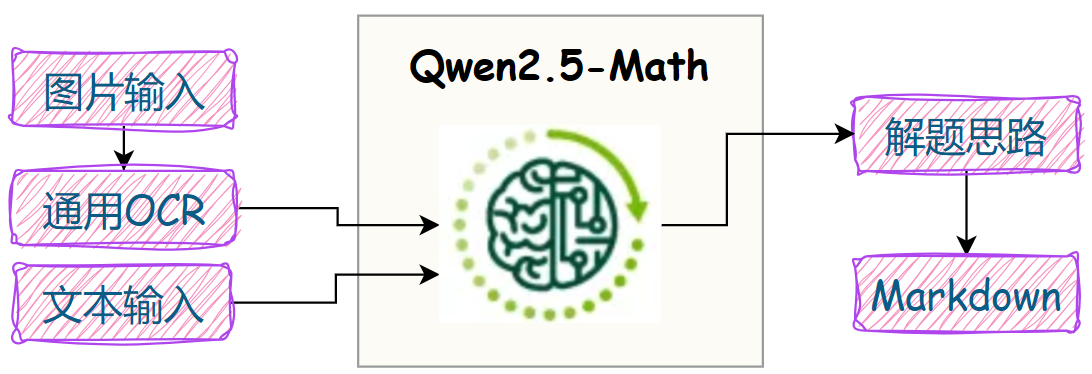
首先定义一个请求体,如果有图片输入,则调用通用 OCR识别题目,否则直接根据文本内容进行答复。
class MathRequest(BaseModel):
image : str = None # base64编码的图片
text : str
最后把两个功能串联起来,核心逻辑就搭建好了:
@app.post('/math')
async def math(request: MathRequest):
if request.image:
image_data = base64.b64decode(request.image)
image_name = f"{time.time()}.jpg"
with open(image_name, 'wb') as f:
f.write(image_data)
ocr_res = ocr_model.chat(ocr_tokenizer, image_name, ocr_type='ocr')
os.remove(image_name)
else:
ocr_res = ''
text = request.text
query = f"{ocr_res} {text}"
messages = [
{"role": "system", "content": "你是一位数学老师,请将自然语言推理与程序结合起来解决上述问题,并在最终答案中使用 \boxed{} 来表示。"},
{"role": "user", "content": query}
]
text = math_tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = math_tokenizer([text], return_tensors="pt").to("cuda")
generated_ids = math_model.generate(**model_inputs, max_new_tokens=4096)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = math_tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
text = response.replace("\\(","$(").replace("\\)",")$").replace("\\[","$[").replace("\\]","]$")
return text
两个模型加载后,整体显存占用情况:

进行推理后,显存使用情况:

怎么样?一块消费级显卡就够。
4. 案例展示
4.1 小学数学题
还是上一篇的小学数学试卷。
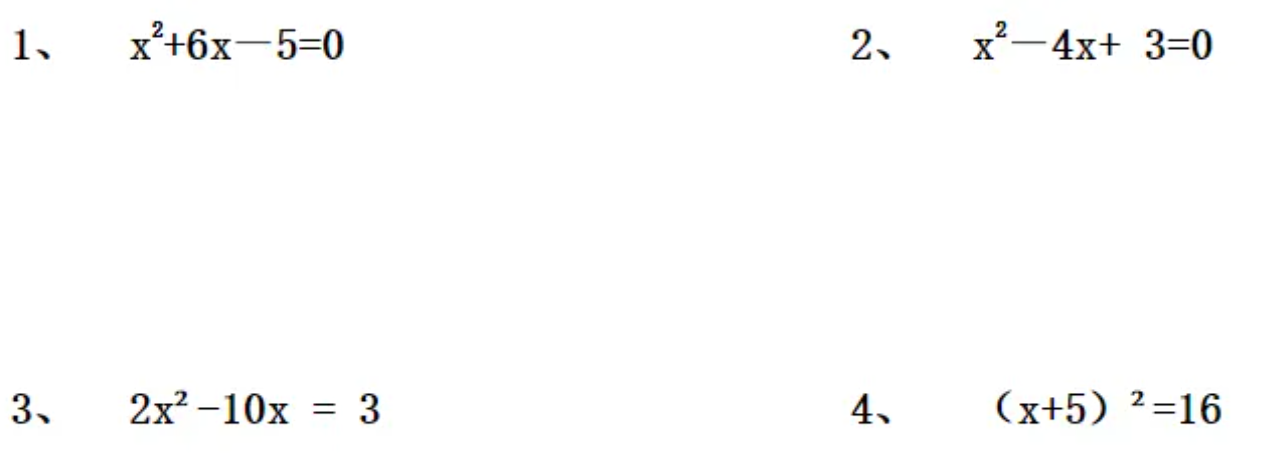
让他来做第4题看看:
def test_math():
image_path = 'data/2.png' # 修改为你的图片路径
base64_image = image_to_base64(image_path)
data = {
"image": f"{base64_image}",
"text": "请问第4题怎么解"
}
response = requests.post("http://localhost:3004/math", json=data) # 修改为你的API地址
print(response.json())
花了 17.7 秒,Qwen2.5-Math 给出的解答如下:

4.2 小学奥数题
先看看下面这段中等难度的奥数题,你能在几秒内搞定?

交给 Qwen2.5-Math,返回结果如下:

上难度了,这道题 Qwen2.5-Math 共花了 36.4 秒,你答对没?
4.3 高中数学题
高中部分,来一道基本不等式吧,是不是已经忘光了?

没关系,交给 Qwen2.5-Math 看看,返回结果如下:

这道题 Qwen2.5-Math 共花了 69.6 秒,就问你强不强?
写在最后
本文带大家实操了 Qwen2.5-Math 本地部署,并搭建了小初高全覆盖的AI数学老师。
有了它,还请什么家教,从此妈妈再也不用担心辅导娃作业啦。
如果对你有帮助,欢迎点赞收藏备用。
AI 不应是冰冷的代码,而应是有温度的伴侣。
大模型应用落地场景中,个人觉得最靠谱的就是教育,最近在打造有温度 有情怀的AI学伴,欢迎感兴趣的朋友一起交流。
为方便大家交流,新建了一个 AI 交流群,欢迎感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,公众号后台「联系我」,拉你进群。

















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









